一种自然邻近关系查询的空间索引结构
2018-10-21李佳田张文靖张思佳
肖 怡,李佳田,张文靖,刘 鹏,王 瑜,张思佳
(昆明理工大学 国土资源工程学院,云南 昆明 650093)
0 引 言
空间目标与它生成的Voronoi区域距离最近,如果两个空间目标具有共同Voronoi边界,那么这两个空间目标之间存在着自然邻近空间关系[1]。自然邻近在自然地表内插[2-3]、空间邻近查询[4]、制图综合[5-6]以及模式分类[7-8]等领域是一个十分重要的研究内容。然而,现有的空间数据库并不支持自然邻近空间关系查询,制约着空间数据库技术在GIS中的应用。
Voronoi图将空间邻近关系隐含于其中。Long等基于Voronoi的空间关系-V9I的基础上进一步分析了A,B两个空间目标之间的空间关系,其中用3×3布尔矩阵表示了A,B自然邻近的情况[9-10]。Xie等提出了不确定的Voronoi图(或UV图),它将数据空间分为不相交的“UV分区”。每个UV分区P与目标集合S相关联,使得位于P中的任何点q都有集合S作为它的最近邻居[11]。Trefftz 等用空间目标的k阶Voronoi图,进而进行邻近查询[12-13]。但是由于至今全要素的Voronoi图的生成方法并不成熟,研究学者纷纷将目光转向Voronoi的对偶Delaunay三角网,Gold等提出了将三角形中的三边根据邻近关系以及边的逆时针方向来分类进而形成二叉树序列来判断自然邻近空间关系[14-15]。但二叉树不是多路平衡树且更新不便。Jones等使用了规则格网索引对三角形做了预处理,通过三角形的邻近关系来确定影响三角形的集合,这种方法被称为简单格网索引方法(Simple Grid Index,SGI)[16]。但是这种方法会存储大量的三角形,占用较多的磁盘空间并且不支持更新。
本文的主要工作是将离散面目标映射到约束Delaunay三角网中,提出Unions Delaunay结构来描述离散面目标之间的邻近区域,进而构建R-tree Gridfile空间索引结构,R-tree Gridfile建立了空间选择范围和分离的空间目标之间的相互联系以此来克服“交”运算不能运用于自然邻近关系查询这一问题。R-tree Gridfile是通过R-tree与Gridfile相结合的索引结构来实现规则空间剖分,对比实验结果表明该空间索引结构通过叶结点部分重构来代替整体更新的方法能够有效地支持离散面目标集合地邻近查询。
1 Unions Delaunay结构
Unions Delaunay结构是在Delaunay三角剖分的基础上,将空间目标剖分成三角形,然后根据三角形边的来源不同重分类,将表示相同邻近空间关系的三角形合并成一个Union,形成空间目标集合和自然邻近空间关系区域相互结合的一种空间剖分结构-Unions Delaunay。用其最小外接矩形(Minimal Bounding Rectangle,MBR)来近似区域,提高了磁盘的空间利用率,减少了索引时间。
三角网中三角形的分类是基于三角形的三条边来源于几个空间目标,以此来将三角形分为3种不同类型的三角形,Union构造过程如图1所示。

