海量样本数据集中小文件的存取优化研究
2018-11-17哈力旦阿布都热依木李希彤
马 振,哈力旦·阿布都热依木,李希彤
新疆大学 电气工程学院,乌鲁木齐 830047
1 引言
样本数据集具有文件类型多样、数量大但单个文件体积小、文件名重复度和类似度高等特点,使Hadoop分布式文件系统(Hadoop Distributed Files System,HDFS)在存储样本数据集时面临巨大挑战,这些挑战主要在主节点内存消耗、元数据管理、存储性能等方面[1-2]。
针对分布式文件系统HDFS在处理海量小文件时效率不高的问题,已有的解决方案如下:
(1)游小容等人[3]提出了一种基于Hadoop的海量教育资源小文件的存储方案,其利用教育资源小文件之间的前驱后继关系将小文件归类合并成大文件,具体方案参见文献[3]。该方案没有通过实验给出设定小文件判断条件的依据,且存在一个文件占据两个数据块的问题。
(2)Sethia等人[4]提出了一种新的OMSS算法(基于优化MapFile的小文件存储),其将小文件合并成MapFile,具体方案参见文献[4]。该方案使用了MapFile的合并文件格式,并未建立所有小文件索引,仅在一定程度上提高了读取效率。
(3)郑通等人[5]提出了将小文件合并为大文件,同时将小文件到大文件的映射关系存于HBase中,具体方案参见文献[5]。该方案采用文件名作为行键,并未考虑HBase的访问热点问题,而且没有考虑缓存穿透问题。
针对以上方案存在的一些问题及样本数据集的特点,本文提出了一种面向样本数据集的存取优化方案。方案中考虑了样本数据集的高度相关性以及缓存穿透问题。
2 小文件存储方案设计
为了保持样本数据集的高度相关性和存储空间合理化,设计用户端和HDFS端的样本数据集目录结构如图1、图2所示。

图1 用户端目录结构

图2 HDFS端目录结构
本文提出的方案由用户客户端、数据处理模块、Hadoop分布式文件系统三部分构成,总架构如图3所示。各部分功能说明如下:
(1)客户端接入模块:该模块用于用户与Hadoop分布式文件系统的存取交互,并实现了远程任务提交功能。
(2)数据处理模块:该模块实现了数据合并处理、索引构建、数据预取和缓存的功能。

图3 样本数据集存储架构
(3)Hadoop分布式文件系统[6-7]:该模块实现海量样本数据集的存储,采用HBase非结构化数据库[8-9]存储小文件索引。
样本数据集的存取过程具有一次写入、多次读取的特点,对读取性能的要求高于写入性能,同时文件增减替换时需要不影响存取的效率。
2.1 样本数据集存储模块
样本数据集有图片数据集、文本数据集、音频数据集和视频数据集等。由于Hadoop并未提供区分大、小文件的判定条件,且不同硬件配置的文件系统对大、小文件判定条件具有一定的影响。因此,本文通过分析Hadoop性能测试工具TestDFSIO写入不同大小文件时的性能,确定文件系统对应的大、小文件判定条件。为了向数据集添加和替换小文件,统计数据集中占比最高的文件大小,将此文件大小设置为预留区域。将数据块减去预留区域大小与合并文件头大小之和作为合并阈值,即
2.1.1 变尺度堆栈算法
本文提出一种基于数据块均匀[10]的合并算法,其核心思想是借鉴堆、栈中数据遵循先进先出(First In First Out,FIFO)和先进后出(First-In Last-Out,FILO)的原则[11-12],改变堆、栈的尺度,并交叉应用到小文件合并的过程,故将其命名为变尺度堆栈算法(Variable Scale Stack Algorithm,VSSA)。算法详细步骤如下:
步骤1 FIFO合并过程。
按小文件的体积从大到小进行排序,以迭代的方法选择最大的i个文件进行合并,直至放入第i+1个文件时超出设定合并阈值时退出此过程,并将此i个文件从文件列表中删除。
步骤2 FILO条件判断。
计算最小文件体积与合并阈值的差值,若为负值,则转到步骤3;若为正值,则转到步骤4。
步骤3 FILO合并过程。
迭代选取最小体积的 j个文件追加到步骤1产生的合并文件中,直至放入第i+j+1个文件时超出设定阈值,并将此 j个文件从文件列表内删除,转到步骤4。
步骤4将选取的文件送入合并模块中,未合并的文件更新为新的输入列表。重复步骤1~步骤4,直至将所有小文件进行合并。
2.1.2 算法实现过程
用户通过客户端向HDFS提交存储任务时,首先根据测得的大、小文件判定条件T将样本数据集分为大文件和小文件。以图片数据集为例,若为大文件,则无需合并,直接将其上传至HDFS的该用户下该样本数据集对应的文件夹中。若为小文件,则通过VSSA算法在该数据集中选取最优文件组合合并,直至合并文件体积达到合并阈值,将合并文件上传至HDFS的该用户下该样本数据集对应的文件夹中。将样本数据集的名称缩写和上传时间作为合并文件的命名方式,例如图片测试集(Image Test Set)ITS20180423123357。合并过程的流程图如图4所示,其他数据集类似于图片数据集的合并方式。图5为合并文件结构图。

