卷积神经网络在短文本情感多分类标注应用
2018-11-17周锦峰叶施仁
周锦峰,叶施仁,王 晖
常州大学 信息科学与工程学院,江苏 常州 213164
1 引言
随着即时通讯技术的广泛应用,互联网用户不再只是简单的信息获取者,同时成为信息制造者。社交媒体的快速发展,加速了用户的这种身份转变,并形成了以短文本为书写特点的用户信息表达方式。例如,在电商平台发表对已购商品的点评;在微博上发表对时事的看法。每天数以亿计的用户短文本信息,包含了丰富的用户观点和情感极性,从中可以挖掘和分析出大量的知识和模式。自然地,机器学习方法可以用来解决这类情感分析问题。而这些社会媒体文本长度短、表达不规范、数量多的特点,导致传统机器学习方法面临样本特征表达稀疏[1]、计算复杂等问题,不能获得非常理想的结果。
深度学习给经典的数据挖掘任务提供了新的手段。卷积神经网络(Convolutional Neural Network,CNN)是一种用来处理具有网状拓扑结构数据的深度神经网络(Deep Neural Network,DNN)。CNN通过卷积操作,组合低层特征形成更加抽象的高层特征[2],使模型能够针对目标问题,自动学习良好的特征。CNN在文本情感分类问题中的应用,能够有效地避免传统机器学习方法所面临的问题[3]。
目前,以CNN为基础的文本情感分类方法广泛利用文本局部最大语义进行情感划分。此类方法在解决文本情感二分类标注问题中已取得良好的效果。人类的情感是复杂的,不是简单的正负极性可以描述,带来了处理多分类标注、连续情感计算等问题[4]。把情感二分类问题的深度学习方法推广到情感多分类问题后,以单一窗口提取局部语义特征和仅保留文本最大语义的方法会忽略语义距离依赖性和语义多层次性[5],将导致分类能力急剧下降。
针对网络短文本的情感多分类标注任务,本文提出一种新的多窗口多池化层的卷积神经网络(multiwindows and multi-pooling Convolutional Neural Network,mwmpCNN)模型来解决其中的语义距离依赖性和语义多层次性问题。该模型使用多个并行的卷积层提取不同窗口大小的上下文局部语义。局部语义表示向量经过模型的多个并行的池化层,降低特征维度的同时提取短文本中不同层次的语义特征。由不同层次的语义特征构成文本特征向量,最后在模型的全连接层利用文本特征向量实现多分类标注。
本文采用斯坦福情感树库(Stanford Sentiment Treebank,SSTb)数据集来验证mwmpCNN模型的多分类标注的有效性。实验结果表明:在训练集包含短语和未包含短语的两种设定条件下,基于本文模型的短文本情感多分类正确率分别达到54.6%和43.5%,显著高于报道的学习方法。
2 相关工作
