一种基于向量模型的藏文字拼写检查方法
2018-10-19才智杰孙茂松才让卓玛
才智杰,孙茂松,才让卓玛
(1. 青海师范大学 计算机学院 藏文信息处理教育部重点实验室,青海 西宁 810008) (2. 清华大学 计算机科学与技术系 清华信息科学与技术国家实验室,北京 100084)
0 引言
拼写检查是自然语言处理领域一项具有广阔应用前景和极具挑战性的研究课题,在语料库建设、文本编辑、语音和文字识别等诸多方面具有广阔的应用前景。近年来藏语自然语言处理技术得到了快速发展,随着统计技术和深度学习技术的引入,藏语自然语言处理也跨入了大数据时代,信息的准确度尤为重要,为此学者们围绕藏文拼写检查问题展开了一系列研究。
由于藏文是一种由字母拼接成字、字组成词、词搭配句、句表达意的文字,因此藏文拼写检查包括字级、词级和语法级。字级检查非真字性错误,判断藏文字是否符合文法中的构字原则,单独考虑字本身,与上下文无关;词级和语法级是真字拼写检查,判断符合构字原则的字在该语境中是否正确。英文和汉文只有词级和语法级拼写检查,不存在非真字性问题。藏文文本中非真字性错误出现的频率很高,是藏文拼写检查的重点,目前藏文拼写检查技术主要集中在非真字拼写检查研究[1]。本文通过分析藏文字的构成原则,提出了一种基于规则的藏文非真字拼写检查方法。本文结构如下: 第一部分分析了拼写检查的研究现状;第二部分在介绍藏文字向量模型的基础上,建立了基于规则约束的藏文字向量模型;第三部分介绍了藏文字拼写检查模型及算法,并实验验证了算法的有效性;第四部分是结论与展望。
1 研究现状
