基于改进时空特征的三维人体位姿估计方法
2018-11-17谢立靖任胜兵
谢立靖,任胜兵
(1.湖南商务职业技术学院 信息学院,湖南 长沙 410205;2.中南大学 计算机学院,湖南 长沙 410083)
0 引 言
随着深度相机的发展,可以获取很多有代表性的运动捕捉结果,但是普通单目视频序列中的三维人体位姿还原依然是一个极具挑战的问题[1]。
针对该问题的研究,已经有一些研究成果。如OuYang等[2]提出的单目三维位姿估计方法,是一种帧对帧的回归跟踪,但由于场景中其它人或物体的干扰和遮挡,该方法容易失效。为此,出现一些致力于通过探测进行位姿跟踪估计的方法,即探测每帧中或多或少的独立人体位姿,然后将各帧中的位姿联系起来[3,4],这类方法在一定程度上提高独立帧计算的鲁棒性。Zhou等[5]研究将二维HOG特征的核基回归到三维位姿的方法。通过探究运动的后验信息来消除选择连续帧中的错误位姿,能够将这种歧义限定到一定范围内。然而,当这种错误在几帧中连续发生时,仅仅进行后期时序处理是不够的。
为解决遮挡和镜像对后期处理的影响,本文直接从输入序列中提取运动信息,提出一种位姿估计回归方法,可从位于中心的时空体中某一序列的给定帧中直接预测出三维位姿。本文找出连续帧中人群周围的边界盒。利用卷积神经网络(convolutional neural networks,CNN)方法进行运动补偿,将时空体中的连续边界盒关联起来,使目标始终保持在中央位置,提取改进时空特征,最后利用不同的回归法对位姿进行预测估计。主要工作包括:①结合外观信息和运动信息,提取多分辨率的时空特征;②利用CNN方法对人体进行运动补偿,提高位姿估计准确性。
1 整体体系
本文以骨架的形式呈现三维人体位姿。该形式能够更好地适应回归,且不需要知道人体目标的具体比例,同时可以使用时间信息解决方向问题。
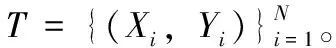
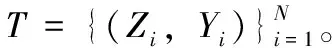
2 提出的方法
本文方法包含以下几个步骤:
(1)找出连续帧中人周围的边界框;
(2)进行运动补偿,使目标始终位于中央位置,形成修正时空体;
(3)从修正时空体中提取三维梯度方向直方图(histograms of oriented gradients,HOG)特征,作为修正时空特征(modified spatio-temporal feature,MSTF)。通过回归估计中央帧的人体三维位姿。
