基于多源数据融合模型的水稻面积提取
2018-10-20魏永霞杨军明SHEHAKK侯景翔
魏永霞 杨军明 吴 昱 王 斌 SHEHAKK M 侯景翔
(1.东北农业大学水利与土木工程学院, 哈尔滨 150030; 2.农业部农业水资源高效利用重点实验室, 哈尔滨 150030; 3.东北林业大学林学院, 哈尔滨 150040; 4.黑龙江农垦勘测设计研究院, 哈尔滨 150090)
0 引言
作物的空间分布信息是农业估产等作物研究的前提和基础,是粮食问题和水资源分析管理等的重要依据[1]。与欧美等国家相比,我国的作物种植结构复杂,地块小且分散[2],这使得遥感影像的空间分辨率制约着作物空间分布信息提取结果的精度[3],且灌区等中小尺度的农业研究需要高空间分辨率的作物空间分布信息来研究农田系统的复杂变化。
Landsat和MODIS是水稻空间分布信息提取中最常用的遥感卫星[4-5],Landsat虽然空间分辨率较高,但是时间分辨率低,容易受云和阴雨等天气的影响,造成作物关键生长发育期无卫星覆盖,以和平灌区2015—2017年为例,作物生长期(5—9月)可获取的Landsat数据有9~10幅,但是实际可用的只有2~3幅,且可利用影像时间分布随机,仅仅依靠可用的Landsat数据进行作物提取将会严重受到数据源的制约。MODIS时间分辨率较高,但是其低空间分辨率的特征使得混合像元的数目增加,而纯净像元指数和景观异质性是影响分类精度的主要因素[6],这必然造成分类精度下降。IKONOS、QuickBird等商业遥感卫星虽然时间分辨率和空间分辨率均较高,但是应用成本较高,不适合长期的作物检测。基于线性混合模型的数据融合模型[7-8]和时空自适应反射率融合模型[9]及其改进模型[10-11]等多源数据融合模型的出现为高空间分辨率的作物空间分布提取提供了研究思路和方法。为此,很多研究者[12-14]基于多源遥感数据融合模型的成果对提取作物种植面积进行了研究,以期能够通过数据融合的手段获得高精度的高空间分辨率作物空间分布信息。但这类模型是为波段数据融合而开发的,基于线性混合模型以初始或者始末两期影像为基期影像来提取丰度矩阵,当中间时刻的植被指数(Vegetation index, VI)随时间变化较剧烈时,存在融合精度较差的问题;时空自适应反射率融合模型及其改进模型以始末两期影像在一定窗口内的高分辨率相似像元与低分辨率像元的变化为线性的假设为理论基础,当中间时刻的像元VI变化与初始时刻的相似性较低时,也存在融合精度较低的风险。
