基于CUDA并行算法的气泡聚并加速优化研究
2018-11-03覃一海
覃一海
(广西建设职业技术学院,南宁 530007)
0 引言
在自然界和工业生产中,不可避免产生各种各样的气泡运动现象,例如气泡合并、上升、撕裂、排斥等。气泡的运动体现了极其复杂的物理现象,研究分析其运动特性,对工业生产有着极其重要的意义。目前,学者针对气泡运动特性的研究有多种数值模拟方法,例如流体体积函数法(VOF)、水平集法(LSM)、格子玻尔兹曼方法(LBM)等。Hua等[1]将VOF与DPM相结合,成功模拟了二维垂直通道内的大气泡和小气泡之间的运动轨迹和相互作用情况。Karagadde等[2]使用LS方法,充分考虑了微尺度结构域,研究了氢气泡在该区域内的生长和运动,成功模拟了铝铸件凝固过程中氢气泡的生长过程。LBM(Lattice Boltzmann Method,格子玻尔兹曼方法)[3]是当前都受学者青睐的数值模拟方法,在研究气泡运动方面得到广泛应用,Inamuro等[4]提出了一种具有大密度差的两相不混溶流体的格子Boltzmann方法,并成功应用于毛细波、二元液滴碰撞和气泡流的模拟。Chen等[5]采用LBM模拟了恒温加热表面气泡的生长过程,研究了气泡生长和脱离对温度分布的影响。LBM是目前使用较多的数值模拟方法,该方法编程简单、边界易于处理、具有天然的并行性,已经被广泛应用于多相流、湍流等领域的数值模拟。
CUDA(Compute Unified Device Architecture,计算统一架构)是NVIDIA公司近来年提出一种并行运算技术。CUDA利用GPU天然的多线程特点,能较大提高算法的计算效率,已经在流体数值模拟、天文计算、生物计算等多个领域的大规模运算得到广泛应用。例如黄昌盛等[6]在基于LBM的二维方腔流、二维圆柱绕流以及三维方腔流模拟中,引入CUDA并行技术,大大提高了程序的运行效率。覃章荣等[7]使用CUDA技术,仅对GPU中的存储器优化,就可实现LBM程序的加速计算,获得107倍的加速比。可见,CUDA在提高算法效率方面是非常有效的。
本文针对常用LBM模型的一些不足进行改进,并进行实验验证,证明模型的可行性,接着使用CUDA并行技术对LBM算法进行加速优化,以提高算法的运行效率。
1 理论及数学模型
1.1 LBM的基本模型
LBM是一种目前使用最多的数值模拟方法。LBM主要有二维模型和三维模型,本文主要使用二维LBM模型进行模拟运算,它的基本方程如下:

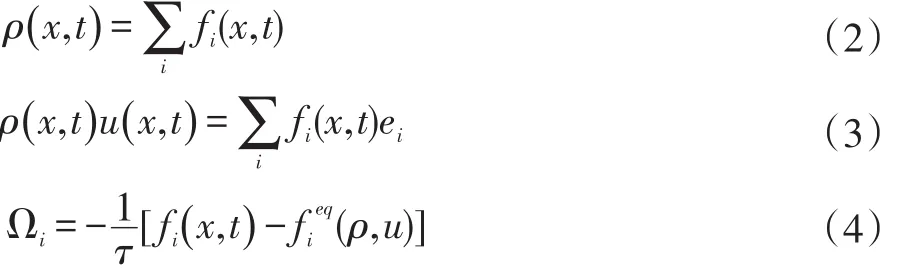
以上式子中,fi、Ωi、ei、fieq(ρ,u)、τ、ρ、u、δt分别指分布函数、碰撞算子、速度矢量、平衡态分布函数、单驰豫时间、宏观密度、宏观速度、步长,fieq可扩展为:

其中式子(1)的演化分为碰撞和迁移过程,碰撞的公式为:
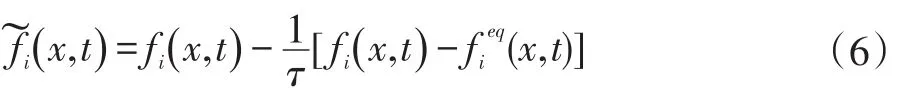
流动的公式为:

1.2 复合LBM模型
Shan和Chen等[8]于1993年首次提出基于LBM的伪势模型,模型引入了分子间的相互作用力。该模型原理简单、编程容易,适用于复杂多相流体的模拟。可惜的是该模型产生的虚速度较大,影响模型的稳定性。伪势模型的方程表示如下:

随后Swift等[9]提出基于自由能的多相流LBM模型,模型引入自由能函数、热力学张量等理论,模型可以模拟大密度比的流体流动。Zheng等[10]进一步对Swift的模型进行改进,巧妙引入捕获方程,能模拟更大的密度比的流体,而有效减小了模型的虚速度。
伪势模型虽然能很好模拟多相流动,但是模型产生的虚速度较大,影响模型的稳定性。Zheng模型虽然能减小虚速度,但模型不符合伽利略不变性。本文将前者的动量方程和后者的界面方程进行组合,产生新的LBM组合模型。
本文提出的模型使用双组分LBM模型。将密度不同的流体定为气相和液相,密度表示为 ρG、ρL。密度
本文模型的动量方程使用如下公式:
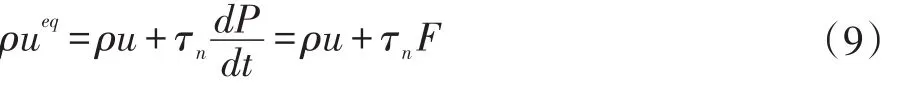

粒子碰撞方程为:


2 模型验证
2.1 Laplace定律验证
本文使用公式(14)来验证模型的正确性,通过实验计算气泡内外压力差,将数据与理论值对比。

上式中,Δp是气泡内外压力差,R是气泡半径,σ是表面张力。设置流场大小为201×201,界面厚度、气体密度、液体密度、驰豫时间、表面张力、迁移系数、序参数等分别为:5、1、1000、0.875、0.1、100、499.5。取多个不同半径进行模拟,模拟稳定后,将压力差与半径关系作图,结果如图1所示,可见实验数据与理论数据基本一致,说明本文的模型满足Laplace定律。

图1 压力差Δp与1/R的关系
2.2 研究两气泡合并实验
设置界面厚度为3.0,迁移系数为100,气泡间距为5,表面张力为0.5。两气泡的合并过程如下图2所示。模拟与文献[10]完全吻合。

图2 两气泡合并过程 σ=0.5,Γ=100,W=3,d=5
3 基于CUDA的双气泡合并的算法加速优化
基于CUDA的优化方法有维度划分优化、存储器访问优化、指令流优化、综合优化等方案。维度划分优化是指合理分配GPU线程网络和线程块的维度比例来提高程序运算效率。存储器访问优化是指优化GPU存储与访问之间的数据拷贝与数据读取的过程,通过合理的存储分配,提高运算效率。指令流优化是指对算法中使用频率高的代码通过算术指令、控制流指令、访存指令、同步指令等优化指令提高程序的运算效率。本文主要使用存储器访问优化方案对LBM进行优化加速。使用cudaMallocPitch()和cudaMalloc3D()方法给LBM算法划分存储空间。使用cudaMemcpy2D()或cudaMemcpy3D()方法将数据进行拷贝。再通过均衡拷贝与存储之间的数据分配,就可以使合局存储器达到最佳的访问要求。经过存储访问优化后,在不同流场中演化100000步所得的加速结果如图3、图4、表1所示,S1是指算法在CPU上运行的结果,S3是指经过存储访问优化后运行的结果。

图3 方案S1和S3在不同流场中的耗时对比

表1 方案S1、S3的耗时和加速效果的比较
由以上对比可知,经过存储访问优化后,算法的达到10000步所耗时间明显变少,加速比随着流场规模变大而变得更高,存储访问优化最高可获得25.41倍的加速比。
4 结语
本文针对主流多相流LBM模型的不足,提出了改进的多相流LBM模型,并通过多方式对模型进行验证,接着使用改进的LBM模型对气泡合并进行模拟,之后使用CUDA并行技术对气泡合并算法进行优化加速,通过对GPU优化方案中的存储访问优化,合理分配存储器拷贝与存储之间的比例,就可获得理想的加速比。接下来会在维度划分优化、指令优化等方面作进一步研究,希望获得更大的加速比。

图4 方案S1和S3在不同流场中的加速比
