基于核心向量机的多任务概念漂移数据快速分类
2018-11-05史荧中王士同邓赵红侯立功钱冬杰
史荧中,王士同,邓赵红,3,侯立功,钱冬杰
随着计算机信息技术的发展,每天都会产生大量电信服务、电子商务、金融市场、交通流量、网络监控、超市零售等方面的数据,这些数据是持续增加且不断变化的。由于数据特征会随着时间逐渐变化,针对这些非静态数据的分类、回归、聚类模型也在随着时间而缓慢漂移,称为概念漂移[1-2]。对概念漂移的研究已在理论上[1-4]及交通流量预测[5]、超市客户行为分析[6]、气体传感器阵列漂移[7]、垃圾邮件过滤[8]等应用场合取得了良好的效果。概念漂移建模过程中每个时刻的数据量都很少,因而需要借助相邻时刻的一些数据来构建合适的当前时刻模型。以往针对概念漂移分类所作的工作大多是基于滑动窗算法[9-11]的思路,即采用一定时间窗口(区间)内的数据进行建模。2011 年,Grinblat等[12]借鉴 Crammer等在多任务学习中兼顾局部优化与全局优化的策略,提出了时间自适应支持向量机[13]方法来求解渐变的子分类器。Shi等[14]提出了增强型时间自适应支持向量机方法,在提高分类性能的同时,从理论上保证了其对偶为凸二次规划问题。
由于生活中的概念漂移问题并不是孤立出现的,如某个气体传感器阵列上对多种气体的测定数据可能会同时漂移;相邻城市的天气情况具有一定的关联;相近街区的交通流量会相互影响等。对多个相关概念漂移问题同时建模,挖掘其他问题中的有效信息,能对建模起到有益的补充。共享矢量链支持向量机[15](shared vector chain supported vector machines, SVC-SVM)方法通过对相关概念漂移问题协同建模,有效地提升了所得模型的泛化性能。但由于具有较高的算法时间复杂度,限制了其在数据量急剧增长的社会现状下的应用能力。
现在已进入大数据时代,各种社交和电子商务等信息量都越来越大,多任务概念漂移算法的时间复杂度也变得越来越重要。SVC-SVM方法可转化为核空间中的另一SVM问题,算法时间复杂度一般为,其中为样本容量。如采用SMO(sequential minimal optimization)[16]方法来求解,其复杂度可降为,但SVC-SVM方法仍然无法从容面对大规模概念漂移数据集。本文旨在寻找出一种新的概念漂移学习方法,除了能保持SVC-SVM方法良好的分类特性外,又能在面对多任务概念漂移大规模数据集时具有较好的算法时间性能。