随着遥感分类技术的发展,作物面积提取的方法不断进步。通过关键时相的VI和作物时序VI曲线提取作物面积是目前两种主要的作物提取方法。与作物时序VI曲线提取作物种植面积不同的是,关键时相的VI提取作物种植面积需要充分了解研究区域的作物物候信息和种植结构等,从中找出具有明显差别的时相来提取作物种植面积,如GUSSO等[15]在对巴西南里奥格兰德州的多年光谱信息统计分析的基础上,建立了该地区大豆提取模型。张荣群等[16]在研究曲周县主要作物的生长发育期归一化植被指数(Normalized differential vegetation index, NDVI)的基础上,提出了该区域的作物提取模型。与其他地区相比,我国东北地区的作物种植结构简单,主要的作物水稻、玉米和大豆均为一年一熟,且主要的生长发育期分布在5—10月。这使得作物在生长期内具有更高的光谱相似性,也一定程度增加了关键生育期作物提取的难度。作物VI曲线法通过分析作物时序VI曲线与目标像元的VI曲线的相似性来提取作物,不需要清楚地了解研究区域的物候信息和种植结构及能够反映作物的动态变化信息等特点而在作物提取中具有独特的优势,在各种尺度的作物空间分布提取中得到了广泛的应用[17-19]。
考虑到现存的数据融合模型在融合VI数据时存在精度可能较低的风险,为解决遥感影像数据源时空分辨率不可调和的矛盾对作物提取的限制,本文根据地物的VI变化特征提出一种多源VI数据融合模型,以常用的Landsat 和MODIS数据为数据源,提出一种适用于中高分辨率影像数据缺失区域的水稻等作物空间分布提取方法。
1 材料与方法
1.1 研究区概况
选择北纬46°51′7.83″~47°4′8.33″、东经127°18′40.28″~127°45′12.22″的区域为研究对象,对多源遥感数据融合提取作物空间分布进行测试。研究区属于黑龙江省绥化市,位于呼兰河左岸的干支流河漫滩及一级阶地上,地势平坦,属寒温带大陆性季风气候,多年平均降雨量为550 mm,平均气温2.5℃。研究区以水稻为主要作物,除此之外,有部分的大豆和玉米等作物种植,还包含草地、林地、水体、道路和建筑物等地物。地表结构复杂,如果以MODIS数据为数据源,存在大量的混合像元。经调查,研究区单块稻田的面积介于0.10~0.17 hm2之间, 研究区所在的庆安县水稻种植面积大概占总农田面积的52.7%。
