基于改进ACO与分布式社区检测的WSN路由协议
2018-11-17朱利民
朱利民,赵 丽
1.河南工学院 计算机科学与技术系,河南 新乡 453000
2.山西大学 软件学院,太原 030013
1 引言
无线传感器网络(Wireless Sensor Network,WSN)由一系列配备微处理器、微型传感器和低功率无线电设备的低成本设备组成,它可以实现数据的传输和处理[1-2]。基于WSN的节能路由协议可以被分类为基于分层和基于聚类的协议[3],这些协议都依赖于被称作簇头(Cluster-Head,CH)的特殊节点。尽管上述协议有许多优点,但它们大多缺乏可扩展性。因此,在大规模无线传感器网络中,实现数据传输的负载均衡和高可靠性,仍然是一个挑战。
在WSN中,一般通过多径路由方案[4-5]解决上述问题。文献[6]介绍了几种基于蚁群优化算法(Ant Colony Optimization Algorithm,ACO)[7]的WSN路由协议。文献[8]提出一种多宿主路由协议SDG,通过在WSN中使用多个接收器来克服可伸缩性问题,但该方法增加了路由的能量消耗。文献[9]提出了一种应用于多媒体WSN的适应性T-ANT路由协议,称作AntSensNet。AntSensNet协议具有三个阶段:信息更新阶段、集群设置阶段和稳定阶段。在前两个阶段里,簇形成在接收器中发起,向多媒体传感器节点广播有限数量的代理,称为簇蚂蚁(CANT),集群的形成通过汇聚点发起。在接收到CANT消息之后,成为簇头的每个多媒体传感器节点将CANT消息转发给另一簇头节点候选者,直到形成簇头和汇聚点骨干网。在稳定阶段,通过使用不同的代理产生簇头和汇聚点之间的路径。代理机制的使用一定程度上增加了算法的复杂度。文献[10]提出一种基于社群检测的WSN路由协议,利用分布式概率选择簇头,以增强社群内部节点与簇头节点间的连通性,增加网络寿命,然而该算法的数据吞吐量有待进一步提高。文献[11]提出一种聚类算法和社团检测算法相结合的路由协议,通过社群聚类策略,可以延长无线传感器网络的寿命,但聚类算法的使用使得该算法的能量消耗较大。
本文提出了一种基于改进蚁群优化算法与分布式社区检测的WSN路由协议,其主要创新点如下:
(1)将改进蚁群优化启发式算法和分布式社群检测的标签传播(Label Spread,LP)算法[12]相结合,以分布式、平衡和自主的方式建立社群(集群),而不需要事先定义集群的数量/百分比、簇头(CH)数及额外的变量。
(2)为了使协议能够在大规模网络中应用,在协议中使用了社群内重传和社群间多径传输方法,最终数据传输的可靠性和负载均衡性有了显著提高。
2 协议说明
2.1 网络模型
本文将WSN表述为一个基本的无向加权图。定义G=(V,E,W)是一个简单的加权图。其中,V是一组节点,用正整数1到||V 表示,用于表示传感器和汇聚点。E是由边构成的集合,表示为ei,j,对于每个ei,j∈E,可以通过两个节点的剩余能量函数计算并估计它们的传输能量开销wi,j∈W。
本文还定义了一个部署函数φ:V↦ℝ2,用于在ℝ2空间中放置节点。因此,为了定义给定节点的邻居,需要先根据给定节点的传输能量确定其最大传输半径R。令d(i,j)表示φ(i)和φ(j)之间的欧氏距离,其中i,j∈V,Ni={j∈V|d(i,j)≤R,i≠j}表示通信范围为 i的节点的集合。假定所有节点都具有相同的传输功率,且在i∈Nj和 j∈Ni之间存在一个双向的信道。
此外,本文提出的算法还使用了网络中社群的概念。社群可以表示为一组高度相关的节点的k路分支。社群除了被表示为,在本文中还表示为Vs,其中s是汇聚点。
2.2 改进的蚁群优化算法
