低信噪比环境下语音端点检测改进方法
2018-11-15王瑶曾庆宁龙超谢先明毛维
王瑶,曾庆宁,龙超,谢先明,毛维
低信噪比环境下语音端点检测改进方法
王瑶,曾庆宁,龙超,谢先明,毛维
(桂林电子科技大学认知无线电与信息处理教育部重点实验室,广西桂林 541004)
针对语音端点检测在低信噪比环境下普遍存在检测性能急剧下降的问题,提出一种将调制域(时间-频率域)谱减法和自相关函数相结合的语音端点检测算法。该算法首先利用调制域谱减法较好的消噪能力来提高含噪语音的信噪比;然后根据语音和噪声的自相关函数的主峰最大值和次大值之比差异较大的特性,结合基于对数能量和自相关函数的端点检测方法对消噪后的语音进行端点检测。实验结果表明,该算法在低信噪比的环境下能取得较好的端点检测效果,并具有较好的稳健性。
低信噪比;调制域;自相关函数;对数能量;端点检测
0 引言
端点检测(Endpoint Detection, ED)指的是从一段语音中辨别出语音信号和非语音信号并确定语音信号的起始点和结束点,又称为语音活动检测(Voice Activity Detection, VAD)。随着智能语音信号处理技术的发展和应用,研究复杂环境下仍能具有良好语音端点检测效果的方法在语音定位、识别、增强、回波消除等方面[1-2]具有一定的实际价值。尤其是语音识别方面,文献[3]中指出,即使是在安静的环境下,语音识别中有一半的错误源自于端点检测。准确的端点检测不但可以缩短语音信号的处理时间,同时还排除了噪声段的部分干扰。
由于端点检测技术是各项技术的融合,目前并没有系统的分类方式。本文根据采用的判决准则和技术,将其分为四类:(1) 基于门限判决方法,该方法以基于时域参数的检测方法为主,最为经典的就是基于短时能量和短时过零率的双门限判决方法[4],这一类方法的提出最早,使用也最为广泛;(2) 基于统计模型和模式分类的方法,该方法建立语音和噪声的统计模型并采用隐马尔可夫模型进行判决[5];(3) 基于人工神经网络的方法,1991年,Ghiselli. Crippa等[6]首次将前馈神经网络运用到端点检测中,充分利用快速收敛训练算法得出网络权重,以达到将语音、非语音和静音逐一辨别出来的目的,之后较成熟的方法有径向基函数网络[7]、自适应线性神经网络以及循环自组织模糊推理神经网络[8-9]等;(4) 基于时频分析和小波变换的方法,该方法利用不同信号在不同分辨率的情况下相关性不同的特性,将小波分析引入端点检测[10-11]。近年来,虽然仍有大量的端点检测方法被提出,但是在低信噪比情况下检测质量不佳仍然是个很大的问题。
针对上述问题,本文提出一种改进的语音端点检测方法。该方法首先使用调制域谱减法对语音质量进行提升,提高语音信号的信噪比,再使用改进的对数能量与自相关函数(Auto-Correlation Function, ACF)相结合的方法进行端点检测。实验证明,该方法在低信噪比的情况下能较好地检测出语音端点。
1 调制域谱减法
1.1 调制域
时域和频域是处理语音信号中最常见的两种方法,而近些年来随着调频技术的发展和频率源的广泛应用[12],调制域渐渐走进人们的视野。时域反映的是幅度与时间之间的关系,频域反映的是幅度与频率之间的关系,而调制域则反映的是频率与时间的关系[13-14]。将三者的关系用空间直角坐标表示,如图1所示。

图 1 时域、频域、调制域之间的关系
1.2 调制域谱减
假设信号由不相关的纯净语音和加性噪声组成,含噪信号可以表示为
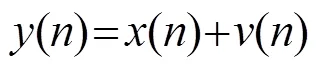

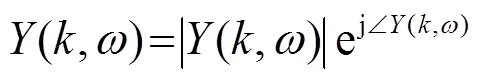
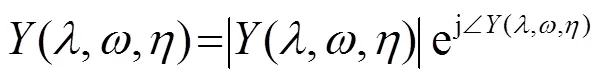