2002年的EMNLP会议上,Pang等[6]首次提出情感分析问题,并采用了朴素贝叶斯模型、最大熵模型和支持向量机(Support Vector Machine,SVM)模型三种传统机器学习方法尝试对文本进行情感分类。此后,以传统机器学习为核心的情感分析模型层出不穷。为提高分类正确率,传统机器学习方法使用大量文本特征。随着特征变多,训练样本在每个特征上的描述会变得稀疏,机器学习的计算复杂性成倍增加。当然,文本特征需要人工来构造,特征越多,人工成本越大。
2003年,Bengio等[7]提出了分布式表达词向量概念,从大量未标注的语料库中无监督地学习出词向量,使得相关或相似的词在向量空间中表示接近。由词向量序列可以构成文本的原始表示形式。分布式表达词向量的出现有效解决了DNN的输入部分对人工的依赖,并推动了DNN发展出新模型应用于文本情感分类问题。Socher等[8]在递归神经网络(Recursive Neural Network,RNN)模型的基础上,提出了RNTN(Recursive Neural Tensor Network)模型。已知样本的语法解析树,RNTN模型在树中每个结点上运用基于张量的复合函数,逐层提取各级短语和句子的合成语义,然后基于合成语义进行情感二分类和多分类标注。RNTN模型过于依赖句子的语法解析树,应用范围受限。Santos等[9]基于单词的构造(以构成单词的字母为单位),提出CharSCNN(Character to Sentence Convolutional Neural Network)模型。CharSCNN模型以CNN为基础,采用两个卷积层分别学习单词的构造特征和句子的语义特征,充分体现CNN对文本局部特征抽象和提取能力。该模型在短文本情感二分类任务中展示了良好的效果。
尽管二分类效果良好,但是CharSCNN模型在特征提取过程中忽略了语义距离依赖性和语义多层次性。而网络短文本情感多分类标注问题,由于语料中文本通常很短,对于这两种语义特征异常敏感。这使得短文本情感多分类时,CharSCNN模型性能显著下降。针对这一问题,本文提出具有提取和保留更丰富语义特征能力的分类模型。
3 mwmp CNN模型
如图1所示,经典的CNN模型解决情感分类标注问题时,通常将一个句子或一段文本以某种形式(例如词向量序列)输入到CNN的卷积层。经过卷积操作,提取出文本的局部抽象语义;池化层对该局部语义表达进行降维,同时保留某一个级别的语义特征;串接层将这些语义特征向量拼接成一个句级或文本语义特征向量;全连接层对这个语义特征向量进一步抽象,最后计算出情感分析结果。
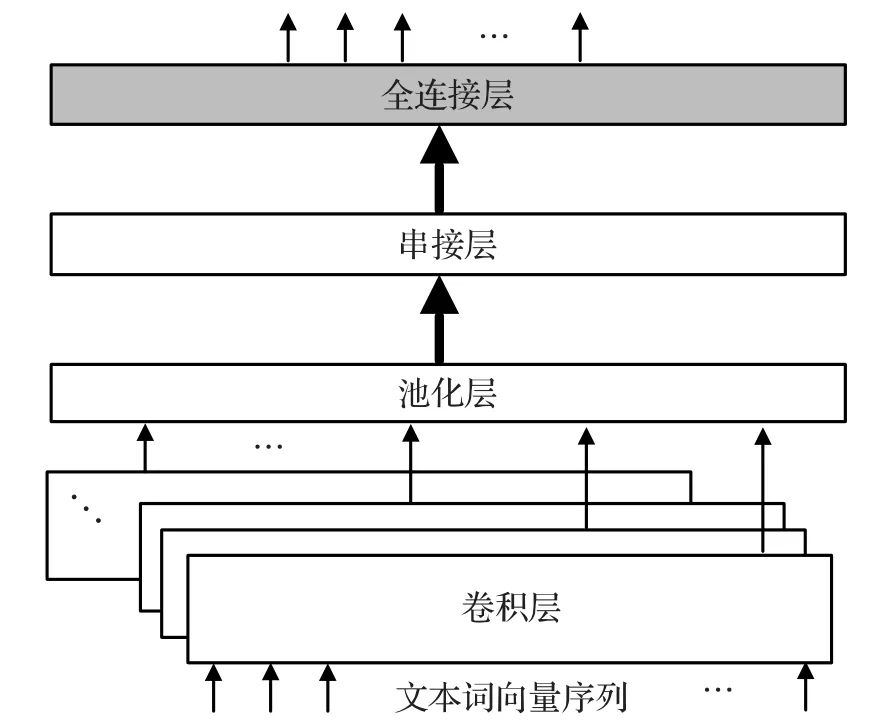
图1 CNN模型结构
本文针对网络短文本的情感多分类标注任务,对CNN进行改进,提出mwmpCNN模型。如图2所示,mwmpCNN模型使用多种卷积核提取不同窗口大小的上下文语义;然后这些上下文语义向量分别送入多种池化层,降低特征维度,同时尽可能地保留了多个层次的语义特征;串接层将多层次的语义特征向量串接成一个文本特征向量;全连接层对这个文本特征向量进一步抽象,最后计算对每个情感分类标签的分数。
3.1 词向量序列