图4 合并过程流程图

图5 合并文件结构图
2.2 构建索引模块
为了快速检索合并文件中的小文件,本文在每次创建合并文件时,将记录小文件名、小文件所在数据块ID及其在合并文件中的偏移量存于临时索引文件中,在上传过程完成之后,再读取此临时索引文件中的信息存储于HBase表中。对于合并文件,将记录文件名和数据块ID。对于大文件,则记录该文件的文件名和存储路径。
由于样本数据集中存在大量不同路径文件名相同、相同路径文件名类似的文件,例如COCO_train2014_000000000110.jpg,COCO_train2014_000000000562.jpg。随着文件数目的递增,以文件名作为Row Key,将会造成访问热点问题[13]和行键重复问题。为此,本文方案将文件MD5值、文件名、样本数据集名结合作为Row Key,将文件标志、小文件和合并文件的数据块ID、大文件存储路径、小文件在合并文件中的偏移量存于索引表中。文件为大文件,将文件标记为b;文件为小文件,则文件标记为s;文件为合并文件,则文件标记为m。以此标志对应不同的读取数据方法。HBase中的索引存储结构如表1所示。
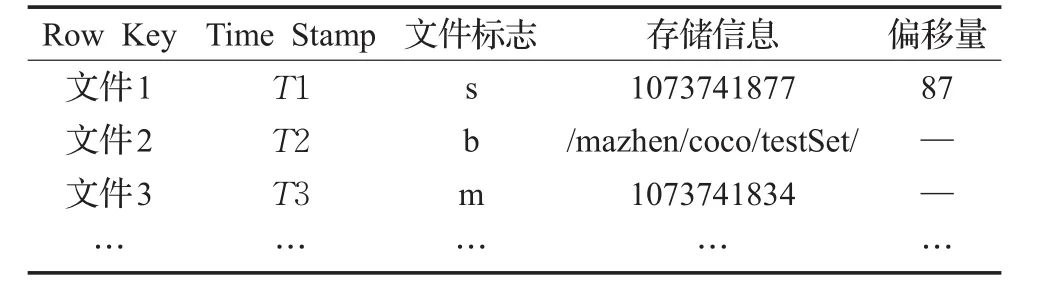
表1 HBase索引存储结构
3 文件访问
3.1 预取机制和缓存机制
由于样本数据集的高度相关性,当用户访问样本数据集时,需要大量向NameNode发送大量获取文件元数据的请求,将给主节点带来巨大的压力。本文采用预先读取的策略,在客户端上搭建Ehcache缓存框架[14],将样本数据集的元数据信息缓存至客户端内存中。
其核心思想为:用户访问某个样本数据集的文件时,在读取该文件索引的同时,将该数据集下所有的文件索引信息缓存在客户端内存中。当用户多次查询不存在的文件时,导致每次都要去HBase和NameNode查询。为此,本文对查询为空的结果进行缓存,设置缓存时间为5分钟,再次查询时,在当前缓存时间上增加1分钟,避免多次访问不存在文件时而导致的缓存穿透问题。在24小时内没有用户访问该样本数据集时,则将其索引信息从缓存中清除。
3.2 文件的访问
当用户向客户端发起读取数据的任务时,客户端首先获取该用户的HBase数据表,根据文件名和样本数据集名在缓存索引表中检索是否存在对应的文件元数据。若不存在,使用原始HDFS读取数据的方法。若存在,判断其文件标志:为b,则使用大文件读取模式(B Mode)获取该文件;为m,则使用合并文件读取模式(M Mode)获取该文件;为s,则使用小文件读取模式(S Mode)获取该文件。
B Mode:结合HBase表中获取的文件存储路径及原始HDFS读取单个文件的方法,便可读取该大文件。
M Mode:结合HBase表中获取的数据块ID,便可读取该合并文件。
S Mode:结合HBase表中获取的数据块ID和偏移量,可确定小文件所在的数据块的准确位置,便可快速读取该小文件。
详细读取过程流程图如图6所示。
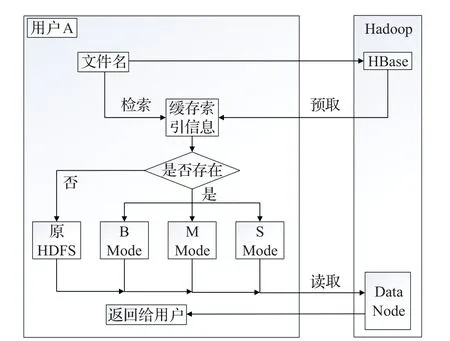
图6 读取过程流程图
4 文件添加、删除及替换方法
4.1 添加文件方法
用户添加文件时参考上述方法。若为小文件,则遵循优先向最小合并文件追加的原则,并构建索引存储至该用户的HBase表中。若为大文件,则直接存储至HDFS,并向该用户的HBase表中添加索引信息。
4.2 删除文件方法