1960年,IBM Thomas J Watson研究中心在IBM/360和IBM/370上用UNIX实现了一个TYPO英文拼写检查器[2],1971年,斯坦福大学的Ralph Gorin在DEC-10机上实现了一个英文拼写检查系统Spell[3],到1991年,已有15种西文自动拼写检查的商品化系统问世,广泛应用于写作、教育、出版等行业。英文拼写检查包括词级和语法级拼写检查,采用基于词典、基于规则、基于统计和自动学习语言知识的方法[3-4],第三、第四种方法不但需要大量的训练语料,还需要在不断的人工交互下学习模型,而训练语料和人工交互学习都比较困难,因此主要采用基于词典和基于规则的拼写检查技术。1980年起开始了汉文词自动拼写检查技术的研究,发展速度很快,并取得了较好的成果,且有部分成果已经商品化[5-10]。汉字是方块象形字,不存在字级拼写检查,只有词级和语法级拼写检查,拼写检查技术基本与英语类同。
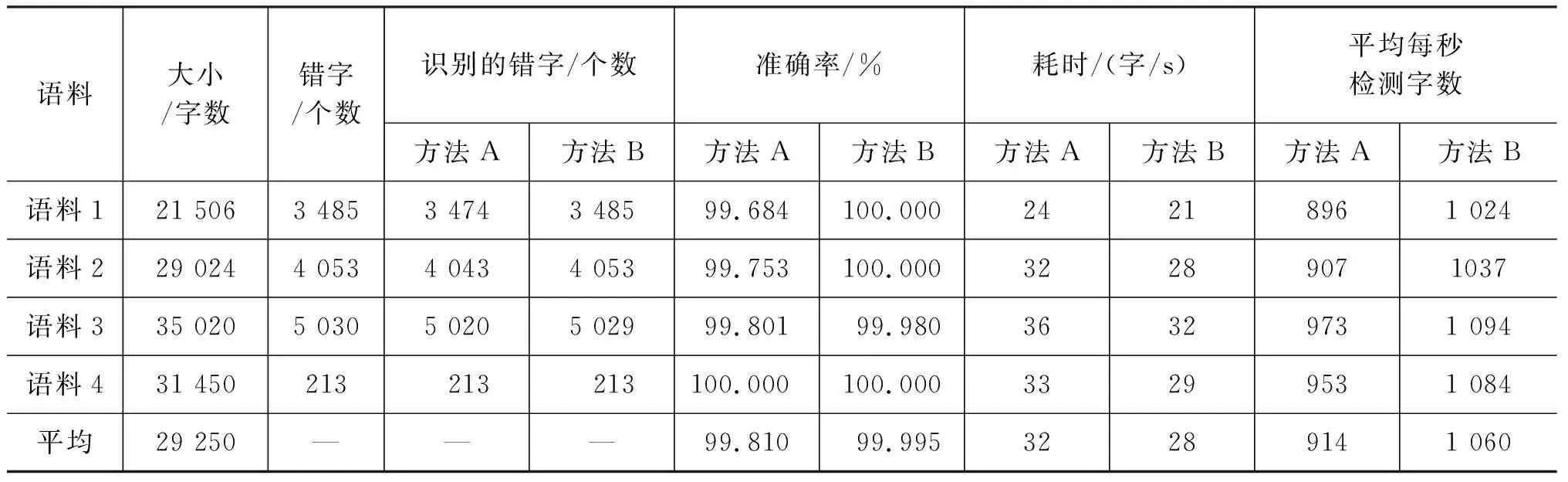
从20世纪90年代起,学者们开始了藏文拼写检查技术的研究,目前主要针对非真字拼写检查技术展开研究。藏文非真字拼写检查主要采用两种技术,一是收集所有可能出现的藏文字以建立字典,采用字典配匹法;二是根据藏文字的特点构建规则,根据规则完成拼写检查。文献[11]分析了藏文字的结构和构件的搭配规则,列举了藏文字的错误类型,没有具体研究拼写检查方法;文献[12]通过建立字表和词表进行查错,作者称对封闭语料的查错准确度较高,但对开放语料的查错率不大乐观,没有给出具体的测试数据;文献[13]通过建立字丁(构件)的三元模型进行查错,模型规模庞大,数据稀疏严重,丢失了藏文纵向拼写的特征,没有给出具体的测试数据,作者称测试效果不是很好;文献[14]将七个构件的藏文字拆分成前缀、元音或音节点和后缀等三部分,建立每部分的对应的表,每部分通过查表进行拼写检查,在没有考虑梵音转写藏文的情况下,拼写错误检查的准确率为