变电站巡检机器人的数字仪表自动识别技术研究
2018-11-16,,,
, , ,
(1.云南电网有限责任公司电力科学研究院,云南 昆明 650206; 2.北京国遥新天地信息技术有限公司,北京 100101)
0 引言
数量巨大的变电站分布在偏远地区,这使得这些变电站的维护和巡检需要更多的人力和财力。此外,一些高电压和超高压变电站的巡检和维护存在较大安全隐患,因此使用人工日常巡检是不现实的[1-2]。因此,基于巡检机器人的变电站的巡检智能化和监控自动化得到广泛关注和应用。
目前常用于巡检机器人的数字仪器识别的方法有线段识别法[3]和神经网络法[4]。由于数码管显示仪表的两个重要特征:数码管由3个水平的平行线段和4个垂直(或稍微倾斜)线段组成,7个线段的位置相对于数码管本身的外部矩形的位置是固定的[5],因此线段识别方法在确定数字区域后,扫描直线上的像素以分析各条线段之间的水平或垂直相交关系以确定所显示的数字。深度学习神经网络是神经网络模型中的一种有效的方法,并模式识别领域得到了广泛的应用。该识别方法首先需要人为地选择数字目标的数字0~9的特征图像,并且将10个数字的特征矢量建立为输入矩阵,通过对神经网络的训练和学习,构建神经网络各层神经元的连接权重和阈值,并把完成训练的神经网络应用于数字仪表输出由10个元素组成的矢量以区分所显示的数字[6]。该方法具有分类能力强,容错性好,自学习能力强等优点;缺点是需要训练过程,效率不高,实现较为复杂。
针对上述数字仪表自动识别方法所表现的缺陷,本文对基于样本匹配原理的数字仪表自动识别算法进行了研究。该算法的思路是,首先建立0~9的数字样本,对处理后的仪表数字和样本数字进行标准化处理,然后逐一比较它们之间的差异,其中具有最小差异的一对被认为是相同数字。这种算法具有计算量小、易于实现的优点。由于该方法需要事先设置好识别样本,为此本文将高分辨率的图像通过分组高阶统计量和阈值的局部最大类间方差进行分割,识别并得到简单、有效、通用的样本匹配。
1 识别过程
数字仪表读数的识别流程图如图1所示,首先机器人摄像机拍摄的彩色图像呈灰色并进行二值化处理,然后找到显示区域,分割出一个数字字符,并识别出数字[7]。
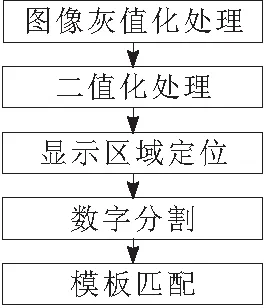
图1 识别流程
2 图像预处理
图像预处理是精确定位数字区域和分割原始图像中的显示区域。根据变电站数字显示仪表的实际使用情况,需要预处理两幅原始图像,包括图2中的反射图像和图7中的颜色信息图像。完成对仪表显示区域的位置确定之后需把仪表所显示的指数分割成单个数字,以便进行下一步的数字样本比对。
2.1 反射图像的显示区域定位
用于定位图2的反射图像的显示区域的算法如下:
原始图像先进行灰值化处理,再使用中值滤波器处理。
在原始图像中,由于显示区域具有反射性和黑暗性,所以本文使用顶帽变换、底帽变换和直方图均衡来减少光反射对图像处理的影响。
顶帽变换是用结构元素s通过打开操作从原始图像中减去显示区域,这样操作可将明亮的显示区域从背景中分离出来。顶部变换公式为:
Ttop-hat(i)=i-(i×s)
(1)
底帽变换是用结构元素s从原始图像中通过关闭操作减去显示区域,这可以从明亮的背景中突出显示黑色显示区域。底帽换算公式为:
Bbot-hat(i)=i-(i×s)
(2)
在公式(1)和(2)中,i代表输入的灰值化图像;s是结构元素;Ttop-hat(i)和Btop-hat(i)分别表示顶帽变换和底帽变换后的图像。