1.3 相位补偿
大多数改进的谱减法都只对幅度做出相应的调整,而忽视了含噪信号中相位的重要作用。相关研究表明,调制域相位相较于频域相位能够提取出更多的有用信息[15],处理调制相位可以进一步抑制噪声,改善语音可懂度,提高语音质量[16]。在此基础上,本文使用相位补偿的方法进一步改进该算法。

(8)
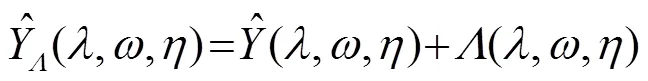
由此,得到调制域相位补偿公式为

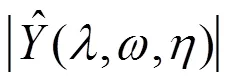

图2为几种消噪算法的时域图。算法流程图如图3所示。

图 2 消噪后的语音时域图对比
由于本文研究的是低信噪比环境,所以图2中的仿真是在-5 dB高斯白噪声环境下去噪后的语音时域图,其中图2(a)、2(b)分别为纯净语音信号和加噪后的语音信号,图2(c)、2(d)、2(e)分别为使用了一般谱减法、对数最小均方误差(logarithm Minimum Mean Square Error, logMMSE)和调制域谱减法进行去噪后的语音信号。从图2中可以看出,在低信噪比环境下,普通的谱减法效果已经不是很明显,而相较于噪声抑制效果较好的logMMSE法,调制域谱减法的语音失真程度较小。所以,本文算法采用调制域谱减法对语音端点检测做前端消噪以提高含噪语音的信噪比,从而提高语音端点检测的性能。
2 语音端点检测
2.1 自相关函数最大值的端点检测
语音信号和噪声信号之间一个非常重要的区别就在于语音的浊音具有周期性而噪声不具备周期性。如果一个信号是周期函数,则其自相关函数为具有相同周期的周期函数。利用这一特性,信号的自相关函数也成为端点检测的一个有效标准[17]。

图 3 调制域谱减法算法流程图
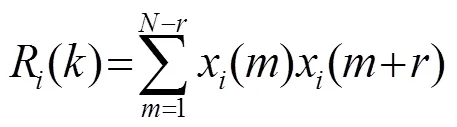

图4为一段噪声信号归一化后的自相关函数。将该自相关函数最大值处放大,每个样点值用点表示,如图5所示。由图5可见,除了最大值为1以外,次大值的幅度在0.1到0.15之间,可近似认为次大值约为0.1。本文定义噪声信号主峰的最大值与次大值的比值大约为10。
图6为-5 dB白噪声环境下一段语音信号的自相关函数。将图6与图4比较可以发现,含噪语音的短时自相关函数呈明显的周期性且在基音周期的各整数倍点上有峰值,而噪声信号的自相关函数并不具备周期性且只在帧中间位置出现最大值,其余值都很小。含噪语音信号自相关函数的最大值和次大值比值约为1。由此可见,可以利用这一特性来区分有话帧和噪声帧[19]。根据噪声具体情况结合双门限法设置两个阈值1和2,当相关函数最大值大于2时则将其判定为语音;当相关函数值大于或小于1时则将其判定为语音的起止端点。

图 4 噪声帧自相关函数

图 5 噪声帧自相关函数最大值处

图 6 含噪语音的自相关函数
但是,在实际情况中噪声具有一定的不稳定性且极有可能含有丰富的高频成分,从而导致自相关函数主峰比值在噪声段出现因起伏引起检测错误的情况。因此,加入对数能量来提高检测的稳定性和准确度。
2.2 自相关函数主峰比与对数能量结合的端点检测
常用的双门限法采用的是基于短时平均能量和短时平均过零率的端点检测方法。本节提出的算法是基于对数能量和自相关函数主峰比值的检测方法,使用对数能量替代短时平均能量,自相关函数主峰比值替代平均过零率。短时平均能量通常情况下在噪声段比较平稳、接近于0,而在语音部分有较高的幅值,这就导致信号的短时平均能量在语音段和噪声段交替时会出现陡变,对短时平均能量取对数则可以缓和短时平均能量剧烈变化的值,在一定程度上平稳了语音段的幅值。