99.8%;文献[15]在研究藏文字、词和接续关系拼写检查的基础上,设计了藏文拼写检查系统框架,其中的字拼写检查技术采用了文献[14]的方法,其准确率为53.825%~67.408%;文献[16]对藏文字的字母组合分段处理,分成了前段和后段两部分(把元音归入了前段),建立前段库Pretibet和后段库Backtibet,对每段通过查表的方式完成拼写检查,实验对含84个藏文字的一段文本进行了实验考察。以上文献都采用了字典配匹法,这种方法适合于封闭语料,但对开放语料效果不佳。文献[14]的实验分析中也提到,由于31个前缀部分未收录在字典中而出现了拼写检查错误,说明了采用字典配匹法的不足。藏文文法中字的构成原则非常完善,如果把藏文构字原则用计算机能识别的方法表示,以此完成拼写检查,其拼写检查效果将有很大提高。因此,本文通过分析藏文文法中字构成原则,利用藏文字向量模型将藏文字用计算机易于操作的向量表示,建立了基于规则约束的藏文字向量模型,进而设计该模型下的藏文字拼写检查模型及算法。算法简单易实现,经测试算法对非真字拼写检查的平均准确率达99.995%,平均每秒检查1 060个字。
2 基于规则约束的藏文字向量模型
2.1 藏文字向量模型
藏文字自公元七世纪松赞干布时期创制并大力推广和应用以来,进行了三次较大规模的厘定,制定了详实的现代藏文文法,使藏语言文字步入了规范化的轨道。第三次厘定后的藏文字和文法称为现代藏文字(本文所提藏文字都指现代藏文字)及现代藏文文法[17],在现代藏文文法中对藏文构字及构件拼接规则有严格的规定。藏文字由30个辅音字母和4个元音字母组成,30个辅音字母可以做基字,其中的10个可以做后加字,后加字中的5个又可以做前加字,两个可以做再后加字。