基于Hadoop分布式文件系统的商业银行大数据分析
2018-10-22张登耀
张登耀
基于Hadoop分布式文件系统的商业银行大数据分析
张登耀
东北财经大学 金融学院, 辽宁 大连 116025
针对当前Hadoop分布式文件系统数据分析时存在的数据读取时间长,数据本地化率低等问题,本文提出了一种基于Hadoop分布式文件系统的商业银行大数据分析方法。首先对Hadoop分布式文件系统的工作原理和流程进行分析,找到引起不足的原因,然后根据商业银行大数据的特点,对Hadoop分布式文件系统的数据副本数量和数据分布位置进行相应的改进,最后通过仿真模拟实验对数据读取速度、本地化率、磁盘负载等进行分析。结果表明,本方法可以有效减少数据读取时间、提升数据本地化率并均衡磁盘负载,整体性能要明显优于对比方法,具有更好的实际应用价值。
Hadoop文件; 商业银行; 大数据
Hadoop分布式文件系统(Hadoop Distributed File System,缩写为:HDFS,下文同)通过节点可用空间分布数据来确保节点间的数据负载均衡,同时采用静态数据副本策略来确保数据存储安全,也就是HDFS的设计架构考虑了数据负载均衡和数据存储安全两项关键因素[1]。但是,缺乏数据处理时对数据访问特点的考虑,导致在提升数据读取性能的时候无法充分利用存储资源。基于此,本文通过剖析商业银行大数据处理过程,深入了解HDFS数据读取特点,结合数据访问频率以及不同数据被同时访问的可能性,提出两项优化策略即调整数据副本数量和数据分布位置,可以减少Hadoop中读取数据所需的时间、提高数据处理时的数据本地化率,从而提升数据存储、读取和处理的性能。在研究中,通过仿真实验的方式验证这两项优化策略,分析仿真实验数据,明确调整方案的可行性和有效性。
1 HDFS的存储架构
HDFS的每个集群采用了由一个管理节点(Name Node)和多个数据节点(Data Node)的主从架构模式(图1)[2]。其中,Name Node具有两项主要职责,其一是负责存储和管理文件系统的元数据信息,包括数据块的存储位置、命名空间、访问权限以及文件和数据块之间的对应关系等信息;其二是负责孤儿数据块的收集、数据块存储位置的调整等任务。Data Node也具有两项主要职责,其一是负责存储和管理数据,包括执行数据块的创建和删除指令、执行数据的读写请求、来自管理节点的块复制指令等;其二是周期性地向管理节点反馈状态信息。当进行数据操作时, 请求端将相关请求发送至Name Node,Name Node通过权限检查后选择合适的Data Node,由Name Node反馈相关元数据信息给请求端,请求端根据元数据相关信息来执行具体的数据操作。
2 HDFS的读写流程
为了说明HDFS中的数据读写流程,本文以一个Map Reduce计算过程中的数据读取来进行说明。由于Map Reduce是一种应对数据密集型问题的编程模型和相应运行环境实现,已被商业银行广泛用于大数据处理领域[3]。典型的Map Reduce过程可以分解为先Map后Reduce的两个阶段,大体过程为:在Map阶段从HDFS中读取数据,进行Map任务的执行,然后将Map产生的中间结果数据写入到缓存中,等待Reduce任务读取中间结果数据,再进行Reduce任务的执行,执行结果直接返回用户或写入到HDFS中,即为完成一个Map Reduce过程[4]。一个Map Reduce过程至少应包含一次读取数据和一次写入数据操作,其执行流程如图2所示:

图 2 典型HDFS数据读写流程图
3 商业银行大数据特点分析
商业银行会将日常与客户交互过程中产生的交易日志数据、音频视频数据以及内部业务处理过长的处理痕迹数据、处理结果数据等随时间点被保留下来,这样处理机制及其结果的特点为多次读取、极少修改的存储特点[5]。商业银行的数据具有明显的时效性,例如客户行为数据、市场利率数据、客户信用数据、宏观经济数据,其价值与产生的时间紧密相关。Hadoop在设计的时候,制定的机制使存储在HDFS中的数据会频繁被读取,但是极少被修改,即使数据产生之后需要被修改,也不是对其直接修改,而是产生新数据。因此,可以将具备读取频率高、修改极少的数据放置在HDFS中实现归档和数据分析。
4 仿真改进的HDFS副本策略
基于上述对商业银行大数据特点的分析,本文提出对数据的副本数量、数据的分布位置进行策略调整,通过比较数据访问热度值、数据访问相关性,仿真验证改进后的效果,策略如下:
4.1 仿真调整数据的副本数量
通过统计不同时间段的数据访问频率,并针对不同时间段设置不同的权重系数,来定义数据的访问热度值[6]。同时,根据生产系统整体的可用空间、数据修改成本、网络开销等设置调整数据副本数量的阈值范围。在此基础上,可以不断地调整数据副本数量,通过观察数据访问热度值所在阈值范围的变化,达到最佳效果。
现定义数据访问热度值,使用H来表示单位数据的访问热度,H表达式为:
H=1×F1+2×F2+…+K×F+…+K×F(1)
其中,K表示第个时间段的权重系数,F表示单位数据第个时间段的访问频率,表示总计考虑个时间段,单位选取次数/小时,单位数据大小为1个数据块[7]。
在初始状态下,每份数据默认拥有3个副本。随着数据访问地持续,产生不同的数据访问热度,可以结合可用的存储容量空间,仿真设置几个副本阈值,并设定不同的副本阈值对应的副本数量不同。在仿真读取过程中,通过观察数据访问热度值范围的变化,动态地调整数据副本数量,不断修正数据副本的数量,以便更好地满足数据访问的特点[8]。
调整数据副本时,计算每份不含副本数据的热度值,然后根据数据的热度对比关系,触发一次针对该数据的副本调整策略。
4.2 仿真调整数据的分布位置
具体方案为根据不同数据被同时访问的情况来计算其关联关系,并对不同的时间段赋予不同的权重系数[9]。根据数据访问状态、存储可用空间等设置调整数据分布位置的阈值范围。随着对数据访问的持续进行,根据关联关系所在阈值范围的变化对不同数据进行整合或拆分操作,完成相应的数据位置调整。
现在进行数据访问相关性定义,用R来表示两个单位数据和之间的访问相关度,R表达式为:R=1×E1+…+K×E+…+K×E(2)
其中,K表示第个时间段的权重系数,E表示数据和数据第个时间段的访问相关度,表示总计考虑个时间段,单位选取为次数/小时,单位数据大小为1个数据块[10]。
在每个将进行数据副本调整的时刻,首先按照上述公式计算每份不含副本数据与其他不含副本数据的一个相关度值,然后根据相关度值排序,进行两个数据副本位置的调整。
5 仿真实验结果及分析
5.1 仿真测试过程
在仿真测试过程中,有两个关键问题,其一是触发调整副本数量、调整副本位置的时刻选择;其二是数据副本的数量控制和数据副本位置关系的控制[11]。
仿真调整数据副本数量的关键在于数据副本的增加。在HDFS中,在Name Node进行相关元数据的删除,即可减少数据副本的数量,而数据副本增加相对比较复杂,不仅涉及Name Node副本数据的增加,还涉及数据复制,时间成本相对较高。在本文仿真模拟试验中,为了减少不必要的开销,不独立触发进行数据副本增加的试验,而是借用数据在处理过程中临时缓存到其处理节点,从而实现数据副本的新增,这种数据拷贝方法并没有增加额外的网络开销。
