改进的FSVM算法用于非平衡情感数据分类
2018-11-17张雪英陈桂军
张雪英,张 波,陈桂军
(太原理工大学 信息工程学院,山西 晋中 030600)
0 引 言
计算机语音情感识别[1]能力应用多样,在多媒体分段与检索、测谎仪、疾病诊断等方面有着广泛的用途。SVM在解决小样本以及维数灾难问题中有着良好的分类效果。但是它也有缺陷,在分类的过程中有些区域不可分,影响分类结果。当数据集中的正负样本不平衡性较大时,SVM对少数类的识别效果很差。同时,支持向量机对噪声和孤立点也比较敏感,影响最终的分类结果。
针对以上缺陷,文献[2]用FSVM对不同的不平衡率样本集进行分类,但忽略了样本点附近的样本分布情况造成了误分。文献[3]在模糊支持向量机的基础上引入了不平衡调节因子,对少数类样本赋予较大的权值,多数类样本赋予较小的权值,有效解决了样本分布不均匀的问题。文献[4]设置了参数值调整选取训练样本的范围,有效地避免了孤立点对最优的分类超平面所造成的影响。文献[5]提出了DEC算法分别给两类样本赋权重,但这种方法没有考虑到样本点周围的疏密性对分类超平面的影响。文献[6]提出了一种近似支持向量机(Proximal SVM),将模型转化为简单的二次规划问题,提高了学习速度。文献[7]通过对支持向量上采样提出了一种不平衡数据分类方法。文献[8]提出了一种核函数选取和欠采样相结合的算法来提高少类样本的准确率。本文提出一种FSVM算法,考虑到每个样本临近区域的样本分布状况以及样本集的不平衡程度,设定控制值灵活的控制样本集的范围,减弱野值点的影响并有效突出支持向量的作用,提高了识别准确率。
1 模糊支持向量机
1.1 改进FSVM算法

(1)
式中:C+,C-为常数,分别代表正负类样本的惩罚因子,为求解式(1),通过拉格朗日函数,出其对偶规划为
(2)
约束条件为

(3)
其中,k(xi·xj)=φ(xi)φ(xi)T为核函数。模糊因子si的确定是模糊支持向量机工作性能好坏的关键,本文重心在于如何精确的对模糊因子si赋值。
1.2 DEC算法
SVM对不平衡的大数据样本集做分类,超平面会偏移,优化性能很差,具体表现在多数样本分类远远优于少数, DEC算法通过对不同类别样本分别给予重要程度,优化分类超平面,使偏移性降低,增强分类结果,文献[5]表明当C-/C+的比率等于n+/n-(n+,n-分别表示正样本和负样本的数量)时,算法最优,能实现最好的分类。基本大多样本类别数目相差悬殊的时候都用此算法,一定范围上可以提高准确性,但并未考虑样本分布情况的影响,若是空间复杂性样本分布或者不规则分布时,算法便不能优化分类超平面了。本文将模糊隶属度与惩罚因子结合起来,根据对分类超平面的贡献值为每个样本分配不同的权重,使分类器分类偏移幅度尽可能的小。
2 面向非平衡数据集的FSVM隶属度设计
2.1 传统隶属度函数设计
为了减少异常值和噪声点对最优分类超平面的影响,传统的隶属函数主要是根据从样本到类中心的距离来设计的。如图1所示,H1与H2上各有3个支持向量,每个支持向量到属于本类的类中心间距不一,这6个支持向量对于确定H这个分类超平面起着决定性作用,如果根据间距赋重要性程度,那么每个支持向量被给予的权值都不同,但实际情况,它们重要性是一样的,传统方法赋值存在很大漏洞,不能单靠与类中心间隔比较来确定重要与否。只有将这些不足之处填补,才能优化分类器的性能,减小数据偏移,大数据氛围下,有大量数据样本点需要做处理、做赋值,必须优化算法才能解决这一问题。

图1 根据样本到类中心的距离进行隶属度函数设计
2.2 根据样本分布情况进行设计

(4)
(5)
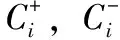

图2 带有一个噪声点的椭圆分布数据
wx++b1=1;wx-+b2=-1
(6)