藏文字结构上由基字、前加字、上加字、下加字、后加字、再后加字及元音组成,一个藏文字有且仅有一个基字,其他部分可能存在,也可能空缺。前加字、基字、后加字与再后加字按一定的约束规则横向拼写,上加字、基字、下加字和元音在基字所在的竖直方向上按约束规则纵向拼写。组成字的各个字母称作基本构件,简称构件[18],基字竖直方向上同时含上加字、基字和下加字的构件称为叠字。

定义1藏文字可用向量集
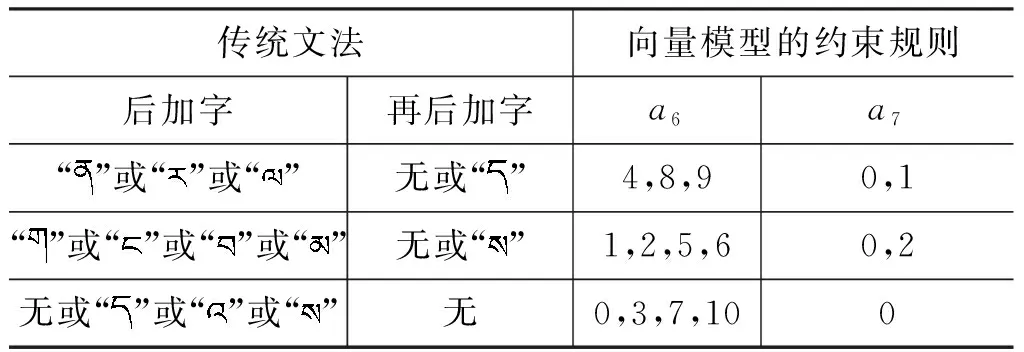
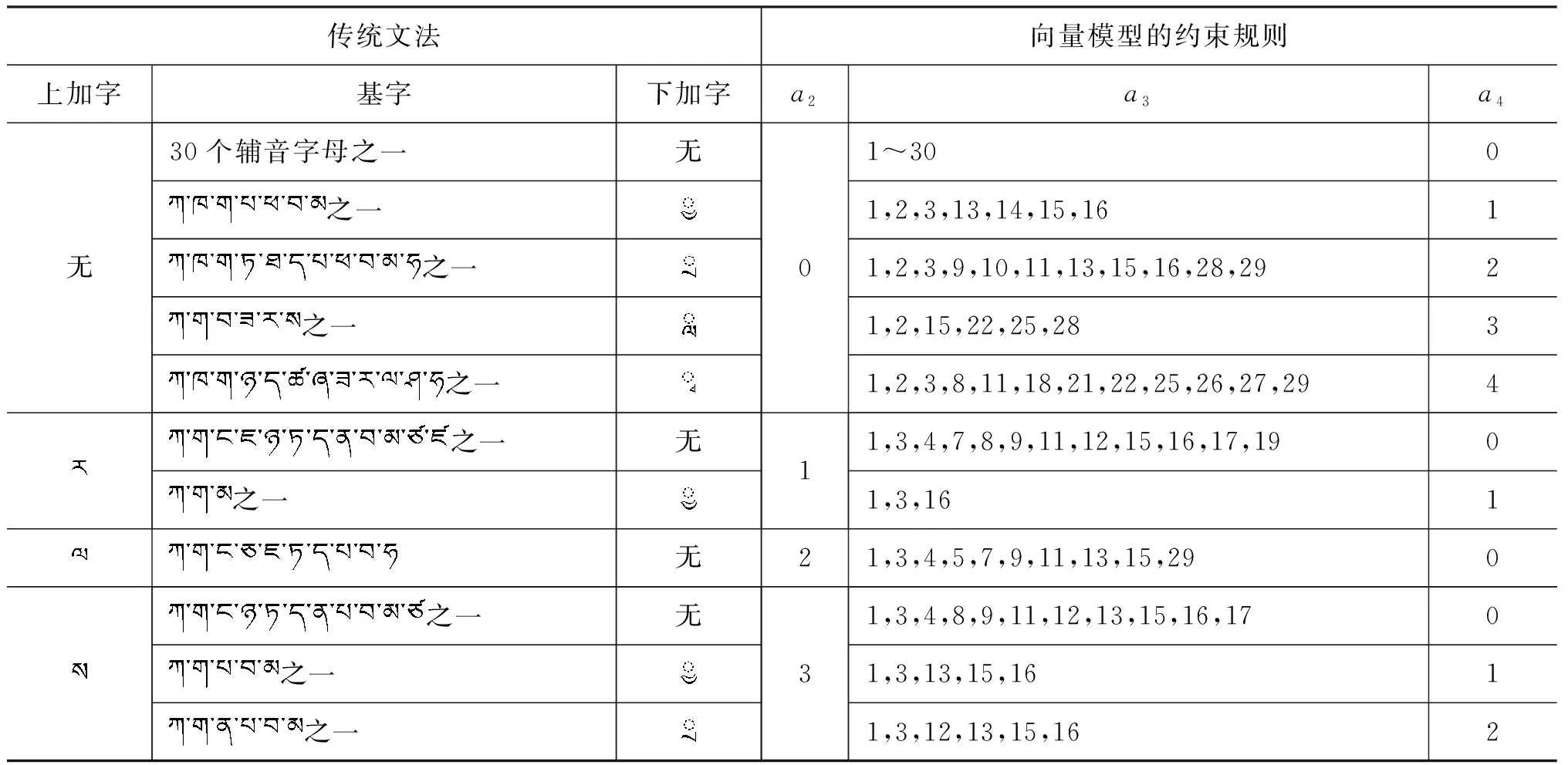
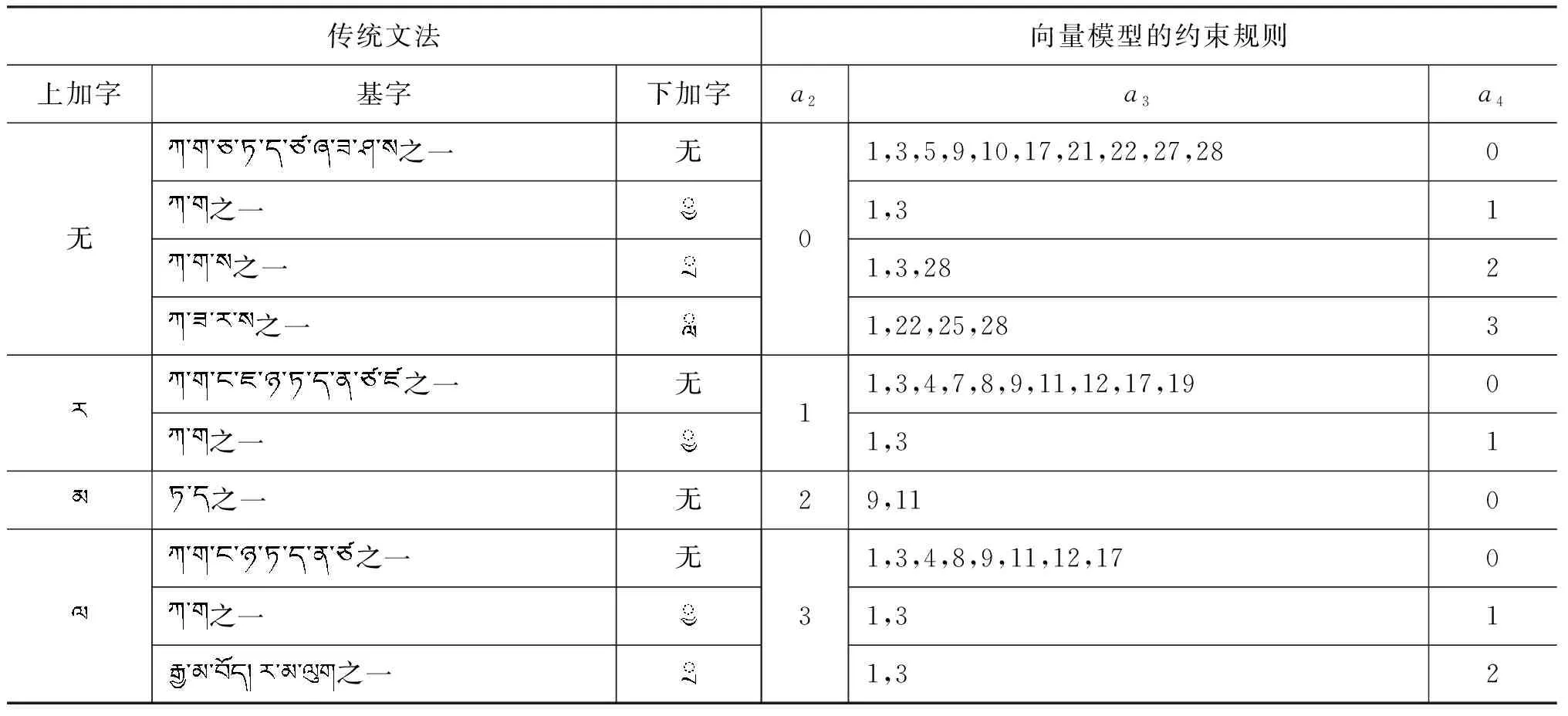
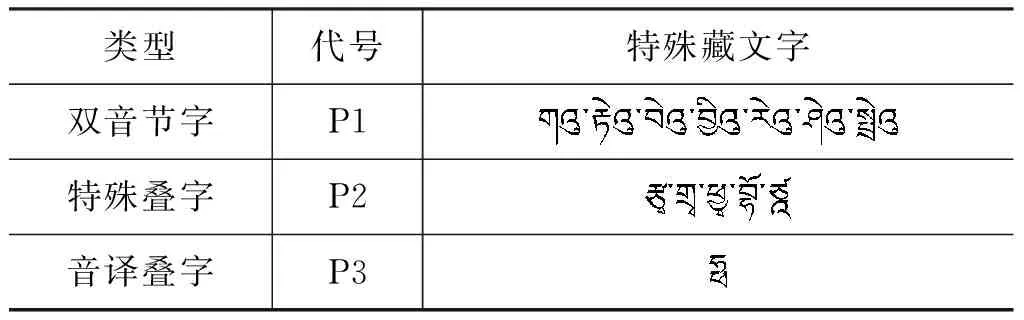
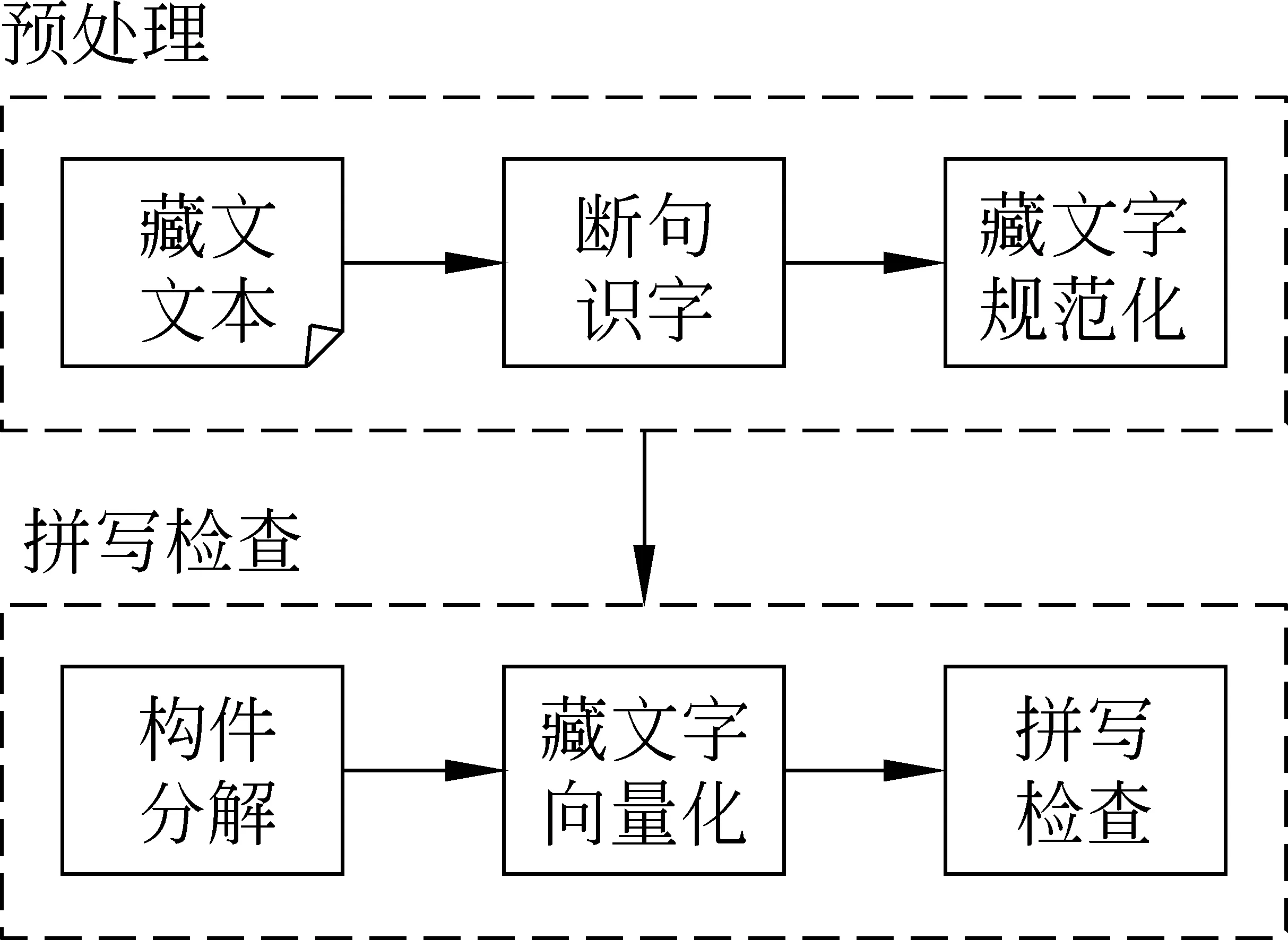
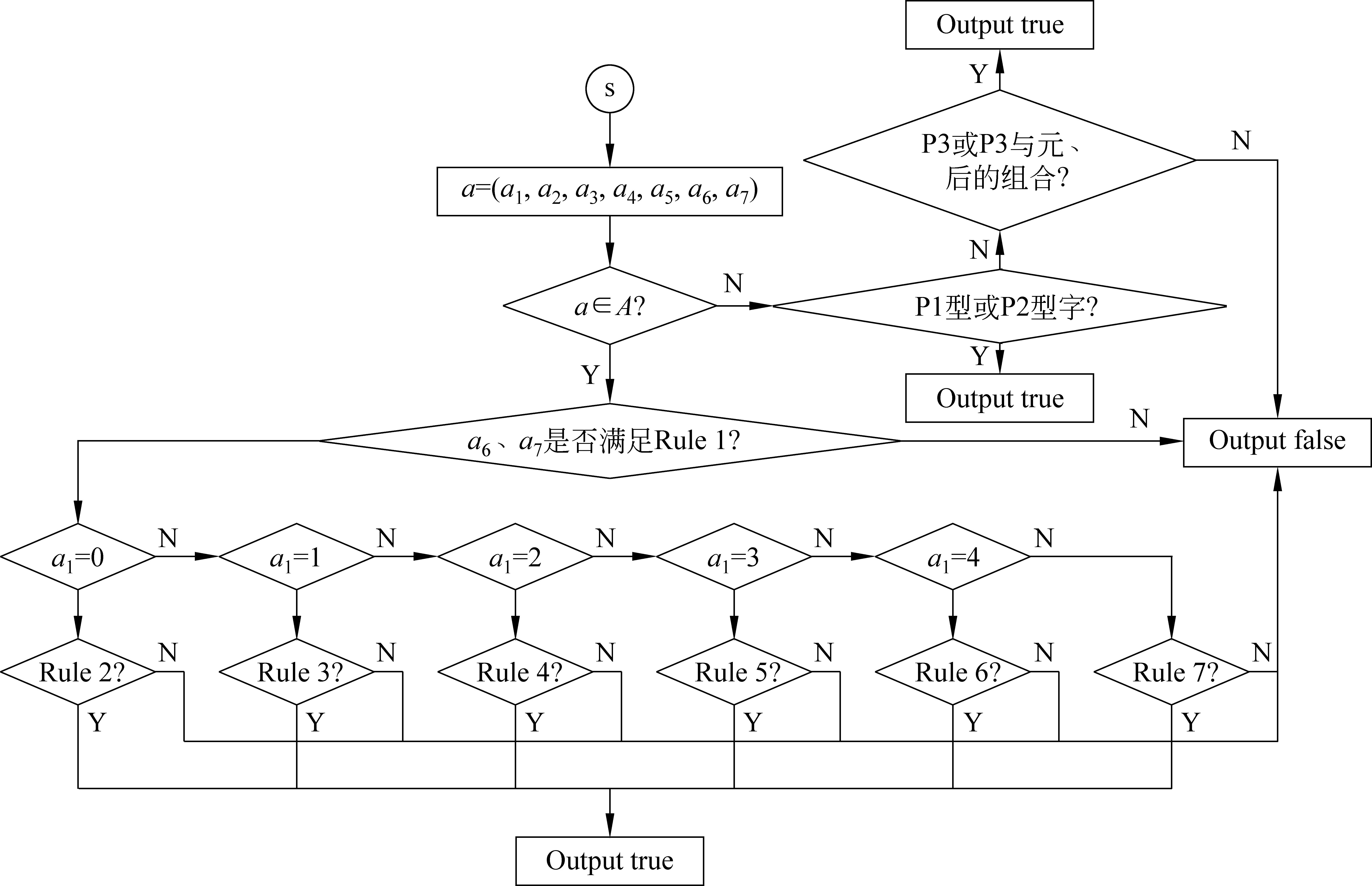
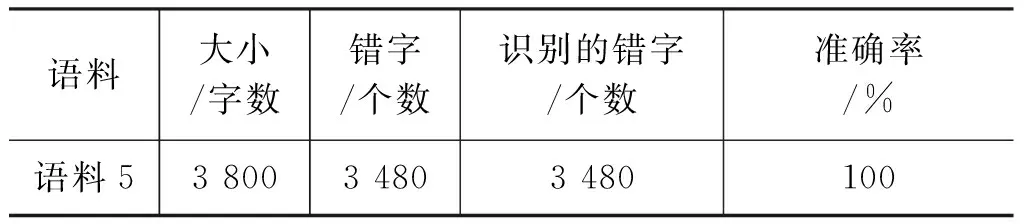
A={(a1,a2,a3,a4,a5,a6,a7)|0≤a1≤5,0≤a2≤3,0 (1) 的元素表示,向量集A叫藏文字向量模型[20](the Vector Model of Modern Tibetan Text,VMTT),由此可建立藏文字的集合S到藏文字向量模型的对应关系f。 设S={s|s∈藏文字集}表示藏文字的集合,A表示藏文字的向量模型,则由式(1)所示。 (2) 定理1藏文字的集合S与藏文字向量模型A间的对应关系是单射。 故藏文字的集合S与藏文字向量模型A间的对应关系是单射。 用一维向量表示藏文字需要满足以下三个条件: (1) 含七个分量; (2) 属于向量模型A; (3) 七个分量a1、a2、a3、a4、a5、a6、a7满足藏文字构件添加规则的约束条件。 