1.2 数据与预处理
选择Landsat8 OLI 数据和MODIS的二级产品MOD09GA和三级VI产品MOD13Q1进行水稻面积提取,Landsat数据和MODIS数据均来自USGS官网 (https:∥earthexplorer.usgs.gov/)。如表1所示,选择2017年作物生长期内(4—10月)可利用的Landsat遥感影像数据为数据源,其伽利略日为229、245、277,将生育期外的伽利略日为101的数据作为初始影像数据;选择对应时期或者对应时期附近日期(VI在几日内不会发生太大变化)可利用的MOD09GA数据为数据源,其伽利略日如表1所示;选择作物生长期内(4—10月)MOD13Q1为数据源。

表1 遥感数据源选择Tab.1 Selection of remote sensing image
Landsat8 OLI已经过几何校正,应用ENVI5.3对其进行辐射定标和大气校正。MOD09GA和MOD13Q1数据采用的是正弦坐标系统,为和Landsat8 OLI保持一致,应用MODIS批处理工具(MODIS reprojection tool, MRT)将其投影系统转换为UTM-WGS84 52N,重采样为240 m×240 m。根据地面样点对Google Earth 影像进行校正,采用ENVI5.3提供的坐标转换工具将其坐标转换为与Landsat8 OLI一致的UTM-WGS84 52N 坐标系统。并选择水体、道路拐角等处对Google Earth和Landsat影像位置的一致性进行检验,经检验位置一致性较好。
土地利用图的精度对作物提取的精度和数据融合的精度具有重要影响,为提高作物提取和数据融合的精度,本文不采用下载的土地利用数据集,而是选择2015年9月13日的Landsat8 OLI影像数据,采用支持向量机(Support vector machine, SVM)的方法将该区域的土地利用类型分成水体、草地、林地、农田和不透水层5类,其结果如图1所示。
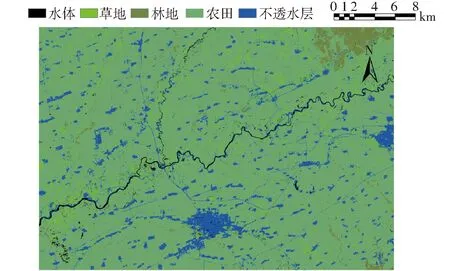
图1 研究区土地利用状况Fig.1 Land cover map of study area
1.3 研究方法