(7)
两类样本到各自类中心的距离
(8)
正样本到过负样本中心超平面的距离
(9)
负样本到过正样本中心超平面的距离
(10)
计算两类类中心的距离
(11)
取
D+=max{di+},D-=max{di-}
(12)
隶属度函数计算公式为
(13)
(14)


图3 新型不平衡隶属度函数设计
将样本点到过负类中心超平面的距离d1i+和T值进行比较,可以彰显H1和H2线上支持向量点效果,突出其对分类超平面的贡献,DEC算法能大幅度降低分类超平面偏移幅度,另外结合紧密度能够确定噪声点将其剔除。
3 实验与结果分析
实验选取两种情感库,CASIA汉语语料库包括5类情感,空间分布规则,不重叠,情感色彩鲜明。太原理工大学TYUT2.0库包括4种情感,由多名学生录制判别,选取大多趋向定义情感类,具有可靠性,两种库比较适合用来做情感识别实验。
实验选取MFCC特征,音质特征还有韵律特征,归一化,分别用CASIA库,情感类为生气的样本,以及TYUT2.0,感受为高兴的样本,默认为正类样本,其余看作一类,不平衡比体现,数据集的介绍见表1。

表1 情感语音数据集
3.1 参数对算法准确率Gm的影响
对于非平衡情感数据集,本文采用不平衡数据学习中的Se,Sp,和Gm来评价[10],其定义为
(15)
TP、FN、TN、FP分别代表分类正确的正样本、分类错误的负类样本、分类正确的负类样本、以及分类错误的正类样本的个数,用Gm对分类器性能进行评价,Gm越大分类效果越好。
本节用不同C值做实验,比较文献[4]中的HFSVM、文献[11]中LFSVM方法,取 0,0.1,1,10,20,…,100,图4、图5分别给出了两种情感库数据集的实验结果。

图4 C值的改变对CASIA汉语情感语料库Gm的影响
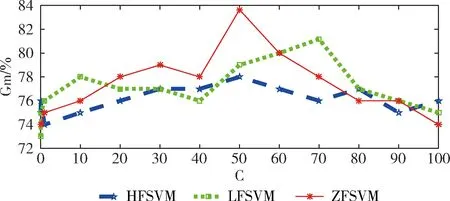
图5 C值的改变对TYUT2.0情感语料库Gm的影响
3.2 算法准确率Gm对比分析
将文献[4]中的HFSVM方法、文献[11]中LFSVM设方法与本文方法对比,选取最高C值。表2为对CASIA汉语库,TYUT2.0情感库做识别的最终结果。

表2 3种算法的比较结果

图6 3种算法对CASIA汉语情感语料库的Gm值比较

图7 3种算法对TYUT2.0情感语音库的Gm值比较
比较图6,图7可以看出,ZFSVM在对不平衡率为14.28的CASIA汉语库做识别时,Gm值为91.70%,对不平衡率为4.89的柏林库做识别时的Gm值为83.65%,算法性能的好坏受样本的不平衡程度影响。不平衡程度越厉害,算法对样本做处理的精确度越高,说明本文所提算法的有效性,造成最优超平面偏移程度很小。此外相比其它两种方法,本文方法的准确性也有增长,因为对每个样本所配权值更加精准了,随着样本数增多前面两种方法会将部分对超平面贡献相同的样本赋予不同的权值,甚至会给部分对超平面贡献较大而距离类中心较远的样本赋予小的隶属度值,一定程度上减弱了支持向量的作用,影响分类结果。
4 结束语
为了解决SVM分类的缺陷,通过DEC算法,及样本点附近样本分布,对每个样本点到类中心超平面的距离设计权值赋予方式,确定噪声点。按照样本点重要与否、程度大小各自赋值,大大减小了非支持向量点影响,去除了噪声点干扰,某种意义上提高了支持向量机的抗噪性。实验结果表明,本文所提算法对不平衡语音情感数据库的识别性能有显着提高。但是,此方法需要设置参数重复实验以选择优值。下一步是更详细地研究参数和隶属函数之间的关系,并找到更方便的参数设置方法。