词向量是词的分布式表示,将词表示为一个稠密的、低维度的向量,它包含一个词的语法或语义信息。

图2 mwmpCNN模型结构
给定由n个单词组成的一个短文本{Wrd1,Wrd2,…,Wrdn},转换每个单词为其对应的dwrd维词向量。设第i个单词Wrdi对应的词向量为xi,xi∈Rdwrd。该短文本可以表示成一个长度为n的词向量序列s={x1,x2,…,xn}。这个词向量序列作为mwmpCNN中卷积层的输入。
3.2 不同窗口大小的多卷积层
与n-gram模型[10]类似,CNN通常使用固定大小的窗口对文本的词向量序列进行一维卷积操作,提取局部语义。除非窗口放到数据集中最长的文本长度,否则固定大小的窗口只能捕捉固定距离上的语义依赖关系。如若放大窗口到最长文本的长度,则将导致数据稀疏、模型参数数量增大等问题。
文本分析研究早已指出文本的语义具有距离依赖性[11],这种依赖性在许多语言现象中起着重要作用,例如否定关系、附属关系等语言关系。语言关系隐式地影响情感分析的结果。网络短文本中长句子少,词义依赖的距离短。一个词仅与它附近出现的一个或几个词具有依存关系。因此,mwmpCNN模型采用多个窗口大小不同的卷积层对输入的词向量序列s进行卷积操作,提取不同窗口大小的上下文局部语义。
mwmpCNN模型在卷积操作时可提供m个窗口大小不同的卷积层,它们的窗口大小分别为{k1,k2,…,km},如图3所示。每个卷积层有cnt个卷积单元。卷积操作时,上述m×cnt个卷积单元将会并行计算,计算结果送至被分配的池化层。

图3 并行的多窗口卷积层
卷积单元计算时,kj窗口中第l个卷积单元(即第 j个卷积层中第l个卷积单元)的计算方法见式(1),其中0≤l≤cnt-1。
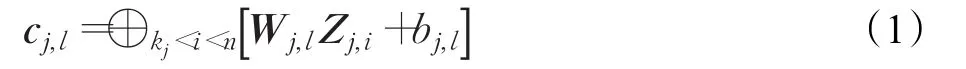
式(1)中,n为词向量序列s的长度;cj,l是以kj为窗口,对当前短文本的词向量序列,连续n-kj+1次卷积操作的结果产生文本局部语义向量,cj,l向量将落在维度为n-kj+1的实数空间中,即是kj窗口中第l个卷积单元的权重矩阵,Wj,l∈Rkj×dwrd;bj,l是 kj窗口中第l个卷积单元的偏置,bj,l∈R;矩阵Zj,i代表一个kj窗口的词向量组合。以s中第i个词向量xi为中心,矩阵Zj,i由xi前后各kj/2个词向量串接生成,即:

3.3 不同池化方法的多池化层
受作者创作时随意性、碎片性的影响,网络短文本所蕴含的情感异常丰富。一段文本中可能部分表达正面情感,部分表达负面情感。同时,文本各部分的情感强度又有差异。只有捕捉到多层次的文本语义特征,才能够分析文本的细粒度情感。
mwmpCNN模型在池化操作时设计了多池化层。并行的多池化层可对各卷积单元提取的局部语义进行统计汇总。池化操作过程中卷积单元产生的局部语义向量将被降维至固定长度。