仿真调整数据副本位置的关键在于数据相关性的判断。在判定了数据相关度的基础上,还需要考虑数据副本调整会增加数据拷贝相关的成本。与上述情况类似,在本文中不独立触发进行数据副本位置调整的操作,不会增加额外的网络开销,主要开销同样是元数据调整开销。
5.2 仿真测试参数及结果分析
仿真测试机器的基础环境为64位CentOS 6.4操作系统,软件版本为Hadoop 2.6.0和JDK 1.8.0。测试参数设置为:存储数据总数为30000份;总存储空间为90000份;每个节点可以存储的数据份数为300份;每份数据的副本数量默认为3份;副本数量最大允许为9份;数据访问发生的时刻为300个;在一次仿真模拟过程中,每一个数据被访问的总次数为一个随机整数值,其值属于[10,1000],每一个数据第一次被访问的起始时刻为一个随机整数值,其值属于[1,300];每一个数据访问次数和两个数据同时访问次数在其可以访问时段的概率为,是一个随机值的指数分布,其值属于[0.1,0.2]。
分析仿真模拟试验数据,从为0.1时的指数分布图(图3)可以看出,数据在最开始产生时,被访问或同时访问的概率较高,随着时间的持续,数据访问概率逐渐减小。为0.2时的情况与为0.1时的情况类似,访问概率减速更快,也就是曲线更加陡立。

图 3 λ=0.1的指数分布
5.2.1 数据副本数量改进仿真实验结果在上述环境下,按照上述参数设置,进行了100次数据副本数量仿真试验(图4),对比数据副本改进前后的仿真试验数据,改进之前默认为不发生数据副本数量的增加操作,改进后数据副本数量发生改变的次数占整体访问次数的比例大致位于18.5%~19.0%之间,其均值为18.8%,该数值表明了Name Node应该将18.8%副本保留在本地,提供给后续访问,可以节省各方面的开销,提高访问存储的性能。
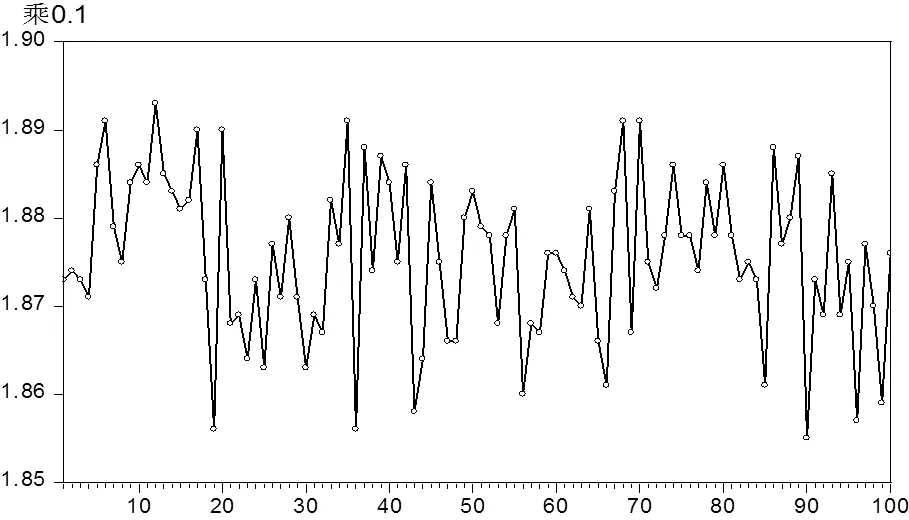
图 4 副本调整次数所占比例
注:①横坐标为仿真模拟实验编号;②纵坐标为“发生副本调整次数与数据访问总次数的比值”。
Note: ①The abscissa is the numbering of the simulation experiment; ②The ordinate is the ratio of the number of times that the number of copies is adjusted to the total number of data accessed.
使用上述参数设置,采用默认副本数量为3,同样进行了100次副本数量改进仿真试验,统计得出改进后副本数量(图5)。对比数据副本改进前后的仿真试验数据,改进之前数据副本默认为3,改进之后数据副本增加为7.635~7.675之间,数据副本增加了2.5倍,每份数据每时刻需满足的访问需求个数相比原来的存储方法减少40%,这样可以更好地满足数据读取的需求。

图 5 副本数量变化值
备注:①横坐标为仿真模拟实验编号;②纵坐标为副本数量变化值。
Note: ① The abscissa is the serial number in the simulation experiment; ② The ordinate is replica number change value.
