卷积神经网络双目视觉路面障碍物检测
2018-10-24马国军王亚军
胡 颖,马国军,何 康,王亚军
(江苏科技大学 电子信息学院, 江苏 镇江 212003)
0 引 言
传统立体匹配算法[1]有SAD/SSD[2]、Adapt weight[3]等基于像素灰度值相似度的算法以及归一化互相关(normalized cross correlation,NCC)[4]、Gradient[2]和Census[5]变换等基于像素灰度提取特征相似度的算法,这些算法对纹理不明显的路面场景匹配精度差。卷积神经网络(convolution neural network,CNN)[6]是一种数据驱动型算法,能从大量的样本数据中自动提取图像中多种隐性特征,因此得到广泛应用。在立体匹配方面,文献[7]设计一种孪生结构MC-CNN,应用于图像块的相似度度量,全连接层的采用极大地增加了网络参数,有效提取图像对的深度信息,但由于卷积层数较少,无法提取深层特征;文献[8]改进MC-CNN孪生结构,增加卷积层数并使用支持向量机(support vector machine,SVM)作为网络输出层,应用于双目视差评估,取得较好的精度。
在障碍物检测方法中,文献[9]采用数字高程图(di-gital elevation model,DEM)的方法实现障碍物检测,具有较好的鲁棒性,但需要对环境进行三维重建,计算复杂,不适合车载计算机实时演算;文献[10]采用光流法检测路面运动障碍物,但无法检测静止的障碍物;文献[11]采用V视差法实现障碍物检测,该方法计算简单,但在道路信息较少的场景中,道路直线提取会受到干扰,降低了障碍物检测效果。
本文提出一种利用卷积神经网络的路面障碍物检测方法,以解决传统方法在匹配精度差,检测算法稳定性与鲁棒性差等问题。首先,设计一种孪生卷积神经网络用于生成立体图像对的视差图;其次,提出道路直线自适应阈值提取算法,以精确提取V视差图中道路直线;最后,逐个判断各个像素点是否为障碍物点。
1 视差计算
在局部匹配方法中,NCC、Gradient和Census变换等只提取图像中的人工特征,进行匹配代价的计算,CNN能够自动提取图像中多个隐性特征并计算匹配代价,从而获得更高精度的视差图。
1.1 网络结构设计
本文设计如图1所示的孪生网络结构,其左右分支参数共享。该孪生网络结构由特征提取子网络(L1-L8)和特征分类子网络(L9-L10)两部分组成。特征提取子网络左右分支能够分别从输入的图像方块和图像长条中提取对应的特征描述;特征分类子网络将提取的左右分支特征描述作点积运算,得到视差搜索范围内待匹配像素点的相似性得分,然后作为softmax层的输入得到视差概率分布。
