基于社交媒体的用户消费能力研究
2018-10-31裘实,刘挺
裘 实, 刘 挺
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
引言
近年来,随着互联网技术的快速与蓬勃发展,社交网络、网上购物等已经成为人们日常不可缺少的互联网应用。作为社交网络的衍生结果之一,微博以其易操作、传播快等特点[1]在社交媒体中脱颖而出。越来越多的人将个人信息公布在微博上,并且通过发表少于140字的短文本来陈述自己的观点[2]。微博极大地促进了信息的传播和共享,其中所包含的隐性商业价值正日益突显。通过观察微博用户微博文本信息后,研究发现活跃用户所发表的微博文本信息与用户的消费能力之间可能存在某种联系。在微博引发的强大推介态势背景下,通过用户的微博信息研究用户在某一产品类型的消费能力这一课题将非常有意义。
本文主要对微博用户所发微博文本与用户的消费能力之间的关系展开研究。通过用户链指的方式获取到微博用户的京东账号信息,以京东账号会员等级将消费能力分为高、中、低3个层次。然后将微博文本向量化处理后与用户属性联合在一起,经过特征选择后作为输入以训练模型,预测用户的消费能力。
1 基于传统分类模型的消费能力模型
随着社交网络的兴起,基于短文本的用户属性的研究得到学者的广泛关注。Rao等人[3]基于国外社交网络Twitter上的文本进行了包括性别、年龄、生活地区等属性的识别,并取得了70%以上的准确率。Sun[4]提出了一种基于微博用户签到地点的消费能力的预测。文中将签到地点分成数个等级,根据微博用户的签到地点判断用户消费能力,但并未对用户基本属性和文本信息与消费能力之间的关系提供后续分析。付博等人[5-6]基于跨社交媒体检索对微博消费对象、消费意图做出了评判识别。Zhao等人[7]基于微博用户信息统计研发了一个产品推荐系统METIS,根据用户的性别、年龄、婚恋状况、教育程度、职业和兴趣(微博标签)等用户信息,通过Learning to Rank进行产品推荐;Hollerit等人[8]通过Twitter检测商业意图来连接卖家和买家。
本文用Uni-Gram单词模型和Bi-Gram二元模型作为传统分类模型的词向量输入。其中,Uni-Gram指单词模型,即探究每个用户的用词与消费能力之间是否存在某种关系;Bi-Gram是指二元模型,即探究每个用户的连续用语习惯是否和消费能力相关。数据集中已经存储了每个用户发布的所有微博,先将每个用户的文本分隔为一个单独的文档,全局文本中共有4 630个文档。然后把每个文档中的文本用LTP进行分词、去停用词,作为每个用户的词典。接下来计算每个单词的TF-IDF值,并建立无重复词的词典,总共统计出333 523个词。最后依次选用IG、CHI和WLLR的特征选择方法进行特征选择。将IG、CHI和WLLR这3种特征选择方法撷选出来的前10 000个词和前50 000个词分别作为特征项,作为模型训练的输入,进行对比实验。
