基于回溯搜索的生物激励完全遍历路径规划
2018-10-25赵文勇王丹丹徐守祥
赵文勇,王丹丹,徐守祥,张 瑞,马 超
(深圳信息职业技术学院,广东 深圳 518172)
引言
未知环境下的完全遍历路径规划是移动机器人自主导航中的一个重要问题。当机器人工作在未知环境下,为了完全遍历工作空间,需要实时构建地图和动态路径规划。常见的完全遍历路径规划方法有人工势场法、模板模型法、神经网络算法等[1-4,12]。
传统的人工势场法[2]通过构造虚拟引力场和斥力场引导机器人向目标运动。该方法在实时避障和平滑轨迹控制方面得到广泛应用,但该方法存在一些缺陷:在处理局部最优解时,容易产生死锁;在靠近障碍物时容易震荡;在狭窄通道中摆动;存在陷阱区域等。
Hofner和Schmidt[3]提出的模板模型法需要事先定义好典型模板,因此该方法不适于处理动态变化的环境。
Simon X. Yang 提出了一种基于生物激励的神经网络算法[4],机器人在利用有限的传感器信息进行路径规划时,通过神经动力学建立了由正方形或矩形单元组成的环境地图。该方法与其它模型相比,不需要先验地图,不需要学习过程,不需要搜索全局自由空间,不需要精确计算代价函数,因此获得了广泛的应用。虽然该方法在完全遍历路径规划中有一定的优势,但也存在一些不足,如分离区域之间的路径非最优等。
本文在生物激励神经网络算法的基础上,结合回溯算法(Backtracking Algorithm[5])与D*算法(D Star[6][7])的优点,提出了基于回溯搜索的生物激励完全遍历路径规划方法。通过仿真比较,该方法相较于基于生物激励神经网络的完全遍历路径规划方法在覆盖重叠率与转向次数等性能指标上得到了改善与提高。
1 基于生物激励神经网络的路径规划算法
1952年,生物物理学家Hodgkin和Huxley提出了著名的神经细胞膜电路模型(membrane model[8])和描述该模型的细胞膜动力方程(H-H模型[8])。Grossberg在该模型的基础上总结和发展出了分流方程(shunting cooperative competitive feedback network,简称Shunting Equation[9],又称逃避方程),并将其应用于机器视觉和感觉运动控制系统。Simon X. Yang将Shunting Equation应用于移动机器人运动的环境建模和路径规划,得到了很好的效果。
1.1 生物激励神经网络模型
Grossberg提出的分流方程形式如下:



图1 神经元连接示意图Fig.1 The illustration of the neuron connection
1.2 路径规划算法
在基于生物激励的神经网络模型中,机器人的路径由状态方程及上一时刻所处的位置决定。给定机器人的当前位置,假设下个时刻的位置为,则按下式确定:



当机器人从当前位置到达下一个位置,下一个位置就变成新的当前位置(如果找到下一位置与当前位置一样,机器人将不会移动)。机器人下一时刻的位置根据变化着的环境作适应性地变化。图2是由算法(3)所产生的局部路径,该地图由30*23个栅格组成。机器人默认按照从左到右,上下往返运动(back and forward[11]),机器人从S(3,2)出发,将经过点D(14,2),最终到达终点E(29,8)。图3表示机器人在D的活性直方图,活性值最高的区域表示检测到的尚未遍历的区域,左边活性值衰减到接近0的区域表示已覆盖的区域,未知区域的活性值保持在0。从图中可以看出该算法在遍历过程中可将障碍物轮廓构建出来。

图2 机器人位于点(14,2)的路径Fig.2 The robot at D(14,2)

图3 机器人位于点(14,2)的活性直方图Fig.3 The coverage path planning with the robot at D(14,2)
1.3 生物激励神经网络的优点
由式(1)和式(3)可知,神经元状态方程是一个与周围神经元有关的一阶微分方程,路径规划则由神经元活性及前一时刻的位置综合决定,因此生物激励神经网络算法模型很简单。该算法不需要先验地图,机器人在利用有限的传感器信息进行路径规划时,建立了由正方形或矩形单元组成的局部地图,因此该算法可以实时构建环境地图。此外,该算法能有效处理死锁(deadlock)状态。当机器人陷入死锁时,能按照活性值由高到低的方向退出死锁,使得机器人不会陷入局部死循环。如在图4中,机器人自A往下运动到D,点D邻域内的8个点要么已经清扫,要么是障碍,机器人陷入死锁。然而,由式(1)可知,神经元活性方程是单调递减函数,当D的活性值衰减到低于C的活性值时,机器人将按从下到上的方向退出死锁,直到再次搜索到未完全遍历的位置B。图4和图5分别是遍历完成的规划路径和活性直方图。

