笑脸表情识别方法研究*
2018-10-30刘振宇
胡 宁,刘振宇
(沈阳工业大学信息科学与工程学院,沈阳110870)
1 引 言
面部表情是由人脸肌肉的运动形成的,是情感变化在面部可观察到的表现[1]。面部表情的变化能显示人的心理活动,调整人之间的社会行为。随着服务机器人产业的兴起,模式识别走进大众视野,人们对表情的研究也逐渐增多[2]。其中笑脸识别技术被广泛应用于机器人视觉及数码相机等智能设备。
近年来研究学者提出了多种笑脸检测的方法,例如深圳华为技术有限公司获得了笑脸检测发明专利权,其原理主要是通过获取到的人脸视频中嘴部的运动信息来判断是否检测到笑脸;何聪[3]利用一种高层次仿真生物视觉方法来实现笑脸的识别与分类,该方法主要基于生物启发特征来进行笑脸的特征提取和分类;陈俊研究了基于生物启发特征的真实环境下的笑脸识别,构造了一个符合人类识别机制的笑脸分类系统[4];郭礼华等人利用分层梯度方向直方图(PyramidHistogramofOrientedGradients,PHOG)特征与聚类特征选择进行笑脸识别[5];严新平融合局部二值模式(LOCAL Binary Patterns,LBP)特征与HOG特征来进行笑脸识别研究[6]。
采用Viola-Jones算法来检测人脸,可将人脸部分提取出来,采用HOG和Gabor两种特征提取方法提取图片特征,并送入支持向量机(support vector machine,SVM)进行训练。通过观察训练样本中的不同表情,发现嘴唇的形状变化最能代表不同表情。同时嘴唇外周的特征例如法令纹等,则不是十分清晰,不同的图片效果差异很大,不适合作为判断表情的标准。通过对嘴部特征点拟合曲线进行分析发现,笑脸的拟合曲线会产生明显的弧度并且拟合曲线两个端点纵坐标的平均值较小,而其他表情的拟合曲线则接近一条水平线且拟合曲线两个端点纵坐标的平均值较大。故此提出一种基于嘴角坐标平均值变化的笑脸识别方法,该方法通过对嘴角坐标的计算,可以准确识别笑脸表情。图1为其主要工作流程。