条件(1)、(2)容易判断,例如,条件(2)可通过分量a1、a2、a3、a4、a5、a6、a7的取值范围0≤a1≤5,0≤a2≤3,0 表1 再后加字添加规则表 再后加字的添加规则仅与后加字有关,与其他构件无关,且后加字不受其他构件的影响,所以再后加字添加约束规则与其他规则独立、无冲突。后加字和元音的添加没有任何规则约束,即后加字和元音添加是自由的。前加字、上加字、基字和下加字的添加彼此制约,由藏文构件拼接规则可得藏文字前加字、上加字、基字和下加字拼接约束规则(称之为基于向量模型的藏文字拼写检查规则1~7,Rule1-7),见表2~7。 表2 a1=0时上加字、基字和下加字的添加规则约束表 表3 a1=1时上加字、基字和下加字的添加规则约束表 表4 a1=2时上加字、基字和下加字的添加规则约束表 表5 a1=3时上加字、基字和下加字的添加规则约束表 表6 a1=4时上加字、基字和下加字的添加规则约束表 表7 a1=5时上加字、基字和下加字的添加规则约束表 定义2藏文字可用向量集 M={(a1,a2,a3,a4,a5,a6,a7)|(a1,a2,a3,a4,a5,a6,a7)∈A,且a6,a7满足Rule11,a1、a2、a3、a4满足Rule1-7} (3) 的元素表示,向量集M叫基于规则约束的藏文字向量模型(the Vector Model of Tibetan Text Based on Rule Constraint, VMTTRC)。 由此可建立藏文字的集合与基于规则约束的藏文字向量模型间的对应关系。 设S={s|s∈藏文字集}表示藏文字的集合,M表示基于规则约束的藏文字向量模型,则由式(3)及Rule1-7得: (4) 显然可得: 定理2现代藏文字的集合S与基于规则约束的藏文字向量模型M间的对应关系是双射。 