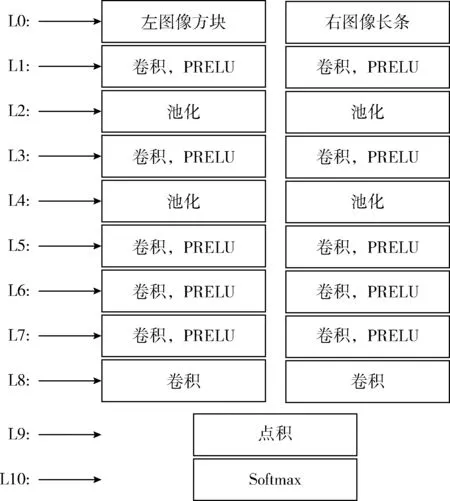
图1 孪生卷积神经网络结构
特征提取子网络左右分支分均包含一个输入层(L0),6个卷积层(L1,L3,L5,L6,L7,L8)和2个池化层(L2,L4)。卷积层采用大小为5×5,数量为32或64个卷积核提取各层信息;同时,使用Batch Normalization技术以弱化网络对初始化的依赖,使得卷积神经网络更容易训练;最后在卷积层上使用PRELU激活函数,输出卷积层结果。在L8卷积层中不使用激活函数是为了保留输出的特征描述负值信息。在池化层中,采用最大池化方式,其中L2层采用9×9池化核,L4采用5×5池化核。最终,特征提取子网络左分支输出1×64维特征描述,右分支输出201×64维特征描述。特征分类子网络包含1个点积层(L9),1个softmax层(L10)。L9层将L8层提取的两个特征描述对应各个视差作点积运算,得到视差搜索范围内待匹配像素点的相似性得分,输入softmax层得到视差范围内视差概率分布。表1给出了卷积神经网络结构的具体参数。
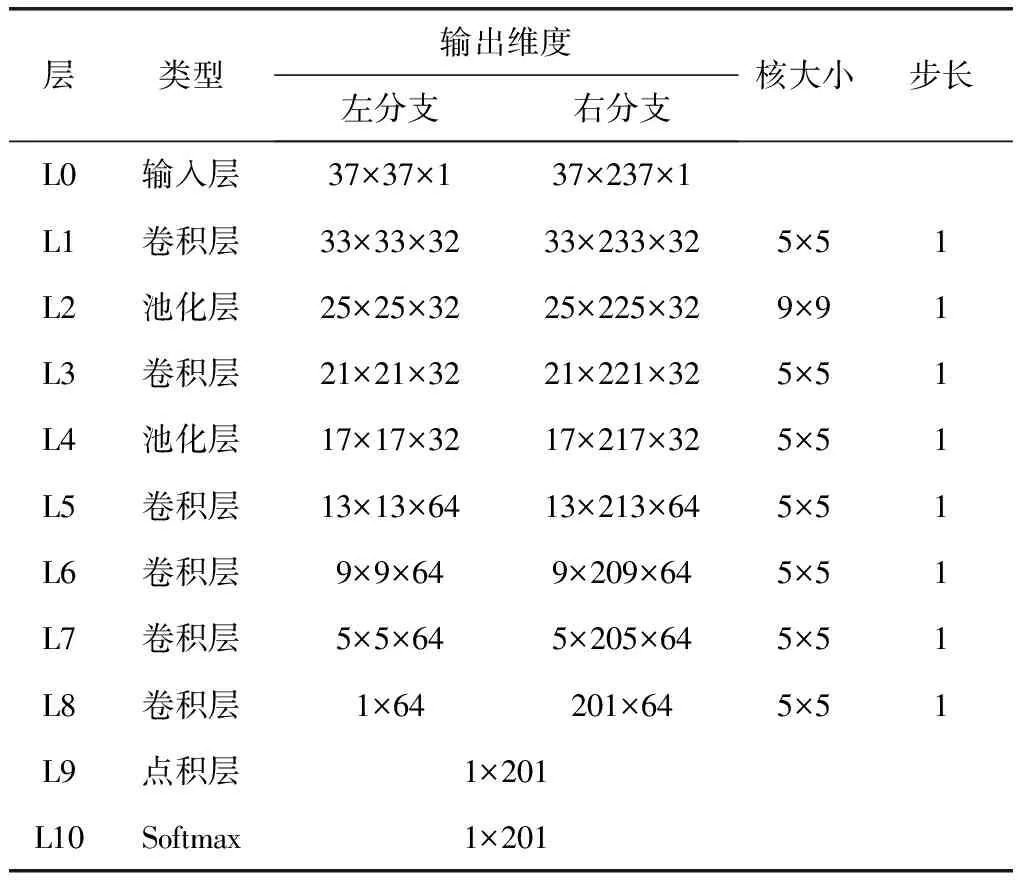
表1 孪生卷积神经网络参数
局部匹配时,通常选择像素点的局部支持窗口作为匹配单元,根据文献[12]的对比实验,选取37×37像素大小的窗口可以得到最优的匹配效果。针对KITTI数据集[13]的真实最大视差,设定视差搜索范围为201像素,故输入网络右分支的图像长条的大小为37×(201+37-1),即37×237像素。
1.2 卷积神经网络的训练
1.2.1 训练集构建
(1)样本裁剪
基于CNN的视差计算方法属于局部匹配方法,要求输入给CNN的数据为图像局部方块。本文使用KITTI双目数据集中的图像的分辨率为375×1242,不能直接输入本文的CNN结构,需要将其进行相应的裁剪,步骤如下:
1)根据KITTI数据集中的真实视差数据,在左图像中选取具有真实视差的像素点p,并记录该点图像坐标(xi,yi);然后提取以该像素点为中心的37×37的图像方块,如图2(a)所示;
2)在右图像中选取像素点q,其坐标为(xi,yi),并以q为中心选择37×37的图像方块。根据视差搜索范围,在右图像中选择以q为中心,图像方块右边界左侧大小为37×237的图像长条,如图2(b)所示。从而该图像长条包含了视差搜索范围内所有待匹配图像方块。
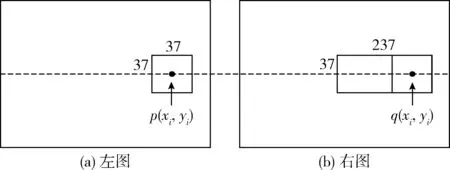
图2 样本裁剪