下面对主要步骤进行具体描述。
2.1 时空特征提取
本文提取的特征矢量Z以三维HOG描述符为基础,该描述符同时将外观信息和运动信息进行编码。首先将数据集细分为同等大小的多个部分;然后计算每部分的三维时空梯度直方图[6]。为提高特征描述能力,本文使用多尺度方法,即使用不同的尺寸计算三维HOG特征。本文在空间维度中使用3种等级(2×2、4×4和8×8);在时间维度上每个时间单元设定为较小值(对于每秒50帧的视频设置为4),以此来捕捉特征细节。通过将多种分辨率的描述符与单一矢量的描述符联系起来,获得最终的特征矢量Z。
2.2 运动补偿
三维HOG描述符表示人体位姿时,要求时间序列上各帧中人体部分位置相一致。这表明,在用于构建时空体的边界盒帧序列中,人应该始终处于中央位置。本文使用可变形部件模型(deformable part model,DPM)[7]检测器来获得这些边界盒,但事实上,这些边界盒可能并没有与人体很好地联合起来。因此,本文在生成时空体之前,对这些序列帧进行运动补偿。
运动补偿以人体目标为中心,训练回归器(本文选择CNN[8]作为回归器)来估计人在各序列帧中向中心位置的转换关系,将这些转换关系应用到各帧中,使目标始终处于中央位置。
假定m是从DPM返回的边界盒中提取的图像块,则所需的理想回归器φ(·)能够返回人从中心m:φ(m)=(δu,δv)移动的水平距离δu和竖直距离δv。为了更加有效地实现这一目的,本文引入两个不同的回归器φcoarse(·)和φfine(·)。训练第一个回归器处理大的移动,训练第二个回归器完成精细处理,两种回归器迭代使用。每次迭代后,用计算好的距离对图像进行转移,并进行下一次估计移动。通常这个过程需要4次迭代:两次φcoarse(·)和两次φfine(·)。
这两种CNN回归器具有相同的构架,均包含完全连接层、卷积层和池化层。池化层用于将回归器转变为小的图形转移,尽管其降低了需要的参数数量,但同时会降低定位性能。由于本文的目标是精准定位,因此,在第一个卷积层中并未进行池化处理,只在随后的层中使用。这有助于进行精准定位,同时保留较少的参数数量,以防止过度拟合。