传统的蚁群算法局部搜索寻优能力较好,但算法在后期容易出现搜索速度减慢的现象,甚至会停滞不前。为此,本节提出一种改进的蚁群算法,以提高蚁群算法的寻优速度,同时增加WSN的网络寿命。
在搜索过程中,信息素会越来越少,此时有必要计算出信息素的挥发量。充分利用搜索路径中消耗的能量和WSN节点剩余能量,以避免WSN节点出现过早休眠的现象,影响路径中的信息传输。基于此,在搜索过程中使用了位置带的概念,使蚂蚁在不同节点之间的移动具有一定的方向性,这么做能够使蚂蚁准确地寻找移动路径,节约能量。如图1所示,如果WSN节点位于位置带n处,当该节点有转发蚂蚁的需求时,其下一跳节点只能从其本身和位于位置带n-1处的节点中选择。图1给出了4个位置带,其中节点A位于位置带n中,A的邻居节点分别是B、C、D、E和F,如上所述,只有节点C、D和E可作为A的下一跳节点。使用这种方法选择下一跳节点能够避免处在和Sink节点(汇聚点)方向相反的位置带n+1中的节点转发蚂蚁,同时,蚂蚁到达Sink节点的过程中所需的跳数以及消耗的能量也会减少。
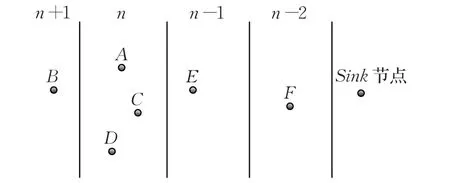
图1 蚂蚁转发示意图
另外,基于信息素,本文将抵抗素的概念应用到蚂蚁转发中,使用信息素和抵抗素得到蚂蚁转发的启发信息。利用WSN中的多个节点分担信息传输过程消耗的能量,以此来均衡每个节点的能量[13]。把信息传输时消耗的能量和WSN节点剩余能量联合起来作为评价构造路径的要素,在计算最终的信息素时就会更加准确。当某一个路径存储的能量较多时,有可能会出现该路径上的能量过度消耗,改进措施则可以避免该现象的出现。
图2所示为改进蚁群算法的影响因素关系,可以看出,在选择下一个节点时,节点剩余能量是算法考虑的主要因素,并且路径的信息素值也受节点剩余能量的影响。改进算法在选择下一个节点时,同样使用了筛选策略,当节点处在特定区域或者其能量满足一定要求时,才能成为符合条件的节点。抵抗素概念的引入也会对下一个节点的集合产生影响。改进蚁群算法的主要贡献是对下一个节点的选择更加精确,优化了算法性能。
2.3 协议概述
对于由传感器节点和汇聚点组成的传感器网络。本文提出的协议具有两个阶段:建立阶段和稳定阶段。建立阶段是在协议操作开始时仅运行一次的阶段,而稳定阶段持续运行直至WSN的功能结束。

图2 改进蚁群算法的影响因素
在建立阶段,协议的第一步是通过社群检测过程识别传感器的社群结构,本文所使用的方法是节点标签传播算法(Vertex Label Propagation Procedure,VLBP)[14]。VLBP以异步分布式的方式运行,仅使用每个传感器节点i∈V的邻居信息。在VLBP执行结束以后,每个社群都被一个作为社群标签的数值所标识,这一数值通常由其成员选择。
一旦形成了社群,协议的下一步就是建立这些社群与汇聚点的层级关系。在这一步中,使用了社群分层传播算法(Community Hierachy Propagation,CHP),将不同的社群分配到不同的层级,算法过程在下文中详细描述。这些层级考虑了社群与汇聚点之间的距离。社群在其边缘收缩到最大值后可以被视作超级节点,在这种情况下,社群与汇聚点的距离就是一系列超级节点到汇聚点的最短距离。
在CHP中,节点间通过传播社区层次结构消息(Community Hierarchy Message,CHM)以设置社群的层次结构级别。传播过程从汇聚点开始,初始的级别设置为0。接下来,这一消息在网络中以泛洪的形式传播,每当遇到一个新的社群,级别值加1。在CHP过程结束时,网络已经完成了分级。在某一社群中的所有传感器节点具有相同的社群级别。分级可以使每一个社群很快发现与相邻的较低层级的社群直接相连的节点,这些节点被称作虚拟汇聚点(Virtual Sink,VS)。