图4 完全遍历路径Fig.4 The coverage path planning

图5 完全遍历活性直方图Fig.5 The histogram of coverage path planning
1.4 生物激励神经网络的不足
虽然生物激励神经网络具有诸多优点,但也存在不足。当机器人陷入死区时(如图2所示)机器人需在该处等待,直到周围的神经元活性大于当前神经元活性时,才能继续覆盖下去。特别是对相距较远的分离区域时,未遍历区域的高活性值在传递过程中可能衰减到0,或者传递到相邻神经元时活性值已经低于当前活性值,这将使得遍历不完整或路径非最优。为方便说明,可构建双U型障碍地图,如图6所示,机器人运行到点D(29,18)陷入死锁状态,此时还有3块区域S1,S2,S3未遍历。此时的活性直方图如图7所示。
由于S2与S3相隔较近,机器人在陷入死锁点D时,等待一段时间后能逃离死区,机器人将从上到下运行到S3区域,完成S3区域的遍历。然而,当机器人覆盖完S3区域时,由于S1与S2离S3较远,区域之间的神经元活性值衰减到接近0,S1对机器人缺乏引导作用,机器人最终的行走路径较为混乱。图8(a)为最终遍历后的路径,明显存在很多重叠路径。
2 基于回溯搜索的生物激励算法
针对生物激励神经网络存在的上述不足,本文提出了基于生物激励神经网络与BT回溯算法及D*搜索算法相结合的基于回溯搜索的生物激励算法。BT回溯算法可以实现快速定位目标点,D*算法是求解动态二维环境最短路径的有效算法,将两种算法与生物激励神经网络结合,可以有效规划出分离区域之间的最短路径。

图6 未遍历区域S1,S2,S3Fig.6 The uncovered area S1,S2,S3

图7 机器人位于点(29,18)的活性直方图Fig.7 The histogram of activity at (29,18)
2.1 算法描述
首先利用生物激励神经网络使机器人覆盖工作空间,直到陷入死锁。机器人在行走过程中构建空间地图,将检测到的邻域内有未遍历的点作为节点记录下来,并按时间先后顺序保存在节点队列表中,同时剔除已遍历节点。当机器人陷入死锁时,说明局部区域已经遍历完成。这时,将当前点设置为起始点,从节点队列中找到距当前时间最近的节点作为下一个目标点。再根据已经构建的环境地图,由D*算法规划出一条点到点的最短避障路径,当到达目标后,由于目标点邻域内有未遍历区域,机器人退出死锁,并按照生物激励神经网络算法遍历该区域。由于D*算法能实时更新启发函数,因此即使在点到点规划过程中遇到未知障碍,也能轻松避障,并以最短路径到达目标点。当节点队列的节点数为0时,说明已经没有未遍历节点,结束遍历工作。
在算法中,定义状态变量 ,表示神经元在位置 的状态,取值如下:

改进后的算法包含以下四个方面:
(1)初始化阶段:初始化算法目的是初始化机器人起点位置,将所有神经元状态置0,将节点队列清空,限定地图大小等。具体见算法1。
(2)地图与节点队列构建阶段:本阶段主要依赖于机器人携带的传感器。本算法假设环境完全未知,外部输入 包含了机器人本身的状态和周围环境状态。因此,机器人对整个空间只有有限的认识。在未知的环境下,机器人朝活性最高且转向最小的未清扫区域移动,并实时建立地图,直到完全覆盖可达区域。同时,当机器人检测到存在节点时,将该节点保存在节点队列,并移除已经遍历过的节点。
(3)全局路径规划阶段:未清扫区域通过神经活性传播在整个状态空间吸引机器人,而障碍只在小区域内使机器人避免碰撞。算法2给出了覆盖算法。该算法中,一旦机器人从当前位置移到下一个位置,下一个位置就成为新的当前位置,之前的位置被标记为已覆盖(见算法2)。下一个位置由神经活性和转向角确定。
(4)点到点路径规划阶段:该阶段的执行并不是必须的,只有当机器人陷入死锁(如图6所示S1、S2、S3)才需要执行此阶段。此时,取队列中与当前位置相隔时间最近的节点作为下一个位置,利用D*算法规划最短路径。
2.2 算法伪码
算法1:初始化算法
算法2:覆盖算法
//未完全遍历,则将当前节点加入队列首位
(3)扫描队列,移除已经遍历的节点;
//检测周围环境,设置标志位和外部输入
(6)判断当前状态:

3 仿真研究
本文提出的基于回溯搜索的生物激励完全遍历算法能够使机器人在没有任何人工干预下自动完成完全遍历路径规划。利用该算法,在图6所示的地图下能实现完全遍历路径规划,规划出的路径如图8(b)所示。
图8(b)中,黑色代表障碍物,蓝色带箭头直线表示运行方向,红色点表示死锁点,绿色点表示从死锁点规划到目标节点的最短路径。根据图8(b)的三条绿色路径,机器人在陷入死锁后,从节点队列中找到距当前时间最近的未完全遍历节点,并由D*算法规划出一条最短路径,进而逃离死锁。通过与图6进行直观对比,可以发现本算法产生的路径更加合理,更少陷入死锁。表1是两种算法在双U型障碍下的性能指标对比。在本例中,两种算法均实现了100%的遍历覆盖率,转弯次数上也不相上下,但在遍历重叠率上,本文提出的算法明显优于基于生物激励神经网络算法。
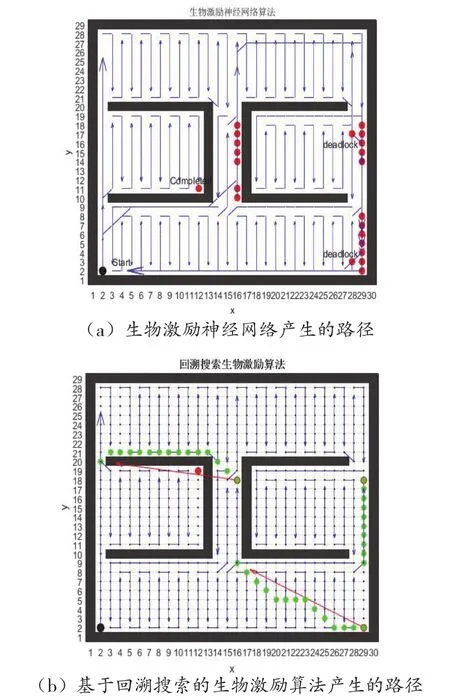
图8 研究双U型地图下的完全遍历路径规划仿真

表1 双U型障碍下的性能指标对比Tab.1 The performance comparison of the double-U map
上述双U型障碍环境下的仿真实例,验证了本方法相对于生物激励神经网络算法在性能指标上能得到显著改善和提高,而且规划的路径更为合理有效。本仿真所假设的环境比较规则,下面对环境更为复杂的情况进行仿真研究。
图9所示环境中,有U型障碍物、梯形障碍区、窄道和其他不规则障碍物,图9(a)是采用文献[2]提出的生物激励神经网络算法所规划的遍历路径。该路径从起点S(2,2)开始遍历,当遍历到R(36,14)时,陷入死锁,利用生物激励神经网络方法,机器人能沿着活性降低及转角最小的方向移动,当运行到T(31,26)时,检测到未遍历区域,进入正常的路径规划阶段;当机器人运行到U(36,34)时,再次陷入死锁,机器人沿着活性降低和转角最小的方向移动,直到运行到V(23,18)时,检测到前方有障碍物,才更改方向向下运动。
图9(b)是采用本文提出的基于回溯搜索的生物激励算法所规划出的路径。当机器人遍历到R(36,14)时,陷入死锁,利用回溯搜索算法,找到距离当前时间最近的目标点T(31,26)(如红色带箭头直线指示),利用D*算法规划出最短路径,当到达T后,检测到未遍历区域,进入正常的路径规划阶段;当机器人运行到U(36,34)时,再次陷入死锁,回溯搜索法找到目标点V(33,35)。由路径图可以直观看出,基于回溯搜索的生物激励算法规划出的路径比生物激励神经网络算法规划出的路径具有更短的遍历长度和更少的转弯次数。表2列出了两种算法在复杂环境下各种性能指标上的差异。

(a)生物激励神经网络产生的路径

Fig9 The coverage path planning of the Asymmetry map图9 复杂环境下的完全遍历路径规划仿真研究

表2 复杂环境下的性能指标对比Tab.2 The performance comparision of the Asymmetry map
4 结束语
本文提出的基于回溯搜索的生物激励完全遍历路径规划算法能有效实现动态障碍物和不确定环境下的完全遍历路径规划问题。在两组较为典型的环境情形下,将本文提出的算法与基于生物激励的神经网络方法进行比较研究,结果表明,本方法在转弯次数、遍历重叠率、遍历长度等指标上都有明显的提高,不仅保证了完全遍历所有可达空间,而且优化了运行轨迹,减少了重覆盖率,显示了该方法具有一定的优越性和有效性。下一步的研究工作将考虑把本方法应用于动态障碍物与不确定环境下的多机器人协同工作,实现完全遍历路径规划问题。