进行CNN补偿时,需要对边界盒中的人进行初始估计,其由DPM实现。然而,将DPM探测器应用到序列中的每个人非常耗时;因此,本文只在第一帧中使用DPM,进行精确定位,得到的边界盒在第二帧中作为初始估计。之后,依次类推。
如图1所示,给出“打招呼”行为有运动补偿和没有运动补偿时的梯度热图。没有运动补偿时,梯度会分散到整个可能的区域中,降低特征的稳定性。进行运动补偿后,人体部分与帧中三维HOG单元相协调,所提取的时空特征处在中央位置,更加稳定。
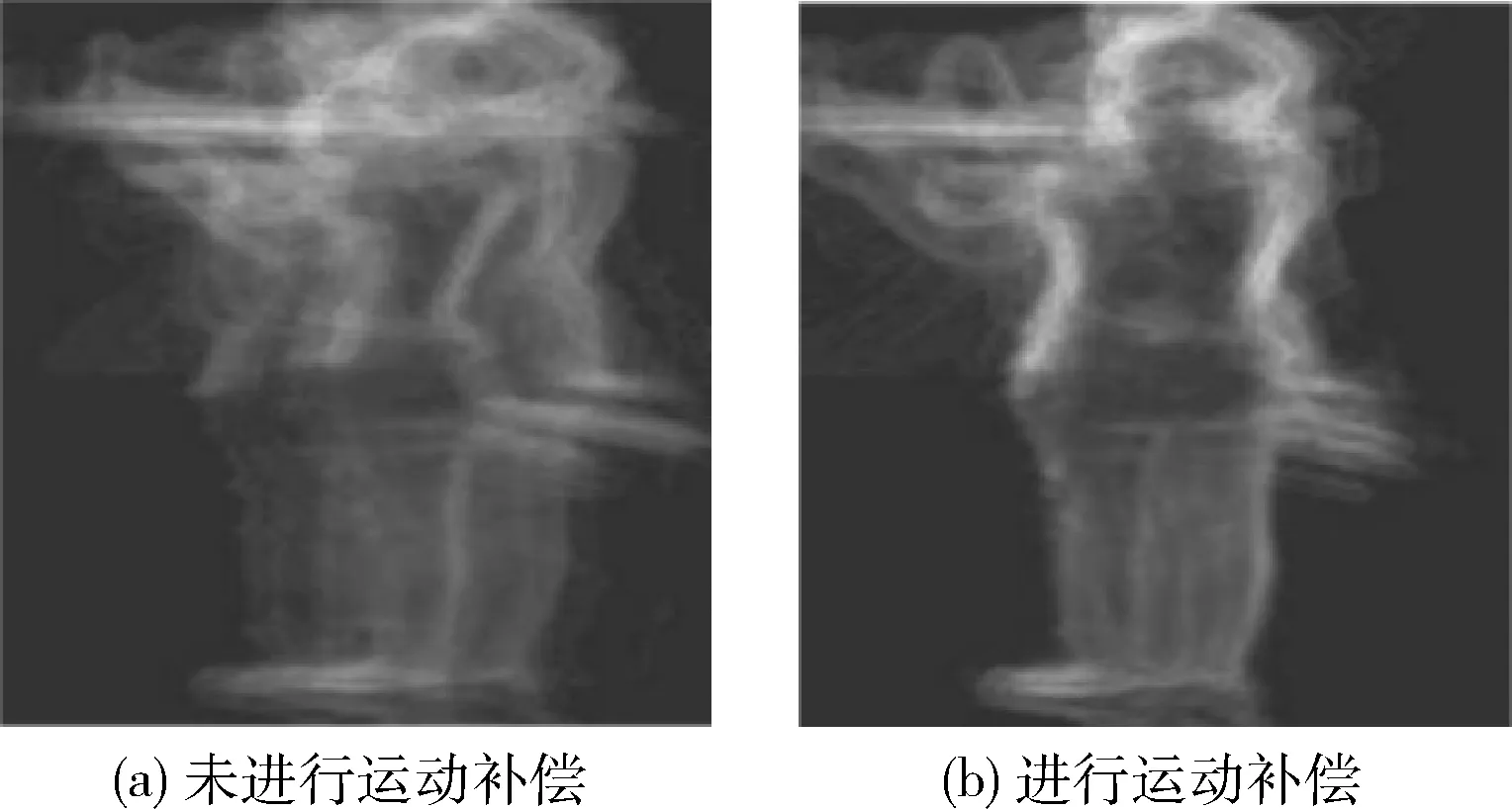
图1 进行运动补偿前后梯度热图
2.3 位姿回归
本文使用的三维位姿估计模型为Z→f(Z)≈Y,其中Z是提取的三维HOG修正时空特征,Y是中央帧的三维位姿。本文分别使用最小绝对收缩与选择算子(least absolute shrinkage and selection operator,LASSO)方法[9]、核维纳滤波(kernel Wiener filter,KWF)方法[10]和深度学习网络(deep learning network,DLN)方法来进行回归函数f研究。
LASSO方法为位姿矢量的每个维度均训练一个模型。为找到从时空特征到三维位姿的影射,其解决如式(1)所示的最小二次规划问题
(1)
其中,(Zj,Yj)是训练对,ΦZ是核基指数的傅里叶近似,该问题可以通过式(2)进行求解
W=(ΦZ(Z)TΦZ(Z)+I)-1ΦZ(Z)TY
(2)
KWF方法为有结构的回归器,其处理三维位姿空间之间的相互关系,分别使用核基影射ΦZ和ΦY,将输入和输出矢量转换至高维度Hilbert空间[11],根据高维度输入空间和输出空间之间的依存关系建模线性函数。用标准核岭回归来计算相应矩阵W,如式(3)所示
(3)
为了生成最终预测Y,进行式(4)处理,将高维度Hilbert空间中的预测与输出影射间的差异最小化
(4)
DLN方法以多层构架为依托,估计三维位姿的影射。本文在前两层中使用包含线性单位激活函数的3个完全连接层,在最后一层使用一个线性激活函数。前两层中每一层包含3000个神经元,最后一层包含与17个三维节点位置相对应的51个输出。本文通过交叉验证方法选择网络中的最佳超参数。本文将通过最小化预测与真实三维位姿的差值,获取由Θ参数化的影射函数f,如式(5)所示
(5)
3 实验结果与分析
