随机森林和支持向量机在利用超声影像特征信息诊断乳腺病变性质的应用价值探索*
2018-11-05赵子龙何英剑欧阳涛姚晨
赵子龙 何英剑 欧阳涛△ 姚晨△
【提 要】 目的 探索随机森林和支持向量机诊断模型在利用人工判读的超声影像特征诊断乳腺病变性质的应用价值。方法 使用相同的训练数据和测试数据,在不同的自变量筛选策略下将随机森林、支持向量机方法建立判别乳腺病变性质的诊断模型与传统logistic回归模型进行比较,以ROC曲线下面积(AUC)作为预测效果的主要评价指标对各模型进行评估与比较。结果 不同自变量筛选策略下随机森林、支持向量机在测试集上的AUC均与logistic回归模型非常接近,差异无统计学意义。结论 随机森林和支持向量机预测效果并未见明显高于logistic回归,考虑到logistic模型在易用性、可解释性上的优势,建议在利用人工判读的超声影像特征建立诊断乳腺病变性质的预测模型时仍使用传统logistic回归。
乳腺癌是中国女性发病率最高的恶性肿瘤[1]。在目前对乳腺癌缺乏有效的病因学预防手段的情况下,合理开展乳腺癌筛查,实现早发现、早诊断、早治疗的二级预防尤为重要[2]。乳腺超声影像检查是乳腺癌筛查的主要方法之一,而基层超声医生的水平、经验不足是目前筛查效果不理想的主要原因[3]。建立基于超声影像特征诊断乳腺病变良恶性的预测模型将有助于协助超声诊断医师作出更准确的诊断[4]。logistic回归由于其易用性与其回归系数较强的可解释性成为医学研究中因变量为二分类变量情况下建立诊断模型时应用最为广泛的方法。国内利用超声影像特征建立乳腺病变诊断模型的研究也多使用logistic回归[4-6]。随机森林、支持向量机作为算法建模方法[7],并不假设数据产生于特定的模型,有能力识别自变量与因变量间非线性的复杂关系,且建模时需要调整的参数相对较少。随机森林和支持向量机分别在预测糖尿病并发视网膜病变[8]、大面积脑梗患者预后[9]和乳腺癌术后复发[10]、急性出血性脑卒中早期预后[11]等应用中显示出了优于传统logistic模型的预测准确性。
本研究将探索随机森林和支持向量机诊断模型在利用超声影像特征信息诊断乳腺病变性质的应用价值,考察随机森林、支持向量机模型是否有比传统logistic回归模型更强的预测能力。
资料与方法
1.资料来源
研究数据为北京肿瘤医院2010年11月至2016年5月累积收集的具有全自动超声影像检查资料、病灶超声影像最大径2cm以下且有组织病理学确诊的1345例病例中成功读取超声影像特征变量的1334例,其中恶性827例,占比61.99%。