图1 Union构建过程Fig.1 Building process for Union
图1 中的β型三角形指这类三角形中的三条边分别来源于两个不同的空间目标,α型三角形指的是三条边来源于同一个空间目标的三角形,这类三角形中如果其重心在其内部,则为δ型三角形,δ型三角形是α型三角形中的一种。
2 R-tree Gridefile空间索引
空间索引在空间数据库中是一种有效的检索手段,其基本思想是对近似(approximation)的使用,根本目的是减少读盘。R-tree采用了B树分割空间的思想[17-18],在更新索引结构时能够以局部代替整体,仅涉及到子结点的合并与分割。而Gridfile采用多属性索引技术来分割嵌入的n维空间,实现二次磁盘访问[19]。通过运用Unions Delaunay结构与R-tree Gridefile相结合,首先提取空间目标的最小完备邻近目标的候选集合,其次建立空间目标与空间选择的关系,从而使得“交”运算同样能够用于自然邻近空间关系计算中。
2.1 R-tree Gridfile的结构
在Unions Delaunay结构中存储了三角形的空间邻近关系,但是并没有存储三角形,所以该结构并不具有实时更新的特征。故在二维欧式空间中采用层次空间剖分方法,用低层面片的重构来代替整体结构的更新。R-tree Gridfile包括R-tree和Gridfile两个基本结构,R-tree 构成二维欧式空间中有界区域的层次剖分,树的根结点代表S,R-tree 采用了MBR的方法,对叶子结点所指向的目标空间用其MBR框起来,越是接近S,框所代表的空间范围就越大,以此来对空间进行规则剖分。在R树中每个叶子结点代表1个最小剖分单元(Minimum split unit,MSU),存放其MBR并指向一个Gridfile结构,叶子结点的结构组成包括其MSU所代表的空间范围以及对应的Gridfile的指针,表示为(MBRi,Gridfile_ptri)。每个结点代表一个剖分单元,可能包含多个MSU,结点结构由自身代表的多个MSU的“并”集以及其包含的叶子结点的指针构成,表示为(MBRi,<child_ptrim,child_ptrim+1,…,child_ptriM>),其中MBR为树的结点所包含的空间范围。除根结点外,每个结点的项数介于最小项数m和最大项数M之间,且1≤m≤M/2,下限保证对磁盘空间的有效利用,上限保证每个结点对应一个磁盘页。树形结构及其相对应的空间分布图如图2、图3所示。在图3中R9区域中存在数据集,我们用MBR框住该区域,其他区域类似,图中R3、R4、R5与R1之间的距离相比R2较近,这由公式(2)来说明,所以将其放入R1的MBR中。R-tree代表了一种规则的、自下而上的空间剖分结构,是空间分割的典型体现。R-tree用叶子结点来代表一个MSU,并且借助其MBR来代表所指向的Gridfile,使得在数据库中的空间索引查询变成了对空间目标所代表的外接矩形进行分析,空间索引只需要访问少量的结点,即可完成对空间目标的快速定位以及分析工作。R-tree Gridfile空间索引具有实时更新的特征。在格网文件单元中包含了空间目标在格网文件中的空间索引信息,由于将整个离散面进行规则格网剖分,所以在这里的空间索引信息即为空间目标在格网中的属性信息形如(xi,yi,locasi1,locasi2,backet_fid),如图4,图5所示,其中(xi,yi)表示空间目标在格网中的位置,在格网索引中每一个格网都被称为一个桶(backet),将落入该格网内的空间目标放入到该格网对应的桶中,从而在空间索引时只对含有空间目标的桶索引。(locasi1,locasi2,backet_fid)表示格网单元记录的桶的首尾地址以及桶的编号,桶中存储的二元组表示了在Union中有邻近空间关系的目标的标号fid。

图3 R树的空间分布图Fig.3 Spatial distribution map of R-tree

图4 R-tree Gridfile的基本结构Fig.4 The basic structure of R-tree Gridfile
定义1(空间占用):在二维欧式空间中,空间目标a(xj,yj),b(xj,yj)之间的距离常用欧式距离(公式(1))来表示,但是这种方法不能够很好地表示a、b之间的空间关系,本文采用空间占用来表示a、b之间的距离。空间占用即a、b的MBR的外接圆之间的关系,在表示a、b之间的空间关系上具有优越的性能,所以本文计算目标之间的距离采用公式(2)的方法。空间占用的计算决定着在R-tree的子结点项数达到M时,即满足分裂条件后,对空间目标所代表的MBR的处理方法。在二维欧式空间中,两个空间目标a,b之间的空间占用关系见公式(2)。

dis(a,b)的值越小,表示两个空间目标之间的距离越近,反之,则表示距离越远。如果非根结点所包含的项数达到M项,那么该结点即达到了分裂的条件,首先计算这M项中dis(a、b)最大的值,找到(a、b)两个空间目标,生成各自的MBR,然后再判断剩余的M-2项的空间实体Q={q1,q2…,qM-2}与a、b之间的空间占用关系,如果dis(qi,a)≤dis(qi,b),那么将qi的MBR与a所代表的空间的MBR构建一个新的MBR。反之将qi的MBR与b所代表的空间的MBR构建一个新的MBR。公式中a,b表示两个空间中的实体,area代表了求取其MBR外接圆的面积函数。
R-tree Gridfile是通过R树与Gridfile相结合的索引结构来实现规则空间剖分,这种混合空间索引机制能够将大量的索引项有序地组织到索引结构中,对R-tree Gridfile空间索引结构中的叶子结点指向的空间目标采用Gridfile索引方式进行查询。R-tree Gridfile索引文件的物理结构包含4个基本要素如图5所示。
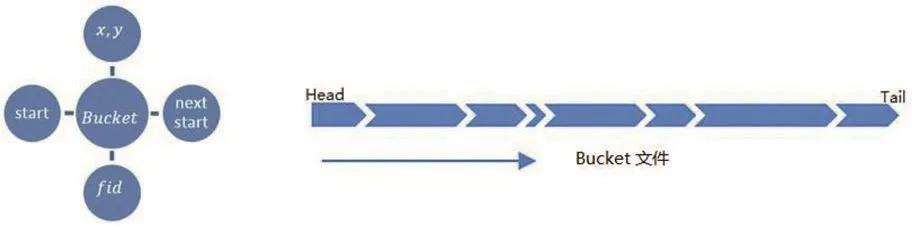
图5 索引文件结构Fig.5 Index fi le structure
图5 中的start代表了该格网文件对应的桶的首地址,next start表示下一个桶的首地址,fid表示桶在格网文件中的索引号,由公式(3)求得,xg,yg表示所求空间目标P所在桶的地理坐标。由公式(4)求得。位置关系如图6所示。

