偏斜正态分布下的ZIP层次回归模型的贝叶斯方法
2018-10-30吕敏红闫奕荣
吕敏红,闫奕荣
(1.西安航空学院 理学院,西安 710077;2.西北大学 数学学院,西安 710069;3.西安交通大学 经济与金融学院,西安 710049)
0 引言
技术数据广泛存在于医疗、生物学、金融保险以及风险控制,拟合计数数据的单用分布主要有泊松分布,二项分布等。但是在实际问题中零观测的比例远超过了拟合分布的允许范围,即存在零膨胀,故零膨胀模型的研究已成为当今国内外的一个热点问题。
自从Lambert提出了零点膨胀Psisson回归模型[1]以来,关于具有零膨胀特征的计数数据已经有了多方面的研究,Greene(1994)[2]在Lambert的思想下提出了零膨胀的可加性负二项回归模型。Fahrmeir和Echavarria(2006)[3]研究了一类零膨胀的可加模型,Xie(2009)[4]系统研究了广义的Poisson混合效应模型的统计诊断问题,Ghosh(2006)[5]研究了零膨胀回归的贝叶斯方法,传统的零膨胀回归模型是对随机效应和随机误差作正态的假设,但是在实际中正态假设可能会导致无效的统计结论。本文考虑了随机误差和随机效应服从偏斜正态分布的ZIP层次回归模型的贝叶斯分析问题,最后用一个实例说明该方法的有效性。
1 零膨胀Poisson回归模型(ZIP)
ZIP分布的基本思想是取值为零的部分和取值为Poisson的部分各占一定的比例构成ZIP混合分布,即:

其中0<ϕ<1为零膨胀系数。显然当ϕ=0时,ZIP分布变为Poisson分布,λ为泊松分布的均值。(1)式的均值和方差分别为:

2 零膨胀Pission层次回归模型
在实际问题中,数据可能呈现内在关联或层次结构,为了刻画数据的这些关系,本文进一步定义层次回归模型[6],层次回归模型综合了线性回归和随机效应模型的优势。
假设Yij为本文感兴趣的响应变量,yij表示第i个群第 j个样本的观察数值。i=1,2,…,m, j=1,2,…,n 相对于传统模型,层次模型可将传统模型的误差项分解到与数据相对应水平上。若Yij~ZIP(φij,λij),针对膨胀参数 ϕij与均值参数λij建立如下混合效应模型:
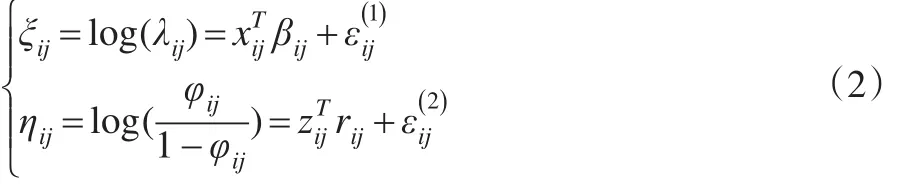
其中,βij与rij分别是协变量xij与zij的回归系数,
进一步对上层模型考虑线性回归,并引入随机效应:
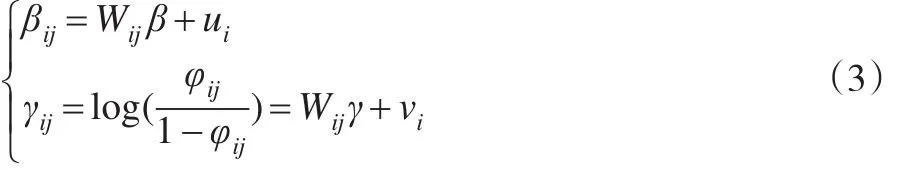
其中,Wij为协矩阵,β与γ为参数向量,ui与vi为随机效应。(2)式与(3)式合称为零膨胀Poisson层次回归模型。
3 偏斜正态分布下零膨胀Poisson层次回归模型的贝叶斯方法
经典的零膨胀Poisson回归模型一般都假设随机误差及随机效应都服从正态分布,但是这种假设过于理想化,现实中很多情况下并不满足,或者说有些数据按照这种假设建立的模型缺乏稳健性。接下来,本文考虑SN-ZIP层次回归模型。
3.1 SN-ZIP层次回归模型
n维随机变量Y服从n元偏斜正态分布,记作Y~SNn(μ,Σ,Δ),其概率密度函数为:
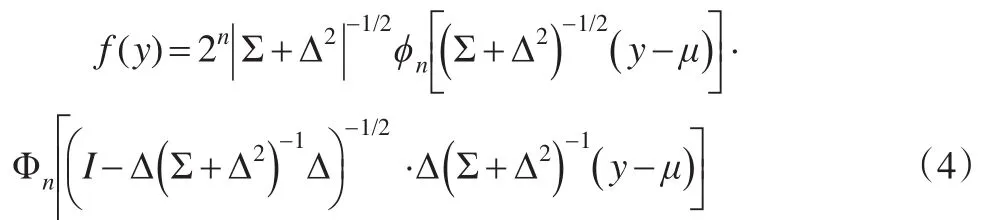
其中,μ 为均值,Σ 为尺度矩阵,Δ=diag(δ1,δ2,…,δn)为偏度矩阵,ϕn和Φn分别为标准正态分布下的概率密度和分布函数。特别当 δ=(δ1,δ2,…,δn)=0 时,分布退化成为多元正态分布。为使用方便,进一步写出(4)式的层次表示[7]:

