基于卷积神经网络的车辆和行人检测算法
2018-11-01周武杰顾鹏笠
潘 婷,周武杰,b,顾鹏笠
(浙江科技学院 a.机械与能源工程学院;b.信息与电子工程学院,杭州 310023)
随着中国经济的持续快速增长,车辆已成为不可缺少的代步工具,人们对汽车的舒适度和安全性提出了更高的要求。在2016年世纪围棋大战落幕之后,2017年迎来人工智能年,无人驾驶作为人工智能的热门应用迎来了巨大的发展空间。在无人驾驶领域,车辆和行人目标检测是车辆感知外界环境的基础环节,也是计算机视觉和图像处理方向的重要分支[1]。2013年随着R-CNN[2]被应用于目标检测领域并取得较好效果,深度学习的方法开始在目标检测领域发展起来,主要分为不基于区域建议和基于区域建议两种方式[3]。不基于区域建议的算法主要采用回归的思路,其检测效果相对而言不理想但速度较快,Szegedy等[4]通过深度神经网络(deep neural network, DNN)采用回归的方式估计图片中目标的概率和分数;Redmon等[5]提出了一种只需在图像上看一次(you only look once, YOLO)即可实现检测的算法,通过将整张图片分为多个网格,分别计算每个网格包含目标及位置的概率检测目标,提高了检测速度;之后出现了诸如单个多盒检测器(single shot multibox detector, SSD)[6]、YOLO算法的变形[7]、小型的单个多样检测器(tiny single shot multibox detector, Tiny SSD)[8]等算法,可以实现实时检测,但检测精度仍略逊于基于区域建议的算法。基于区域建议的算法主要分为两步,一是找到感兴趣区域;二是通过卷积神经网络检测得到目标并标定矩形框。通过在基于区域卷积神经网络(regions with CNN, RCNN)算法基础上不断改进,He等[9]提出了空间金字塔池化网络(spatial pyramid pooling network, SPP-net),取消了输入尺寸的限制;Girshick等[10]提出了快速基于区域卷积神经网络(fast regions with CNN, Fast RCNN),通过增加区域建议融合层减小了计算量;Ren等[11]提出了更快速的基于区域卷积神经网络(faster regions with CNN, Faster RCNN),将目标检测的4个步骤融合提高了检测精度,并且提高了检测效率;之后出现了诸如基于区域的全卷积神经网络(region-based fully convolutional networks, R-FCN)[12]、基于掩模的区域卷积神经网络特征(mask regions with CNN, Mask RCNN)[13]等网络框架,改进了基于区域建议的方法。其中,Faster RCNN算法因较好的性能,被应用于诸如车型识别、人脸检测、医疗病理检测及电力小部件识别等,并且都取得了较好的结果。