应用数据融合模型和光谱耦合技术结合的方法来提取灌区的水稻种植面积,具体流程如图2所示。首先应用土地利用类型图和模糊C聚类算法(Fuzzy C-means algorithm, FCM)对多期可利用Landsat数据计算得到的增强植被指数(Enhanced vegetation index, EVI)数据进行分层聚类,定义为各个土地覆盖类型的子类。然后根据Landsat计算得到的子类平均EVI与分解MOD09GA的混合像元得到的地表覆盖类的平均EVI的转换系数以及转换系数的线性变化规律。应用MOD13Q1数据的EVI产品融合生成高时空分辨率的时序EVI数据。应用FCM将融合生成的时序EVI数据分成若干类,然后根据标准水稻时序EVI曲线和各类EVI的平均值的相似性来提取水稻空间分布。其主要包括3个步骤:①数据融合。②构建水稻标准时序EVI曲线。③光谱耦合技术提取水稻种植面积。
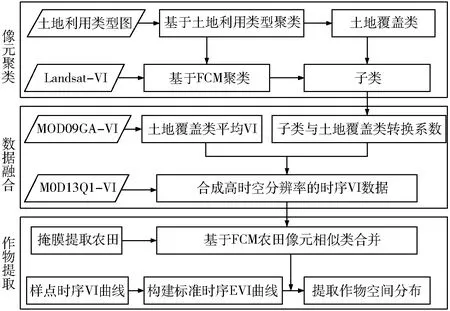
图2 方法流程图Fig.2 Flow chart of algorithm
1.3.1数据融合
研究区主要作物水稻、玉米和大豆均为一年一熟。其主要生长期为5—9月,该时期内的Landsat遥感影像有9~10幅,但是受云和阴雨天气等因素的影响,作物生长期内可用的影像资源极少,对于本文的研究区域,2015年可用的Landsat影像数据只有3幅,部分可用的有2幅(部分可用是指影像中有部分区域存在云遮盖等现象);2016年可用的Landsat影像数据只有2幅,部分可用的有2幅;2017年可用的Landsat影像数据只有3幅,部分可用的有2幅。且可利用影像的时间分布基本无序,因此仅仅依靠可利用的遥感影像数据进行作物的提取将会受到数据源的严重限制,作物提取的关键时相无卫星覆盖的现象普遍存在。
按照线性混合模型的假设,低分辨率影像像元(混合像元)是高分辨率端元的线性组合[20]。基于该假设可认为低分辨影像像元的VI是其所包含的高分辨率影像类别VI的线性组合。土地覆盖类型可用于提取丰度矩阵[21],因此,可以将低分辨率影像与高分辨率影像类别的关系表示为
(1)
式中IC(k,ti,B)——低分辨率的混合像元k在ti时刻的平均VI
A(k,C)——像元k的丰度矩阵
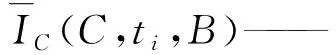
ε(k,ti)——混合像元k在ti时刻计算的残差
m——类别数