以此步骤,提取KITTI数据集中所有的图像构建训练集。选用KITTI数据集中200对图像中160对图像用于网络训练,由此方法提取的图像块共有14 248 394对。
(2)标准化处理
样本裁剪后得到的训练集中,原始数据范围为[0,255],不能直接作为网络的输入,需要对数据进行标准化处理。利用式(1)将原始数据变换到[-1,1]范围内,并以此作为网络的输入
(1)
其中
(2)
(3)
1.2.2 网络训练
网络的输出为softmax分类层,在训练过程中需要对网络权重w最小化互熵损失函数。针对本文的应用场景,对原始互熵损失函数进行了相应的修改,如式(4)
j(ω)=∑i,dipgt(di)lgpi(di,w)
(4)
其中
(5)

本文采用自适应矩估计的随机梯度下降算法(Adam)[14]来优化式(4)的损失函数,并调整网络参数,根据损失函数对每个参数的梯度的一阶矩估计和二阶矩估计,动态调整每个权值的学习速率,使得网络权值平稳、迅速达到最优解。
1.3 视差计算
训练良好的卷积神经网络能够有效提取左右图像中各像素点的64维特征描述,分别记作SL(p)和SR(q),其中p和q表示为左右图像中的点;将SL(p)与SR(q)作点积运算得到图像对相似性得分,然后将该相似性得分取相反数作为图像对之间的匹配代价CCNN(p,d)
CCNN(p,d)=-s(
(6)
式中:s(
最后,采用胜者为王(winner-take-all)策略[15],在视差搜索范围内,选择匹配代价最小的点作为匹配点进行视差选择,进而生成视差图D
(7)
2 障碍物检测
V视差法通过累计视差图的同一行中视差值相同点的个数,将原图像中的平面投影成一条直线。在障碍物检测问题中,路平面被投影成V视差图中的一条斜线,即路面检测由平面检测转化成直线检测。通过引入直线检测算法,提取V视差图中的路面直线,即可准确获取路面在图像中的区域,进而判断非路面区域为障碍物区域。
2.1 道路直线提取
针对传统的V视差法在道路信息较少,且存在较多较大障碍物干扰时,不能准确提取道路直线的问题,本文提出了道路直线自适应阈值提取算法。
(1)在视差图的列方向上,路面像素值均匀变化,而障碍物区域,像素值基本不变,本文采用Prewitt算子计算视差图列方向的梯度,并保留梯度为负值位置的视差,以滤除障碍物像素点,如式(8)
D(G≥0)=0
(8)
其中

(9)
G=D⊗h
(10)
其中,h为Prewitt算子,D为原视差图,G为视差图列方向梯度,符号⊗表示卷积。
图3(a)为原始视差图,滤波后如图3(b)所示,可以看出图像中大部分的障碍区域被滤除并保留了大部分的路面信息。

图3 道路直线提取自适应阈值算法过程