当前车辆和行人检测算法主要是在目标检测算法的基础上,针对车辆在不同尺度和角度下特征的区别,以及考虑行人多姿态的情况,设计出有针对性的算法,诸如行人检测的可变形组件模型(deformable part model, DPM)[14]算法和可用于车辆检测的深度学习的ZF模型[11]算法等。基于上述研究,本研究提出了基于卷积神经网络的车辆和行人检测算法,该算法针对当前算法特征提取时参数较多、计算量较大的不足,以及传统检测算法中特征提取鲁棒性较差的现象,在Faster RCNN的开源框架的基础上,利用Squeezenet网络框架提取特征,有效减少参数提高计算性能,之后在训练学习阶段通过在线负样本学习[15](online hard example mining, OHEM)算法将疑难样本重新训练以降低损失,并且利用Soft-NMS[16]算法有效抑制多余的检测框,能够较为精确地检测出其具体位置,通过在KITTI数据集上验证该算法能够实现车辆和行人检测。
1 基于卷积神经网络的车辆和行人目标检测框架
1.1 OHEM算法
OHEM于2016年被应用于Fast RCNN网络框架中改进检测网络。在本研究中,通过采用OHEM算法对损失函数的数值进行排序,选择出同一批次中损失较高的前600个返回作为困难样本再训练,以改善随机梯度下降(stochastic gradient descent, SGD)过程,从而获得更好的模型。具体过程如下:对于第t次进行SGD迭代的一个批次的图像,假设某一张图片作为输入,首先通过卷积网络提取特征图。之后,在提取感兴趣区域(region of interest, RoI)过程中,通过RoI网络利用特征图和所有输入的RoIs(即某一个批次中所有样本的RoI)一起传递参数。通过对输入的RoI进行排序以选出当前损失值最高的600个特征图。该过程通过参数共享降低计算量。此外,由于选择了少量的RoIs来更新模型,所以相较于之前的过程并没有增加太多计算量,但是由于图片可能会出现同一个位置多个重叠矩形框,会导致损失重复计算,因此本研究采用了Soft-NMS算法删除重叠框。
1.2 Soft-NMS算法
Soft-NMS算法于2017年被提出,是针对非极大值抑制(non maximum suppression, NMS)算法的改进,在检测过程中最后通常需要通过NMS算法抑制重叠框,具体做法就是设置阈值,低于此阈值的框将被直接删除,只保留最高得分的几个框。不同于NMS算法直接将重叠度较高的框直接删除的做法,Soft-NMS在考虑到可能重叠部分有两个物体的情况,诸如两辆紧挨着的汽车,此时直接删除框可能会造成漏检,因此Soft-NMS通过一个衰减函数取代直接删除框的做法,这对提高检测率有一定的效果。
1.3 基于Faster RCNN的算法设计
检测过程主要分为训练阶段和测试阶段。通过大量图片训练得到合适的模型,之后对输入该模型的图片依次检测,并且计算检测性能。本研究主要利用了Faster RCNN的开源框架,将目标检测的4个基本步骤融合到一个网络框架里,通过共享卷积参数和利用GPU并行运算等方式提升计算性能,并在此基础上进行了一定的改进,具体流程如图1所示:首先将图片输入Squeezenet神经网络中进行特征提取,然后通过RPN网络得到感兴趣的区域,将输出的包含类别和边界框信息的感兴趣区域与Squeezenet提取的特征共同通过RoI池化层输出,经过全连接层并进行检测计算获得类别分数与边界框,并将此时的预测值与标注信息计算损失函数,判定参数好坏。在此过程中对损失函数进行排序并将同一批次中损失值较大的600个样本作为疑难样本返回到RoI池化。之后,将RoI池化层输出的结果通过全连接层和分类层与边界框回归层,获得最后的检测结果。此过程重复多次,最终获得合适的检测模型。其中,将损失值较大的样本作为疑难样本返回到RoI池化层的这一过程仅存在于训练阶段。图中虚线框代表提取的感兴趣区域。