研究中的因变量为经组织病理学确诊的乳腺肿块的良恶性分型。研究中的自变量为由超声影像专家组定义的超声影像特征变量,测量数据由北京肿瘤医院超声医生在盲态下根据超声影像判读提取。具体变量赋值情况见表1。

表1 各变量赋值表
2.随机森林基本原理
随机森林是由Leo Breiman于2001年[12]提出的基于决策树的集成学习算法,其特点主要包括:需要调节的参数较少,通常不需要费力调整参数即可取得很好的预测效果;对数据预处理(标准化等)的需求低,容易使用;大量应用实例表明随机森林有很强的预测能力,对数据的异常值和噪声具有很好的容忍度;随机森林可以评估自变量重要性,可据此进行自变量筛选。
随机森林的基本思想是建立很多预测效果较好而在不同方面有过拟合的决策树,通过平均它们的预测结果可以减小过拟合的程度同时仍能保持预测能力[13]。建立随机森林模型的具体过程为:(1)利用bootstrap重采样方法从训练集中有放回地抽取与原样本量相同的样本,重复M次得到M个数据集;(2)在每个数据集上建立决策树,建立决策树时采用递归二元分裂的算法自上而下每次将原样本分枝为2个子样本直至每个叶中样本数不高于预定参数nodesize,在每个节点处从原自变量中随机选出mtry个自变量,在此范围内根据分枝后“不纯度”最小为准则选择该节点处分枝的变量与阈值,得到M个决策树;(3)预测结果取决于M个决策树投票的结果(本研究所用软件包[14]中则是将每颗树对某类的预测概率值取平均作为该类的预测概率,以此实现判别)。衡量节点“不纯度”的指标有Gini系数、交叉熵、错分率[15]。本文采用Gini系数。另外,根据用某变量进行分枝前后Gini系数的平均改变量可以对自变量的重要性进行评分[15]。随机森林模型主要的参数为:决策树数量M、在建立决策树时各节点随机选取的候选自变量个数mtry、决策树停止分枝规则中设定的叶中样本量界值nodesize。
3.支持向量机基本原理
支持向量机是由Vapnik[16]在20 世纪90 年代提出的方法,它具有坚实的理论基础,理论上得到的是全局最优解,具有无局部最小点、预测可靠性高且泛化能力强的特点。其他特点主要包括:由于训练样本中只有少数靠近决策边界的支持向量决定支持向量机模型,因此支持向量机对数据具有一定的稳定性;支持向量机的预测能力对自变量的尺度以及参数的设定都比较敏感,需要进行仔细的数据预处理及参数选择;模型的可解释性较差;支持向量机本身并不能有效地进行自变量筛选,常与其他方法结合使用。