(2)对滤波后的视差图计算其V视差图I1,如图3(c)所示。由于路面为平面,在视差图中每一行的视差值相等,而在V视差图中表现为每一行的最大值,搜索I1中的每一行最大值并保留,其余像素点灰度值置0,从而获得V视差图I2,如图3(d)所示。
(3)为去除摄像机远端非路面像素点的干扰,设定阈值T,将I2中大于T的像素灰度值置1,其余置0,生成仅包含道路信息的V视差二值图I3,如图3(e)所示,阈值T的计算公式为
(11)
式中:xi为I2中各像素值;N为I2中像素总个数;1{xi≠0}表示xi不等于0时取1,否则取0。
(4)运用hough变换提取I3中路面直线,如图3(f)中红线所示。
2.2 障碍物区域判定
在V视差图中,道路直线是路面投影,道路直线上方的点是障碍物投影。将视差图中每个像素点投影到V视差图中,通过判断其是否在道路直线上,从而检测视差图中像素点是否为障碍点,步骤如下:
(1)计算道路直线在V视差图中图像坐标的斜率k和截距b;
(2)按照光栅扫描法,从下往上从左往右逐点扫描视差图D(x,y,d),对每个像素点计算f=kd+b;
(3)若(f-y)>T1,则视差图中像素点投影在V视差图中高于道路直线,即高于路面,则该像素点为障碍点,其中,T1为去除路面不平现象而设定的阈值;
(4)重复步骤(2)、步骤(3),直至完全扫描视差图,得到图像中障碍物区域。
3 实验结果与分析
为验证本文方法,使用Torch深度学习框架和MATLAB2015a软件进行仿真实验。硬件平台为Intel core i5-6500 CPU、12 GB内存和NVIDIA GTX 1070,使用KITTI双目数据集中的200对图像,包含乡村、城市、高速公路等多种道路场景。实验时,选取其中160对图像作训练集,40对图像作测试集。
3.1 视差图生成实验
为了验证本文孪生卷积神经网络计算视差图的有效性,在测试集选取21组不同场景的图像,其中乡村、城市、高速公路场景各7张,进行测试。图4列举部分场景的测试结果,图4(a)、(c)、(e)为原始图像;图4(b)、(d)、(f)为计算的视差图。

图4 部分场景视差计算结果
采用误匹配像素百分比(percentage of bad matching,PBM)的评价,估算出的视差图与标准视差图的误匹配率,并与NCC、Gradient、Census视差计算方法进行对比。表2为21组场景的平均误匹配像素百分比,本文方法的平均PBM为4.29%,远低于NCC的16.78%、Gradient的37.31%、Census的12.16%;图5为21组场景误匹配像素百分比分布,本文方法PBM的标准差为0.0207低于NCC的0.0832、Gradient的0.1005以及Census的0.0569。表明本文视差计算方法的稳定性与鲁棒性更好。