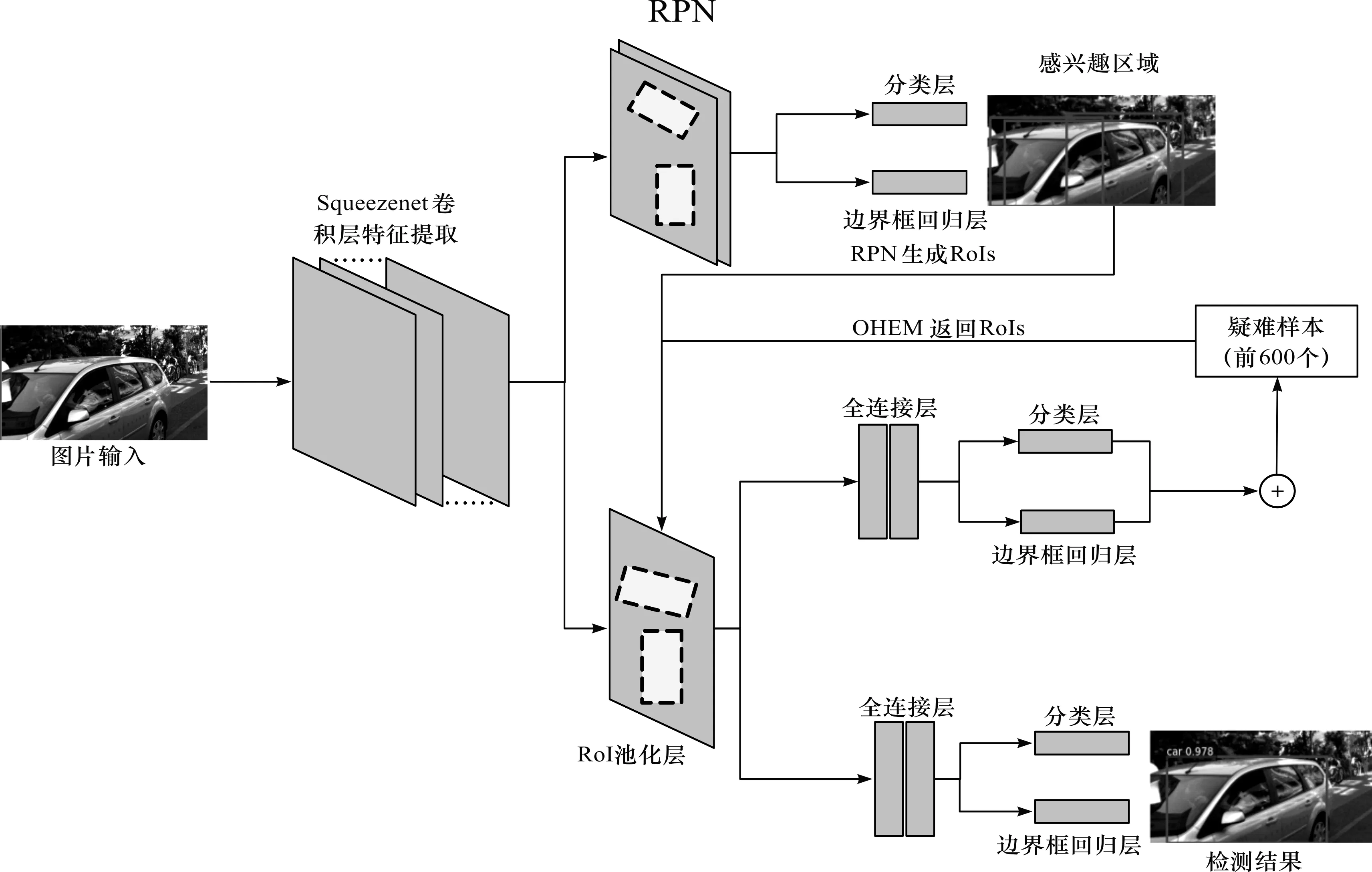
图1 算法流程图Fig.1 Algorithm flow chart
2 试 验
2.1 试验数据
本试验中我们使用了KITTI官网[17]提供的训练集(共7 481张图片),由于官网未提供测试集的标注信息,为了能够大致了解模型的检测精度,将训练集按照8∶1∶1的比例随机分为训练集、验证集和测试集三部分。其中,训练集用于训练得到模型,验证集用于在训练过程中及时了解模型性能以便于选出最优的模型,测试集用于最后检测模型的性能。随机处理获得数据集之后,处理得到合适的数据格式。部分样例如图2所示,包含诸多情况下的场景。我们通过同一个模型对这两者一起进行训练和最终的测试,即实现了多类检测。

图2 训练数据集样例Fig.2 Examples of training data
2.2 试验环境
为了验证基于Faster RCNN方法在车辆和行人检测中的具体应用具有可行性,试验在Linux环境下完成,采用Ubuntu 16.04系统,硬件设施如下:16 GB内存,GPU为NVIDIA 1070的显卡,包含8 GB显存,通过Python语言完成试验。
2.3 试验结果与分析
通过输入如图3所示的待测试图片,当图片包含诸如形态不同、存在遮挡以及尺寸较小等诸多情况时,可以发现该模型能够很好地检测出车辆和行人,并且针对不同视角和不同尺寸的目标也能够实现较好的检测结果,对光照、姿态、尺寸等都具有一定的抗干扰性,具体结果如图3所示。其中,面对同一张图片同时包含车辆和行人时,能够用同一个模型同时检测出结果,并且分别给出得分。在测试过程中,我们将检测目标的置信度设置为0.8,如图3所示的p(car|box)≥0.8,这意味着只有当检测到车辆或行人的概率超过0.8时才框定出位置。

图3 测试集图片检测结果示例Fig.3 Detection results about testing data
通过与传统典型可变形的组件模型算法和ZF网络模型的深度学习算法的比较可以发现,我们提出的算法获得了较好的检测结果。当前,目标检测主要通过计算一批图片的平均正确率(average precision, AP)代表检测结果的准确率,由于我们的方法可以检测车辆和行人两个类别,因此要对两个类别的检测结果算平均AP值(mean average precision, mAP)作为最终的检测结果准确率。本文方法的车辆检测结果准确率为60.1%,行人检测结果准确率为34.6%,平均检测准确率为47.4%,具体结果如表1所示。其中,由于KITTI数据集主要包含车辆信息,行人的数据偏少,在训练过程中,行人的正样本信息所占比率小于车辆的数据,训练不够充分,导致结果中行人检测率较低。

表1 测试结果对比Table 1 Comparison of detection results %
3 结 论
本研究在Faster RCNN的网络框架基础上,通过加入Squeezenet网络,在不影响精度的前提下提高了运算性能,之后通过加入OHEM算法对负样本进行及时学习,从而有效地提高了检测率。试验结果表明,本方法可以有效地通过一个模型同时检测出车辆与行人。可是,由于训练样本太少等问题导致本方法有一定的误检率和漏检率,因此有待进一步研究。