支持向量机主要思想是将待分类数据进行非线性特征映射,使之投影到在有一定容错的条件下线性可分的更高维特征空间,在新特征空间中通过构造最优分类超平面的方式对数据进行分类[17]。最优分类超平面的确定只与在高维特征空间中不同类别之间边界附近的样本点有关,这些样本点被称为支持向量[15]。对样本的二分类取决于判别函数(即最优分类超平面表达式)的正负符号。通过在训练集上将判别函数值作为自变量拟合logistic回归模型可以使支持向量机输出概率预测值[18-19]。判别函数的计算基于样本在新特征空间中与各支持向量间的内积以及各支持向量的重要程度。使用核函数可以直接计算与该核函数对应的新特征空间中样本之间的内积。本文使用最常用的径向基核函数。径向基核函数对应无限维度的特征空间,它考虑所有可能的由原始特征组成的多项式特征,但特征的重要度随着多项式次数的增高而降低[13]。模型主要的参数为:控制对错分的惩罚程度的正则化参数C与控制样本间距离尺度的径向基核宽度倒数σ。
4.训练集与测试集划分
以因变量为分层因素,随机抽取75%(1000例)作为训练集,剩余25%样本(334例)作为测试集。训练集用于自变量筛选、探索性分析、构建各模型,测试集用于评价各模型表现。
5.自变量筛选
模型中纳入过多自变量会增大模型复杂度,同时也会增大模型过拟合的风险。因此在建立模型前常需要进行自变量筛选。如果只选择单因素分析有统计学意义的自变量,则那些只在与其他自变量同时使用时才有很高预测价值的自变量会被剔除。本研究采用三种自变量筛选策略:(1)不进行自变量筛选使用全部25个自变量;(2)利用logistic回归筛选自变量:在训练集上以乳腺肿块的良恶性为因变量,各超声影像特征变量为自变量建立logistic回归模型,使用后退法筛选自变量,筛选自变量时检验水准设为0.05;(3)利用随机森林筛选自变量:在训练集上以乳腺肿块的良恶性为因变量,各超声影像特征变量为自变量建立随机森林模型,根据随机森林对各自变量计算的重要性评分选出与logistic回归筛选自变量相同数量的自变量。
6.模型建立与参数设定
在训练集上分别用logistic回归、随机森林、支持向量机建立诊断模型。在建立诊断模型时使用不同的自变量组合各建三个模型以更全面考察三种建模方法:(1)不进行自变量筛选,使用全部自变量;(2)使用logistic回归筛选的9个变量作为自变量;(3)使用随机森林筛选的9个变量作为自变量。以约登指数最大为准则选取诊断模型进行判别时使用的截断点。在建立随机森林模型与支持向量机模型时利用网格搜索(grid search)方法[13]尝试预先设定的各参数组合,以训练集上5折交叉验证得到的平均AUC最大为依据确定模型使用的参数。随机森林建模时M设为500,nodesize设为1,参数mtry的挑选范围为2~6。支持向量机建模时参数C与σ的挑选范围均为[0.01,0.1,1,10,100]。
7.统计分析与软件实现