式中,W表示格网的宽度,H表示格网的高度,|result|表示对所得到的结果result取整数,xp,yp代表了空间目标在格网中的坐标,即像素坐标,这里需要将P所在的像素坐标转换成地理坐标,使之携带地理信息,同时使得P在格网中的行列号与具体的地理坐标建立了对应关系,并使得目标索引得以建立。Δx,Δy指明了格网的规则剖分尺度,其值的大小是影响格网空间索引效率的一个重要因素,格网单元太大时会导致每个格网单元中包含较多的空间目标,格网单元太小则会造成多个网格单元会索引到同一个空间目标,都会造成空间索引时间的增加,影响索引效率。因此格网单元大小的选择需要根据地理空间目标的窗口数来多次测试格网单元的划分,以此取得较好的索引效率。

图6 位置关系图Fig.6 Position relationship diagram
2.2 R-tree Gridfile构建算法
下面介绍基于 Unions Delaunay三角网创建 R-tree Gridfile空间索引结构的算法,其构建流程图如图7所示。由程序流程图可以看出在索引结构的构建过程中,输入的是三角形集合Unions Delaunay。输出的则是R-tree Gridfile空间索引结构。在该过程中主要涉及到几个基本部分,格网单元的划分被首先确定,其前提是经过对空间目标窗口数的多次比较得到性能较优的划分,其重要的步骤为扫描Union以及写入索引文件,即图7中的两条分支,在左分支,即扫描Union的过程中获取Unionn以及其MBR在格网中的相关信息,同时创建二元组,形如<fid1,fid2>,表示在Unionn中有邻近空间关系的目标fid;在写入索引文件的过程中,核心过程为得到以及更新格网单元中记录的形如(xi,yi,locasi1,locasi2,backet_fid)的信息。

图7 Gridfile索引结构构建流程图Fig.7 Design fl ow chart for Gridfile index structure
2.3 R-tree Gridfile 查询与更新过程
R-tree Gridfile 自然邻近查询过程中输入的是根结点S以及所要查询的空间目标p所代表的空间范围的MBR,输出则是与p具有自然邻近空间关系的集合U,p与U的关系记为nar(p,u),U={u1,u2,…,un},ui与p可能具有邻近关系。一个空间目标p在R-tree Gridfile空间索引结构中的查询过程可以分为以下几个步骤。
1)查找与p对应的Gridfile,递归R-tree,用p所代表的空间范围的MBR与R-tree Gridfile结点的MBR做比较,如果p.MBR∩node.MBR≠ø,且结点是叶子结点,则表示找到了包含空间目标p的格网单元的地址。
2)找到p所对应的格网单元(i′,j′),得到格网单元的相关记录信息,计算格网文件的偏移值4×sizeof(int)(j(j′-1)+i′),然后读取字节长度4×sizeof(int),其中,j、i为格网的行列数,同时得到格网对应桶的首尾地址,Bucket文件在内存空间中偏移值为locas1,读取字节长度即为(locas2-locas1)。
3)解析桶中被读取的二元组<fid1,fid2>,其中fid值即为候选目标的fid,得到与p可能满足邻近空间关系的完备集合U。即完成空间目标p在R-tree Gridfile空间索引结构中的查询工作。
R-tree Gridfile的更新主要是针对待插入、删除的空间目标,求出这些空间目标自身的MBR与R-tree Gridfile索引结构中格网单元所代表的空间范围之间的空间关系的完备候选集合。然后再根据图7中的算法对R-tree Gridfile空间索引结构部分重构。R-tree Gridfile空间索引结构在执行对空间目标的索引或者对变化的目标进行更新的过程中并没有对索引结构整体的更新,而是以叶结点的部分重构来代替整体的重构,实现了对索引结构的实时更新。
3 实验与分析
本文实验所用处理器为Inter(R)Core(TM)i5-3317U CPU@1.70GHz,所涉及的结构和算法在vs2013以及oracle 11g软件环境下实现,所用来测试的数据均为离散面目标空间数据。格式为Arcgis中shp格式。详细信息见表1。

