基于新媒体的视图像内容识别技术研究*
2018-11-07张家亮
张家亮,曾 兵,沈 宜,李 斌,贾 宇
(成都三零凯天通信实业有限公司,四川 成都 610041)
0 引 言
随着互联网产业的快速发展,以图片、视频为载体的新媒体在网络空间中的应用越来越广泛,已逐步成为使用率最高的媒体形态[1]。微信、微博、APP、网站和论坛等新媒体应用平台在给人们带来便利、消弭信息鸿沟的同时,也滋生了一些不良、不实的内容信息。一方面,新媒体应用平台具备发出声音快、事件传播快等特点,一旦出现不良不实内容,将会给国家和社会造成潜在或显在的负面影响和危害。另一方面,新媒体应用平台上的视频、图像等内容成几何级数增长[1],如何有效分析这些海量大数据,快速、有效、准确地识别出其中的不良不实信息,给各行业监管部门带来了巨大挑战。
1 新媒体简介
新媒体是价值信息的有效载体,为受众在第一时间内提供有效的信息,是新媒体以及所有媒体存在的基本价值。与传统媒体相比,新媒体足够新,符合时代的发展和大众对信息的需求。目前的新媒体以数字信息为基础,以互动传播为特点,通常以网络为载体,对大众提供个性化的信息。对新媒体的界定,目前业界没有统一定论。新媒体可以是数字电视、手机客户端、博客、微博等。这些终端主要借助互联网技术与用户相连,以海量、即时的信息吸引用户眼球,以充分共享的特征服务着不同用户。新媒体的出现满足了碎片化时代的需求。现代人们生活节奏快、压力大,碎片化阅读模式成为必然的趋势,而新媒体可以充分满足这一需求[2]。
常见的新媒体应用平台主要是两微一端一站,即微信、微博、网站、APP等。本文主要阐述两微一端一站的新媒体视图像内容监测技术研究情况。
2 新媒体视图像内容识别技术
两微一端一站等新媒体应用平台上发布了海量的视图、图片等信息。由于该平台具有很大的开放性和极强的互动性,为信息的快速广泛传播提供了便利,一旦出现违法违规等内容,将会给国家和社会造成潜在或显在的负面影响和危害。能够用于快速自动识别这些信息的新媒体视图像内容识别软件系统总体设计,如图1所示。

图1 新媒体视图像内容识别软件系统架构
软件整体架构从逻辑上可划分为数据采集层、数据清洗层、数据分析层和应用层。
数据采集层根据需要识别的范围,完成对指定的微博、微信公众号、APP、网站中的视频和图片数据的网络爬取。
数据清洗层对网络爬取的数据进行清洗,包括数据去重、数据转码和数据标准化等归一化处理,供数据分析层进行进一步的内容分析处理。
数据分析层针对清洗完毕的数据进行内容分析,主要通过视图像识别模型和视图像指纹两种方式来实现内容的智能识别。
应用层根据用户的内容识别需求,通过基于web的人机交互界面对软件参数、使用权限等进行系统管理,以及必要的业务逻辑配置对分析识别的数据进行存储、备份等管理,并对分析识别的结果予以统计分析展示。
2.1 多通道多来源的分布式爬虫技术
多通道多来源的分布式爬虫技术主要实现对指定网站、APP、微信公众号、微博帐号的数据爬取,并基于Redis消息分发技术作为基础数据的分布式部署,将数据采集来源从单纯的网页扩展到微博、微信公众号、APP等,极大地扩展了新媒体视图像内容识别的广度。
新媒体视图像内容识别软件系统中的爬虫系统基于该分布式爬虫技术和数据源调度方式,以满足多项目多用户为设计目标,有机地融合了对两微一端一站的视图像数据爬取的调度,为整个识别软件平台提供了全面的数据支撑方案,同时构建了以支撑大规模爬虫功能集群为基础的运维体系,理论上可满足各种数据通道与来源的无限扩展,并实现了大规模数据采集状态下网络带宽资源的最优化利用。多通道多来源的分布式爬虫的流程示意图,如图2所示。

