面向大数据矩阵分解的推荐系统的研究
2018-11-09浩庆波万曙静
◆浩庆波 徐 岩 万曙静
面向大数据矩阵分解的推荐系统的研究
◆浩庆波 徐 岩 万曙静
(曲阜师范大学网络信息中心 山东 273100)
随着互联网应用范围的不断扩大和网络技术的飞速发展,互联网为人们提供了丰富且数量庞大的信息资源,但同时也造成了互联网信息过载等问题。推荐系统的产生则能够有效解决信息过载这类问题。推荐系统无需太多干预用户正常的互联网使用习惯,通过挖掘用户偏好,构建用户画像,从而针对不同用户提供个性化服务。本文研究了基于矩阵分解推荐系统的核心技术,并对推荐方法和评价方法进行研究阐述,最后对推荐系统的下一步研究方向作出展望。
大数据;协同过滤;矩阵分解
0 引言
面对互联网中存在的数量庞大且种类繁杂的数据资源,即便借助数据库技术和搜索引擎的关键字过滤技术,处理后的结果仍然有很大的数据级,人们很难在如此大量的数据中找到自身真正需要的数据信息。我们称上述问题为互联网信息过载[1]。推荐系统的应用则能够有效地解决信息过载这类问题[2]。而推荐系统是一种无需干预用户浏览行为,根据用户的自身属性、浏览历史、情境等信息来建立用户的兴趣模型,通过建立的兴趣模型从而为用户推荐其所需的网络信息资源。
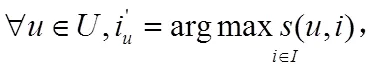
1 推荐系统推荐方法
推荐系统按照推荐方法大致可分为以下几类[3,4]:基于内容的推荐、基于协同过滤的推荐以及混合推荐三种推荐方法[5,6,7]。
基于内容的推荐方法思想是:根据用户已经浏览过的项目的内容,在推荐数据集中查找相似的项目内容,并将查找到的内容推荐给该目标用户。这种方法的局限性是无法发现用户新出现的兴趣点,推荐的新颖性不足。
相比于基于内容的推荐方法,基于协同过滤的推荐方法使用更为广泛,其思想为:首先根据目标用户的访问兴趣点,在用户集中寻找与目标用户兴趣点相似的用户。然后查找相似用户的访问记录,找到相似用户浏览过的且目标用户没有浏览过的信息资源。最后将这些资源推荐给目标用户。协同过滤推荐方法在保证推荐准确性的基础上兼顾了推荐的新颖性。但该推荐算法中若目标用户没有浏览记录或目标用户没有相似用户,就产生了冷启动问题。
为了解决冷启动问题,提出了混合推荐方法。混合推荐的本质是将多种推荐技术进行混合,使其相互弥补不同推荐方法中的缺点,从而获得更好的推荐效果。常用的混合策略包括:特征组合、加权、合并、转换等等。其中最常见的方法是将协同过滤的推荐与其他方式的推荐进行结合。
2 基于矩阵分解的推荐系统
2.1 用户偏好挖掘
用户的基本偏好会在该用户的社会属性中进行一定程度的表现,而用户在使用网络过程中所产生的浏览行为往往反映了其个人偏好。对于推荐系统来说,这些用户的社会属性信息和浏览行为可以用来描述用户画像[8]。针对不同的推荐场景,推荐系统有不同的用户行为记录,例如在新闻推荐中,用户点击、浏览、停留时间、收藏等。在音乐推荐中,用户行为有收听、收藏、评论等。推荐系统将用户行为映射成喜好评分(1-5),比如新闻推荐中收藏映射成5(非常喜欢),短时间内关闭映射成1(兴趣不高)。推荐系统可以借助这种方式对用户行为数据进行预处理,为用户建立用户喜好画像。
2.2 矩阵分解
推荐系统根据预处理后的用户画像与物品组成的用户-物品矩阵(User-Item矩阵),生成推荐列表。在Netflix Prize推荐算法竞赛中,涌现出一批优秀的推荐方法,矩阵分解方法是最流行和成功的方法。矩阵分解方法的本质是将User-Item稀疏矩阵分解成为两个低维隐含向量矩阵,这两个矩阵分别是用户-隐含向量和隐含向量-物品矩阵,通过将这两个低维矩阵相乘,得到原矩阵的一个相似非稀疏矩阵,用这个矩阵中的元素代表原User-Item矩阵中的缺失元素,得到一个top-k的推荐列表,推荐给用户。图1表明了矩阵分解应用在推荐系统的原理。
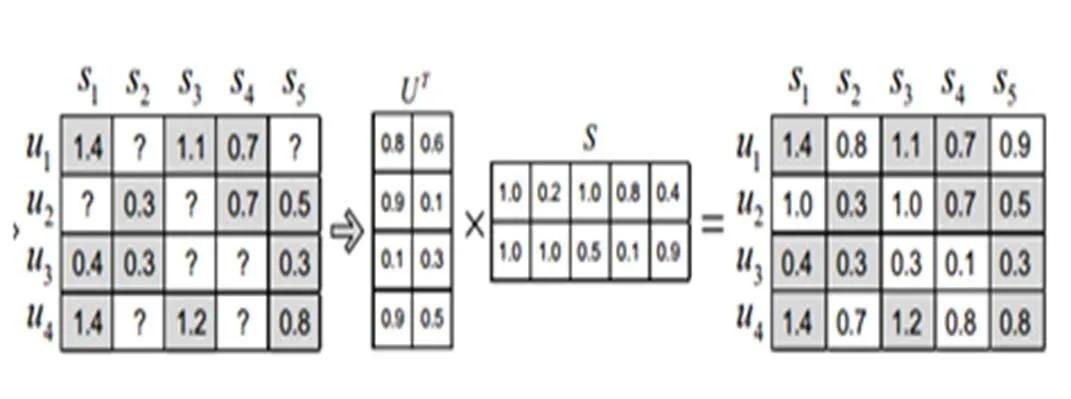
图1 矩阵分解应用在推荐系统
在物品推荐中,用户与物品相互作用产生的文本、情境信息中往往蕴藏着反映用户对物品的偏好程度的最本质信息,挖掘与探索这些信息对提高推荐结果有积极影响。而在自然语言处理情景中,LDA(Latent Dirichlet Allocation)则为发现文档集合主题的方法,作为发现用户隐含偏好的方法应用在推荐系统中,取得了非常优秀的效果。类似的做法还有奇异值分解(SVD)、非负矩阵分解等。
2.3 融合信息