则有每一帧的对数能量[20]为
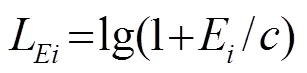
式(15)中,为常数,用于减小中某一数值与前后数值的差距。
最新研究表明,语音段能量的变化趋势与过零率、自相关函数峰值比呈反比,即能量较大时,过零率和自相关函数峰值比值较小[19]。将能量值除以过零率值即能-零比法,可进一步拉大信号噪声段和语音段的幅值差,从而提高端点检测的准确度。本节使用对数能量除以自相关函数峰值比的方法,相较于能-零比法,能更好地拉大差异,提高检测质量。
两种方法归一化后的图形比较如图7所示。由图7可以发现,对数能量除以自相关函数主峰比值的图示效果在噪声段的效果明显要好于对数能量除以过零率的方法,不但噪声与语音的边界更加陡峭,而且在语音主峰部分也更加平缓。
综上所述,本文采用的端点检测方法的具体步骤为:
(1) 使用调制域谱减法提高了含噪语音的信噪比;
(2) 对增强后的语音分帧,并逐帧求自相关函数的主峰最大值与次大值之比以及对数能量;
(3) 将自相关函数主峰比值除以对数能量并对结果进行归一化;
(4) 在得到归一化的对数能量除以自相关函数主峰比值的图形后,结合2.1节提到的双门限法,设定好两个合理的阈值1、2,从而对语音信号进行端点检测。经过大量的实验比较,本文选择1为1.55,2为1.35。
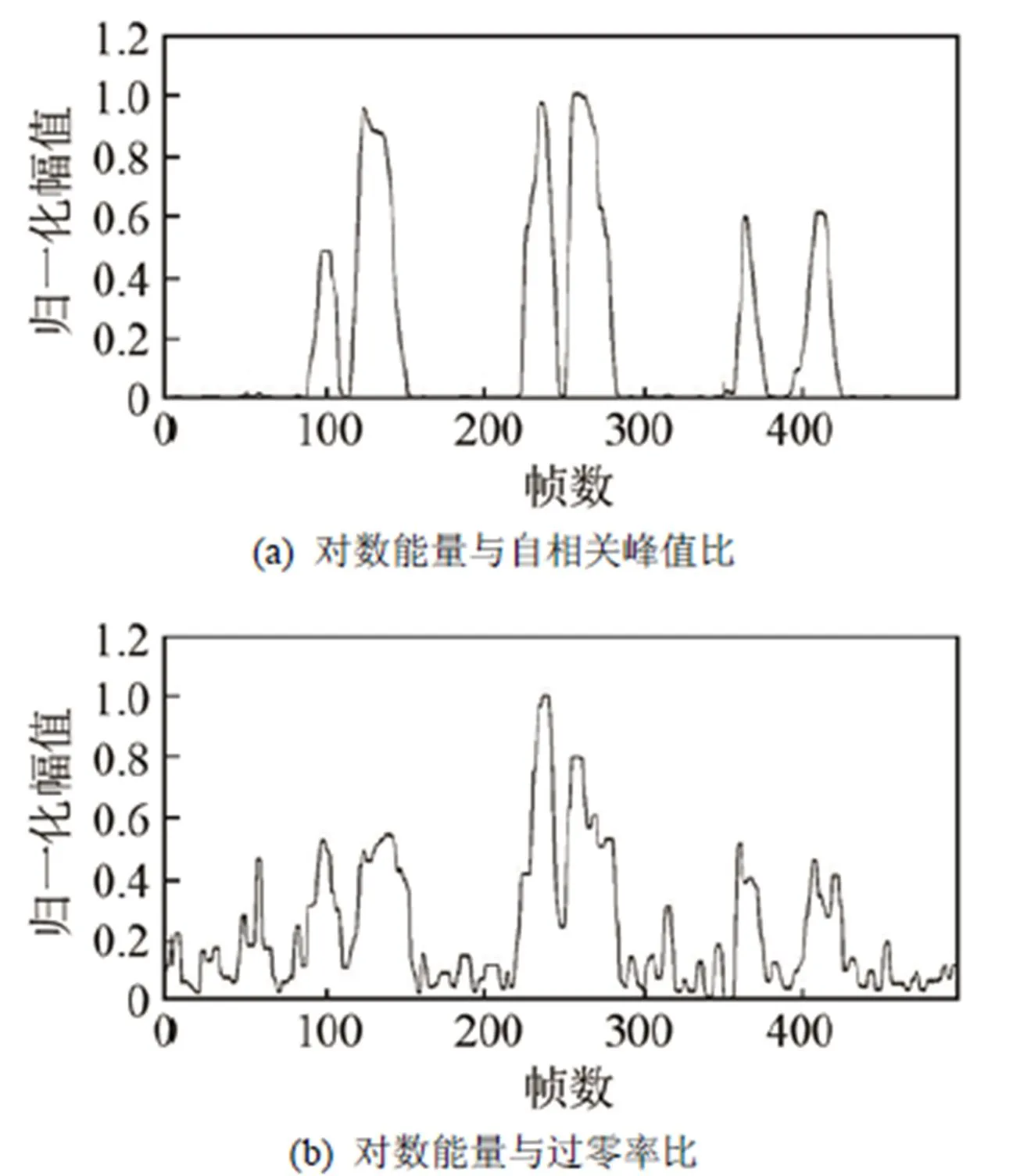
图 7 对数能量-自相关比法与对数能量-过零率比法
3 实验结果
本次实验数据使用M-AUDIO公司的M-TRA-CK EGIHT音频采集器完成,录制背景为相对空旷安静的天台,噪声和语音在同样的环境下进行采集。噪声采集使用了4种噪声,分别为white、f16、volvo噪声和脚步噪声,语音和噪声的采样频率均为8 kHz,采样精度为16 bit。算法中对语音信号加汉明窗分帧处理,帧长=256,帧移=64。
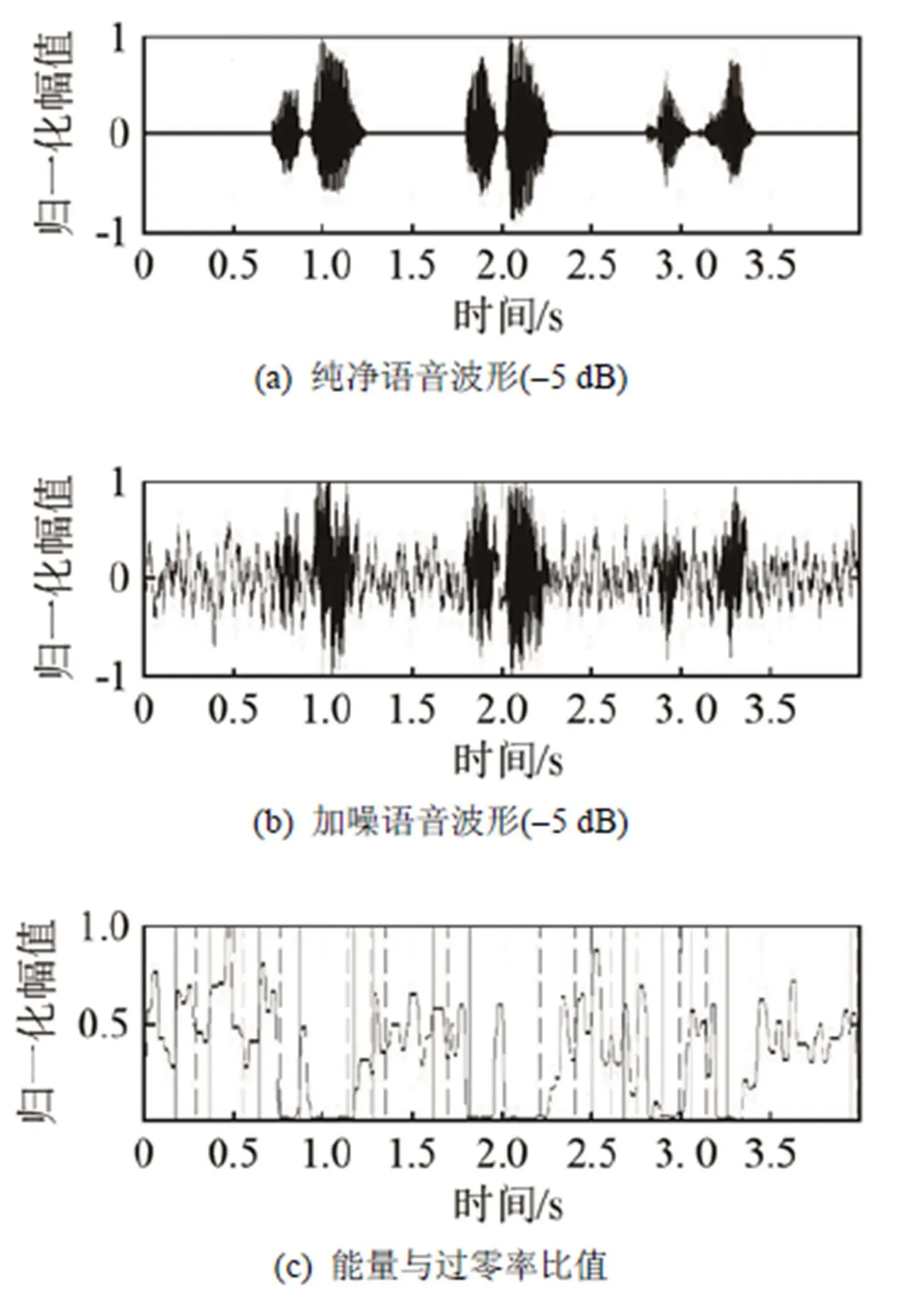