结合前期在概念漂移领域的研究基础[14-16],本文提出了共享矢量链核心向量机(shared vector chain core vector machines, SVC-CVM)方法,并基于核心向量机[17-19](core vector machine, CVM)理论给出了SVC-CVM方法的快速算法。所提SVCCVM方法具有以下特点:
1)面对多任务概念漂移问题时,SVC-CVM方法优于独立求解单个概念漂移问题的TA-SVM及ITA-SVM方法;
2)SVC-CVM方法采用了与SVC-SVM方法相同的技巧,即假设多个概念漂移问题共享渐变的矢量链序列,因而在分类性能上,SVC-CVM方法与SVC-SVM方法相当;
3)SVC-CVM方法可以借鉴CVM理论[17]设计出快速求解算法,以处理多任务概念漂移中数据量较大的问题,算法时间复杂度接近。
1 概念漂移问题相关研究
在概念漂移研究方面,传统的研究是基本滑动窗算法,这是一类局部优化模式。TA-SVM和ITA-SVM方法对局部优化和全局优化进行了权衡,取得了良好的效果。
1.1 单任务概念漂移分类方法
TA-SVM[13]方法及ITA-SVM[14]方法针对的是传统的单任务概念漂移分类。假设有T个按时间顺序采集的子数据集,TA-SVM方法在优化各子分类器的同时,还假设子分类器应该能够光滑地变化,因此约束相邻子分类器之间的差异,其基本思想可由(1)式来表示。

1.2 SVC-SVM方法及其对偶
为了能进一步挖掘出相关概念漂移数据集中蕴含的有效信息,需要协同求解多个分类模型。假定现有K个相关概念漂移数据集,每个概念漂移数据集中的数据由T个按时间顺序采集的子数据集组成,每个子数据集中的数据量为m个。将所有数据合并记为数据集,。记为 第个任务在第T)时刻的分类模型,为第t 时刻的共享矢量,表示在第t 时刻共享矢量与第个任务之间的差异。面向多任务概念漂移分类的共享矢量链支持向量机方法SVC-SVM的原理可通过式(2)来表示:
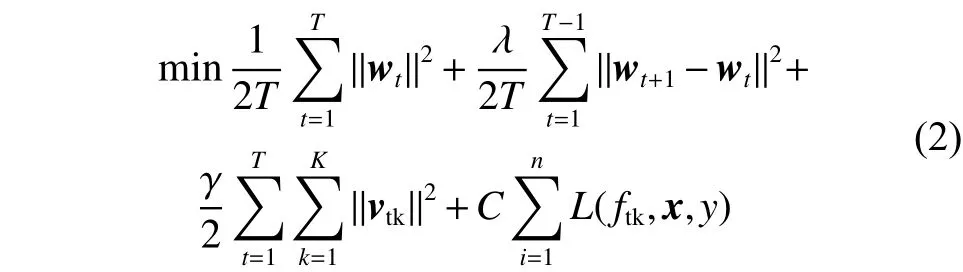
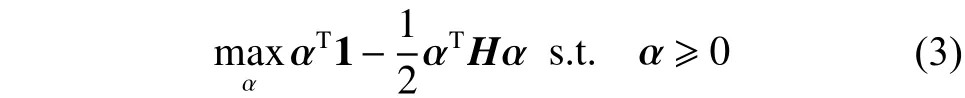