传统基于协同过滤的推荐,仅考虑User-Item两个维度的数据。而现实世界中,显而易见的是,用户与物品的上下文信息(context)对用户评价物品有非常大的影响。例如在广告推荐中,如果广告的内容与用户正在浏览的网页内容高度契合,那么用户有很大的可能去点击浏览这个广告。上下文信息是指一切作用在用户与物品交互时候的信息。例如物品在页面中的位置,物品与其他物品的关系,用户浏览物品的时间、地点,以及用户的社交关系等信息。在推荐中引入上下文信息称之为情境感知推荐(CARS,context-aware recommender system)。实践表明上下文信息的引入对推荐效果的提高具有显著作用。在考虑上下文信息的推荐中,通常有三种做法:将上下文信息用来过滤user-item矩阵的方式称为前过滤;在传统推荐系统产生推荐列表后,用上下文信息对推荐列表进行匹配处理,称为后过滤;将上下文信息应用到推荐系统参数化模型建模的方式称为中过滤。
在中过滤方法中,引入上下文信息的方式主要有两种,一种是概率方法,通过贝叶斯概率等方法将上下文信息转化成现象概率,来预测在已知上下文信息条件下,用户与物品相互作用的概率,将预测高概率的物品集合生成top-k推荐列表;另一种方式是将传统的user-item二维矩阵扩展成user-item-context三维张量,如图2通过张量分解的方法将张量分解成三个低维矩阵,再扩展成原张量的相似张量生成推荐列表。图3表明了CP张量分解。
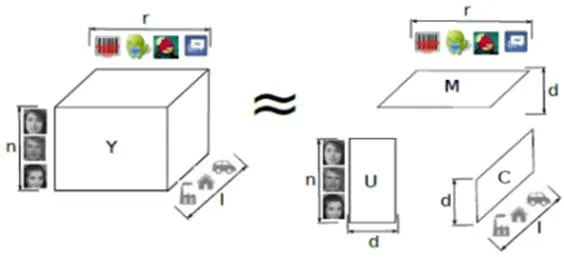
图2 CP张量分解

图3 基于张量分解方法的推荐
2.4 评价指标
在评价推荐系统的评价指标中,通常使用准确率(精度)、召回率(查全率)两个指标评价推荐系统算法。将推荐的资源数据随机的分割成为两组数据集:训练数据集和测试数据集。准确率是指在完成训练后的推荐系统推荐正确的结果占整个测试数据的比例,反映了推荐系统的准确度;召回率是指推荐系统推荐正确的结果占推荐中结果的比例,反映了推荐系统的查全率。召回率与准确率两个指标相互制约,若只考虑准确率,则系统的覆盖程度不够,反之亦然。为了平衡两者关系,提出了F-measure值来综合描述两者的关系。
3 总结与展望
在大数据环境下,推荐系统作为解决信息过载的有效途径正在受到越来越多学者的关注。本文介绍了推荐系统,并对推荐系统的核心技术做了一个初步的介绍,总结了推荐系统研究中的问题。在推荐系统未来的研究中,应对以下方面进行重点关注:
在过往的推荐系统研究中,针对特定的物品,根据其特征分析,提出的种种信息融合方式的推荐往往不能推广到一般,提出的方法缺乏鲁棒性。
基于内容的推荐在某些领域取得了一定效果,但是不同的待推荐物品对于内容的敏感程度是不同的,如何对内容的粒度进行有效过滤是一个值得研究的方向。
[1]Peng M,Zeng G,Sun Z, et al. Personalized app recommendation based on app permissions[J]. World Wide Web-internet & Web Information Systems,2017.
[2]Chua T S,Chua T S,Chua T S,et al.Cross-Platform App Recommendation by Jointly Modeling Ratings and Texts[J].Acm Transactions on Information Systems,2017.
[3]刘华锋,景丽萍,于剑.融合社交信息的矩阵分解推荐方法研究综述[J].软件学报,2018.
[4]余永红,高阳,王皓,孙栓柱.融合用户社会地位和矩阵分解的推荐算法[J].计算机研究与发展,2018.
[5]Sundermann C V,Domingues M A,Conrado M D S, et al. Privileged contextual information for context-aware recommender systems[J]. Expert Systems with Applications An International Journal,2016.
[6]李慧,马小平,施珺,李存华,仲兆满,蔡虹.复杂网络环境下基于信任传递的推荐模型研究[J].自动化学报,2018.
[7]朱天宇,黄振亚,陈恩红,刘淇,吴润泽,吴乐,苏喻,陈志刚,胡国平.基于认知诊断的个性化试题推荐方法[J].计算机学报,2017.
[8]Xu X,Dutta K,Datta A, et al. Identifying functional aspects from user reviews for functionality‐based mobile app recommendation[J].Journal of the Association for Information Science & Technology,2017.