语音内容为3个词:“火灾”、“爆炸”、“抢劫”。由于本文研究的是低信噪比环境下的端点检测算法,所以实验分别在信噪比为5 dB、0 dB、-5 dB的环境下进行,同时针对实际环境中的各种场景,采用白噪声、f16噪声、volvo噪声和室内脚步声4种环境噪声进行仿真。为验证本文算法的可行性,采用对数能量-过零率比法、对数能量-自相关峰值比法与本文的算法进行对比。为方便起见,上述3种算法分别简称为能-零比法、能-峰比法及本文算法。
图8~10分别为信噪比在5 dB、0 dB、-5dB的高斯白噪声环境下的检测结果。由图8可以看出,在信噪比相对较高的高斯白噪声环境下,3种算法都有不错的检测效果。从图8~10综合来看,在白噪声的环境下,当信噪比降到0 dB时,能量与过零率比值法已经有部分幅值较小的语音无法检测出来;当信噪比降到-5 dB时,能-峰比法也开始出现严重误判,但是本文算法依然能很好地检测出语音端点。同时,从图8~10三幅图中不难发现,在说话起始的轻声和尾音的检测中,本文算法在低信噪比环境下都没有让其被噪声淹没,仍然能在不改变门限阈值的情况下较好地完成检测。