在分类器的选择上,选择了支持向量机(Support Vector Machine, SVM)[9]。这是一种二元分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器[10],学习的策略是间隔最大化,最终可转化为一个凸二次规划问题的求解,运行求解设计可如图1所示。
本文中,分类器的特征项达到了10 000维,甚至50 000维,而研究中的训练数据只有4 630个。所以选择了对维数大于训练数据个数的最优化SVM分类器作为分类模型。

图1 支持向量机模型
2 基于LDA主题模型的用户消费能力模型
通过观察用户所发微博文本信息,发现各个用户所关注以及乐于发表观点的主题存在很大区别。因此,研究拟通过抽取每个用户喜爱谈论的主题来考查其是否与消费能力相关。本文的主题词模型的构造采用LDA的方法来实现。
LDA(Latent Dirichlet Allocation)是离线数据集合的生成概率模型,也可以称为3层贝叶斯概率模型[11]。LDA的3层结构分别是词、主题和文档。在本文中,每个用户的微博文本分词结果都是一个文档,且认为每个文档中的词是通过一定概率选择了某几个主题,并从这些主题中以一定概率选择某个词语。文档与主题之间服从多项式分布,主题与词之间服从多项式分布,模型设计则如图2所示。LDA属于机器学习中的非监督学习类型,一般用来通过非监督的方式生成文档的主题。研究通过使用词袋方法向量化每篇文档中的词,这样每篇文档就有了某些主题构成的概率分布。本文将这种主题概率的分布作为预测消费能力的特征项,探究不同消费能力用户文本信息主题概率分布的改变是否存在规律性。
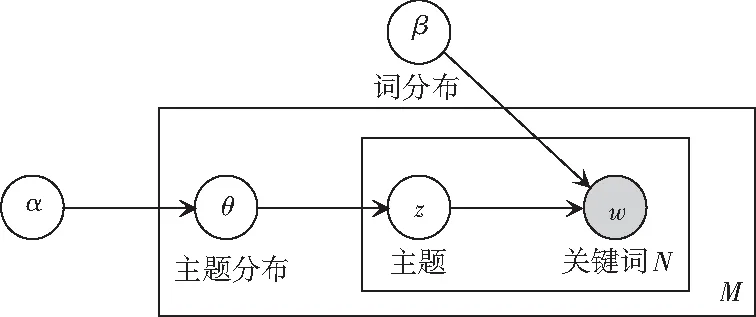
图2 LDA主题模型
用LDA方法选出了200个主题,每个主题下有20个词。通过观察这200个主题以及属于主题的词语,发现有些词语集合主题比较明显,但也存在一些完全无规律词语集合,研究从200个主题中选出了包括足球、母婴、股票、购物等57个具有明显主题的词集,举例中的分类划定可见表1。

表1 LDA选择出的主题及主题下的词语举例
3 评价指标与实验结果
3.1 评价指标
本文采用有监督的学习方法,将消费能力分为高、中、低3个等级,因此选取文本分类中常用的评价指标,即:准确率、精确率、召回率、以及精确率和召回率的调和平均值作为评价的标准。论述详情可见如下。
(1)准确率(accuracy)。是指对于给定的测试数据集,分类器正确分类的样本数与总样本数的比值;另外3个评价指标在本文中分别针对不同的类别,每一类别中以该类别为正类,其它2个类别为负类,分类器在测试数据集上的预测可判为正确或不正确,4种情况出现的总数分别设定为:TP表示将正类预测为正类数;FN表示将正类预测为负类数;FP表示将负类预测为正类数;TN表示将负类预测为负类数。
(2)精确率P。数学定义可表示为:
(1)
(3)召回率R。数学定义可表示为:
(2)