假设ZIP层次回归模型中的随机误差和随机效应都服从SN分布,则ZIP层次回归模型便成为SN-ZIP层次回归模型。
首先,ZIP层次回归模型中的随机误差服从SN分布,即(2)式中的:

其中 Δk=diag(δ1(k),δ2(k),…,δn(k)),k=1,2 。
其次,ZIP层次回归模型中的随机效应也服从SN分布,即(3)式中的:

其中 Δu=diag(δu1,δu2,…,δun),Δv=diag(δv1,δv2,…,δvn)。
式(2)、式(3)、式(6)、式(7)合称为SN-ZIP层次回归模型。
3.2 贝叶斯推断
与似然方法相比,贝叶斯方法综合了样本中的先验信息,对于某些复杂的模型具有特别的灵活性,下面具体研究SN-ZIP层次回归模型的贝叶斯推断。
3.2.1 潜变量的数据添加
零膨胀回归模型中的响应变量Yij可以表示为Yij=Cij(1 -Bij)[5],其中Bij是具有参数φij的伯努利分布随机变量,Cij服从参数为λij的Poisson分布,那么给定:
Yij=yij时(Cij,Bij)的联合条件分布为:
当 yij>0时,Bij=0,Cij=yij,即:
P(Bij=0,Cij=yij|Yij=yij)=1
当 yij=0时,有两种情况 Bij=0,Cij=0或 Bij=1,Cij=cij,此时:
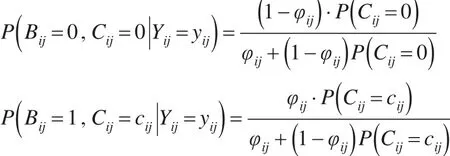
3.2.2 先验分布和参数设定
若 θ=(β,γ,δ(1),δ(2),δu,δvσ2(1),σ2(2),Σu,Σv)为本文涉及的全体参数,其中 β、γ是本文感兴趣的参数,δ(k)=(δ(k),
1
δ2
(k),…,δn(k))T,k=1,2。假设 f(θ)为 θ 的先验密度函数,在后面的贝叶斯推断中选择如下的独立先验分布,即:

其中Ωk=diag(σ2(k)), β0、γ0δu0、δv0为层次回归分析的截距项。σ2(k)、Γ(k)、Γu、Γv、ω1(k)、ω2(k)、ψu、ψv,Ru、Rv为超参数,超参数的选取一般通过给定的先验信息来确定。
3.2.3 模型建立
本文考虑随机误差和随机效应服从偏斜正态分布的ZIP层次回归模型,利用偏斜正态分布的层次表示方法,即式(5),本文建立如下模型。
第一步:潜变量建模
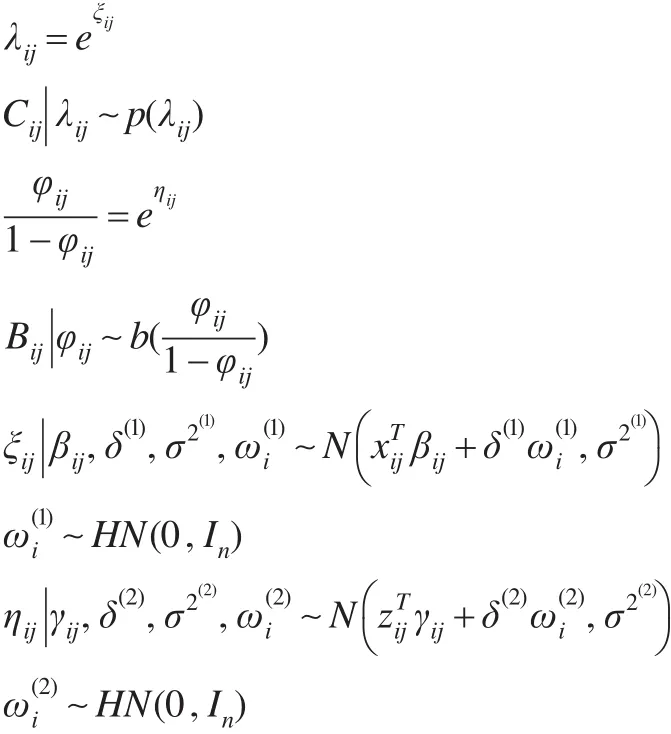
第二步:回归系数建模
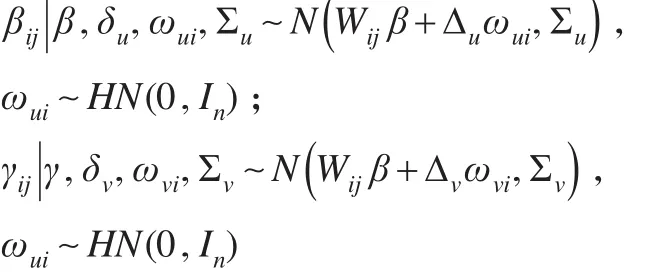
用贝叶斯的方法,参数θ的后验分布基于观测数据是很难直接计算出来的,可以采用Gibbs抽样和M-H算法[7],并且借助计算机可以较为简单的解决上述问题。在抽样过程中,由于Gibbs抽样的顺序不会影响贝叶斯估计的结果,当样本收敛后,就会得到感兴趣参数的估计值。然后,可以采用Johnson给出的贝叶斯拟合统计量[8]来计算模型对数据的拟合程度。
贝叶斯模型选择的方法有很多,比如贝叶斯因子,后验模型概率和后验预测检验等,本文选用BIC作为模型选择的准则:
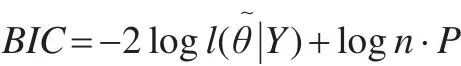
4 实例分析
数据来源于Lloyd社记录的34条船只的5年内发生事故受损的情况。本文对数据进行分析后发现其具有零膨胀特征。为了分析船只种类、建造时间及服务年限对受损情况的影响,本文建立了偏斜正态分布下的ZIP层次回归模型,计算出参数的后验均值及MC误差,具体见表1,其中A1,A2,…,A5表示船舶类型,B1,B2,…,B4表示建造年代,T1、T2表示服务年限。除使用上述模型外,本文还利用一般ZIP回归模型及ZIP混合效应模型对该数据进行了拟合,通过BIC准则比较了模型的优劣,计算结果见表2。

表1 参数的贝叶斯估计

表2 不同模型的BIC值
由表2可以看出,层次SN-ZIP的BIC值最小,表明用层次SN-ZIP模型对数据进行拟合,拟合程度最高。也是就说对于这组数据,偏态的作用是显著的,考虑对随机误差及随机效应服从偏斜正态分布比假设两者服从正态分布要合理。
5 结论
传统的ZIP层次回归模型的基本假设是随机效应和随机误差正态分布,然而在实际中,正态假设缺乏稳健性,也可能会导致无效的统计结论。为了精确处理参数估计的问题,本文考虑了随机误差和随机效应服从偏斜正态分布的情况,最后通过实例说明了该方法的有效性。但是缺失数据下的偏斜正态分布还有待进一步研究。