建立阶段的最终步骤,被称为社群内部构建(Intra-Community Setup,ICS)。在ICS中,每个被识别为社群内虚拟汇聚点的节点都会在其社群内发送一个虚拟通知消息(Virtual Announcement Message,VAM),其目标是获得传感器节点的路由表以及与社群的其他VS的开销。VAM具有每个节点d∈VS的识别编号(vsID)、VS的社群标签以及当前位置到VS的距离(vsDist)。对于一个传感器节点i,当它从一个邻居 j处获得一个VAM后,会比较其接收到的VAM与VS节点的距离与存储在路由表中的距离RT.DistVSi,j,d。这一距离和下一跳以及目的对{j,vsID:d=vsID}有关。如果接收到的VAM中的distVS值较小,就会更新RT.DistVSi,j,d。在更新阶段,节点i创建一个它所接收到的VAM的副本,在这份副本中会将distVS的值传送给它的下一个邻居。在VAM传播过程结束后,每个传感器i都会根据路由表中每一个下一跳终点初始化它的信息素权重τi,j,d∈RT,其中τi,j,d=1/RT.distVSi,j,d。
协议的稳定阶段包括三个异步执行的过程,分别是信息素浓度蒸发、社群内路由(Intra-Community Routing,ICR)和社群间可靠传输(Inter-Community Reliable Transmission,ICRB)。信息素浓度蒸发过程基于一个预定义的信息素浓度衰减参数,对传感器的路由表中每个记录的信息素浓度进行周期性的衰减。
在ICR过程中,协议依靠分布路径决策方法向每个目的地发送前向信息。在这一过程中,使用代理数据消息(Agent-Data Message,ADM)通过动态多径来传递感兴趣的信息到多个虚拟汇聚点,并更新传感器的路由表中路径信息。每个ADM的副本都包含着源传感器节点ID、终点ID(VSid)、当前路径中下一跳的ID以及路径的累积剩余能量。路径的累计剩余能量可以通过对路径中每个传感器节点的剩余能量求和得到。在接收到一个ADM之后,一个中转传感器根据由式(1)给出的概率 p,自主地决定到达ADM所指示的虚拟汇聚点的路径的下一跳。

其中,i∈V是一个到达局部虚拟汇聚点的路径中的一个中转节点;d∈V;τi,j,d表示节点 j到d的下一跳的信息素浓度。因此,节点i在重新将ADM传送给下一跳节点 j之前,会先更新路径和累积剩余能量。一旦ADM到达了终点的虚拟汇聚点,虚拟汇聚点会将ADM拷贝到输出缓冲区,并将它发送给靠近汇聚点的下一个社群。之后,虚拟汇聚点会根据式(2)计算路径质量:

其中,w是一个(v0,d)路径,也就是一条v0和d之间的路径;Eˉ(w)是w中节点的平均剩余能量。最终,一个虚拟汇聚点在一个反向通路中传送反向代理信息(Backward Agent Message,BAM)。如果源节点在相同的社群中,BAM 就会被发送给源节点,否则,它将会被发送给相邻的低级社群。BAM 包含的信息有路径w、中转节点ID、目的节点 j以及路径质量q。因此,路径中的每个节点(j∈W,i≠j)都可以根据式(3)来更新信息素浓度τi,j,d。

式(3)的意义在于强制使用具有最佳关联的剩余能量和路径长度的路径。
稳定阶段的最后一步是社群间的可靠传输。在这一阶段,一个携带着可靠数据消息RDM的数据包被发送给靠近汇聚点的下一级社群。这些信息可能包含聚合的或者不聚合的ADM信息。一旦终点正确接收到了ADM,就会回传一个可靠确认信息(RAM),如果RDM受到干扰,终点节点不会做任何动作。经过特定的时间后,虚拟汇聚点会注意到缺少确认信息,并重传RDM。