图2 数字仪表图
直方图均衡化[8-9]也称为灰度均衡化,在均衡化后,图像具有相对较高的对比度和相对较大的动态范围,灰度比较丰富,易于解释。灰度直方图是二维图形,横坐标是图像像素的灰度级,纵坐标是每个灰度级上像素的数量或概率,并且直方图反映了灰度图像像素的整体分布水平。直方图均衡的思想是通过某种灰度映射重新计算整个图像像素的灰度值,使输入图像的像素在每个灰度级均匀分布,即直方图变得均匀。平衡的图像提高了视觉效果,易于理解。
直方图均衡处理的目的是是处理后的图像的对比度更高,灰度显示更加丰富且便于解析。直方图由横坐标是灰度级和纵坐标是灰度级对应的像素数量或概率所构成的二维图,该图形是图像像素的在灰度级维度上的整体分布的直观反映。直方图均衡处理的思路是通过灰度映射对所处理的图像像素的灰度值进行重新调整,而调整的结果是所处理的图像的像素对应于灰度级的分布更加均匀,以便对图像进行下一步的处理。
对原始图像进行底帽变换、顶帽变换和直方图均衡化后的效果如图3所示。

图3 图像预处理的效果
使用最大类间方差法[10](OTSU)对上述获得的灰度图像进行二值化。
OTSU是一种依据图像灰度分布特性确定灰度阈值,并更具灰度阈值将图像分割成目标区域和背景区域的方法。目标区域和背景区域的类间方差大小和这两个区域的灰度值差别成正比关系。采用OTUS方法确定灰度阈值分割目标图像可以将背景区域和目标区域分割错误的概率降至最小。下面对OTUS的灰度阈值确定思路进行简要阐述。
如果所处理的图像的灰度值分布在[L1,L2]之内,则所确定的阈值T将图像像素分为C1和C2两类,其中C1的灰度值分布在[L1,T],C2的灰度值分布在[T+1,L2]。C1的发生概率为P1(T),C2的发生概率为P2(T),C1的灰度均值为u1(T),C2的灰度均值为u2(T)。而整个图像的灰度均值为u,则类间方差为:
σ2(T)=P1(T)(u1(T)-u)2+P2(T)(u2(T)-u)2
(3)
通过式(3)可以计算出灰度阈值T。利用该阈值T对图3所示的图像进行二值化处理的效果如图4所示。

图4 二值化图像
对二值化图像进行解析可以获得数字仪表的读数显示区域,如图5所示。从图中可以看出,由于知道矩形的3点坐标可以完全确定一个矩形,所以第3个仪表由于光线的影响而缺少一个角落,但不影响定位。
通过上述操作,获取数字仪表读数显示区域,随后将该图像叠加至原始数字仪表图像中,如图6所示的效果图。

图5 数字仪表的读数显示区域
由图6可知,3个读数显示区域与原始图像的叠加效果良好,说明该读数显示区域的位置识别十分准确,并且通过上述操作较为有效地排除了光线反射等环境因素的影响,为下一步的读数识别提供了较好的基础。

图6 显示位置
2.2 基于颜色信息的读数获取
由于数字仪表的读数显示是通过颜色来突出显示效果,因此通过颜色信息的解析来获取数字仪表的读数能够提高读数的获取准确性。为了获取图7所示的数字仪表中读数的颜色信息,需要先将该RGB图像转换为HSV图像。

图7 电气仪表图
常见的图像都是采用三基色来表示人眼可识别的所有颜色。这三种基本颜色是红色(R)、绿色(G)和蓝色(B)。而与常见的图像三基色大相径庭的是,人眼的颜色感知是基于HSV颜色模型[12]的。HSV颜色模型通过3个参数色调(H)、饱和度(S)和明度(V)来描述人眼所能识别的所有颜色。其中色调(H)为颜色的角度度量,范围为0°~360°,其中红色为0°,绿色为120°;饱和度(S)表示颜色的接近光谱色的程度,范围是0%~100%,值越大,饱和度越高;明度表示颜色明亮的程度,范围是0~1,其中1表示白色。将RGB转换成HSV的公式为:
(4)
(5)
V=RGBmax
(6)
RGBmax表示最大(R,G,B)值;RGBmin表示最小(R,G,B)值。并且如果H< 0,则H的值加360°。本文采用S分量提取图像的红色区域。结果如图8所示。