定理2说明每一个现代藏文字都可以用基于规则约束的藏文字向量模型M中的元素表示,反之每一个M中的元素表示一个现代藏文字,即现代藏文字的集合与基于规则约束的藏文字向量模型等价。 藏文文本中经常出现七个双音节字(下文称为P1型)、五个特殊叠字(下文称为P2型)和一个音译叠字(下文称为P3型)或音译叠字、元音和后加拼接成的特殊藏文字,这些藏文字的构成不符合现代藏文构字原则,无法用基于规则约束的藏文字向量模型表示。在拼写检查时,我们建立了特殊藏文字表(表8),通过查表的方式完成该类字的拼写检查。 表8 特殊藏文字表 基于向量模型的藏文非真字拼写检查可采用以下模型,如图1所示。 图1 藏文非真字拼写检查模型 藏文非真字拼写检查模型的预处理模块将藏文文本进行断句和识字处理,并将字规范化。断句可以按单垂符“|”或双垂符“‖”或空格为边界点,字间以音节分隔符“·”为边界点,藏文字规范化部分主要采用还原法识别紧缩词[21]。拼写检查模块先对规范藏文字进行构件分解[22-23],并利用藏文字向量模型表示法将藏文字表示为向量,然后通过基于向量模型的藏文字构件约束规则1~7及特殊藏文字表进行拼写检查。 设s为规范藏文字,A为藏文字向量模型,拼写检查模块流程如图2所示。 基于向量模型的藏文字拼写检查的具体步骤为: 第一步: 构件分解; 第二步: 藏文字向量化; 图2 藏文字拼写检查流程图 第三步: 根据基于向量模型的藏文字约束规则及特殊字表进行拼写检查。 