图9 信噪比为0 dB的白噪声环境下的端点检测
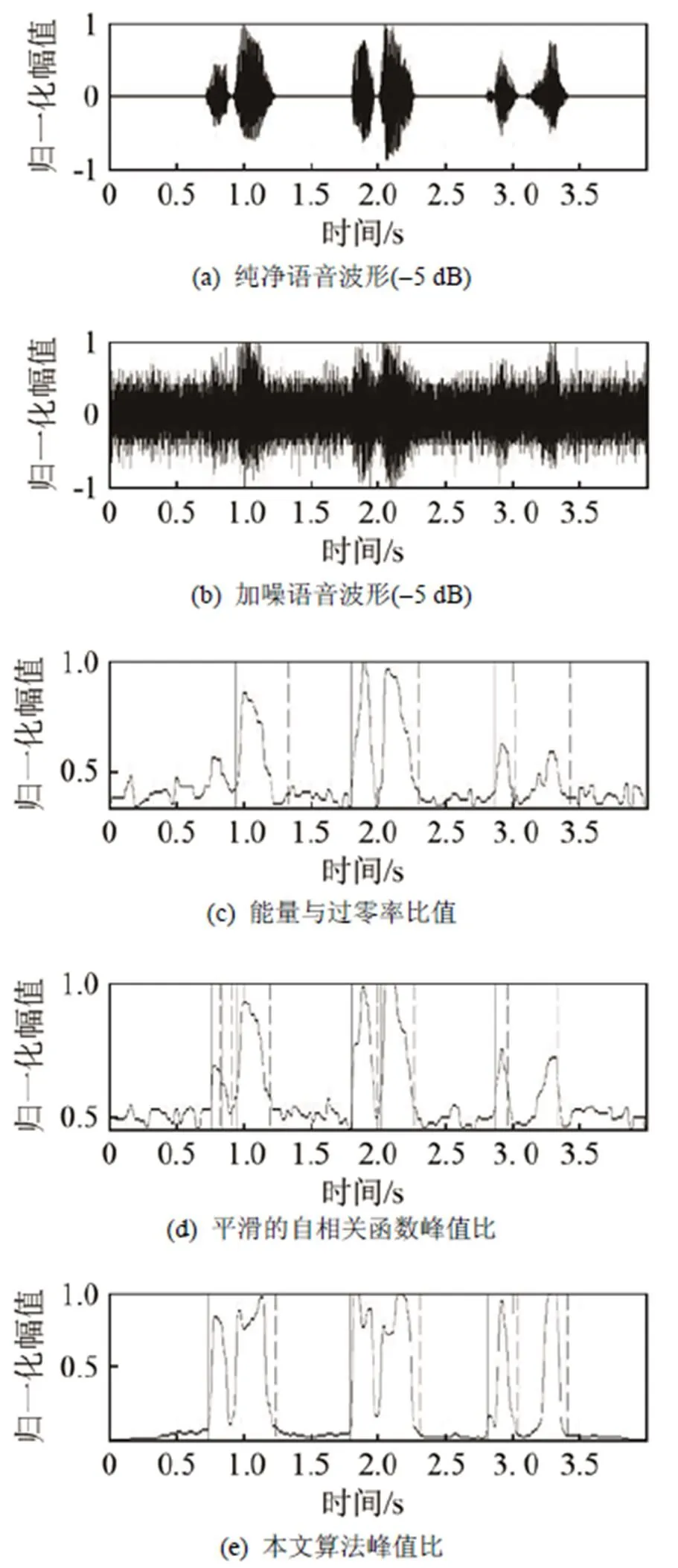
图10 信噪比为-5 dB的白噪声环境下的端点检测
由于白噪声的功率谱密度在整个频域内均匀分布而具有平坦功率谱的特性,所以与实际生活中常见的具有随机性的非平稳有色噪声有着一定的差异,不具备普遍性。针对这一问题,本实验对生活环境下的f16噪声和volvo噪声进行了模拟。图11~13、图14~16分别为f16噪声和volvo噪声环境下3种算法的对比效果。考虑到上述噪声具有一定的特性,从波形来看有相关的规律,同时为了验证本文算法的适用性,图17~19将室内环境下突发的脚步声作为噪声源进行仿真。
由图11~16中可以发现,在低信噪比的有色噪声环境下,能-零比值法的图形并没有在白噪声环境下平缓有辨识度,在f16噪声环境下尚能取得一定的检测效果,但是在volvo噪声环境下已经出现比较严重的偏差;能-峰比法的检测效果略好于能-零法,但是在强噪声环境下,也有重大的误判现象;本文提出的经过调制域谱减后的能-峰比法则无论是在f16噪声还是volvo噪声环境下,都表现出良好的端点检测质量。