图1 笑脸识别流程
2 人脸检测
检测采用Viola-Jones算法来识别人脸和嘴部。该算法是由Paul viola和Michael J.Jones共同提出的一种人脸检测框架。它极大地提高了人脸检测的速度和准确率。该算法利用积分图像来提取图像特征值,利用adaboost分类器的特征筛选特性,保留最有用特征,从而有效减少了检测时的运算复杂度,提升了运算速度。同时将adaboost分类器进行改造,变成级联adaboost分类器,提高了人脸检测的准确率[7]。
Viola-Jones算法采用haar-like特征提取方法。Haar-like是由许多黑白块组成的,分别将白色和黑色区域中的所有像素相加,然后做差,就是区域的特征值,即:
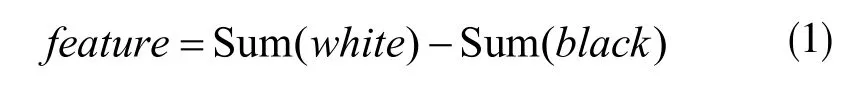
但是考虑到多尺度问题,即利用不同大小的扫描窗口去检测不同大小的人脸的问题,这个特征需要进行归一化处理。首先选定检测窗口的大小,利用这个窗口对整个图像进行滑动,每滑动到一个位置,就在窗口中提取一系列haar-like特征。由于哈尔特征极多,而这些特征中只有一小部分是有用的,所以采用adaboost分类器进行特征选择。adaboost分类器的原理就是构造一个由多个弱分类器并联而成的强分类器,每个弱分类器都根据自己的准确率将自己的分类结果乘以权值,最后的输出是所有弱分类器输出的加权和。每个弱分类器的分类准确率可以很低,但是整个强分类器的准确率却会很高[8]。图2为采用Viola-Jones算法提取的人脸部分和嘴唇部分。

图2 对人脸和嘴部进行检测提取
3 HOG特征提取