式中:H为扩展核空间上的某个核函数,具体表达形式可以参见相关文献[15]。从式(3)可知,SVCSVM方法对多个概念漂移问题同时建模,其对偶问题为核空间中的另一个支持向量机问题,当采用普通方法来求解此二次规划问题时,其算法时间复杂度为,即便采用SMO[16]方法来求解SVC-SVM的对偶问题,使其复杂度降为,仍然是无法承受计算的代价,难以从容面对现实生活中数据规模较大的应用场景。
2 共享矢量链核心向量机及快速算法
2.1 共享矢量链核心向量机
鉴于SVC-SVM方法在针对多任务概念漂移大规模数据集时算法时间复杂度偏高,本文借鉴CVM[17-19]的思路,提出了与SVC-SVM方法在分类性能相似,但在数据量较大的场景时又能进行快速处理的SVC-CVM方法。SVC-CVM方法借鉴了SVC-SVM方法的思想,为了能进一步用快速算法求解,本文按文献[17-18]的方法对SVC-SVM[15]的目标函数稍作变化,采用平方损失函数,通过推导得到可以用CVM方法快速求解的对偶形式。
SVC-CVM方法的目标函数为


由KKT条件,J取得极值时,有
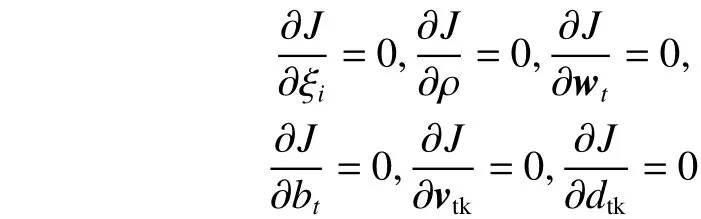
因此有:

式中:
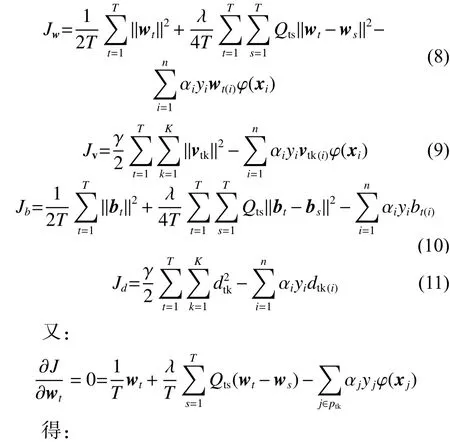
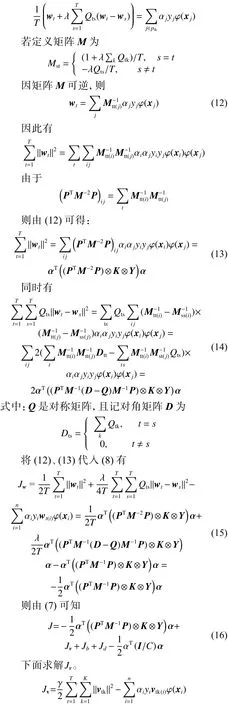

原始问题的对偶问题如下:
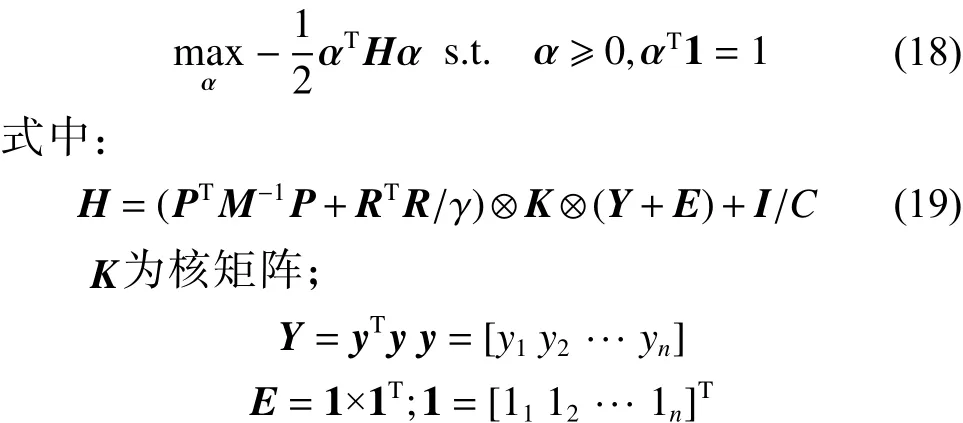
由此,SVC-CVM方法中虽然包含了多个数据流,但其对偶问题仍相当于核空间中的另一个SVM问题,可以用常规方法来求解,其算法时间复杂度为,在算法效率上并不具有优势。因此下文将介绍SVC-CVM的快速求解方法。
2.2 核心向量机
求解最小包含球(minimum enclosing ball,MEB)是一个数学问题,等价于求解一个二次规划问题[17-19],如式(20)所示:
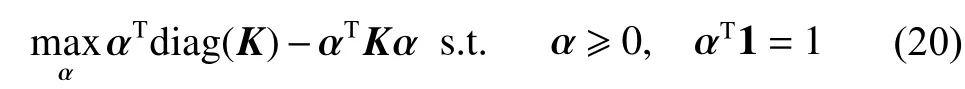
Tsang等在文献[17-18]中指出,形如式(20)的二次规划问题,如果核矩阵对角线元素为常量,则均等价于求解MEB问题。他们借助求解MEB问题时的近似包含球方法[19],提出了核心向量机(core vector machines, CVM),在处理大规模数据集时有接近线性的时间复杂度。对形如式(20)的二次规划问题,即使核矩阵对角线元素不为常量,也可以使用核心集方法进行求解,这时就需要给核空间中每个样本点都添加一个新的维度,样本在新特征空间中表示为,然后求解在新特征空间中的最小包含球。该问题的形式如下:

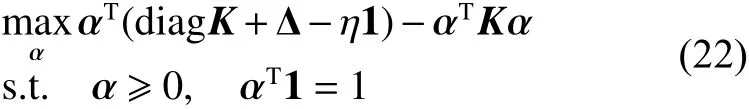
2.3 SVC-CVM的快速算法
当使用普通方法来求解SVC-CVM时,其求解时间复杂度为,对于多任务概念漂移大规模数据集来说,是相当大的计算开销。对比式(18)和式(22),它们具有相似的形式,因此,SVCCVM方法可以利用核心向量机技巧来求解。可以将式(18)等价地改写为
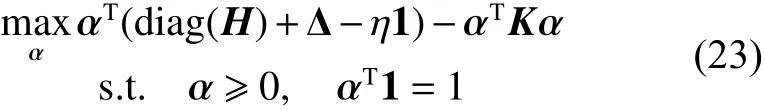
SVC-CVM算法的输入为多任务概念漂移大规模数据集S, 核心集逼近精度、、等参数;输出为核心集和权重系数。下面给出实现步骤:
由于SVC-CVM算法是基于核心集理论的,因而在描述算法的时间与空间复杂度时,可以参考文献[17-18],得到相关结论:
输入 数据集S, 最小包含球近似精度;
5) 计算新的中心到其他各点的距离 ;
3 实验研究和分析
本节将对SVC-CVM方法进行实验验证,实验将从SVC-CVM方法的分类准确率、SVCCVM算法的时间性能两个方面展开。这里有必要首先验证其分类准确率。1)需要考察引入分类间隔及采用平方损失函数以后,SVC-CVM算法是否保持了良好的分类能力;2)因为SVC-CVM方法的有效性是其快速算法有效的必要条件。本文另外选取了在单任务概念漂移建模中取得良好效果的两个方法作为对比算法,作为对比算法的共有:1)TA-SVM 方法[13];2)ITA-SVM 方法[14];3)SVM-SVM方法[15]。为了对比的客观性,本节实验中所使用的数据集及实验的设置都参照对比算法TA-SVM[13]。实验环境为MATLAB R2013a,操作系统为Windows7, 8 GB内存及3.30 GHz奔腾处理器。
3.1 实验设置
实验中涉及的各方法与相应参数在表1中列出。

表 1 实验所用的对比方法及相应参数Table 1 Methods and parameters used in experiments