图11 信噪比为5 dB的f16噪声环境下的端点检测


图14 信噪比为5 dB的volvo噪声环境下的端点检测
在室内环境下,突发的脚步声对端点检测有较大的影响,如图17~19所示。能-零比法和能-峰比法无法较好地分辨背景脚步声和说话声,从而导致了误判,而本文算法通过调制域谱减法对突发噪声进行了有效的消噪处理,加上合适的阈值选择,减少了误判提高了端点检测质量。


图 18 信噪比为0 dB的脚步噪声环境下的端点检测

4 结论
目前语音识别在智能手机、智能家电方面的应用越来越广泛,智能识别语音口令、提取关键词等相关技术也逐渐成为研究重点。本文提出了一种将调制域谱减法与改进的对数能量和自相关峰值比相结合的语音端点检测算法。该方法首先使用调制域谱减法对低信噪比的含噪语音进行处理,提高语音信噪比,再使用对数能量-自相关峰值比法做端点检测。
实验证明,本文算法在低信噪比的环境下,无论是平稳的白噪声环境下还是非平稳的有色噪声环境下,都能取得较好的语音端点检测效果。另一方面,本文算法的仿真图形在低信噪比环境下依然能保持峰值明显平缓,这表明该算法还有进一步挖掘的空间。本文算法由于加入去噪过程,两次短时傅里叶变换增加了算法的复杂度,运行时间相较于一般的端点检测算法要长出不少。如何在保持算法准确度的同时缩短运行时间是本文下一步的工作。
[1] 赵力. 语音信号处理[M]. 3版. 北京: 机械工业出版社, 2016.
ZHAO Li. Speech Signal Processing[M]. 3rd Edition. Beijing: China Machine Press, 2016.
[2] 韩立华, 王博, 段淑凤. 语音端点检测技术研究进展[J]. 计算机应用研究, 2010, 27(4): 1220-1226.
HAN Lihua, WANG Bo, DUAN Shufeng. Development of voice activity detection technology[J]. Application Research of Computers, 27(4): 1220-1226.
[3] LI J, ZHOU P, JING X, et al. Speech endpoint detection method based on TEO in noisy environment[J]. Procedia Engineering, 2012, 29(4): 2655-2660.
[4] 路青起, 白燕燕. 基于双门限两级判决的语音端点检测方法[J]. 电子科技, 2012, 25(1): 13-15, 19.
LU Qingqi,BAI Yanyan. A speech endpoint detection algorithm based on dual-threshold two sentences[J]. Electronic Science and Technology, 2012, 25(1): 13-15, 19.
[5] JIE L I, YOU D. Enhanced speech based jointly statistical probability distribution function for voice activity detection[J]. Chinese Journal of Electronics, 2017, 26(2): 325-330.
[6] Ghiselli Crippa T. A fast neural net training algorithm and its application to voiced-unvoiced-silence classification of speech[C]// Proc. Int. Conf. Assp, 1991, 1: 441-444.
[7] 刘华平, 李昕, 徐柏龄, 等. 语音信号端点检测方法综述及展望[J]. 计算机应用研究, 2008, 25(8): 2278-2283.
LIU Huaping, LI Xin, XU Boling, et al. Summary and survey of endpoint detection algorithm forspeech signals[J]. Application Research of Computers, 2008, 25(8): 2278-2283.
[8] WU G D, HUANG P H. A maximizing-discriminability-based self-organizing fuzzy network for classification problems[J]. IEEE Transactions on Fuzzy Systems, 2010, 18(2): 362-373.
[9] WU G D, HUANG P H. A vectorization-optimization-method-ba- sed type-2 fuzzy neural network for noisy data classification[J]. IEEE Transactions on Fuzzy Systems, 2013, 21(1): 1-15.
[10] AGHAJANI K, MANZURI M T, KARAMI M, et al. A robust voice activity detection based on wavelet transform[C]//Internation- al Conference on Electrical Engineering. IEEE, 2008: 1-5.
[11] 李乐, 王玉英, 李小霞. 一种改进的小波能量熵语音端点检测算法[J]. 计算机工程, 2017, 43(5): 268-274.
LI Le, WANG Yuying,LI Xiaoxia. An improved wavelet energy entropy algorithm for speech endpoint detection[J]. Computer Engineering, 2017, 43(5): 268-274.
[12] PALIWAL K, WÓJCICKI K, SCHWERIN B. Single-channel speech enhancement using spectral subtraction in the short-time modulation domain[J]. Speech Communication, 2010, 52(5): 450- 475.
[13] 周维权. 调制域分析技术[J]. 电子信息对抗技术, 1995(3): 38-43.
ZHOU Weiquan. Modulation domain analysis[J]. Electronic Information Warfare Technology, 1995(3): 38-43.