mwmpCNN模型有t个并行的池化层,各池化层的池化方法不同,如图4所示。局部语义向量经卷积单元提取后,被送至指定的池化层进行池化操作。虽然模型实现时卷积单元的分配方法因人而异,但是每个窗口经池化操作后均产生固定的cnt个元素。为方便表述,本文认为由每个窗口经池化操作后产生的cnt个元素构成该窗口所对应的局部文本语义特征向量。对有m个窗口的卷积层,多池化层最终对应输出一个包含m个文本语义特征向量的序列vsent={v1,v2,…,vm}。这里,v1(v1∈Rcnt)为k1窗口所对应的局部文本语义特征向量,v2等依此类推。

图4 对各卷积单元输出进行多池化操作
设文本局部语义向量cj,l被送至池化层a,用于生成kj窗口所对应的语义特征向量vj的一个元素vj[l]。cj,l的池化过程为:

其中,pa为池化层a采用的池化方法。池化操作时,常用的池化方法有提取文本最强烈语义的max-pooling方法和提取文本平均语义的avg-pooling方法等。
3.4 串接层与全连接层
串接层串接操作vsent中每个元素,得到文本特征向量rsent∈Rcnt×m。串接操作为:

全连接层进一步抽象特征向量,为情感多分类T中的每个情感分类t(t∈T)计算得分。全连接层采用两层设计,即式(5):
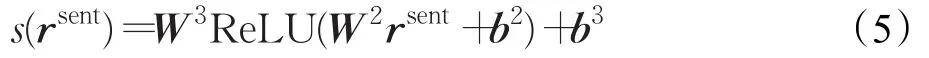
最后,mwmpCNN模型使用softmax函数计算词向量序列s在每个情感标签t下的得分,即:
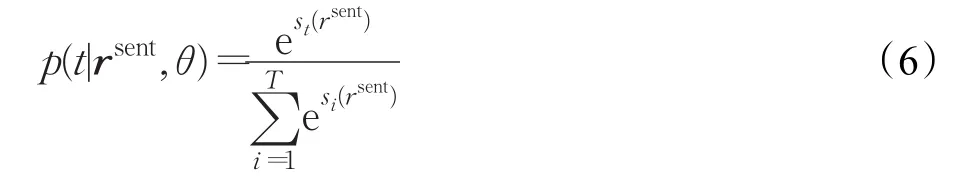
4 mwmp CNN模型训练
mwmpCNN模型是通过最小化负对数似然函数进行训练。对式(6)取对数:
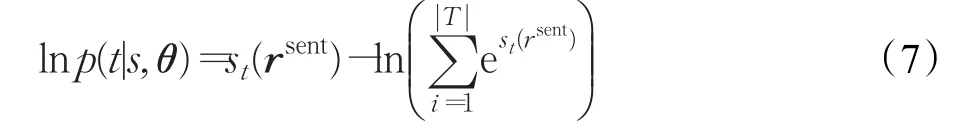
采用随机梯度下降(Stochastic Gradient Descent,SGD)算法来最小化负对数似然函数,得到:

其中,D代表训练语料;si、yi表示训练语料的一条句子及其对应的情感标签;θ表示模型所有参数。
由于网络短文本包含的上下文信息有限,噪声较多,过度拟合的语义关系是由训练数据集采样噪声产生,并不真实地存在于测试数据集中[12]。这个现象将降低模型的泛化能力。此外,SSTb数据集中用来做长句训练集的样本数量较少,在进行卷积神经网络模型训练时,过拟合现象比较容易发生[13]。因此,训练过程中,本文在mwmpCNN模型的输入层和全连接层使用Srivastava等人[12]提出的Dropout技术,有效地防止过拟合,明显降低泛化误差。
5 实验
5.1 情感分析数据集
SSTb的语料内容来源于在线影评,属于网络短文本[8],它包含11 845条句子和227 385条短语,其中短语由句子的语法解析树产生。数据集有句子和短语的情感实证概率。根据分类标准界限[0,0.2],(0.2,0.4],(0.4,0.6],(0.6,0.8],(0.8,1.0],情感实证概率可映射到五分类中,即表达非常负面、负面、中性、正面、非常正面的情感。
实验时,本文设置有两个训练集和一个测试集。其中,训练集A只包含句子,训练集B包含句子和短语,测试集则只包含句子。实验用数据集划分见表1。