(3)精确率和召回率的调和平均值F。数学定义可表示为:
(3)
所以对于3个类别,每种方法将会得到一个准确率和3个不同的精确率、召回率和调和值。
3.2 实验结果与分析
研究选用Uni-Gram—单词模型研究的是用户的用词习惯和消费能力之间是否存在关联,实验结果可见表2。
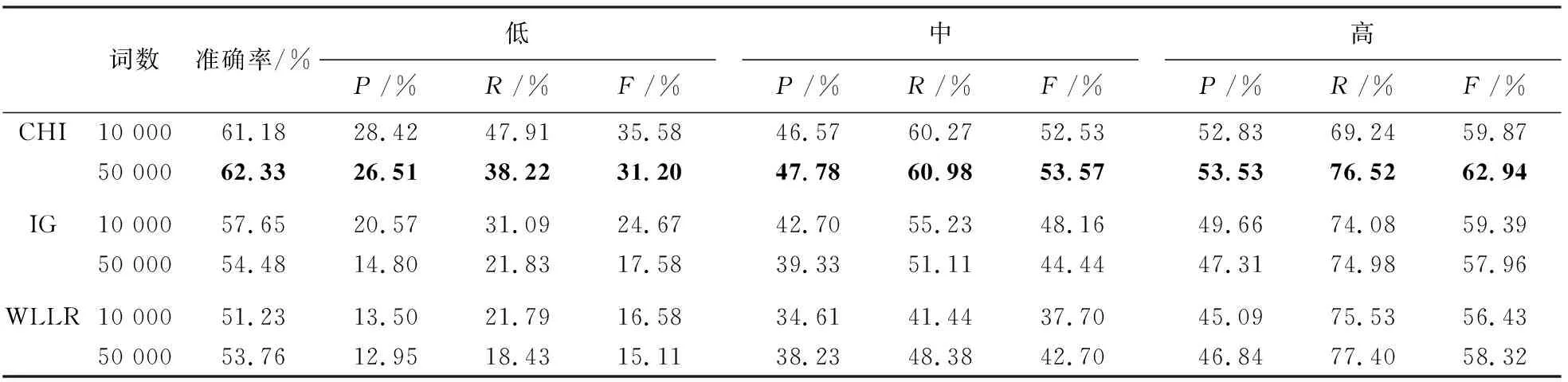
表2 Uni-Gram模型实验结果
如表2所示,研究中用CHI方法选出特征值为前50 000个词作为特征项具有较好的预测结果,准确率为62.33%,3个消费等级的F值分别为31.20%、53.57%和62.94%。
接下来,将再次选用Bi-Gram—二元词组模型研究用户的用语习惯和消费能力之间是否存在关联,实验结果可见表3。
从表3可以看出,Bi-Gram的预测正确率明显高于Uni-Gram,CHI方法选出的特征值前10 000个词具有较好的实验结果,准确率达到了70.33%,3个消费等级的F值达到了45.11%、62.73%和69.07%。由此则可推断得出:用户的用语习惯较用词习惯与消费能力的关联关系更为密切。
最后,主题模型探究的是用户喜欢谈论的主题与消费能力之间的关系。研究选择了用LDA方法得出的主题中具有明显特点的57个主题,以每个用户在这57个主题上的概率分布作为特征项进行训练和预测,最终结果可见表4。
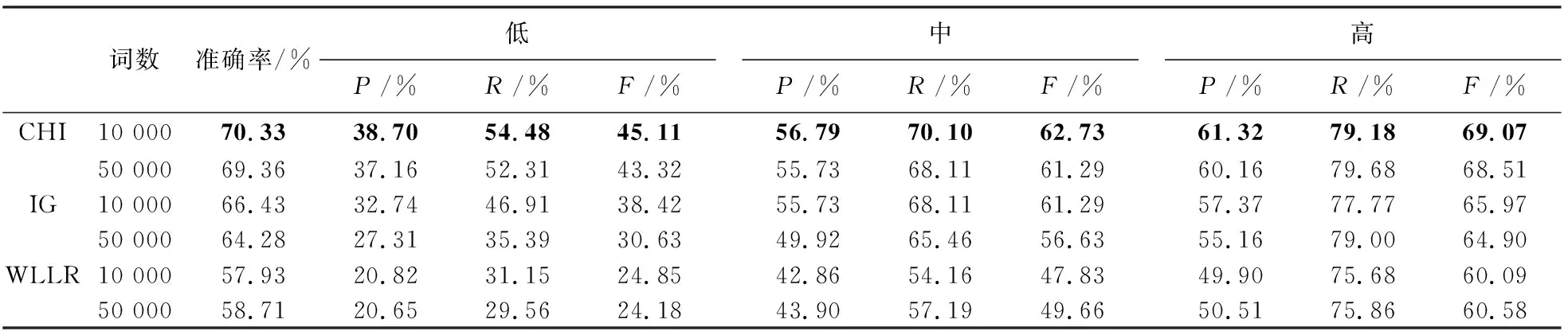
表3 Bi-Gram模型实验结果
表4主题模型实验结果
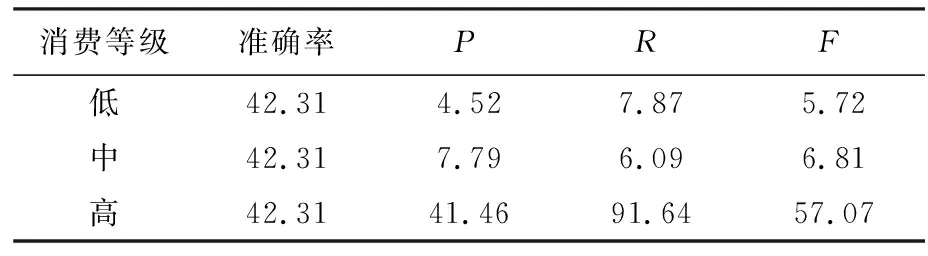
Tab. 4 Experimental results of topic model%
从表4中可以看出主题模型的预测结果并不好,由此可以得出结论,即:用户喜爱谈论的主题和消费能力之间的关联度不大。
4 结束语
本文研究的主要内容是基于社交媒体的用户消费能力。目前,基于短文本社交媒体的用户画像工作已经成为自然语言处理领域研究的热点。但已有工作主要是对用户未公开的基本属性进行预测和对消费意图进行识别,而本文研究的重点是社交媒体中用户所发文本和基本属性与消费能力之间的关系。在此任务中,利用用户链指的方式建立了社交网络—微博与购物网站—京东的映射途径,以京东的级别信息作为消费能力的判定标准。以用户所发微博与用户基本信息作为输入,预测用户的消费能力。本文通过对比Uni-Gram模型、Bi-Gram模型和主题模型的实验结果,探究用户的习惯用语和个人基本信息与消费能力之间的关联。结果表明,用户的用语习惯与消费能力之间的关联度最大,其次是用词,最后是主题,且主题与消费能力关联度非常小。因为本文中获取到的数据较少,且存在比例不平衡的问题,所以后期工作中可以在用户链指的方向上实现进一步研究,比如通过用户名相似度匹配来获取更多用户,减少数据不平衡所造成的偏置;用户属性的信息还有继续挖掘的可能性,未来针对特征的选择还可以加大研究力度等。