基于向量模型的藏文字拼写检查算法如下: 1: 输入: 藏文字s2: 输出: true或false,true时该字正确, false时该字为非真字3: Component decomposition(s,T); //分解s的构件,并存入到T中4: Vector quantization(T,a); //将T中构件向量化到a中5: if(a∉A) //a不符合向量模型A6: if(s isP1型或P2型) output(true); //P1型和P2型为特殊藏文字7: else if(s is P3或P3与元、后的组合) output(true);8: else output(false);9: else if((a6,a7)∉Rule1) output(false); //a6,a7不满足规则表110: else if(a1=k and (a2,a3,a4)∈Rule k+2 ) output(true) k=0,1,2,3,4,5; //无前加字或前加字为或或或或,且符合Rule 2或Rule 3…或Rule 711: else output(false); 为了验证模型及算法的有效性,我们研发了基于向量模型的藏文非真字自动拼写检查系统,并设计了两组实验。实验一考察系统对实际语料中非真字的拼写检查效果,实验二考察系统对各类非真字的拼写检查效果。实验硬件环境为Intel core i5 2.40GHz、2GB内存的PC,软件环境为Windows 7,系统由Delphi 2010开发。实验语料及数据如下: 实验一的语料包含11.7万藏文字,将语料分成了四部分,分别对4个语料考察非真字的识别率和拼写检查耗时,每个语料保留了现代藏文字及特殊藏文字,删除了特殊藏文字外的所有梵文字符、序号、数字、符号等。语料1选用了小学藏语文五年级(上册)教材语料,规模含21 506个字;语料2选用了小学藏语文六年级(上册)教材语料,语料规模含29 024个字;语料3选用了华丹萨迦巴专著中的诗歌专辑的一部分,语料规模含35 020个字;语料4为网络语料,语料规模含31 450个字。