图8 S信道处理后的图像
上面的图像被二值化以及打开和关闭操作,结果如图9所示。

图9 二值化图像
当得到显示区域的位置时,最后将它绘制在原始图像中,并得到如图10所示的结果。

图10 位置图像的结果
2.3 数字分割
一旦定位目标读数区域,就需要将这些数字分成单一的数字,以便进行数字的识别。首先对读数显示区域进行水平和垂直投影,完成对读数显示区域的边界的确定[13]。然后使用从上到下扫描读数显示区域,以确定读数的上下边界。目前变电站所使用的数字仪表一般采用7段LED数码管显示读数,即通过7个不同位置的LED的点亮组合来显示10个不同的数字。为确保所分割区域大小基本相同,本文采用将数码管的所7段有LED全部点亮(即数字8)作为分割样本。所以数字1被分割在图像的右侧,这是因为数字1来自右侧的2个LED灯。对数字仪表读数区域进行分割的效果如图11所示。

图11 读数分割的效果
3 样本匹配算法
样本匹配算法效率高且易于实现而被广泛使用。该算法的关键是数字样本的选择。该样本要求与待识别的数字图像完全相同,且其图像结构相对稳定。由于室内变电站数字仪表的读数显示形式基本相同,且数字结构完全一致,所以变电站数字仪表的读数完全符合该算法的前置条件。
首先,建立了数字仪表的读数样本库[14-15],然后对巡检机器人所采集的读数图像进行预处理。随后将所预处理的读数分割为单个数字的二值化图像,每个读数样本大小统一为34×29(像素),待识别的数字图像大小也统一处理为和样本大小一致,最后逐一比较它们的差异,将具有最小差异的两幅图像视为相同数字,以确定数字图像的值。具体识别过程描述如下。对应于10个样本的二值化图的矩阵被表示为与二值图像像素的黑色和白色像素相对应的M0,M1,M2。0和1如果归一化的矩阵数字图像由Ms表示,则有以下公式:
(7)
通过公式(7)的计算将巡检机器人所采集的读数图像与样本库的样本图像之间的差异数值化。该数值越小,说明采集的读数图像与样本图像之间的差异越大,当数值达到其最大值时,样本图像中的数字就是巡检机器人所采集的图像的数字。
4 实验验证
为了验证该样本匹配算法的识别效果,选择图11为带识别的数字图像。并采用本文所述的方法对这4个图像进行识别。样本1由于图像采集不完整,因此第2位数字的识别出现错误, “2342”被识别为“2742”。另外3个样本均被准确识别。
为了进一步检验算法的稳定性,本文测试了变电站采集的200台数字显示仪表的图像,准确识别的数目为190,识别准确率为95%。
本文的图像是在相对良好光线的环境下拍摄的。识别率最大的影响因素是所收集图像的光线反射,使得分割的数字不完整。但图像质量可以人为控制,识别率可以满足需求。
5 结束语
本文在对变电站巡检机器人所采集到数字仪表的彩色图像进行预处理的基础上,采用数字分割、样本匹配的方法实现了一种对数字仪器读数的识别算法。所提算法的关键是建立一个标准的深度学习样本库。样本库的样本数量越多,能够覆盖数字仪表的型号越多,识别正确率也就越高。在大量的验证实验中,尽管采集的数字仪表的读数图像清晰度不高,甚至读数显示有残缺,但采用本文所提出的算法具有高的识别正确率,这表明算法具有较好的有效性和稳定性,能够应用于变电站巡检机器人的数字仪表自动识别。