本文对Human3.6m、HumanEvaI/II和KTH多视角足球II数据集进行实验。Human3.6m含有360万张图像及复杂移动场景中相应的三维位姿,包括4个不同视角下捕捉到的11个目标的15个不同行为;同时,人体形态、衣着、位姿和视角在训练/测试集中均有较大差别。Human-EvaI/II数据集提供的是合成图像和移动捕捉数据,为三维人体位姿估计的评价基准。KTH多视角足球II数据集是运动员移动时的抓拍图像,用于评价本文方法在野外环境时的性能。为了说明本文方法的有效性,与未进行运动补偿或其它三维位姿估计的代表算法进行比较。
3.1 Human3.6m数据集
目前的位姿估计方法普遍使用未进行运动补偿的二维HOG特征,并使用LASSO方法、KWF方法等方法进行回归,本文实验中称其为LASSO方法和KWF方法。本文利用运动补偿的三维HOG的修正时空特征MSTF,称作为MSTF+LASSO、MSTF+KWF或MSTV+DLN,以上3种方法使用的回归器分别为LASSO、KWF和DLN。为了评价位姿估计的准确性,本实验以预测位姿与真实位姿的平均欧几里得距离(以毫米为单位)为误差评价标准。
本实验对15个不同行为训练回归器,使用了5个目标(目标1、5、6、7、8)进行训练,两个目标(目标9、11)进行测试;训练测试时使用所有的摄像机视角。三维人体位姿均用17个节点的骨架表示,其三维定位与捕捉图像的摄像机坐标系统的根节点有关。
表1给出不同方法对Human3.6m数据集15种行为的位姿估计误差值。本文通过提取MSTF特征,对于LASSO方法,平均误差由181.30降低到150.26,降低了17%;对于KWF方法,平均误差由164.17降低到127.08,降低22%。可以看出MSTF特征可以显著提高位姿检测的准确性。比较结合MSTF特征的3种回归方法,MSTF+KWF和MSTF+DLN的误差值明显低于MSTF+LASSO方法。对于“买东西”、“坐”、“坐下”3种行为,MSTF+KWF方法的结果稍微好于MSTF+DLN方法;但对于其它行为,MSTF+DLN有更好的位姿估计准确性能,并且平均误差最低。

表1 不同方法的位姿估计误差结果
下面更加直观的对各种方法进行比较。图2给出传统KWF方法和本文MSTF+DLN方法的结果,第1~3行分别对应“买东西”、“讨论”、“吃饭”3个行为。可以看出传统的KWF方法的位姿估计结果中存在自我遮挡和方向歧义的情况,而本文MSTF+DLN方法的位姿还原结果的效果最好。图3给出结合MSTF特征的3种回归器,对“散步”行为的位姿估计结果,可以看出MSTF+KWF和MSTF+DLN方法的位姿估计结果较MSTF+LASSO方法更加准确,而MSTF+DLN与真实位姿更加接近。