表1 SSTb数据集实验数据划分
5.2 模型参数设定
本文训练集上使用五倍交叉验证(Cross Validation)确定以下超参数:卷积层的窗口大小{k1,k2,k3,k4}、每个卷积层所拥有的卷积单元数量cnt以及词向量维度dwrd。综合考虑小窗口有利于捕捉细节特征和大窗口有利于捕捉远距离上的语义依赖性,从{2,3,5,7}、{2,3,7,9}和{3,5,7,9}中选择{k1,k2,k3,k4},从{50,100,200,300}中确定cnt,dwrd则从{25,50,100}中选取。这3个参数构成36种不同的参数组合,使用网格搜索方法(Grid Search)确定优化以上超参数。对于其他超参数:hlc是全连接层中隐藏层神经元数量,与隐藏层的输入向量维度有直接关系[14],本文模型的隐藏层输入向量rsent维度为4×cnt,为了随着rsent维度的变化调整hlc的值,直接设定hlc为4×cnt。参照其他基于CNN的文本分类模型使用Dropout的设置[15-16],以 p=0.5的概率随机保留输入层的输入和全连接层的隐藏单元。||D为每个训练批次包含的样本数,实验中固定为64。所有超参数的设定值见表2。
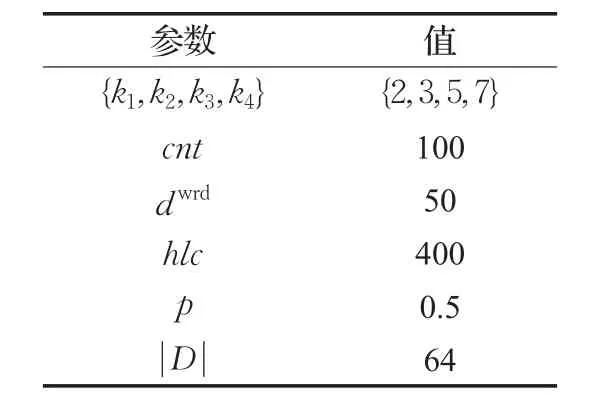
表2 mwmpCNN实验超参数设定
5.3 词向量预训练
本文在实验中使用两种词向量:经过预训练的词向量和未经过预训练的词向量。在训练过程中,这两种词向量都作为可训练参数进行调整。
实验选择GloVe算法[17]进行词向量预训练。因Twitter与SSTb同属社交网络文本,Twitter语料库的词语空间分布接近于SSTb的词语空间分布,所以本文词向量预训练使用Twitter语料库。
词向量训练后,本文得到一个包括一百多万条目的单词表。对于SSTb中未出现在单词表中的单词,实验时使用零向量代替。
对未经过预先训练的词向量,向量中每个值由均匀分布在区间(-0.01,+0.01)的随机数初始化[18]。
5.4 mwmpCNN结构设置
实验中的mwmpCNN模型结构具体设定如下:
mwmpCNN模型卷积操作时有四个并行的卷积层,其窗口大小见表2。池化操作时有两个并行的池化层。池化方法采用max-pooling方法和avg-pooling方法。每个卷积层内有一半的卷积单元的输出送到avg-pooling池化层,另一半的卷积单元的输出送到max-pooling池化层。
为了有效地对比实验结果,本文还基于mwmpCNN模型的两种特殊结构进行实验。一种特殊结构为单窗口多池化结构,即swmpCNN(single-windows and multipooling Convolutional Neural Network),该结构中窗口大小只有一种,设定为3,其他部分设定与mwmpCNN一样。另一种特殊结构为多窗口单池化结构,即mwspCNN(multi-windows and single-pooling Convolutional Neural Network),该结构中只有单一池化方法的池化层,池化方法为max-pooling,其他部分设定与mwmpCNN一样。