2.3.1 节点标签传播算法
节点标签传播算法(VLBP)旨在通过考虑节点邻居的共识对网络中节点进行标记。算法1给出了VLBP算法的伪代码,每个传感器都使用这一算法定义其自身的标签。
算法1节点标签传播算法(VLBP)
1.初始化标签集L={1,2,…,|V|}
2.令mylb为L中任意值
3.令mylt为false
4.执行
5. 设置m为(mylb,mylt)
6. 广播(m)
7. 重置timer
8. 当timer<tmax时
9. 如果接收到消息m′,则
10. 将lt和lb设置为m′中提取的值
11. 如果true==lt,则将lb加入B
12. 否则,将lb加入A
13. 结束
14. 结束
15. 如果A⋃B=∅则
16. mylt=true
17. 否则
20. 如果nlb==mylb,则mylt=true
21. mylb=nlb
23. 结束
24.直到mylt为空
在这一过程的开始阶段,每个节点v都被随机分配了一个标签。变量mylt始终跟踪着当前节点标签的状态,如果这一标签不是最终标签,则其值为false,如果这一标签是最终标签,那么它的值就为true。之后,节点v广播一个消息m用于通告它的标签和状态。接下来,就会开始三个主要阶段的循环,这一过程由变量timer和一个最值tmax控制。第一阶段会创建一对标签集合A和B,A中包含了尚未完全确定标签的邻居,B由已拥有永久标签的v的邻居组成。这些集合由第8行至第13行的循环生成。
如果A或者B不是空集,就会开始第二阶段。否则,当前v的标签就定义为节点的最终标签并结束这一过程。在第二阶段中,大多数A⋃B中的标签都在Maj中定义。为了描述这一步,定义一个函数c:L→ℤ返回一个标签在给定集合中的重复次数。在第三阶段中(第17行至第23行),节点从集合Maj中随机选择了一个标签,如果这个集合的A和B中有标签,就只会考虑B中的标签。之后,集合A被定义为空集,这是因为节点广播消息只有在它的标签完全确定以后才会发出。
2.3.2 社群层次传播过程
算法2描述了社群层次传播过程(CHP),定义了某一社群中节点与汇聚点间的距离。分层级别由社群分层消息(CHM)确定,这一消息由源ID(srcID)、源社群标签(srcLB)和源社群级别(srcLV)三部分组成。
算法2社群分层传播过程(CHP)
1.令i∈V
2.令LBi是执行完VLBP过程后节点vi的标签
3.令LVi是节点i的分层级别
4.令LVNi是每个 j∈Ni的分层级别集合
5.如果i是汇聚点,则
6. LVi=0;生成CHM m:=(i,LBi,LVi);广播m
7.否则
8. LVi←∞,根据应用设置chpTimer
9. 执行
10. 如果从任意 j∈Ni接收到了m',则
11. LVNi[j]=m′.srcLV
12. 如果 m'.srcLB=LBi,则
13. 如果 m'.srcLV<LVi,则
14. LVi=m'.srcLV
15. 生成CHM m:=(i,LBi,LVi);广播m
16. 结束
17. 否则m'.rcvLV+1<LVi,则
18. LVi=m'.rcvLV+1
19. 生成CHM m:=(i,LBi,LVi);广播m
20. 结束
21. 结束
22.直到chpTimer超时
23.结束
在算法2执行的开始阶段,每一个节点i∈V都具有一个由VLBP过程所产生的社群标签LBi,表明这一节点属于某一社群。算法2执行的结果是确定每一个节点连接到汇聚点的社群分层级别,也就是所有属于这一点邻居(LVNi)的节点集合的分层级别。
2.3.3 社群内配置过程