本文独立生成相同分布的训练集、验证集和测试集各10组,共进行10次重复实验,以获得比较客观的实验结果。实验分为参数优化和建模测试两个阶段,首先需要基于训练集,利用验证集获得各方法的最优参数;其次基于得到的优化参数对训练集建模,并利用测试集来获得各方法的性能。本文采用网格遍历法来寻找最优参数。
将旋转超平面数据集记为数据集DS1中的第1个任务Task1,Task1数据集的样本量为500,采样于独立分布的2维立方体,两类之间的边界是一个超平面,并绕原点缓慢旋转。设超平面的法向量为,Task1的训练、验证、测试数据由式(24)生成:
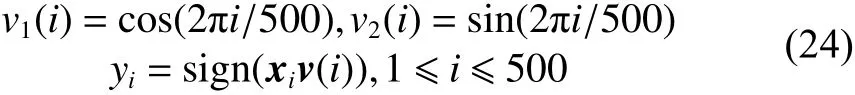
数据集DS1中的第2个任务Task2数据则由Task1模型顺时针旋转一定的角度后随机生成,以体现出Task2与Task1模型的相关性。
将TA-SVM方法中所使用的高斯漂移数据集记为数据集DS2中的第1个任务Task1,数据集中包含两个类别,共含有个数据点,每个类别中数据的特征都在缓慢变化。Task1的训练、验证、测试数据由式(25)取时独立生成,DS2中还包含另一个概念漂移数据集Task2,其数据同样由(25)式生成,这时,以体现任务之间的差异性。

将DS1、DS2中的类别标签按一定比例随机替换以模拟噪音数据,得到数据集DS3、DS4,用于测试SVC-SVM方法在噪音条件下的分类能力。
数据集DS5、DS6由DS1, DS2逐步加大采样量分别得到,它们用于测试SVC-CVM方法的算法时间复杂度。实验所用数据集如表2所示。
3.2 SVC-SVM的分类性能
本子节基于数据集DS1和DS2来观察SVCCVM方法的分类能力,并将在噪音数据集DS3、DS4上观察SVC-CVM方法在噪音条件下的性能。
针对数据集DS1,依据文献[13]的策略,我们独立生成10组训练集、测试集及用于选择最优参数的验证集。根据前述的实验设置,实验分为优化参数和建模测试两个阶段。核函数选用最常用的线性核及高斯核。当两个概念漂移数据Task1、 Task2呈现出不同的偏离程度时,求得各方法在两个概念漂移数据Task1、Task2上的分类精度及平均值Average。每个方法对各训练集共计10次运行后的平均分类精度及标准差记录在图1中。

表 2 实验所用的数据集Table 2 Description of artificial dataset
由图1可以得到如下观察:
1)在数据集DS1上,不管采用高斯核还是线性核,当多个任务呈不同偏移程度时,协同求解多个概念漂移问题的SVC-SVM、SVC-CVM方法在任务Task1和Task2上总是优于独立求解单个概念漂移问题的TA-SVM和ITA-SVM方法,显示了协同求解多任务概念漂移问题是有效的。
2)随着多个任务之间偏离程度的增加,相对于独立求解单个任务,协同求解方法的优势逐渐减弱。
3)不管是采用高期核还是线性核,也不管任务间的偏移程度,用普通方法求解的SVC-SVM与核心集技术求解的SVC-CVM的分类性能都非常接近。
对高斯漂移数据集DS2,按照同样的实验流程,求得当两个任务Task1、 Task2呈现出不同的偏离程度时,各方法的分类性能。每个方法对各训练集共计10次运行后的平均分类精度及标准差记录在表3及表4中。
由表3及表4可以得到如下观察:
1)在高斯漂移数据集DS2上,不管是采用高斯核还是线性核,协同求解多个概念漂移问题的SVC-SVM、SVC-CVM方法总是优于独立求解单个概念漂移问题的TA-SVM方法及ITA-SVM方法,与数据集DS1上的实验结果相似。
2)采用高期核或线性核时,不管任务间的偏移程度,SVC-CVM与SVC-SVM方法的分类性能是相当的。
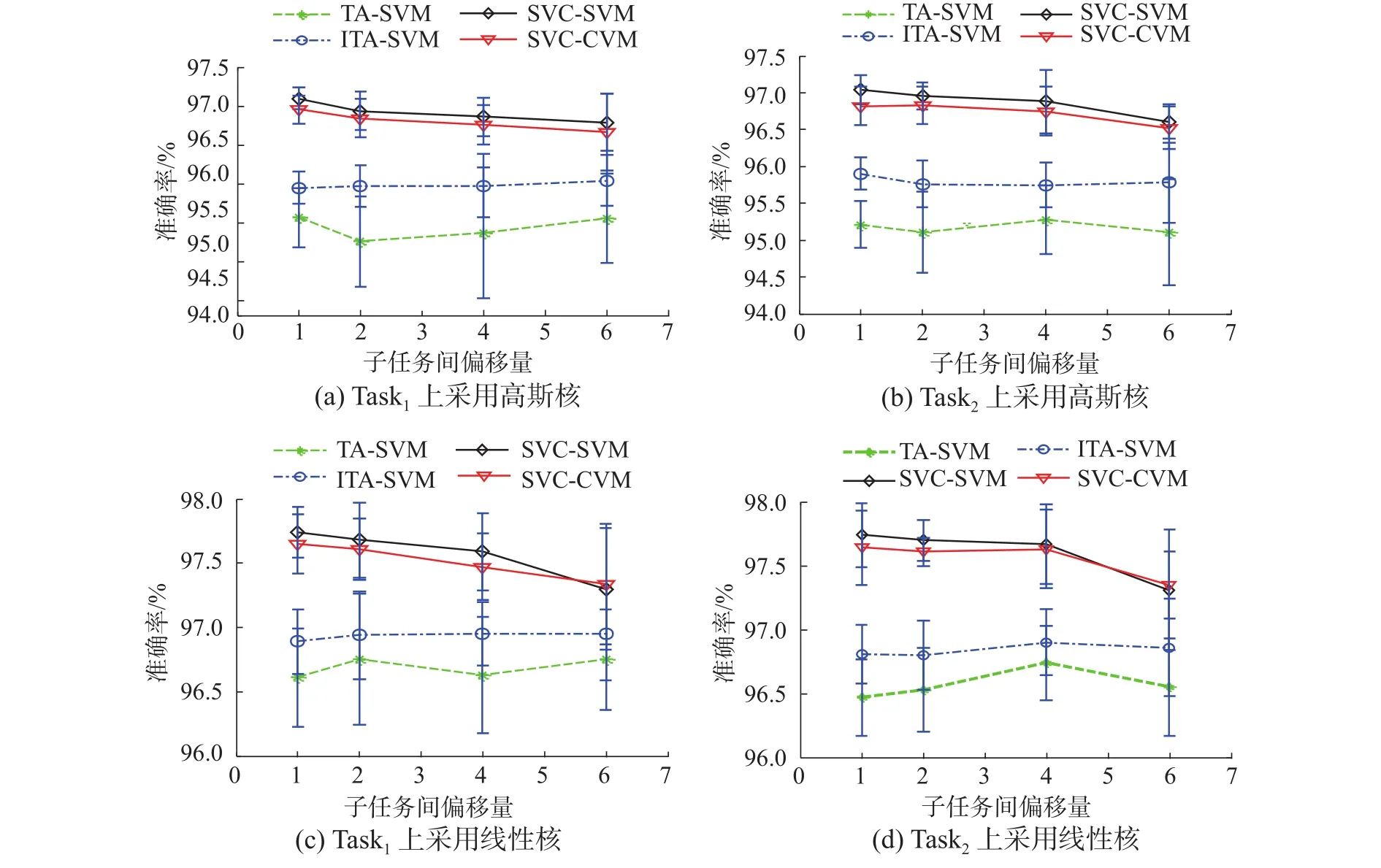
图1 旋转超平面数据集DS1上各概念漂移数据之间偏移角度变化时的分类性能Fig. 1 Classification accuracies on DS1 with different diversities of data stream
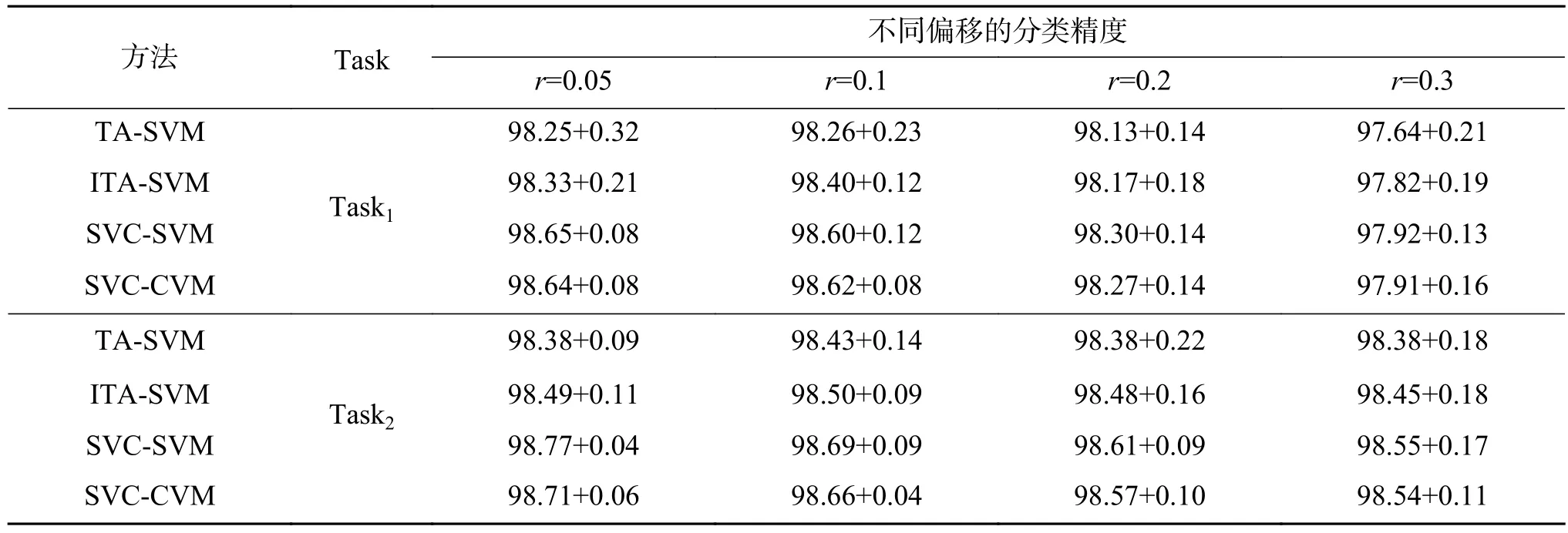
表 3 数据集DS2上采用高斯核时各方法的平均分类精度Table 3 Classification accuracies on dataset DS2 with Gaussian kernel
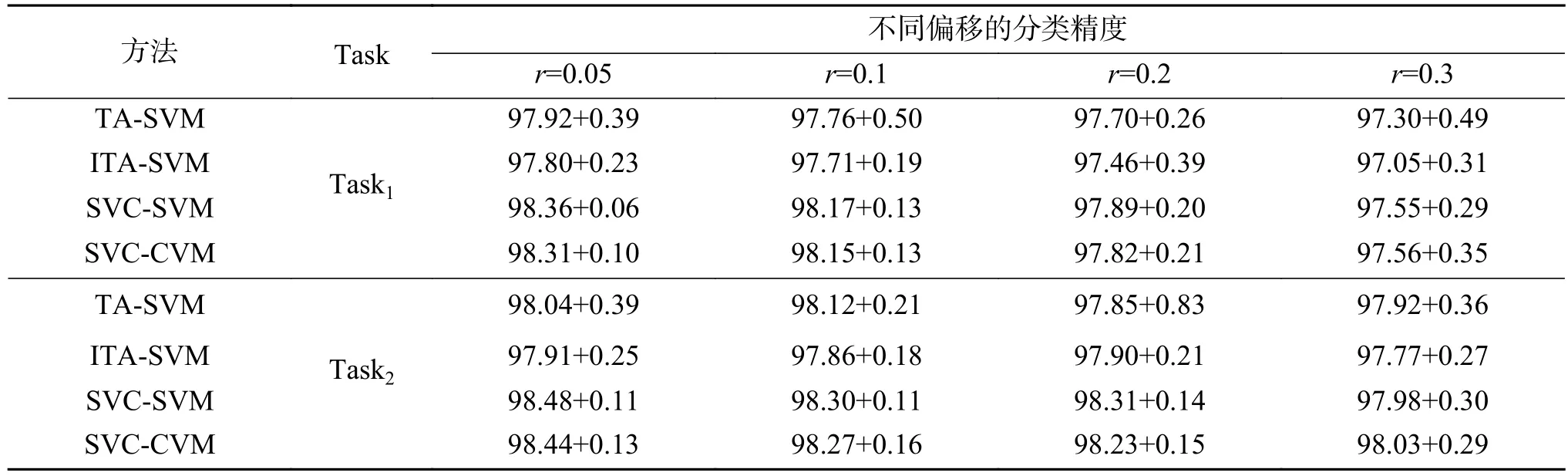
表 4 数据集DS2上采用线性核时各方法的平均分类精度Table 4 Classification accuracies on dataset DS2 with Linear kernel