其中语料1、2、3来自青海师范大学语料库,语料4来自琼迈文学网。实验数据见表9,实验中的耗时包括识字、规范化、构件分解、字向量化和拼写检查等操作所用的时间。表中方法A指的是文献[14]的TSRM方法,方法B指本文所提出的基于向量模型的藏文字拼写检查方法。实验结果如表9所示。 表9 基于向量模型的藏文非真字拼写检查(实验数据1) 实验二参考文献[11]列举的藏文错字类型,主观构建了包含各种错误类型的语料,考察对每种错误类型的拼写检查的准确率,实验结果见表10。 表10 基于向量模型的藏文非真字拼写检查(实验结果2) 实验二表明本文提出的方法能够识别各种类型非真字错误,验证了规则的通用型和全面性。 本文通过分析藏文构字和构件拼接原则,建立了藏文字向量模型(VMTT)及基于规则约束的向量模型(VMTTRC),并构造了基于向量模型的藏文非真字约束规则,在此基础上设计了基于向量模型的藏文非真字拼写检查模型及算法。算法先将藏文文本进行断句、识字、字规范化、构件分解后,将规范藏文字表示为向量,通过基于向量模型的藏文字约束规则完成藏文非真字拼写检查功能。算法简单易于实现,经对含117 000字的藏语语料测试,对非真字识别的平均准确率达99.995%,拼写检查的平均速度约为1 060字/s,满足文本自动拼写检查的需求。今后在该研究基础上,通过分析词语的搭配方式及字、词同现度,研究藏文真字的拼写检查方法,进一步完善自动拼写检查技术。


2.2 基于规则约束的藏文字向量模型







3 基于向量模型的藏文字拼写检查模型

3.1 基于向量模型的藏文字拼写检查模型

3.2 基于向量模型的藏文字拼写检查算法

3.3 实验数据

4 结论与展望