算法3展示了社群内配置过程(ICS),在这一过程中,每一个非汇聚节点都根据它的邻居信息决定其是否为自己所属社群内的虚拟汇聚点。节点i是一个虚拟汇聚点,如果它具有一个以上的邻居 j,并且这一邻居节点的社群标签LBj≠LBi,则社群分级LVj<LVi。然后,所有的虚拟汇聚点会在其社群内广播一个VAM,从而对其社群内的每一个非虚拟汇聚点的路由表(RT)进行初始化。一个VAM头包含如下结构:源ID(srcID)、虚拟汇聚点ID(vsID)、虚拟汇聚点社群标签(vsLB)以及当前位置到虚拟汇聚点的距离(distVS)。在算法3所示的过程中,第9至30行对于任意节点i∈V的路由表RT,配置了一组可用的虚拟汇聚点(dinVSset)及到达这一节点的下一跳 j的开销τi,j,d。虚拟汇聚点的集合是数据消息可能到达的局部终点的集合。
算法3社群内配置过程(ICS)
1.令i∈V,i不是汇聚点
2.令LBj是节点 j的标签,∀j∈Ni
3.令LBset,i是节点i观测到的节点 j标签的集合,∀j∈Ni
4.令LVi是节点i在经过CHP过程后的分层级别
5.令VSset是节点i可达的社群虚拟汇聚点的集合
6.令RT是节点i的路由表
7. 如果 ∃LBj∈LBset,i且 LBj≠LBi,LVj<LVi
isVS=true;否则,isVS=false
8.如果LVi<∞则nodeready=true;否则nodeready=false
9.如果nodeready==true,则
10. 如果isVS==true,则
11. 生成VAM m:=(i,i,LBi,0),广播m
13. 设置vsBroadcastTimer
14. 如果isVS==false,则
15. 执行
16. 如果从 ∀j∈Ni中接收到一个VAM m',满足 m'.vsLB==LBi,则
17. m'.distVS=m'.distVS+1
18. 如果 m′.vsID∉VSset,则
19. VSset=VSset⋃{m′.vsID}
20. RT.distVSi,j,m′.vsID=m'.distVS
21. 广播m'
22. 如果 m′.vsDist≤RT.distVSi,j,m′.vsID,则
23. RT.distVSi,j,m′.vsID=m'.distVS
24. 广播m'
25. 结束
26. 结束
27. 直到vsBroadcastTimer超时
29. 结束
30.结束
2.3.4 社群内路由过程
所有的活动节点都在协议的稳定阶段异步地执行社群内路由过程(ICR)。算法4和算法5对这一过程进行了详细的描述,算法4是社群中虚拟汇聚点所执行的路由过程,而算法5是普通的传感器节点所执行的操作。节点间的交互是通过ADM和BAM两种消息实现的。
算法4由虚拟汇聚点执行的社群内路由过程
1.令i∈V,在配置阶段中nodeready=true
2.令LVi是节点i在CHP过程后的分层级别
3.令LBj是节点 j的标签,∀j∈Ni
4.令LBset,i是节点i所观测到的所有的节点 j的标签集合,∀j∈Ni
5.令VSset是节点i可能到达的本社群的虚拟汇聚点
6.令RT是节点i的路由表
8.令ei是节点i的剩余能量
9.令ew是路径w的累积剩余能量
10.执行
11. 如果从j∈Ni接收到了一个ADM m'且m'.vsID=i
12. 如果aggregationTimer超时
13. ∀j∈Ni,LBi≠LBj,nextHopOutCommunity=j
14. enqueueOnRelay(Data,nextHopOutCommunity)