在测试集上以AUC为主要指标对各模型的表现进行评价。使用Delong,Delong和Clarke-Pearson非参数法[20]计算各模型在测试集的AUC置信区间,以logistic回归为对照组比较各模型的AUC值以检验随机森林与支持向量机的预测效果是否优于logistic回归,检验水准设为0.05。数据清理、logistic模型建立应用SAS 9.4实现,随机森林、支持向量机的模型建立及ROC分析应用基于R语言的相关软件包(caret包[21]、ranger包[14]、kernlab包[18]与pROC包[22])实现。
结 果
1.训练集与测试集的因变量分布情况
对样本进行拆分后,训练集含样本1000例,其中恶性肿块620例,占比62.00%;测试集含样本334例,其中恶性肿块207例,占比61.98%。
2.自变量筛选结果
全模型筛选策略纳入所有25个自变量(表1),利用logistic回归和随机森林进行自变量筛选的结果见表2。

表2 logistic回归与随机森林自变量筛选结果*
*:logistic回归筛选结果按标准化偏回归系数绝对值降序排列,随机森林筛选结果按基于Gini系数评估的变量重要性降序排列。
3.logistic回归建模效果评价
在三个不同的自变量筛选策略下分别建立logistic模型,其中以logistic回归筛选变量作为自变量的传统模型中各自变量相关参数估计信息见表3。将该logistic模型应用于测试集数据,得该logistic模型的AUC及其95%CI为0.7684 (0.7071,0.8297)。在训练集上分析选取的截断点(0.6431)下,模型在测试集上的灵敏度为70.37%,特异度为68.60%。其他两个logistic模型的相关预测表现见表3。
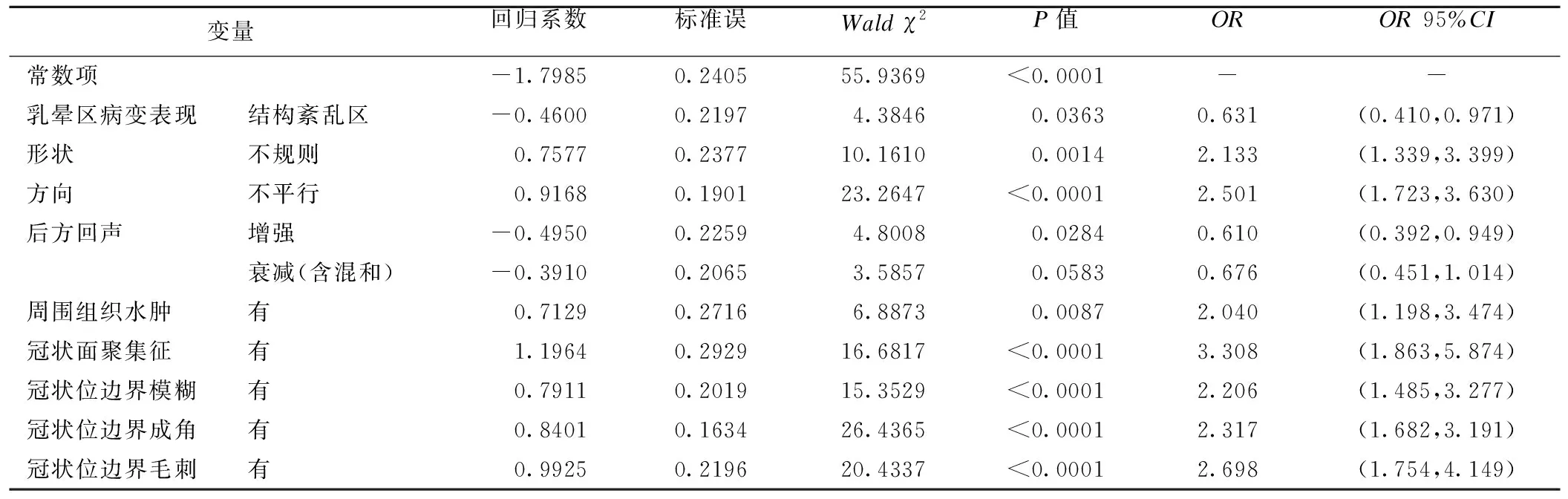
表3 logistic回归模型参数估计表
4.随机森林分析结果
在三个不同的自变量筛选策略下分别建立随机森林模型,其中使用随机森林筛选所得自变量的随机森林模型经过网格搜索遍历各参数组合,当mtry设定为2时在训练集五折交叉验证得到的平均AUC最高,该模型在测试集AUC为0.7868(0.7377,0.8359),在训练集上选取的截断点(0.6019)下该模型在测试集上灵敏度为70.53%,特异度为70.08%。其他两个随机森林模型相关信息见表4。
5.支持向量机分析结果
在三个不同的自变量筛选策略下分别建立支持向量机模型,其中使用随机森林筛选所得自变量的支持向量机模型经过网格搜索遍历各参数组合,当C=0.01,σ=0.1时在训练集五折交叉验证得到的平均AUC最高,该模型在测试集AUC为0.7852(0.7359,0.8344),在训练集上选取的截断点(0.5766)下该模型在测试集上灵敏度为68.60%,特异度为70.87%。其他两个支持向量机模型相关信息见表4。