方向梯度直方图(Histogram of Oriented Gradient,HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成图像特征[9]。
HOG特征提取过程如下,首先要对上述裁剪出来的图片进行Gamma校正来弥补图像光照不均匀的问题。采用平方根的办法进行Gamma标准化,对标准化后的图像,求取其梯度及梯度方向。采用的水平和垂直方向的梯度算子为:
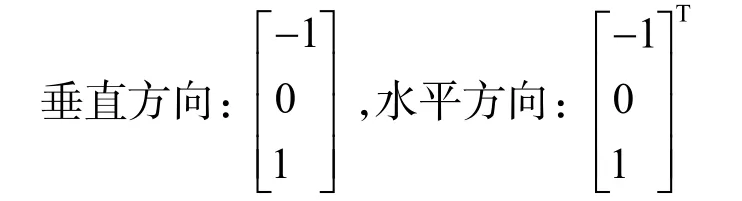
然后用水平和垂直梯度算子对原图像做卷积运算,得到χ方向(水平方向,以向右为正方向)的梯度分量 Gχ(χ,y)和y方向(竖直方向,以向上为正方向)的梯度分量 Gy(χ,y),具体为:
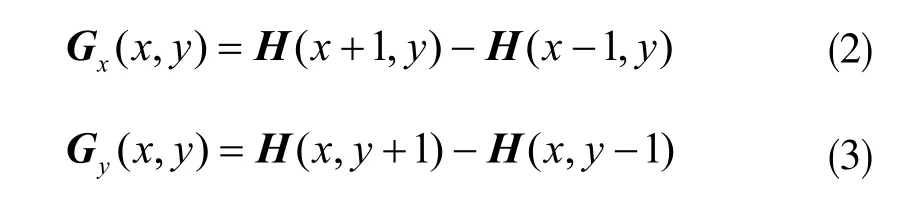
式中H(χ,y)表示输入图像中像素点(χ,y)处的像素值。将这两个方向的梯度分量带入下式中即可得到该点的梯度大小和方向:

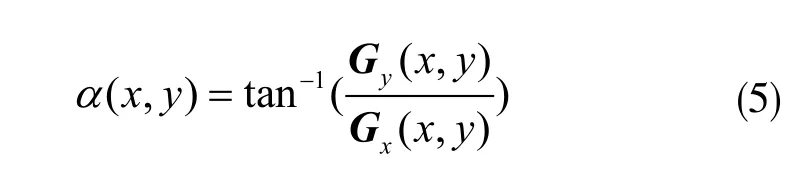
然后将图像划分成若干个cells(单元),相邻的cell之间不重叠。在每个cell内统计梯度方向直方图[5]。
随后分别对每个block进行标准化,一个block内有4个cell,每个cell含有一个9维特征向量,故每个block就由4×9=36维特征向量来表征。将所有block的HOG特征结合在一起形成整个图片的HOG特征向量。图3为脸部HOG特征直方图。

图3 脸部HOG特征直方图
4 Gabor特征提取
Gabor变换属于加窗傅立叶变换。Gabor函数可在频域不同尺度、不同方向上提取图片特征。Gabor滤波器的频率和方向类似于人类的视觉系统,所以常用于纹理识别[10]。在空间域,二维Gabor滤波器是一个高斯核函数和正弦平面波的乘积,其复数形式为:
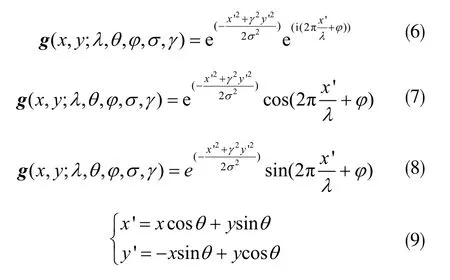
公式中:λ是正弦函数波长,θ是Gabor核函数的方向,φ是相位偏移,σ是高斯函数的标准差,γ是空间的宽高比。式(7)和式(8)分别为滤波器的实部和虚部[11]。
首先生成5个尺度和8个方向的Gabor模板,共计40个模板,这些模板与样本图像无关。然后利用每一个模板与样本图像做一次卷积运算,得到对应的40个卷积图像;不同尺度不同方向的Gabor模板对同一幅图像生成了不同视图的数据,类似于不同的观察角度产生了不同的特征数据,图4表示了这样的一组脸部Gabor特征。每一个卷积后的样本图像矩阵是9行1列的,连接在一起就是360行一列的Gabor特征值。本研究共有100张训练样本,将所有Gabor特征值组合成一个360×100的矩阵,每一列代表一个图片的Gabor特征。

图4 脸部Gabor特征
5 支持向量机(SVM)
支持向量机(简称SVM)是一种新型的机器学习方法,其主要功能是分类和回归[12]。SVM是由两类线性可分情况下的最优分类面发展起来的。图5为二维线性可分的情况,其中f(χ)为分类线,f(χ1)和f(χ2)分别为过两类样本中离分类线最近的点且平行于f(χ)的直线,f(χ1)和f(χ2)之间的距离称为两类的分类间隔。
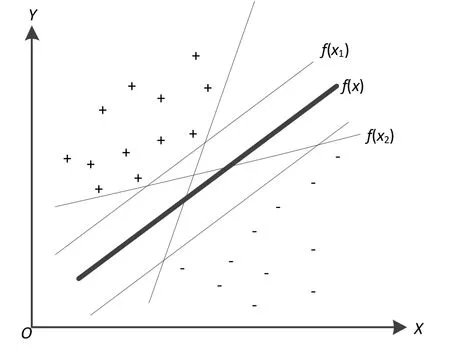
图5 SVM二分类示意图
SVM的基本思想是寻找一个可以将两类样本分开的最优分类线,使得分类间隔最大。设判别函数为:

当f(χ)=W·χ+b的时候,即为决策边界,f(χ1)和f(χ2)上的样本称为支持向量。对判别函数进行归一化后两类样本都满足,分类间隔为,满足的样本就是f(χ1)和f(χ2)上的支持向量。