17. nextHopInCommunity=stackPop(m'.w),创建BAM,m:=(i,nextHopInCommunity,i,m'.w,q)
18. 否则
19. Data=Aggregate(m'.payload)
20. 结束
21. 结束
22.直到节点操作结束
算法5由非虚拟汇聚点执行的社群内路由过程
1.令i∈V,在配置阶段中nodeready=true
2.令VSset是节点i可能到达的本社群的虚拟汇聚点
3.令RT是节点i的路由表
5.令ei是节点i的剩余能量
6.令ew是路径w的累积剩余能量
7.执行
9. 从applicationDataBuffer中提取数据Data
10. 根据应用配置qtyOfDuplicates
11. 对于i从1到qtyOfDuplicates,执行
12. 随机在VSset中选择一个节点d
14. w={i}
15. ew=ei
16. 生成ADM消息
17. m:=(i,nextHopInCommunity,d,w,ew)
18. 结束
19. 结束
21. 如果从 j∈Ni接收到了一个ADM m'且m'.destID=i,则
23. m'.srcID=i
24. m'.distID=nextHopInCommunity
25. m′.w=m′.w ⋃ {i}
26. m'.ew=m'.ew+ei
27. 单播m'
28. 结束
29. 如果从 j∈Ni接收到了一个BAM m'且m'.destID=i,则
32. nextHopInCommunity=stackPop(m'.w)
33. m'.destID=nextHopInCommunity
34. 单播m'
35. 结束
36. 结束
37. 结束
38.直到节点操作结束
由于这些消息的目的地不同,它们的结构也各不相同。ADM由源ID(srcID)、目的ID(destID)、虚拟汇聚点ID(vsID)、当前路径队列(w)、当前路径剩余能量(ew)以及数据有效负载组成;BAM由源ID(srcID)、目的ID(destID)、虚拟汇聚点ID(vsID)、当前路径队列(w)和由虚拟汇聚点计算得到的最终路径质量(q)构成。
普通传感器节点在ICR中扮演的角色可以总结为两类:向随机选择的虚拟汇聚点发送新的聚合数据(算法5的第5~15行)和将所接收到的ADM和BAM转发到下一跳的目的地(算法5的第17~34行)。虚拟汇聚点在ICR中所扮演的角色比较复杂,因为虚拟汇聚点每接收到一个ADM都需要生成一个BAM。由于每个BAM都具有路径质量参数q,虚拟汇聚点必须要考虑ADM中的w和ew参数来计算它。
虚拟汇聚点可以在一定的时间间隔对所接收到的数据进行聚合,这一时间间隔在应用中由aggregationTimer参数指定。因此,虚拟汇聚点随机选择一个位于社群外的邻居发送数据,并通过enqueueOnRelay函数将其放入队列中。
3 性能分析
3.1 仿真模型与假设
本文假定模型是适用于静态传感器网络的,在这一网络中,节点是均匀分布的,但其具体的位置坐标未知。此外,所有的节点都配备了相同的无线电设备和传输功率,从而形成了节点网络间的对称链路。
3.2 度量指标
本文使用三种度量指标来评估提出协议的性能:实际吞吐量(交付率)、传输延迟和能量消耗。
(1)吞吐量
本文定义的吞吐量是指传递到汇聚点应用层的总消息数量与每个节点所产生的原始数据消息的总和的比值,吞吐量由式(4)定义:

其中,Mi是由节点i产生的原始数据消息的集合;Ri是汇聚点接收到的节点i所发送出的原始数据消息的集合。
(2)传输延迟
本文将单个消息的数据传输延迟定义为消息从源节点发送到汇聚点所消耗的时间。对于每一个节点,将个体的传输延迟视作总体延迟的均值,因此,可以假定总体的传输延迟为所有个体传输延迟的均值。