5.2.2 数据副本位置改进仿真实验结果使用上述参数设置,得到的仿真测试结果显示,仿真改进后的算法相对于原有的算法,数据本地化率提升了25.6%,而在20.4%的时刻会发生数据副本位置的调整操作,该数值表明了Name Node需要增加更多的开销(表1)。

表 1 调整数据副本位置的仿真测试数据
仿真数据表明,仿真改进后的方法可以减少数据处理时所需读取的数据不在本地的概率,提升了数据本地化率,从整体上减少了等待数据的时间,降低了存储数据节点的磁盘负载等。
6 总结
通过分析商业银行大数据访问的特点,深入研究HDFS数据存储机制、Map Reduce的数据处理方法,为HDFS数据副本高效利用奠定了理论基础,并提供了一定的技术支持。结合对两者的分析,提出如下数据存储改进方案:首先,针对商业银行不同的数据被访问频率不同的特性,可以通过定制不同性能的数据存储设备,访问需求不同的数据存放在不同性能的存储设备上,使得经常被访问的数据能够更快地被访问,并保证归档类数据的存储,充分利用存储资源以提升性能;其次,根据商业银行基于预知数据相关性的特点,同时利用具有关联关系的数据经常被同时访问的情况,可以通过调整数据副本的存放位置,使得关联数据同时被访问,从而提高数据本地化率,优化数据读取的性能;最后,利用商业银行大数据被访问的概率特性及大数据产生的时间具有的相关性,通过针对最近的数据存储策略进行优化,提升数据读取的性能。
[1] 信怀义.商业银行大数据的应用现状与发展研究[J].中国金融电脑,2016,27(8):26-28
[2] 顾涛.集群Map Reduce环境中任务和作业调度若干关键问题的研究[D].天津:南开大学,2015
[3] 罗鹏,龚勋.HDFS数据存放策略的研究与进步[J].计算机工程与设计,2014,35(24):1127-1131
[4] 信怀义.基于商业银行大数据访问规律的HDFS副本策略优化研究[J].软件,2015,36(11):74-79
[5] 张艳,蔡光兴.基于ARIMA和GRNN模型对人民币汇率的预测[J].特区经济,2017(2):53-55
[6] 林伟伟.一种改进的Hadoop数据放置策略[J].华南理工大学学报:自然科学版,2012,40(1):152-158
[7] Tom White. Hadoop权威指南[M].第2版.周敏奇,王晓玲译.北京:清华大学出版社,2011:15-73
[8] 王意洁,孙伟东,周松,等.云计算环境下的分布存储关键技术[J].软件学报,2012,23(4):962-986
[9] 王习特,申德荣,于戈,等.Map Reduce集群中最大收益问题的研究[J].计算机学报,2015,38(1):109-121
[10] 宫夏屹,李伯虎,柴旭东,等.大数据平台技术综述[J].系统仿真学报,2014,26(3):489-496
[11] 黄山,王波涛,王国仁,等.Map Reduce优化技术综述[J].计算机科学与探索,2013,7(10):865-885
Big Data Analysis of Commercial Banks Based on Hadoop Distributed File System
ZHANG Deng-yao
116025,
In view of the problems of long data reading time and low localization rate of data in the data analysis by Hadoop distributed file system, this paper proposed a large data analysis method for commercial banks based on Hadoop distributed file system. Firstly, the working principle and process of the Hadoop distributed file system were analyzed and the reasons for the shortage were found. Then, according to the characteristics of the big data of the commercial bank, the number of data copies and the data distribution position of the Hadoop distributed file system were improved. Finally, the data reading speed was passed through the simulation simulation experiment. The localization rate, the disk load and so on were analyzed. The results showed that the method could effectively reduce the time of data reading, improve the localization rate of data and balance the load of the disk. The overall performance was better than the contrast method, and it has a better practical application value.
Hadoop file; commercial bank; big data
TP391
A
1000-2324(2018)05-0884-05
10.3969/j.issn.1000-2324.2018.05.033
2017-08-11
2017-10-09
张登耀(1981-),男,博士研究生,主要研究方向为农村金融、资本市场. E-mail:717960543@qq.com