因此在支持向量机的训练过程中,主要目的是获得W,一旦有了一个训练后的支持向量机(这个向量机保证了最大的边缘超平面,使得在此数据集下有较好的分类精度),就可以对线性可分的数据进行分类[12]。对于线性不可分的数据,会添加约束条件进行计算。
通过以下两式可将求W的问题转化为求解拉格朗日乘子αp的问题,通过对拉格朗日方程求偏导可以得到两个约束条件,进而求解出αp:
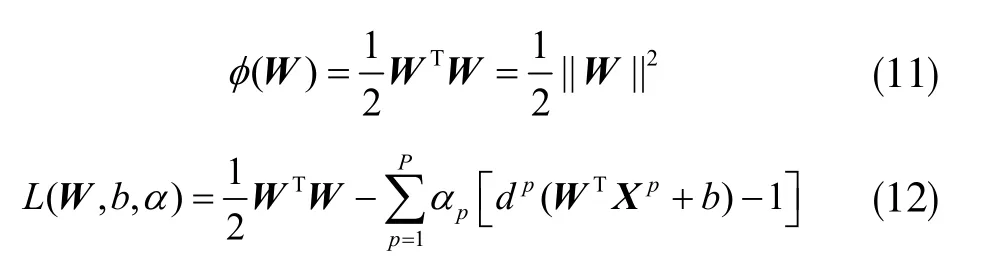
6 嘴角坐标法
6.1 Shi&Tomasi算法
嘴角坐标法首先采用Shi&Tomasi算法对嘴部特征点进行检测,该算法是Harris算法的改进。Harris角检测器由于能够检测已旋转、缩放、有照明差异或噪声较大的图像中的角点而被广泛应用。Harris算法最原始的定义是将矩阵行列式的值与矩阵特征值的和相减,再将差值同预先给定的阈值进行比较[13]。后来Shi和Tomasi提出了改进的方法,若两个特征值中较小的一个大于最小阈值,则会得到强角点。
设角点检测响应为RH,对于一个输入图像来说有:
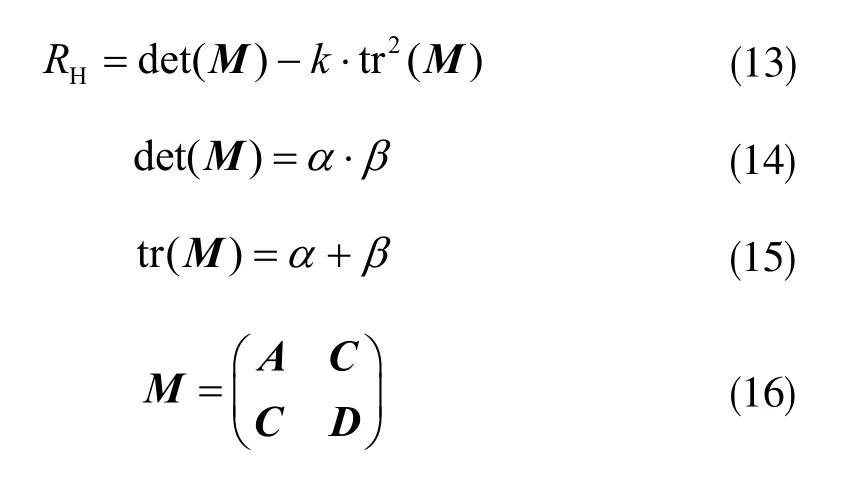
上述四式中α和β为矩阵的特征值,M是一个矩阵,M中的三个矩阵元素如下:
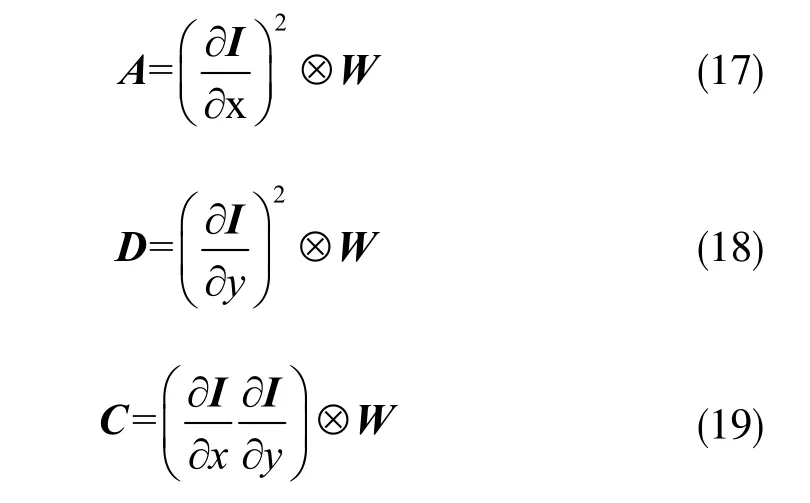
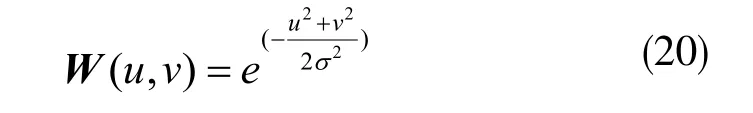
当某像素属于一个角时,该检测器输出RH>0;当像素属于边缘的一部分时,RH<0。
6.2 分类识别
利用Shi&Tomasi算法检测出嘴部的角点特征后,对这些特征值进行一系列的整合和运算,得到笑与不笑之间的分界值Pavg,通过这个值对测试库中的图片进行分类,分类操作的流程如图6所示。