图2 分布式爬虫流程
2.2 基于深度学习的视图像内容分类技术
传统的视觉词袋模型对图像进行底层特征提取与描述,对提取的特征进行量化得到视觉词典,随后将每幅图像表示成基于相同维数的视觉单词频率直方图向量,然后将该向量作为对图像的描述,最后将图像描述向量代入分类器中进行分类[3]。这虽然实现了低层特征到高层语义的映射,具有一定的有效性,但是视觉词袋模型采用SIFT算法提取的特征点存在区分度和代表性不高的缺点[3]。
新媒体视图像内容识别软件系统采用了基于深度学习的视图像内容分类技术,运用多模态特征的视频分类方法[4]进行视频内容的分类。该视频分类方法采用3D卷积方法提取图像和短视频特征,并放入长短记忆网络LSTM进行序列识别[5]。卷积神经网络、3D卷积神经网络为LSTM进行特征提取,长视频被分成一个个图像、短视频。每个图像、短视频通过卷积神经网络、3D卷积网络后,提取出一个特征向量。特征向量被送入LSTM进行序列识别。循环执行这个过程,直至所有的图像和短视频均被识别完成,从而更加合理地实现视频分类。基于深度学习的视图像内容分类流程,如图3所示。
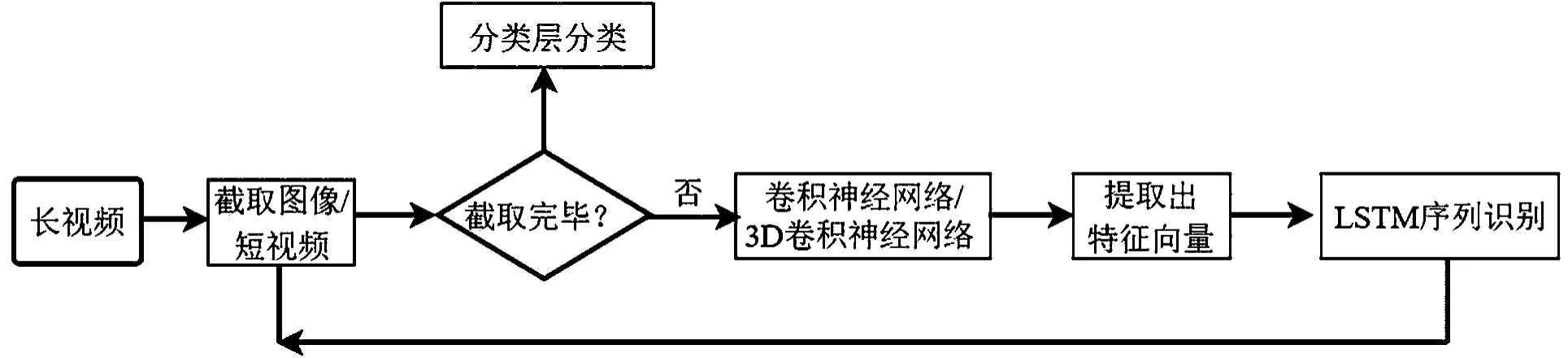
图3 基于深度学习的视图像内容分类
2.3 视频近似拷贝检测技术
传统视频拷贝检测的特征算法要计算整个视频子序列的时空相似性,因而其特征向量维数较高,导致相似度计算的复杂度较高[6]。
新媒体视图像内容识别软件系统采用视频近似拷贝检测技术,基于CUDA加速的SIFT特征计算与分布式系统视频特征索引相结合的方式实现,可以很好地检测出翻拍、涂鸦、形变、画中画等多种人为的特殊处理,从而实现快速的视频内容识别。该技术首先利用GPU服务器上的硬解码组件对视频流进行解码处理,然后采用关键帧提取的方法依次从解码后的视频序列中取出各个关键帧信息,并逐个提取关键帧的SIFT高维特征点,即视觉唯一特征(图像指纹),然后对这些特征点进行索引处理。通过视频高维特征集的索引与分布式检索系统相结合的方式,可实现大规模视觉特征集的快速搜索。视频近似拷贝检测的流程如图4所示。

图4 视频近似拷贝检测流程
3 结 语
本文对新媒体违法违规内容造成的危害和监管部门面临的监管挑战进行分析,介绍了新媒体视图像内容识别软件的技术架构,并对视图像内容识别的关键技术进行了详细的阐述。基于本文研究的相关技术成果,目前已经完成了新媒体视图像内容识别软件系统的基础平台研制。该平台采用多通道多来源的分布式爬虫技术,使采集数据更丰富、监测范围更广,已经实现了对两微一端一站的视图像数据的采集。通过融合多种模型算法的视图像识别技术,提高了视图像内容识别的效率和准确度,已经实现了暴恐、色情和赌博等多类识别及融合应用。目前,该平台已在多个行业监管部门进行部署试用,将有助于提升行业监管部门的监测和布控能力。