表1 实验数据详细信息Tab.1 The details of experimental data
3.1 索引结构的物理性质比较
表2比较了R-tree Gridfile空间索引结构与SGI结构在索引构造过程中表现出的特性。

表2 索引结构的性质比较Tab.2 Comparison of properties of index structures
3.2 索引构建耗费时间和空间比较
构建R-tree Gridfile与SGI所消耗的CPU时间、所占磁盘空间大小与三角形数目之间的关系如图8所示。R-tree Gridfile这种空间索引结构的优点在于:①Unions Delaunay将表示相同邻近空间关系的三角形合并成了一个Union,而SGI是以三角形为基本单位建立其自身的MBR在格网单元中进行空间索引,相比之下R-tree Gridfile能够大量减少计算次数,节省了CPU工作时间;②SGI结构在索引构建过程中,需要将全部的三角形都存储下来,需要较多的I/O时间。
而在占用磁盘空间方面,R-tree Gridfile索引结构不需要存储三角形,它仅仅需要记录Union所表示的二元组,即存储空间目标邻近目标的fid而SGI空间索引结构需要存储全部的三角形,耗费磁盘空间远大于R-tree Gridfile的构建过程所消耗的磁盘空间,因此,R-tree Gridfile明显优于SGI。

图8 三角形个数与磁盘空间以及创建索引时间关系柱状图Fig.8 The relationship histogram about number of triangles with the disk space and the creation of the index time
3.3 索引结构更新分析
R-tree Gridfile空间索引结构的创建过程大致包含3个步骤:①Delaunay三角网的生成;②生成Unions Delaunay结构;③Gridfile结构的创建。图9表示了在不同结点数的情况下这3部分的生成所对应的CPU耗费时间的相关情况以及生成R-tree Gridfile空间索引结构总共耗费时间。

图9 结点数与索引构建时间关系Fig.9 The relationship between the number of nodes and index construction time
图9 中的relation表明了创建R-tree Gridfile空间索引结构CPU耗费的时间和目标边界结点的数量是大致呈线性递增的关系,且可以看出③在这3个步骤中耗时最少,变化率较小,故其时间效率主要体现在步骤①、②中。今后如果要对该索引结构进一步优化,则着重考虑步骤①、②的优化。
3.4 索引的性能分析
随机选择R-tree的1叶子结点相对应的Gridfile(1550个结点,95个面目标),在固定格网大小(50×50)的情况下查询9个随机点以及相关的数据见表3。

表3 R-tree Gridfile空间索引结构性能分析Tab.3 Performance analysis of spatial index structure for R-tree Gridfile
表3中,(行,列)表示查询目标在格网空间中的行列号;所求目标数表示对空间目标查询得到的邻近空间目标的数量;CPU时间表示1次查询所需要的时间;读取的字节数表示1次查询从磁盘空间中读取的字节多少。由表3统计可知,平均一次查询时间24.56 ms,每次选出3.56个邻近空间目标;需要读取34.56字节大小的数据。从数据分析来看,R-tree Gridfile 空间索引结构在数据库中进行自然邻近空间关系查询表现出了较优的性能。部分实验结果如图10所示。

图10 部分实验结果Fig.10 Some experimental results
4 结束语
在空间数据库中直接使用现有索引来扩展自然邻近查询并不能保证结果的完备性,因此有必要将Voronoi/Delaunay结构考虑加入到索引结构的构建中。本文采用约束Delaunay三角网, 建立面目标自然邻近关系表达结构-Unions Delaunay,进而提出了一种空间索引结构-R-tree Gridfile来实现自然邻居候选集提取。该索引结构能够降低对磁盘空间占用,减少索引时的计算量以及实现了对叶结点的更新来代替整个索引结构的更新,实验表明了其可行性。今后将对R树固有的区域重叠和覆盖的缺点以及Delaunay三角网和Unions Delaunay结构的生成算法做出进一步优化,以提高索引效率。