(3)能量消耗
本文使用处于传输状态(TX)节点的能量开销来衡量能量消耗。本文在估计单个节点的传输能量消耗(Etx)时考虑了文献[15]所提出的能量模型:
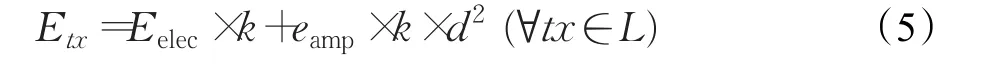
其中,L是所有传输的集合;k是距离为d的传输的比特数(在这种情况下,d是给定tx传输功率的最大传输距离);Eelec是传输一个比特的能量消耗;eamp是放大器能量开销。因此可以对网络的总开销(单位为J/h)进行估计,总开销为式(6)中所定义的每次传输的能量的总和:

其中,T是网络的总操作时间。
3.3 仿真参数和场景
为验证算法的有效性,在NS2(Network Simulator Version 2)仿真环境下对本文协议、文献[10]、文献[11]提出的协议进行仿真比较。在500 m×500 m的目标区域内部署500~3 000个节点,其余参数如表1所示。

表1 仿真参数
本文根据每个节点的概率λ来考虑不同的数据生成速率,每个节点在每秒最多产生一条消息。λ的取值分别为0.01、0.02和0.05,分别表示数据生成速率由低到高。在模拟中,数据生成周期为500秒,从第1 000秒生成开始,到第1 500秒结束。在这段时间之后,仿真持续进行直至网络中不存在数据消息。
3.4 仿真结果分析
(1)节点数量和吞吐量的关系
图3是关于吞吐量的仿真结果。从图中可以看出,在所有场景中,本文协议都比其余两种协议具有更好的性能。三种协议的吞吐量都随着节点数量的增加和λ值的增加而下降,这是因为随着节点数量和数据生成速率λ的增加,网络的冲突情况也显著增加。由于本文协议使用了基于主动确认的社群内重传机制,它可以提供较强的消息传输可靠性。文献[10]和文献[11]提出的协议仅仅是利用社群检测技术增加网络的连通性,相比之下,本文协议能够取得更好的效果。
(2)节点数量和能量消耗的关系
能量消耗的平衡依然是大规模WSN中的一个重要问题。图4是三种协议的能量消耗情况。虽然本文协议能比其余两种协议传送更多的原始数据,它的每小时平均能量消耗却比其余两种协议有所降低。事实上,本文协议使用社群方法的主要优势就是降低代理在距离和能量消耗方面的开销。因此,实验结果表明,使用改进蚁群算法在社群内更新和维护路由路径,可以减少能量消耗。另外,从图4中还能看出,当数据生成速率λ越来越大时,网络中节点间传输的消息也越来越多,因此能量消耗也越来越大。
(3)节点数量和传输延迟的关系
图5为三种协议的传输延迟情况。当数据生成速率λ一定时,三种协议的传输延迟都随着节点数量的增加而增大。当λ=0.01时,本文协议的传输延迟和文献[10]协议相差不大,均优于文献[11]协议的传输延迟;但随着λ逐渐增大,网路中需要传输的消息逐渐增加,相应的社群内重传机制执行的次数也会增加,因此出现本文协议的传输延迟大于其余两种协议的传输延迟,如图5(b)、(c)所示。
4 结束语

图3 节点数量和吞吐量的关系

图4 节点数量和能量消耗的关系

图5 节点数量和传输延迟的关系
本文阐释了在大规模网络中使用群智能协议的优越性,并提出了一种基于改进蚁群优化算法与分布式社区检测的WSN路由协议,由仿真结果可知,本文协议在吞吐量、能量消耗等方面体现出了一定的优势。利用改进的蚁群优化算法和标签传播技术来降低代理的开销,从而减小网络负载和内存开销。使用一种基于主动确认的社群内重传机制,在保证较低的能量开销的前提下,提供了较强的消息传输可靠性。
下一步工作将考虑使用多个移动的汇聚点收集数据,以减小传输延迟,从而更好地满足WSN的应用需求。