下面继续评估SVC-CVM方法在噪音数据集DS3和DS4上的表现,以观察本文方法的抗噪能力。与文献[13]的实验设置相同,通过将DS1和DS2上的类别标签随机变换来模拟噪音数据,噪音比例分别为2%~10%。在数据集DS3和DS4上,当含有不同噪音时各方法的实验结果记录在表5到表6中。
由表5及表6可知:
1) 在噪音数据集DS3及DS4上,不管采用高斯核或是线性核时,SVC-SVM和SVC-CVM方法相对于独立求解的TA-SVM方法及ITA-SVM方法,都有较大的优势。

表 5 数据集DS3上各方法在不同噪音下的平均分类精度Table 5 Classification accuracies on dataset DS3 with Different kernel
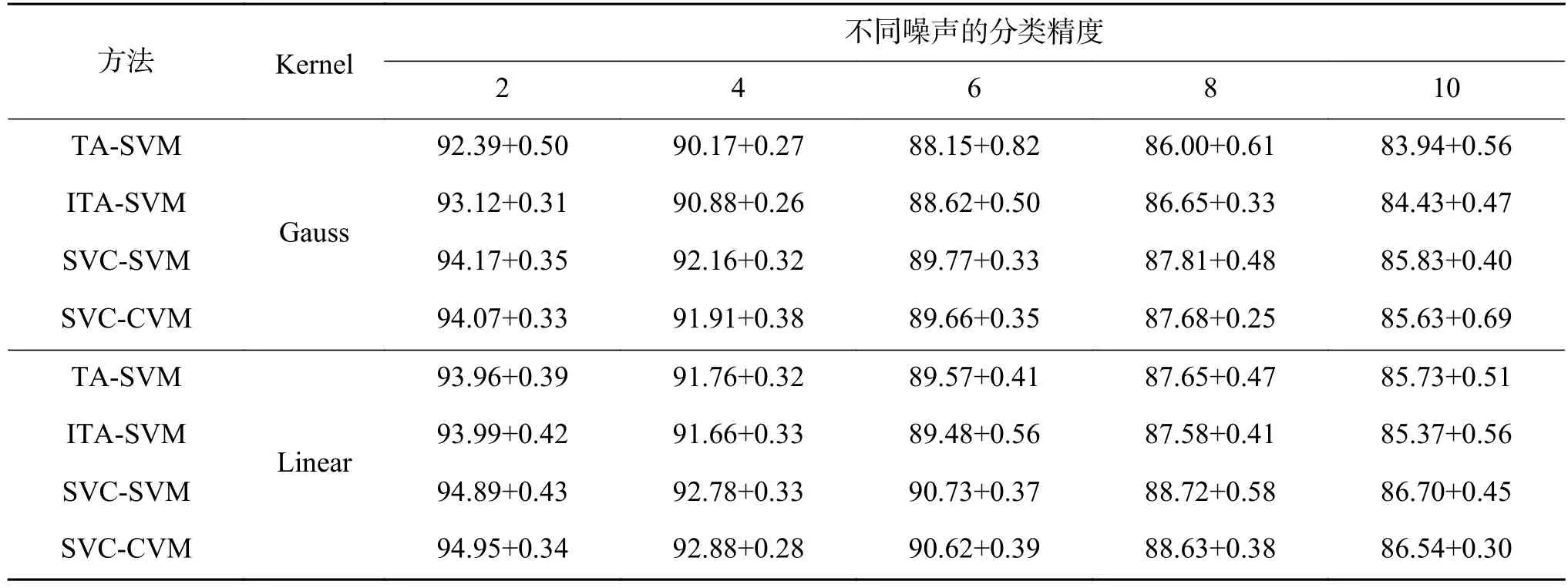
表 6 数据集DS4上各方法在不同噪音下的平均分类精度Table 6 Classification accuracies on dataset DS4 with Different kernel
2) SVC-CVM与SVC-SVM方法在噪音情况下的分类性能是相当的。
3.3 SVC-CVM方法的时间性能
本子节将以数据集DS5、DS6为基础来评估各方法的算法时间效率。各数据集的样本量从500缓慢增加到30 000个。对于数据集DS5,独立生成10组训练集及测试集,并将各方法在取不同容量样本时的平均准确率及平均训练时间显示在图2中。随着数据量增加时,为了能更准确地观察各方法时间性能的量级,本文分别以(为样本量)为横坐标,以(S为运行时间,单位为s)为纵坐标描述各方法的时间性能图,将始的指数曲线转化为线性曲线,斜率代表运行时间的指数量级,如图2(b)所示。
由图2可以得到如下观察:
图2(a)可知,在数据集合DS5上,随着训练数据量的加大,各方法的泛化性能稳定增加。同时SVC-SVM和SVC-CVM方法优于独立求解单个概念漂移问题的TA-SVM和ITA-SVM方法。由于用普通SVM方法求解时需要先求解相应方法的核矩阵,因此受硬件约束较大,当数据量较大时,相应方法无法继续求解。而SVC-CVM方法采用核心集技术求解,相应的支持向量逐个添加到核心集中,不需要预先计算核矩阵,因而能处理更大容量的数据,得到泛化能力更强的模型。
图2(b)可知,在数据集DS5上,求解各方法所需时间与数据量之间呈现稳定的指数级关系,其中SVC-CVM方法所表示的准直线的斜率明显小于其他方法,显示了SVC-CVM方法在时间效率上远优于TA-SVM、ITA-SVM与SVC-SVM方法。