但是各种土地覆盖类型包含不同的地物,各个地物VI各异,且随时间变化存在不同的变化规律。为使得丰度矩阵中的同类像元具有相似的反射率和反射率变化,用可对多维数组进行聚类的FCM将各土地覆盖类型聚成若干类,定义为各个土地覆盖类型的子类,使得子类内部的像元具有相似的反射率和反射率变化。并假设子类内部像元的反射率变化等于子类平均反射率变化,从该假设中可以得到
(2)
式中If(k,tp)——tp时刻子类S中的像元k的VI
If(k,t0)——t0时刻子类S中的像元k的VI
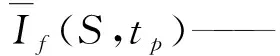

鉴于直接对子类的丰度矩阵进行混合像元分解可能造成较大误差。为此,假设土地覆盖类型与其子类的比值Vti在一段时间内呈线性变化。从作物时序VI曲线可以看出,作物时序VI曲线在一段时间内的变化基本为线性。因此,可以假设作物时序植被指数曲线在一段时间内呈线性变化。
(3)
Vti=a(ti-tj)+Vtj
(4)
式中Vti——ti时刻子类S平均VI与其所属的地表覆盖类的平均VI比值
Vtj——tj时刻子类与其所属的地表覆盖类的平均VI比值
a——常数,是比值Vti随时间的变化率
应用线最小二乘法可以从式(1)中计算出低分辨率影像的子类在各个时刻的平均VI(IC(k,t0,B),IC(k,t1,B),…,IC(k,ti,B))。应用线性回归模型可以从式(4)中求解出参数a。
结合式(2)和式(3)可知,ti时刻像元k的VI可以表示为
(5)
1.3.2构建水稻标准时序EVI曲线
VI是对植被生长发育状况简单、有效的度量参数[22],被作为特征参数应用于作物面积提取。NDVI是作物面积提取中最常用的VI[14]。考虑到大气和土壤等对NDVI的影响,很多研究者对NDVI进行了改进,提出了新的VI。如LIU等[23]考虑到大气和土壤的相互作用,引入了EVI,其因引入了蓝光波段,能够消除背景噪声和大气干扰而具有一定的优势[22,24],在水稻面积提取中得到了应用[25-27]。本文选择EVI进行水稻面积提取。
为准确地提取水稻的时序VI曲线,从灌区选取17个地面水稻样点,保证样点100~200 m范围内均为水稻,应用融合生成的多时相VI数据提取各个样点的EVI曲线。应用所有样点EVI的平均值来构造标准时序EVI曲线,其结果如图3所示。
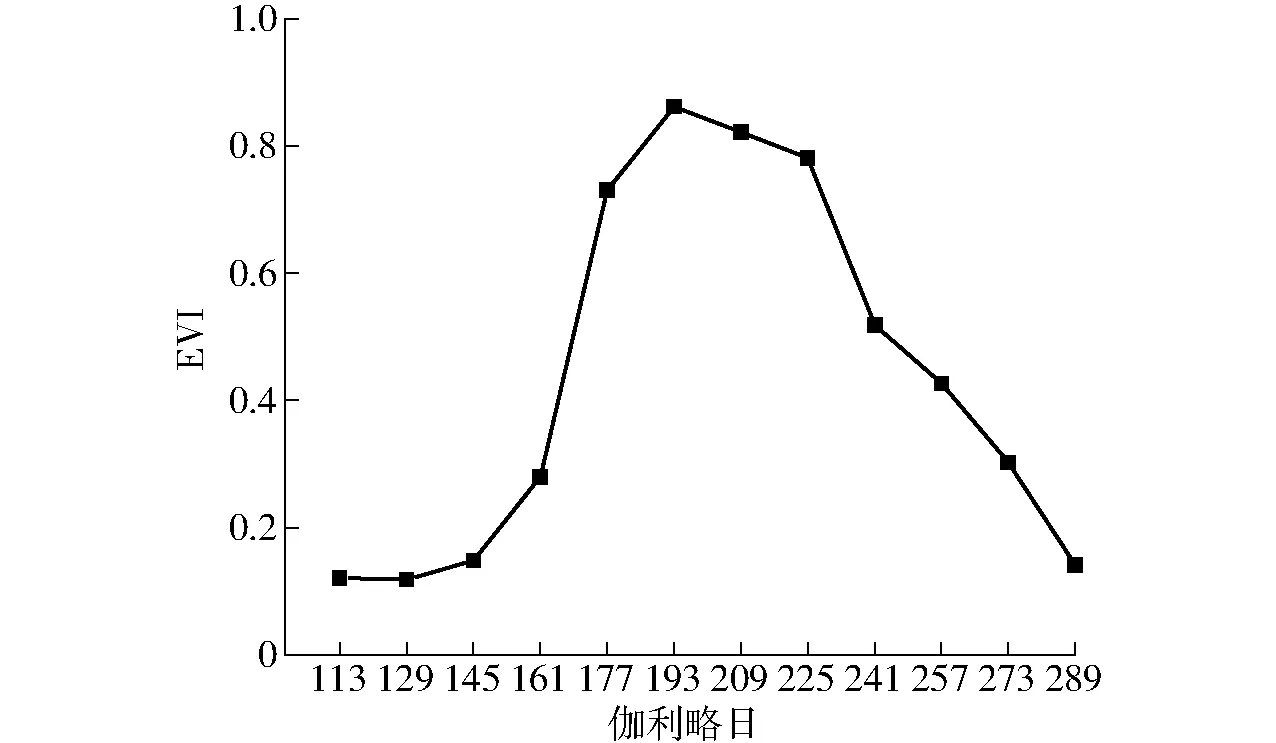
图3 水稻标准时序EVI曲线Fig.3 Standard series EVI curve of rice