用户删除文件时,首先根据文件名和样本数据集名在HBase表中查找该文件的索引信息,将此索引标记为待删除。若为小文件,定位小文件的位置并将其删除,最后将标记索引删除,将剩下的文件合并和更新索引信息。若为大文件,则将大文件和标记索引先后删除。
4.3 替换文件方法
用户替换文件时,首先根据文件名和样本数据集名在HBase表中查找该文件的索引信息。若为小文件,将此数据块内的文件索引标记为替换,并用新文件替换此小文件,最后更新所有标记的索引信息。若为大文件,将文件的索引信息标记为替换,删除旧文件,并将新文件存储至对应的位置。最后更新大文件的索引信息。
5 实验结果及分析
5.1 软硬件环境
实验使用Apache Ambari[15]部署了3个节点的集群环境,各节点操作系统均为Centos 7,Hadoop版本为Hadoop 2.7.2,开发环境为Eclipse 4.6,节点采用SSH(Secure Shell)免密码配置,数据块的副本数量为2。各节点机器详细配置见表2。

表2 各节点机器详细配置
本次实验从多个公开数据集的训练集和测试集中随机选取200 000个文件作为测试数据集,并保持公开数据集的目录结构。公开数据集有cocodataset2017(http://cocodataset.org/#download,大规模的物体检测、分割和字幕数据集),Stanford Car Dataset[16](http://ai.stanford.edu/~jkrause/cars/car_dataset.html,汽车图像数据集),Daimler Pedestrian Benchmark Data Set(http://www.gavrila.net/Datasets/Daimler_Pedestrian_Benchmark_D/Daimler_Pedestrian_Segmentatio/daimler_pedestrian_segmentatio.html,Daimler行人视频数据),THUYG-20(http://www.openslr.org/22/,维吾尔语语音数据库),The WikiText Long Term Dependency Language Modeling Dataset(https://einstein.ai/research/the-wikitext-longterm-dependency-language-modeling-dataset,基于 Wikipedia的长期依赖语言模型数据集)。其中1 KB~100 KB的文件占10%,100 KB~17 MB的文件占80%,17 MB以上的文件占10%。分5组进行实验,每组的文件数量为40 000、80 000、120 000、160 000、200 000。
5.2 大、小文件判定条件T的确定
将2 GB数据平均分为200 KB、700 KB、1 MB、5 MB、10 MB、13 MB、15 MB、16 MB、17 MB、17.5 MB、18 MB、18.5 MB、19 MB、19.5 MB、20 MB、25 MB、30 MB、35 MB、40MB大小的文件,使用Hadoop性能测试工具TestDFSIO测试写入不同大小文件的性能,得到相应的Throughput和Average IO Rate,结果如图7所示。因此,设置17 MB为大、小文件判定条件T进行后续的实验。