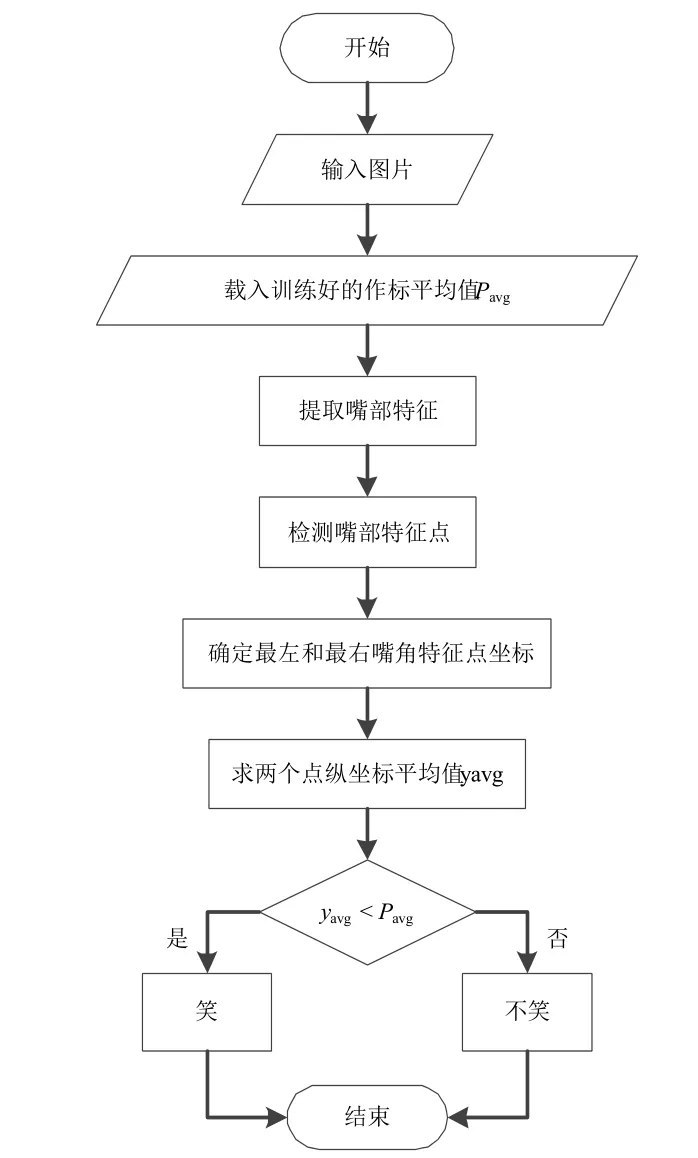
图6 嘴角坐标法流程图
算法具体过程如下:对于训练阶段来说,首先通过Shi&Tomasi算法检测出嘴部特征点,如图7所示;然后计算嘴角部分特征点的数量,并对这些点进行处理,去除掉在一个位置上重复的点;根据这些点的坐标画出特征点拟合曲线。

图7 检测嘴部特征点
曲线拟合采用二阶抛物线拟合,基于最小二乘法曲线拟合原理,即已知离散的数据集,构造一个函数,使原离散点尽可能接近给定的值。最小二乘法是通过最小化误差的平方和,寻找数据的最佳匹配函数,如下式所示:
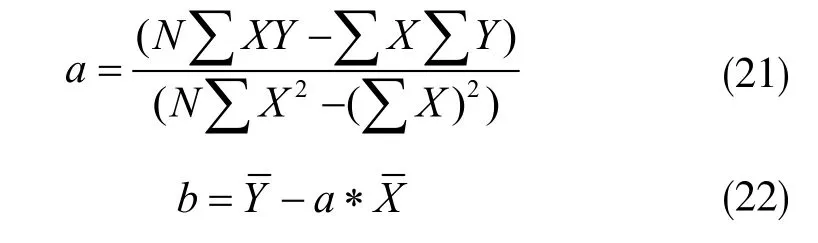
通过对上述二式进行计算,可以得到嘴部特征点的拟合曲线,如图8所示为笑嘴的角点拟合曲线,图9则为非笑嘴的角点拟合曲线。再将拟合曲线左右端点的值定义为左右嘴角的特征值,求这两个点纵坐标的均值,按此规则操作,得到所有笑脸及非笑脸嘴角特征点的纵坐标均值。图10即为训练样本纵坐标均值分布曲线。
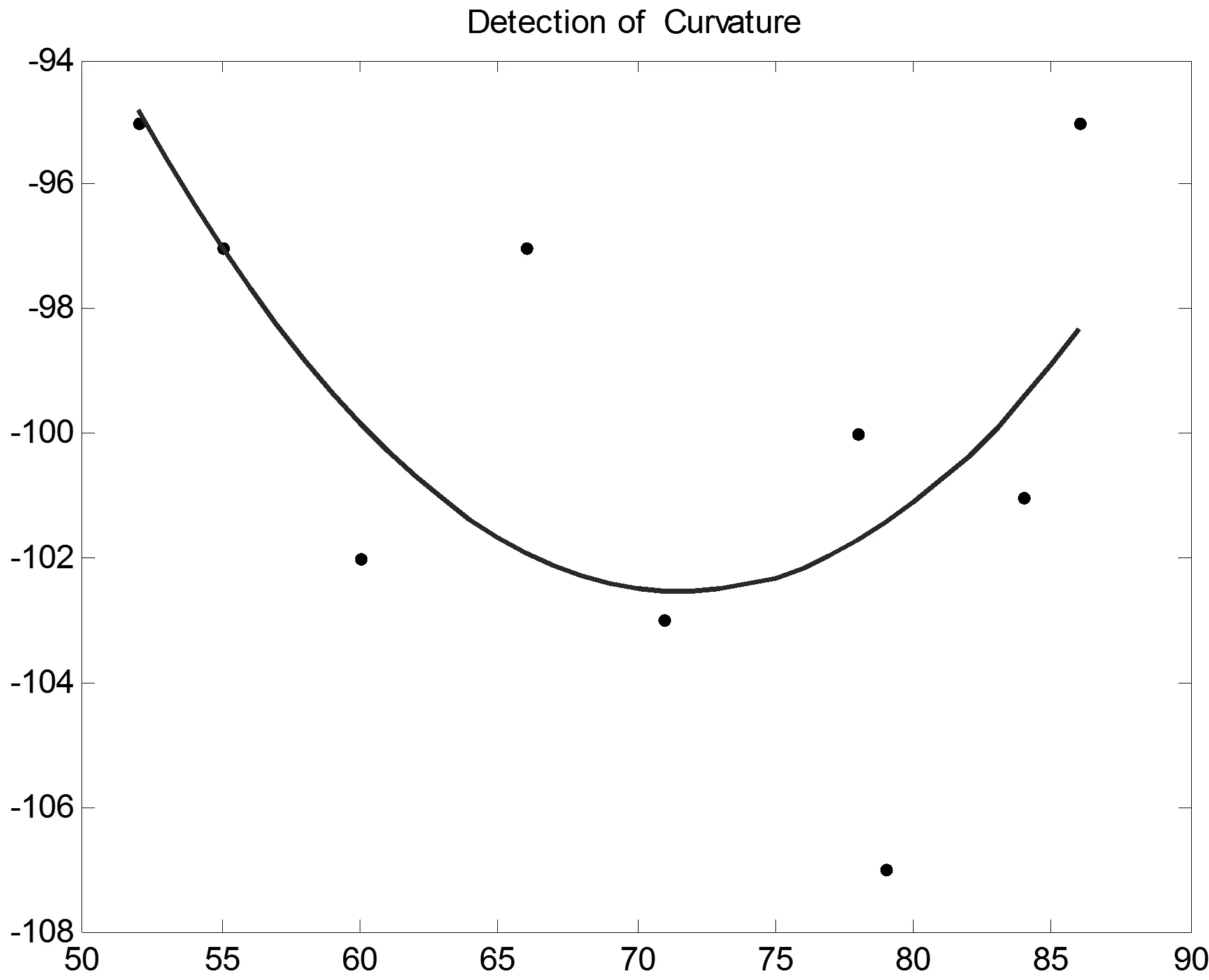
图8 笑嘴的角点拟合曲线
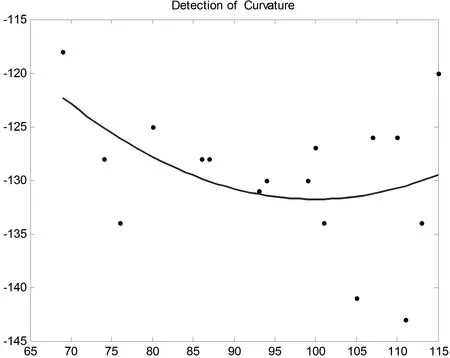
图9 非笑嘴的角点拟合曲线

图10 训练样本纵坐标均值分布曲线
通过计算发现,笑脸的角点纵坐标均值最大为105,非笑脸的纵坐标均值最小为110,因此设Pavg=108作为判断图片是否为笑脸的条件。在测试阶段,如果测试图像左右嘴角的纵坐标均值大于108,则该图片被判定为非笑脸;如果小于108,则为笑脸。经过测试,该方法的准确率达到了92%。
7 实验结果