图2 不同方法的位姿估计结果比较
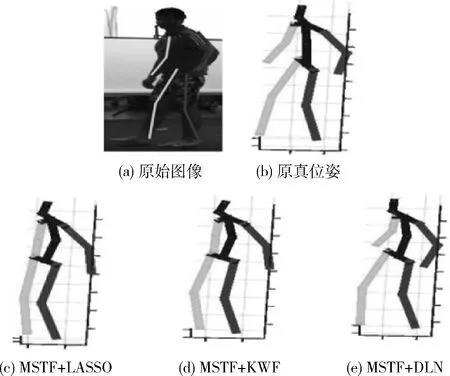
图3 提取MSTF特征时不同方法的位姿估计结果比较
为了说明运动补偿的重要性,下面对有无运动补偿的结果进行比较。未进行CNN运动补偿是直接提取时空特征,称作STF(spatio-temporal feature)。选择两种有代表性的行为进行比较,“遛狗”行为涉及大量移动情形,“打招呼”行为中的主体并没有太多走动。结果见表2,可以看出,即使未进行运动补偿,提取的STF特征结果优于传统的KWF方法;与STF相比,运动补偿MSTF进一步提高了位姿估计性能。
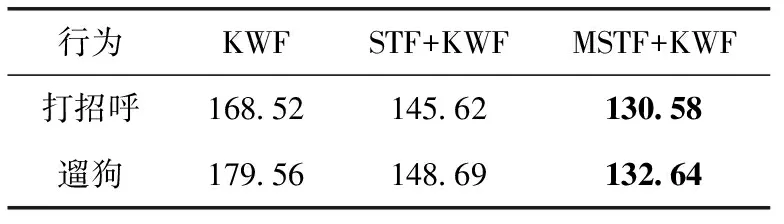
表2 有无运动补偿的误差结果
为说明临时窗口大小对位姿估计的影响,比较不同窗口大小情况下的结果。选择“行走”和“吃”两种行为进行比较,临时窗口大小从12帧调整到48帧,回归方法为MSTF+DLN,结果见表3。可以看出窗口大小在24帧~48帧的范围时,获得最佳的结果,即对于每秒50帧的情况,对应为0.5 s~1 s。临时窗口较小时,提取特征中的信息数量不足以进行精准估计;窗口太大时会造成过度拟合问题,因为计算输入数据中的差别显得更加困难。本文对于Human3.6m数据集的实验,窗口大小均使用24帧,其不仅可以进行准确的位姿还原,还可以进行有效的特征提取。
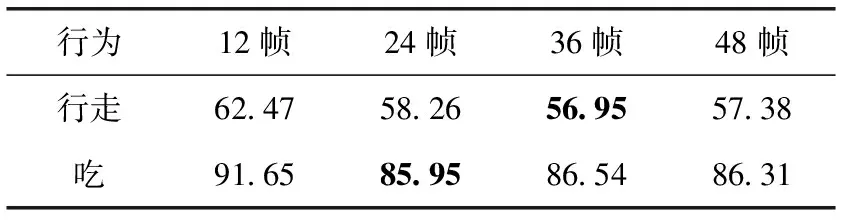
表3 不同临时窗口大小的误差结果
3.2 HumanEva数据集
由于HumanEva的训练集太小,不能用于训练深度学习网络,因此本实验主要使用MSTF+KWF方法与其它传统方法进行比较。本实验与Human3.6m数据集实验一样,使用预测位姿节点位置与真实位姿节点位置欧几里得的平均距离差值作为评价标准。