6.模型比较
各模型在测试集上的表现汇总及模型间AUC的差异性检验结果见表4。在不同的自变量筛选策略下三个模型在测试集上的表现均非常接近,随机森林和支持向量机与logistic回归间AUC的差异没有统计学意义。此外,不同自变量筛选策略下相同建模方法所建的各预测模型在测试集上的AUC间的差异也没有统计学意义。
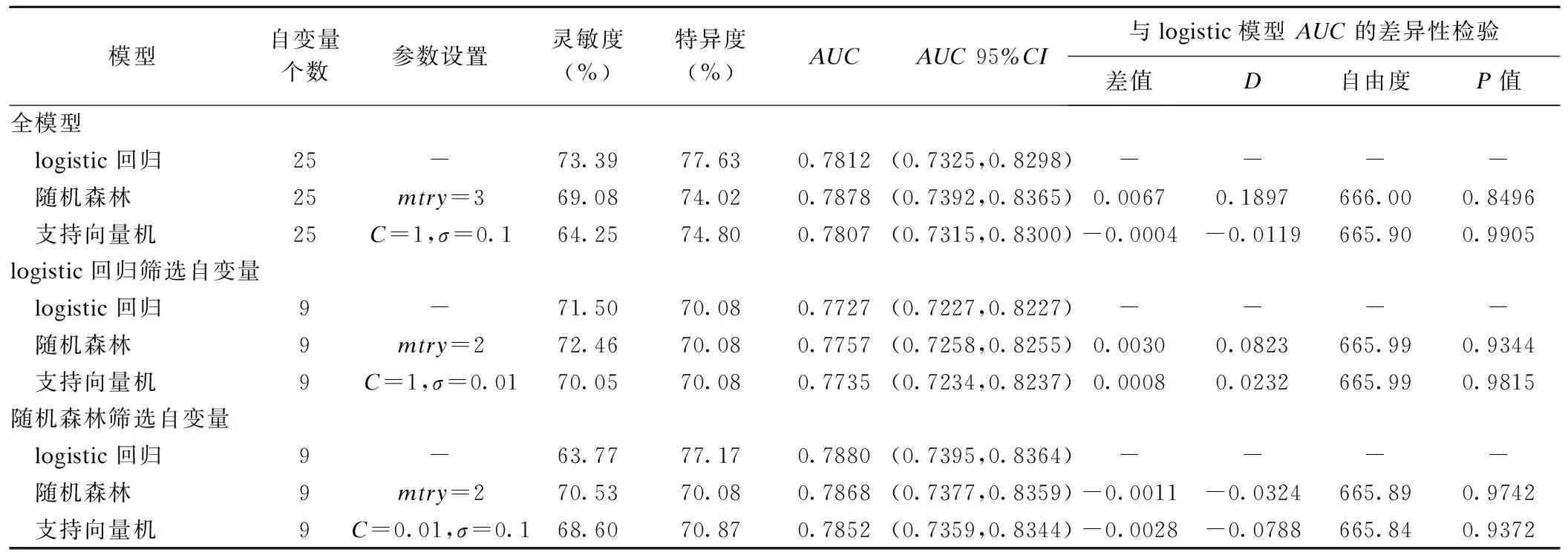
表4 各模型在测试集上的模型评价与模型间AUC比较
讨 论
可用于解决分类问题的机器学习方法众多,不同方法间的优劣要视具体数据情况而定,探索多个模型尝试获得更好的预测结果往往是有益的。随机森林与支持向量机均是机器学习中的常用技术,已在多个应用实例中表现出很高的预测准确性。本研究结果表明在利用人工判读的超声影像特征变量建立判别乳腺病变良恶性预测模型的问题上随机森林与支持向量机在预测准确性方面并未见比传统logistic回归有明显的提升。在本研究中,自变量均为分类变量,这种情况下应用logistic回归建模时不需要考虑线性关系假设[19],则logistic回归主要的局限性得以避免,使得logistic回归有能力较为准确地描绘自变量和因变量间的关系。
选择最终使用的模型需要综合考量模型的预测能力,可解释性,训练模型的计算成本等多个方面。如果希望通过建立基于超声医生肉眼判断的超声影像特征对于乳腺病变良恶性的预测模型来帮助基层医院的筛查超声医生提高业务水平,则模型中使用的特征变量及其权重/重要性这些解释性信息也是很重要的。随机森林或支持向量机等类似于“黑箱”的模型需要在预测准确性方面有很明显的优势才足以弥补其解释性信息缺失的不足。利用人工判读的超声影像特征诊断乳腺病变性质时随机森林与支持向量机在预测能力方面与logistic回归近似,再考虑到logistic模型在操作便捷性、应用的普遍性和可解释性上的优势,建议在利用人工判读的超声影像特征建立诊断乳腺病变性质的预测模型时仍使用logistic回归。
从超声图像中提取特征时,由于超声图像受到检查者操作探头位置影响,提取连续性变量则测量误差相对较大。本研究的自变量均为分类变量,测量误差相对较小,基层医院超声科医生应用较为方便。从使用复杂度更高的随机森林、支持向量机模型未能显著提高模型的预测准确性的研究结果来看,人工判读的超声影像特征变量的诊断价值很可能已被较为充分地利用。如果超声图像中的信息不采用人工判读而让深度学习算法基于图像像素信息自动识别特征,以此作为自变量建立诊断乳腺病变有望得到诊断能力更强的预测模型。