实验采用Matlab软件进行程序编写及测试,训练图片为100张,其中包含50张笑脸图片,全部来自GENKI笑脸数据库,50张非笑脸图片,测试图片100张,包含多种表情,非笑脸图片和测试图片皆来自网络搜索。如图11和图12即为截取出的部分人脸图片,从中可以看出Viola-Jones算法对于检测截取人脸某一部分图片的效果非常好。
将截取出来的图片进行尺寸归一化,嘴部图片尺寸设置为18×18像素,单个嘴部的Gabor特征为一个360×1的矩阵,HOG特征为一个1×15的矩阵。应用于Gabor特征提取的脸部图片设置为88×88像素,每一个图片的Gabor特征为一个360×1的矩阵,应用于HOG特征提取的脸部图片设置为96×96像素,HOG特征为一个1×1215的矩阵。

图11 脸部截取

图12 嘴部截取
将所有用于训练的图片特征进行交叉组合得到训练总矩阵,将这个矩阵中代表笑脸图片特征的标签设为1,代表非笑脸图片特征的标签设为2,输入到SVM进行训练。用同样的方法求出测试库的特征,利用训练好的SVM进行分类。
基于角点检测的嘴角坐标法按照上述步骤处理,得到分类平均值为108,然后对测试库中的图片进行测试。表1为本方法的正确率。可以看出,嘴角坐标法的正确率高于Gabor和HOG方法。
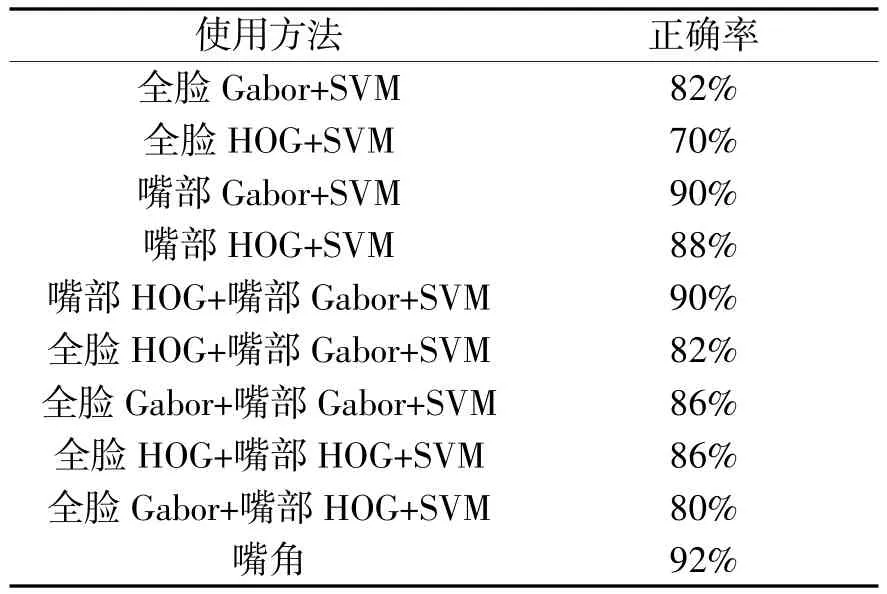
表1 不同算法的正确率
8 结束语
采用HOG和Gabor这两种特征提取方法来提取脸部特征,送到SVM进行分类识别,从而提出一种基于嘴角特征点的微笑检测方法。对于特征提取来说,提取嘴部的特征比提取整个脸部特征速度更快,而且数据量比较小,冗余数据就相对较少,这会使分类的准确率得到提升。通过融合不同的特征进行测试发现,提取嘴部Gabor特征的正确率最高,达到了90%,而基于嘴角坐标的算法正确率为92%,高于融合不同特征进行分类的正确率。在今后的研究中,可以尝试在角点坐标平均值的基础上,通过计算嘴部张开的面积等方法来进一步细分笑的程度。