对于HumanEvaI数据集,本实验与文献[12]的二维位姿探测器、文献[13]的三维图像架构、文献[14]中依赖自上而下的动态优化方法进行比较。表4显示了不同方法对于“行走”和“拳击”行为的位姿误差结果。对目标1、2、3的训练序列选了不同的回归器,本文方法只从第一个摄像机视角计算时空特征。由表4可以看出,本文方法对于“行走”的循环运动和“拳击”的非循环运动中的位姿估计性能在此基准上均优于其它方法。
对于HumanEvaII数据集,本实验与文献[3]检测跟踪的方法进行比较。不同方法对于“combo”序列的位姿误差结果见表5。HumanEvaII数据集只有一个测试集,没有训练集,因此,本实验利用HumanEvaI数据集中不同摄像机视角拍摄的数据训练回归器,对HumanEvaII数据集进行测试,以验证本文方法对其它摄像机视角的泛化能力。本实验分别使用HumanEvaI数据集的目标1、2、3数据进行训练,对HumanEvaII数据集前350帧中目标2的位姿进行估计,估计误差结果如表5所示。可以看出本文方法的性能最佳,说明本文方法具有较好的泛化能力。
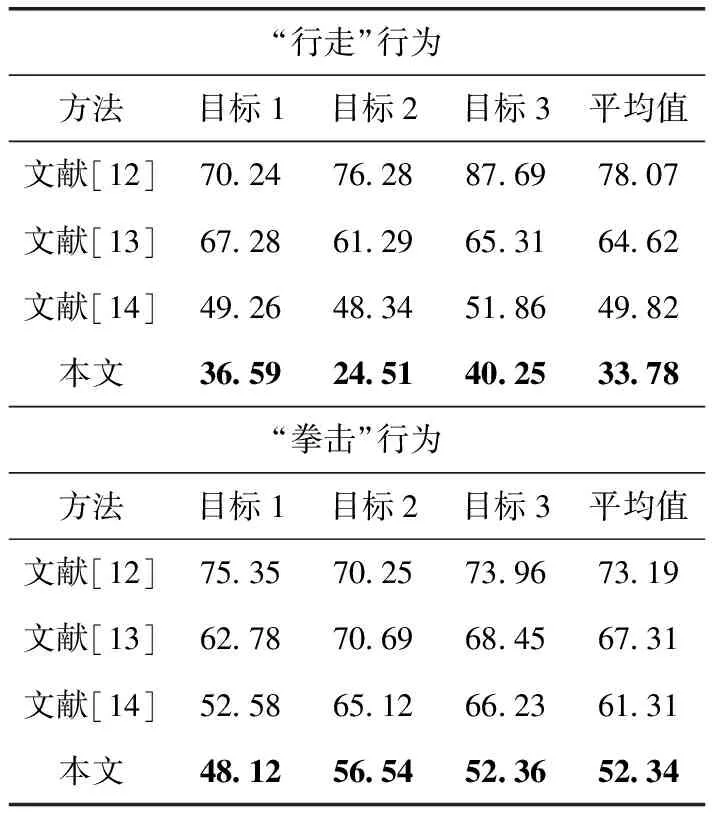
表4 不同方法在HumanEvaI数据集上位姿估计误差结果

表5 不同方法在“combo”序列的位姿估计误差结果
3.3 KTH多视角足球数据集
本实验对KTH多视角足球数据集的运动员2序列进行位姿估计;同HumanEva数据集一样,主要利用MSTF+KWF方法。该序列的前半部分用作训练,后半部分用作测试。本实验以正确估计部分得分为位姿估计准确性的评价标准,并与文献[3]的方法进行比较,结果如表6所示。可以看出,即使本文方法使用单目摄像机,而文献[3]使用双摄像机,本文方法的位姿估计结果更加准确。这是因为,文献[3]的方法依赖于二维人体部分探测,当外观信息较模糊时,位姿估计准确性受到较大影响。而本文方法从修改时空体中实时综合提取外观信息和运动信息,三维位姿估计的精准性更好。
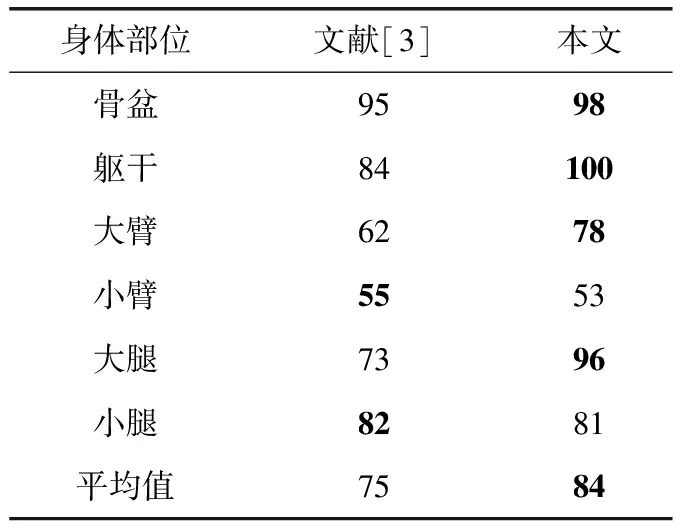
表6 KTH多视角足球集位姿估计结果
4 结束语
本文在位姿估计过程中,综合考虑外观信息和运动信息,并进行CNN运动补偿,建立修正时空体。该方法比利用后验信息连接单帧的位姿估计性能有很大提升。修正时空体在修改时空体中提取外观信息和运动信息,能够降低因自我遮挡或镜像的歧义。对于不同数据集,实验结果表明,本文方法的三维人体位姿估计准确性较其它方法有较大提高。即本文所提方法较为通用,可以应用于不同连贯运动中。