图7 不同文件大小下的处理性能
5.3 写入性能实验
为了验证本文方案与原HDFS、SequenceFile[17]方案在上传速度方面的差异,将5组数据分别通过改进方案与原HDFS、SequenceFile方案上传到HDFS。每组进行3次实验,取平均值进行分析,结果如图8所示。
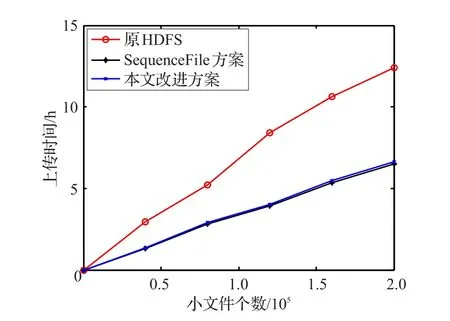
图8 写入时间对比
由实验结果可知,本文方案和SequenceFile方案均优于原HDFS上传方式。因为原HDFS频繁地向NameNode发送请求,NameNode响应占用了大量时间。而本文方案和SequenceFile方案将多个文件合并上传至HDFS,NomeNode仅响应一次。但本文方案在上传的同时还要向HBase写入索引信息,因此比较耗时。
5.4 内存占用实验
为了验证本文方案在主节点的内存占用率优化程度,设计本文方案与原HDFS的实验进行对比。记录每组文件上传之后的内存变化,每组进行3次实验,取平均值进行分析,结果如图9所示。

图9 内存占用对比
由图9可知,本文方案在缓解NameNode内存压力方面优于原HDFS。主要原因是本文方案采取先将文件合并再上传的方法,大大减少了数据块的数量和NameNode管理的文件数量,从而降低了主节点的内存消耗。
5.5 读取速度实验
为了验证本文方案在文件读取方面的优势,按照相同的步骤对本文方案和原HDFS、SequenceFile方案进行实验。根据文件名和样本数据集名读取文件并记录时间,每组进行3次实验,取平均值进行分析,结果如图10所示。

图10 文件读取时间对比
从图10文件读取时间的比较可知,本文改进方案在文件读取方面优于原HDFS和SequenceFile方案。由于原HDFS和SequenceFile方案读取文件时均会向NameNode发送大量获取文件元数据的请求。而本文方案加入了基于Ehcache的缓存框架的预取机制,将正在访问的数据集元数据信息预取至客户端内存中,减少了向NameNode发送请求的次数,从而提高了文件的读取速度。随着文件数量的递增,本文方案将呈现更加明显的优势。
6 结束语
本文考虑了样本数据集的高度相关性,提出了一种面向样本数据集存取优化方案,并优化了样本数据集的写入、读取、添加、删除和替换方法。本文方案使用Hadoop分布式系统架构,利用分布式文件系统HDFS的高吞吐量的优点存储样本数据集,并对其存取方式进行优化。首先根据机器配置上文件系统对应的大、小文件判定条件,将样本数据集分为大文件和小文件,使用变尺度堆栈算法优化小文件合并过程,构建所有文件的索引并存储在HBase中,优化HBase的行键,将正在访问的样本数据集元数据缓存于客户端内存中。通过实验对比,本文方案在存储文件、读取文件以及降低主节点内存消耗方面均有明显的改善。