[14] 胡丹, 曾庆宁, 龙超. 调制域谱减法用于鲁棒性语音识别[J]. 科学技术与工程, 2016, 16(4): 216-220.
HU Dan, ZENG Qingning, LONG Chao. Modulation Domain Spectral Subtraction for Robust Speech Recognition[J]. Science Technology and Engineering, 2016, 16(4): 216-220.
[15] SO S, PALIWAL K K. Modulation-domain kalman filtering for single-channel speech enhancement[J]. Speech Communication, 2011, 53(6): 818-829.
[16] 陈紫强, 李欣阳, 谢跃雷. 结合相位谱补偿的调制域谱减法[J]. 信号处理, 2015, 31(4): 468-473.
CHEN Ziqiang, LI Xinyang, XIE Yuelei. Modulation domain spectral subtraction combined with phase spectrum compensation[J]. Journal of Signal Processing, 2015, 31(4): 468-473.
[17] 刘淑华, 胡强, 覃团发, 等. 基于自相关函数最大值的语音端点检测方法[J]. 电声技术, 2006(12): 47-50.
LIU Shuhua, HU Qiang, QIN Tuanfa, et al. A method of the voice endpoint detection based on maximum of autocorrelation function[J]. Audio Engineering, 2006(12): 47-50.
[18] VARY P, HEUTE U, HESS W F. Digital speech signal processing [M]. New York, USA: John Wiley & Sons, 2004.
[19] 陈泽伟, 曾庆宁, 谢先明, 等. 基于自相关函数的语音端点检测方法[J]. 计算机工程与应用, 2018, 54(6): 216-221, 256.
CHEN Zewei, ZENG Qingning, XIE Xianming, et al. Speech endpoint detection method based on the auto-correlation function[J]. Computer Engineering and Applications, 2018, 54(6): 216-221, 256.
[20] 孙战先, 储飞黄, 王江. 一种自适应语音端点检测算法[J]. 计算机工程与应用, 2014, 50(1): 206-210.
SUN Zhanxian, CHU Feihuang, WANG Jiang. Self-adaptive algorithm of voice endpoint detection[J]. Computer Engineering and Applications, 2014, 50(1): 206-210.
An improved speech endpoint detection method under low SNR
WANG Yao,ZENG Qing-ning, LONG Chao, XIE Xian-ming, MAO Wei
(Key Laboratory of Cognitive Radio and Information Processing of Ministry of Education,Guilin University of Electronic Technology,Guilin 541004,Guangxi,China)
In this paper, a new approach combining the spectral subtraction in modulation (time-frequency)domain and the post processing for the autocorrelation functions of signal and noise is proposed to improve the performance of speech endpoint detection in low SNR environment. Firstly, the modified spectral subtraction used in modulation domain reduces the noise to increase SNR. Then, according to the feature we figure out that a quite difference in the ratio of maximum to secondary value of the peak of autocorrelation function exists between speech and noise, a method based on logarithmic energy and autocorrelation function is used for endpoint detection of the speech after denoising. Experiments show that the proposed method achieves a high performance and good robustness of speech endpoint detection under low SNR.
low SNR; modulation domain; autocorrelation function; logarithmic energy; endpoint detection
TN912.35
A
1000-3630(2018)-05-0457-11
10.16300/j.cnki.1000-3630.2018.05.010
2017-07-18;
2017-09-18
国家自然科学基金(61461011)、“认知无线电与信息处理”教育部重点实验室2016年主任基金(CRKL160107)、广西自然科学基金重点项目(2016GXNSFDA380014)
王瑶(1993-), 女, 江苏南京人, 硕士研究生, 研究方向为语音信号处理。
龙超, E-mail: bishe006@163.com