1.3.3光谱耦合技术提取水稻
受物力人力等因素的限制,大范围的地面样点调查一般很难实现。为有效识别地物,采用FCM将多时相EVI宏影像聚成若干类。该算法采用模糊数学的思想,在确定聚类中心数后,根据隶属度来判断一组多维数对另一组多维数的隶属程度,使得相同类的相似性最大,不同类之间的相似度最小。其可使聚为一类像元的EVI的相似性最大,不同类之间的相似性最小。
光谱耦合技术(Spectral matching technique, SMT)是指通过分析多光谱曲线与已知曲线的相似程度来对目标对象进行分类的技术[14, 28]。可以应用该方法通过判断目标类别的时序EVI曲线与地面样点构建的标准时序EVI曲线的相似性来对目标类别进行分类。光谱耦合技术中应用光谱相似度(Spectral correlation similarity, SCS)来表示多光谱曲线之间的相似程度,本文中用其来表示目标类别与标准水稻时序EVI曲线之间的相似程度。相关计算式为
(6)
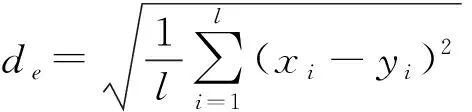
(7)
式中SSV——光谱相似度,用来度量两条光谱曲线之间的相似程度
de——欧几里德距离,值越大,表示曲线之间的相似度越小
l——时序曲线的时间序列步长
xi——i时刻的目标类别EVI
yi——i时刻的标准曲线EVI
2 结果与分析
2.1 提取结果
在融合生成高时空分辨率的EVI数据后,用掩膜提取研究区域中的农田,采用FCM将土地利用类型中的农田分为20类,计算20个类在各个时相的平均EVI,根据EVI的平均值构建20个类别的时序EVI变化曲线。构建20个类的平均EVI曲线和标准时序EVI曲线的相似性矩阵。根据相似矩阵对类别进行合并识别来提取水稻种植面积,提取结果如图4所示。
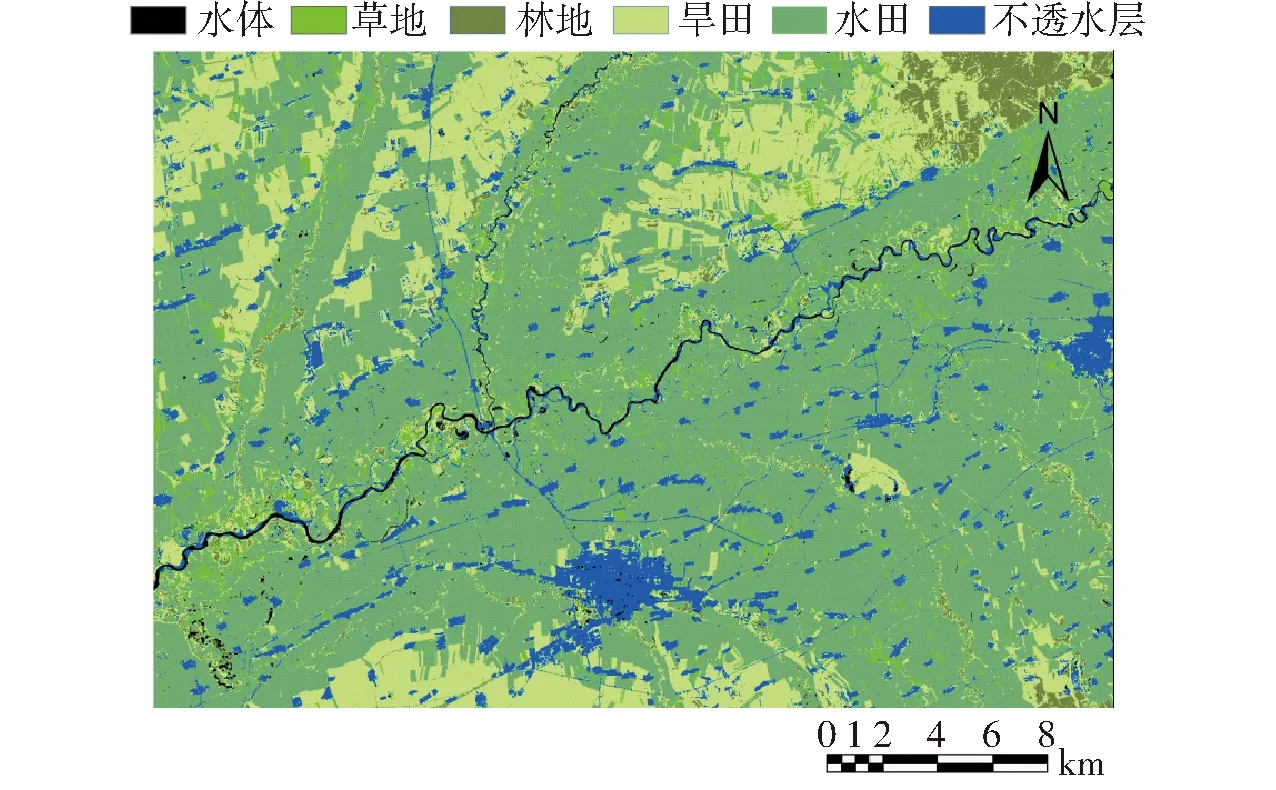
图4 研究区作物提取结果Fig.4 Crop extraction result of study area
研究区2017年土地利用状况如表2所示,研究区中水稻种植面积最大,占总面积的63.24%,占农田面积的75.85%。其次为旱田,种植作物为玉米和大豆,占总面积的20.14%,占农田面积的24.15%。草地、林地、水体和不透水层的面积相对较小,占总面积的16.62%。
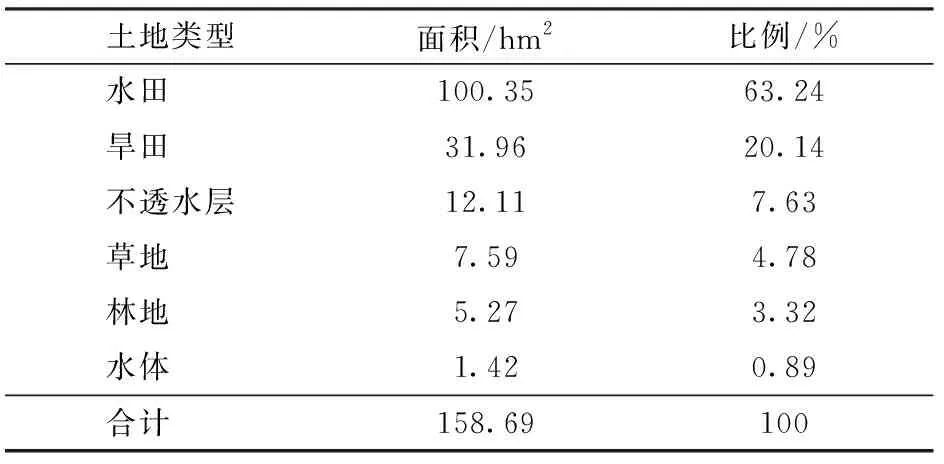