图2 各方法在数据集DS5上的性能Fig. 2 Performance on DS5
在数据集DS6上,按相同的流程进行训练及测试,并将各方法在不同容量样本上的平均准确率和标准差、平均训练时间和标准差分别记录在表7及表8中(其中—表示在本文实验环境中无法得到相应结果)。
由表7及表8可以得到如下观察:

表 7 在数据集DS6上当不同数据量情况下各方法的平均分类准确率及标准差Table 7 Classification accuracies with different dataset size of DS6 %
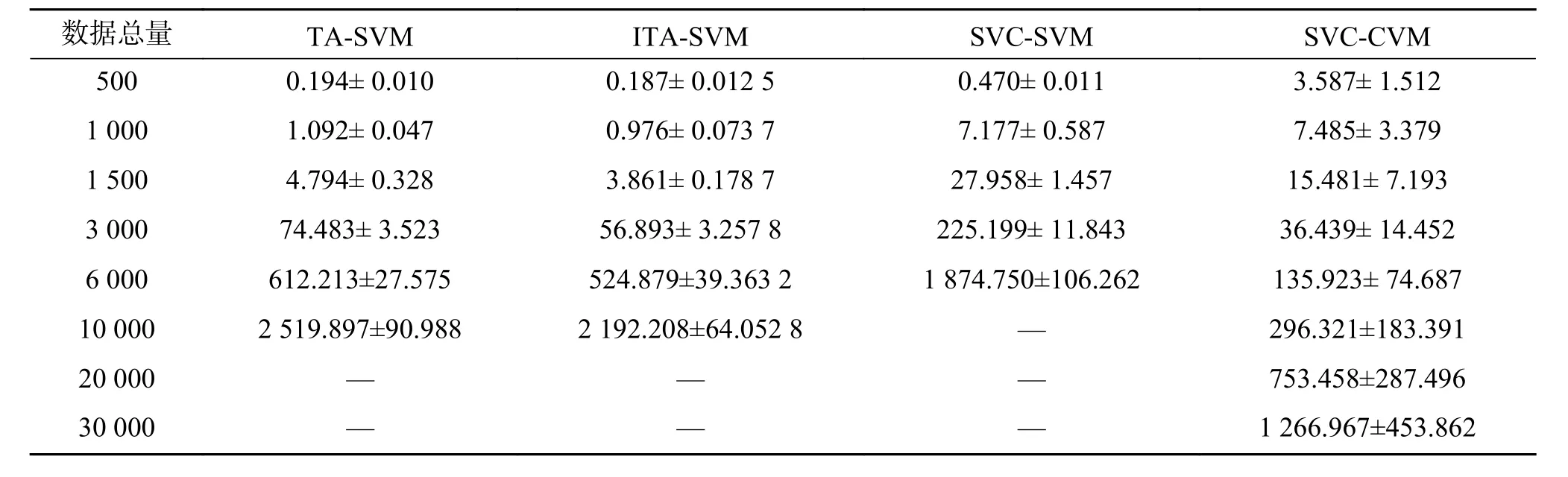
表 8 在数据集DS6上当不同数据量情况下各方法的平均训练时间及标准差Table 8 Training time with different dataset size of DS6 s
1) 从表7中可以看出,在数据集DS6上,随着训练数据量的增加,各方法的分类性能逐渐增高,其中SVC-SVM和SVC-CVM的分类性能相当,都优于独立求解单个概念漂移问题的TA-SVM与ITA-SVM方法。
2) 从表8可以看出,在数据集DS6上,当数据量较小时,SVC-CVM方法的求解时间上并不具有优势。当数据量的逐渐增加时,SVC-CVM方法求解时间的变化很缓慢,明显优于用普通二次规划方式进行求解。
在数据集DS5和DS6上的实验可知,当数据量不大时,SVC-SVM方法和SVC-CVM方法都优于独立求解的方法,且两者的分类性能相当。当数据量很大时,只有SVC-CVM方法能处理较大规模数据集,且在算法时间性能上保持近线性时间复杂度,因而具有较强的实用性。
4 结束语
本文提出了适用于对概念漂移大规模数据集快速求解的多任务核心向量机方法SVC-CVM。由于采用共享矢量链技术协同求解多个概念漂移问题,SVC-CVM方法在分类精度上等价于SVCSVM方法,明显优于独立求解单个概念漂移问题的TA-SVM及ITA-SVM方法,且SVC-CVM算法在面对多个概念漂移大数集时仍然能够进行快速建模决策。当然SVC-CVM方法仍需要进一步研究,特别是多任务概念漂移大规模数据集的回归问题;多任务概念漂移大规模数据集的单类问题,将是更有意义的挑战。