5.5 实验结果
实验机器选用Intel I5-4200的CPU,8 GB内存,256 GB的SSD硬盘,Linux操作系统。经过约20小时的运行得出实验结果。
mwmpCNN模型在SSTb数据集上执行情感五分类标注的结果见表3。表中“预训练”一栏标识为“是”,表示模型使用的词向量经过预训练;标识为“否”,表示使用的词向量采用随机值初始化。“短语”一栏标识为“是”,表示训练集包含短语,标识为“否”,表示训练集中不包含短语。为了比较和论证,表3中还含有Socher[8]使用RNTN、RNN及SVM模型,和Santos[9]使用CharSCNN、SCNN模型在SSTb数据集上进行情感五分类标注的正确率。
5.6 实验结果分析
5.6.1 mwmp CNN模型与其他模型比较
从表3中可以看出,训练集中未加入短语的情况下,mwmpCNN、CharSCNN和SCNN的分类正确率持平(43.5%)。而在训练集加入短语后,mwmpCNN的正确率(54.6%)要超过文献[8]和文献[9]所报道的结果。
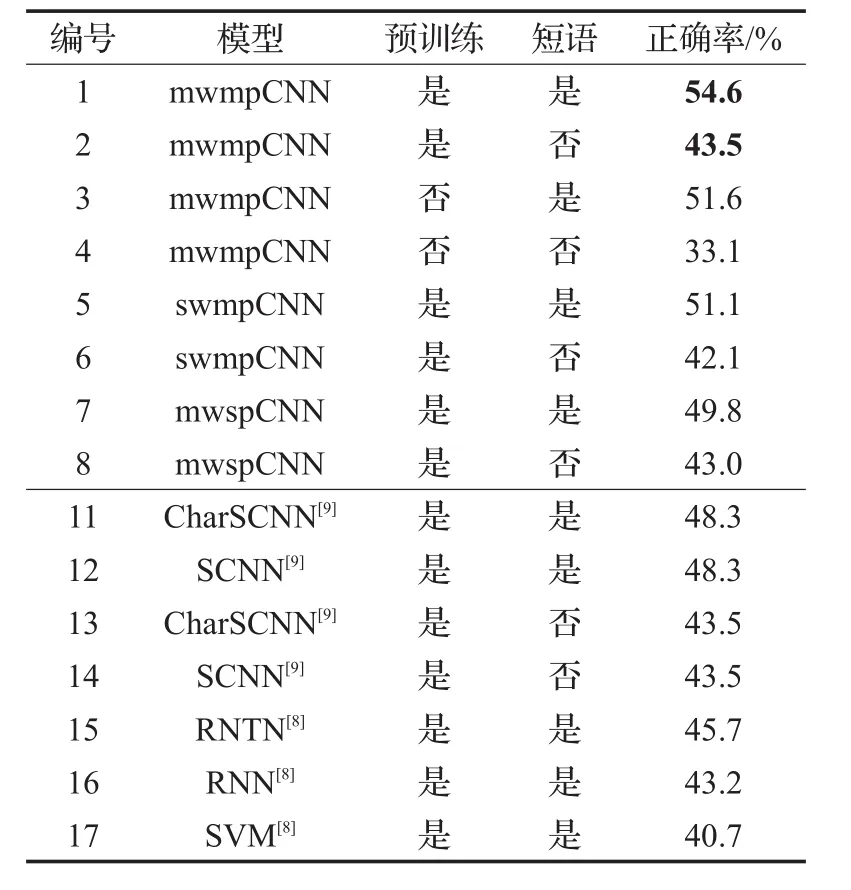
表3 在SSTb数据集上不同模型实验正确率
通过实验可以看到,当训练数据集中加入了短语后,mwmpCNN性能提高(如测试1和测试2对比,测试3和测试4对比)会比CharSCNN(如测试11和测试13对比)和SCNN(测试12和测试14对比)要快。其中的原因可能是,当训练样本达到一定数量后,比仅仅使用一种窗口大小的卷积层和max-pooling池化层的设计,mwmpCNN可以学习到语义表达更精确、层次更丰富的文本特征向量,使全连接层能够有效地计算文本的细粒度情感。
对于不使用短语训练的一组测试,即测试2、测试6、测试8、测试13和测试14,正确率均相差不大,可能是因为在不使用短语训练情况下,训练集数量相对于需要训练的模型参数不足,不能有效地反映模型效果的差别。
5.6.2 不同窗口大小卷积层的影响
对比测试1(54.6%)和测试5(51.1%),测试2(43.5%)和测试6(42.1%)两组实验的正确率,无论训练集含有或未含有短语样本的情况下,使用多窗口mwmpCNN的正确率高于使用单窗口swmpCNN,特别在训练集含有短语样本的情况下,这种提高比较明显。说明当训练样本达到一定数量后,多种窗口大小的卷积层提取的多种局部特征[19],有效地捕捉多种距离上的语义依赖性,有助于更精确地计算文本在每个情感标签下的得分。下面的例子说明在远距离上的语义依赖性对整个句子情感的影响:
(1)at all clear what it's trying to say and even if it were--I doubt it.