表2 不同方法平均误匹配百分比
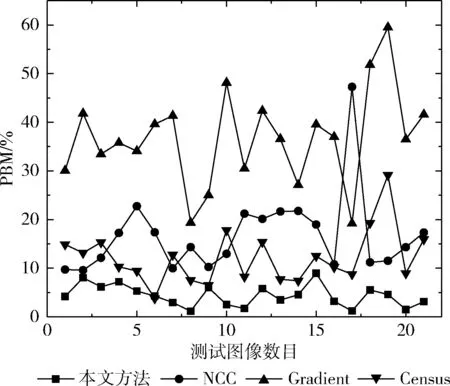
图5 不同方法误匹配百分比
3.2 障碍物检测实验
图6列举了乡村、城市、高速公路场景使用本文V视差法的障碍物检测结果,其中,阈值T1=5。图6(a)、(c)、(e)为原图像,图6(b)、(d)、(f)为障碍物检测图,图中亮色区域为障碍物区域。
为进一步的评价本文V视差法,与传统V视差法在召回率和精确率两个指标上进行比较。召回率表示障碍像素点被预测正确的比率;精确率表示预测为障碍像素点是真障碍点的比率,计算公式如下

(12)
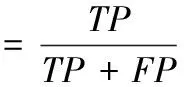
(13)
其中,TP表示正确的正检测结果,FP表示错误的正检测结果,FN表示错误的负检测结果。本文V视差法与传统V视差法在召回率和精确率的对比如图7所示。
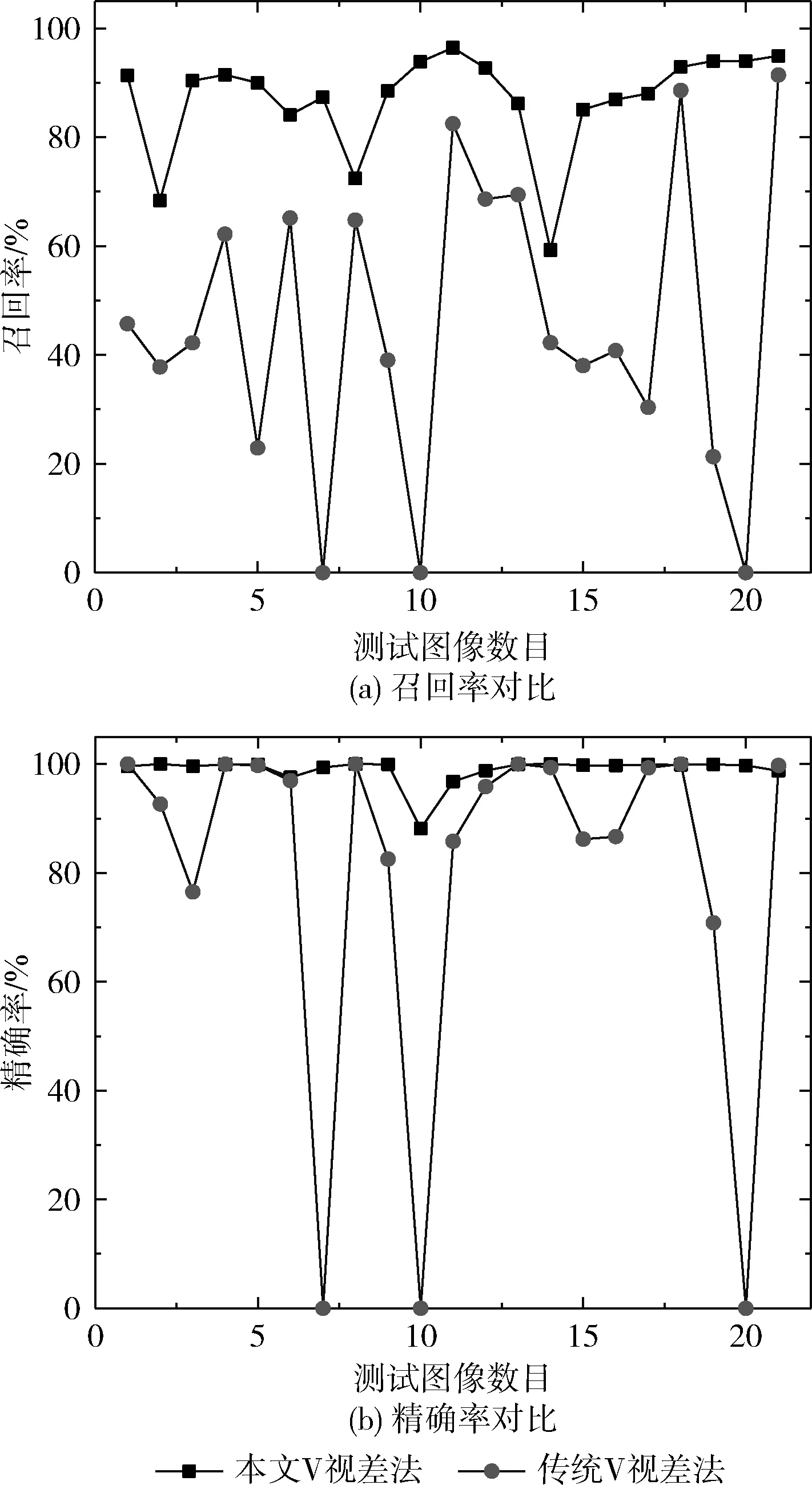
图7 召回率与精确率对比
本文的V视差法在所有的场景中均能够有效地识别出障碍区域,且召回率和精确率要优于传统V视差法,其标准差分别为0.0901和0.024,小于传统V视差法的召回率与精确率标准差0.2667和0.0884,表明本文V视差法检测障碍物的可靠性。
3.3 阈值T1对障碍物检测结果影响
在障碍物检测过程中,阈值T1是为了去除真实路面不平的现象,阈值T1的选取对检测效果有较大影响。本文对T1在[0,30]范围内进行取值实验,计算其召回率和精确率,由表3可知,召回率随着阈值T1的增大逐渐的减小,精确率在阈值T1=5时为99.05%,并随着阈值的增大缓慢增大。综合考虑,当阈值T1=5时障碍物检测效果最好。
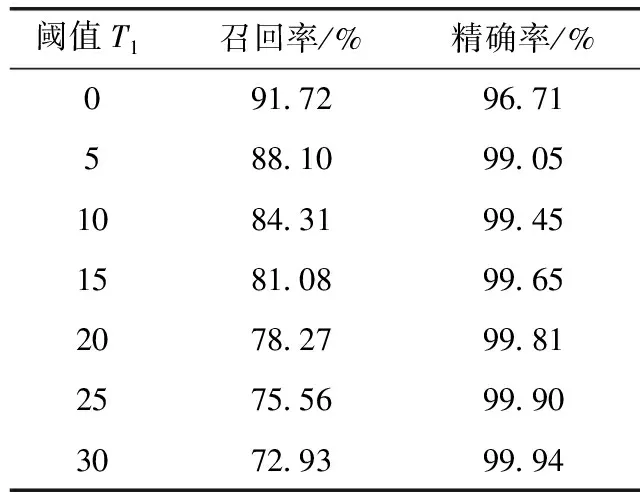
表3 不同阈值T1召回率与精确率
4 结束语
本文设计一种孪生结构的卷积神经网络生成视差图,在传统V视差法基础上提出道路直线自适应阈值提取算法,利用KITTI数据集对该方法进行测试。实验结果表明,该方法具有如下优势:
(1)孪生卷积神经网络在处理立体图像对时,可提取单个像素点的64维特征,用于匹配代价计算,避免了人工特征的局限性。相比于传统的视差生成方法,具有更高的精度。
(2)本文V视差法通过道路直线自适应阈值提取算法有效提取道路直线,从而完成路面障碍物检测,相较于传统V视差法具有较高的召回率、精确率和可靠性。