表2 研究区2017年各土地利用比例及面积Tab.2 Land use area and proportion of study area in 2017
2.2 提取精度
为有效地对提取结果进行验证,采用地面样点和Google Earth影像两种方法对提取结果进行验证。85个地面样点的分类结果如表3所示,从结果可以看出,除草地的分类精度较低之外,其他地物的分类结果精度都相对较高。水稻的提取精度为0.92,宏影像的分类精度为0.91,精度相对较高。
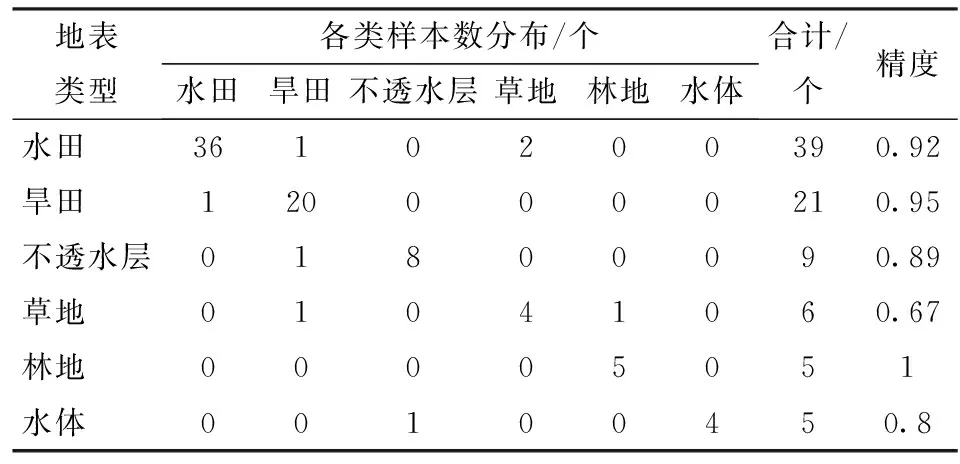
表3 基于地面样点的分类结果精度评估Tab.3 Accuracy assessment of classification result using ground sample
Google Earth 包含着丰富的高空间分辨率卫星影像数据,其分辨率可以达到亚米级,而且包括较新的影像数据。从Google Earth 影像中不仅可以清楚地区分出农田、城镇、林地等,而且还可以区分出稻田和旱田,但是很难从Google Earth影像中区分出旱田作物为玉米还是大豆。由于亚米级分辨率影像的缺失使得结果的验证较难,为此,本文随机从Google Earth 影像中选择150个样点为标准点对提取的结果精度进行验证。其结果如表4所示。
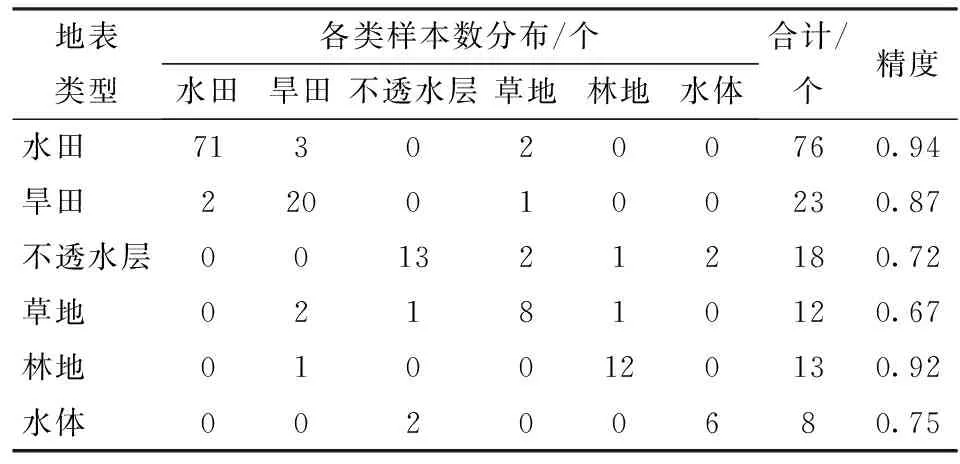
表4 基于Google Earth影像分类结果精度评估Tab.4 Accuracy assessment of classification result using Google Earth image
从表4可以看出,宏影像的分类精度为0.87,水稻面积提取精度较高,达到了0.94。草地和水体的分类精度相对较低。草地的分类精度只有0.67。从图4可以看出,灌区的水体主要以河流的形式存在,其在Landsat影像中的宽度只有1~3个像元。这使得其分类容易受到影像几何校正等的影响,从而将水体分到距离其较近的水田和不透水层等地物中。草地在灌区中分布分散且占的面积比较少,这使得其大多数与其他地物混合存在,从而使其容易被分为其他类。
2.3 分辨率对提取的影响