(2)at all clear what it's trying to say and even if it were--I doubt it would be all that interesting.
可以看出(2)的负面情感程度比(1)要弱一些,因为doubt后面四个词距离上的all影响了它的强烈程度,从而影响了全句的负面情感的强烈程度。(1)的真实分类是负面,而(2)的真实分类是中性。
5.6.3 多种池化方法的影响
对比测试1(54.6%)和测试7(49.8%),测试2(43.5%)和测试8(43.0%)两组实验的正确率,无论训练集含有或未含有短语样本的情况下,使用多池化mwmpCNN的正确率高于使用单池化mwspCNN,特别在训练集含有短语样本的情况下,这种提高非常明显。多种池化方法保留的多层次语义特征对细粒度情感的判断是很重要的。以SSTb数据集中的句子为例:
The storylines are woven together skillfully.|0.5972 2
以大小为3的窗口将该句分割成四个短语,短语及对应的实证概率值如下:
(1)The storylines are|0.5
(2)storylines are woven|0.5
(3)are woven together|0.569 44
(4)woven together skillfully|0.777 78
可以看到一个句子包含着不同语义层次的短语,它们都会对整个句子的情感倾向产生影响,因此仅保留一种语义层次很难精确地判断文本情感倾向。
5.6.4 词向量的影响
由于词向量是mwmpCNN的可训练参数,训练过程实际上也在调整词向量,使其更适合情感多分类任务。如表3所示,mwmpCNN模型使用预训练初始化词向量的两组实验正确率要高于使用随机数初始化的词向量。特别是只使用句子进行训练时,使用预训练初始化词向量比使用随机数初始化词向量的实验正确率提高10.4%(测试2和测试4对比)。这表明经过预训练的词向量包含大量先验知识,这个先验知识能够有效地提高情感分析的正确率。而且仅包含句子的训练集中只有8 000多条样本,不足以充分地从“零基础”训练词向量。同时表3也显示,当加入了短语到训练集时,使用预训练初始化词向量的实验正确率只比使用随机数初始化词向量的实验提高3%(测试1和测试3对比)。这是因为包括短语和句子的训练集含有23万多条样本,已经可以较好地从“零基础”训练词向量,而且这种训练是针对本分类问题进行的专门训练,所以当训练集中加入短语,正确率提升很多。当训练样本数量足够大时,用随机数初始化的词向量和预训练初始化的词向量作为输入,标注正确率相差可能会很小。需要注意,从实验过程中可以得知:相比使用预训练初始化词向量,当mwmpCNN使用随机数初始化词向量,模型完成训练过程需要更多的训练批次。
5.6.5 短语的影响
如表3所示,使用短语训练模型比不使用短语训练模型正确率有较大的提高。在使用预训练初始化词向量的情况下,正确率提高11.1%(测试1和测试2对比)。而在使用随机数初始化词向量的情况下,正确率提高达到18.5%(测试3和测试4对比)。如果既没有预训练初始化的词向量,也没有短语参加训练,模型能够学习的先验知识是非常有限的,这种情况下实验的正确率是非常低的(33.1%)。这表明:由语法分析树生成且已经完成情感标注的短语,作为训练样本加入到训练集后,虽然在训练过程中没有直接使用语法分析树的信息,但依然有助于提高模型正确率。这些短语给出它们如何形成句子情感的信息,使得模型可以在训练过程中学习到更复杂的现象[9]。
6 结束语
网络短文本的情感多分类标注对于语义特征敏感。针对这一特点,本文提出一种能够有效地捕捉语义距离依赖性和多层次语义特征的CNN改进模型mwmpCNN。它使用窗口大小不同的多个卷积层,抽象出包含不同窗口大小的上下文局部语义;同时使用多种池化层在局部语义基础上提取和保留多层次的语义特征。实验结果可见该模型和其他模型比较,在正确率上有显著的提高。
尝试通过调整超参数和模型部分结构,探索mwmpCNN在中文情感多分类标注问题的应用,是下一步的工作。