Landsat像元大小为30 m×30 m,约0.09 hm2,基本小于单块稻田的面积,故忽略识别误差的情况下,除边界的稻田外,大多数稻田基本能被识别出来。MODIS像元远大于单块稻田的面积,混合像元中的地物大于一定比例才能够被识别出来。假如图5所示为1个包含7×7个高分辨率像元的混合像元,虽然其包含的高分辨像元包括水田、旱田、不透水层和水体等地物,但因水田占较大的比例,混合像元识别结果为水田,识别的水田面积会过大。
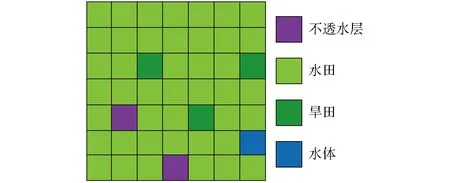
图5 混合像元示意图Fig.5 Mixed pixel schematic
研究区水田面积占总农田面积的63.24%,假如本文中的模型提取的结果为真值,用包含16×16个Landsat像元的网格(一个MODIS像元大概包含16×16个Landsat像元)去划分本文中的模型提取结果(图4),统计每个网格中农田面积的百分比,其结果如表5所示,从结果可以看出,MODIS像元混合现象明显。假如水田低于20%的会被识别为其他地物,则4.22%的像元被识别为其他地物,但其包含10%~20%的水田。假如水田面积大于80%的地物会被识别为水田,则14.44%的地物被识别为水田,但其包含10%~20%的其他地物。若采用低分辨率像元,这些误差是不可避免的,从中可以看出高分辨率像元对提高提取精度具有重要意义。

表5 网格中水田面积百分比区间所占的比例Tab.5 Proportion of percentage interval of rice pixel in grid %
3 结论
(1)应用地面样点对提取结果的评估表明,水稻提取精度为0.92,宏影像分类精度为0.91;应用Google Earth影像对提取结果的评估表明,水稻提取精度为0.94,宏影像分类精度为0.87;水体和草地等地物因分布分散而使得提取精度较差,这说明地物的分类结果受地物离散程度的影响。
(2)低分辨率像元可能包含几种不同类型的高分辨率像元,采用低分辨率影像进行作物提取时存在被识别其他地物的像元包含一部分高分辨率水稻像元和被识别为水稻的地物包含一部分其他地物的可能性,对于地表结构复杂的地区,这种现象可能造成较大误差,故采用高分辨率像元来提取作物对提高精度具有重要意义。
(3)通过关键时相的VI(如根据稻田移栽期积水的特性来提取水稻种植面积)提取作物空间分布是一种主要的作物提取方法。如果能够通过多源数据波段融合或者VI数据融合获得较高精度的融合数据,也可以融合生成高时空分辨率用于关键时相提取作物空间分布,这将会对高精度的作物提取产生重要的意义。
