基于双语短语约束的交互式机器翻译方法
2018-10-19张桂平
徐 萍,叶 娜,吴 闯,张桂平
(沈阳航空航天大学 人机智能研究中心,辽宁 沈阳 110136)
0 引言
机器翻译(Machine Translation,MT)是指利用计算机将一种自然语言翻译成另一种自然语言的方法,其研究旨在使计算机能够替代人类实现高质量的全自动翻译[1]。现有的自动机器翻译产生的译文质量并未达到可以直接应用的水平,翻译系统产生正确译文的过程离不开译员的参与。于是,一些研究人员将研究重点由全自动机器翻译转向了计算机辅助翻译(Computer Assisted Translation,CAT)[2],系统为译员提供辅助译文和辅助工具帮助译员对译文进行译后编辑。
交互式机器翻译是计算机辅助翻译领域的一个重要研究课题,不仅提供了译员和机器之间相互交流和学习的接口,还允许译员在翻译过程中指导目标语言的生成,减少译员工作量,提升翻译效率。使用较为广泛的交互式机器翻译方法[3-12]大多使用译员确认的前缀作为唯一约束,译员在系统给出的推荐译文上直接选取正确的最长前缀并输入字符作为新前缀反馈给系统指导解码,搜索符合条件的译文后缀,译员与系统不断交互,直至得到完全正确的译文。图1为一个完整的交互式机器翻译实例。
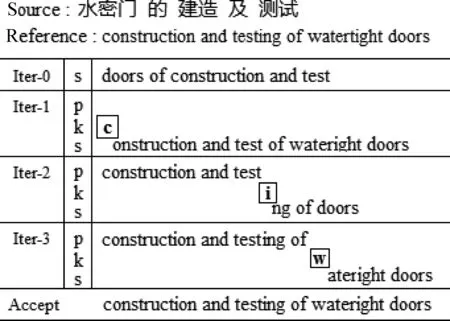
图1 基于前缀的交互式机器翻译实训
Source为译员输入的源语言,Reference为参考译文,Iter-0是机器翻译系统的推荐译文,第一次迭代过程中(Iter-1)p为译员确认正确的前缀信息,k为译员与系统的交互内容,译员使用键盘输入字符“c”,系统根据前缀搜索出的新译文后缀s,重复迭代交互过程,直到搜索到译员满意的译文,翻译结束。
与全自动机器翻译和需要大量译后编辑的计算机辅助翻译相比,传统的交互式机器翻译通过在译文上确认前缀的方式,直接参与并指导翻译系统的解码过程,但是这种方法仍有很多不足: 第一,传统IMT方法通过逐字确认前缀的方式自左向右补全句子,一个短语需要解码多次才能被翻译正确;第二,翻译正确的译文后缀会随着前缀的更改重新解码,有时原本正确的译文在增加了前缀约束后会被翻译错误,需要译员重新确认,影响交互效率;第三,限制了人机交互方式,译员无法从其他方式给予更充分的指导;第四,一些研究人员对传统交互方式进行扩展[13-16],允许译员在译文中选择单语片段,但是从错误的译文里识别正确的译文片段十分困难,增加了译员的认知负担。
针对上述情况,本文提出一种基于双语短语约束的交互式机器翻译方法,从交互模式和解码算法两个方面对传统交互式机器翻译方法进行改进。在交互模式方面,加载短语表为源语言短语建立候选短语译项表,允许译员在译前选择短语的正确译项,并对短语译项表进行了多样性处理,提高候选译项的多样性,根据译员的翻译认知过程设计交互界面;在解码算法方面,将译员选择的双语短语与前缀一同作为约束传入解码器中指导解码,过滤短语的候选译项,提高翻译选项评价和过滤的准确性。本文在LDC议会记录和LDC法律汉英平行语料上开展真实人工评测实验,采用平均翻译时间作为主要评测指标,实验结果中时间分别缩短了22.80%和18.34%,表明本文方法在实际应用中的翻译效率较传统交互式机器翻译方法有显著提高。
1 相关工作
1997年Foster[17]提出了TransType系统的雏形,实现译员和机器翻译方法的优势互补。2002年欧盟RTD计划的TransType2(TT2)[18]系统在TransType的基础上进行改进,从预测几个词到可以预测整个句子,此后研究人员都是在TT2系统的基础上对交互式机器翻译方法进行改进的。
研究人员大多通过改进IMT的翻译框架来对传统方法进行改进: Och等[3]利用词图假设对翻译译文进行搜索,减少系统的反应时间及键盘敲击率(KSR),提高搜索效率;Civera等[4]在系统中使用随机有限状态转换机(SFST)提高了最佳译文后缀的搜索效率;Tomás 等[5]利用了基于短语机器翻译的单调搜索和非单调搜索算法,将基于短语的统计机器翻译引入计算机辅助翻译中,提高了运行速度;González-Rubio等[6]将基于短语的翻译模型和层次模型整合在一起,对系统进行误差修正,提高译文的翻译质量,减少译员的工作量;Peris等[7]在神经机器翻译模型上进行改进,实现了基于前缀和基于片段两种神经交互式机器翻译,针对不同语言和领域进行模拟实验,神经机器翻译模型具有更加适应用户反馈的灵活性,显著减少了用户工作量;Wuebker等[8]将短语模型和神经网络模型共同应用到交互式机器翻译中,递归神经系统能够提供更准确的预测结果,短语翻译系统运行速度快,并且可以提供N-best译文,该方法将两种系统的优势互补,有效地提升了IMT系统对译文后缀中第一个词预测的精确度。
研究人员还通过改进解码算法来提高IMT方法的翻译性能: Nepveu等[9]提出了基于缓存的自适应语言模型和翻译模型,通过利用缓存中的语言模型信息和翻译模型信息降低模型的困惑度,提高译文质量;Bender等[10]用动态规划算法结合词图提高搜索效率,完善译文生成策略;Cai等[11]从引入动态调序距离限制、部分翻译假设的差异最大化和对译员确认前缀的利用三个方面进行改进,提高了系统效率;Koehn等[12]利用译员提供的前缀在统计词图中搜索最佳后缀;Green等[13]在基于短语的机器翻译系统上进行修改,提出了前缀解码、动态扩大短语表等方法,并利用交叉熵目标函数实现重调序的判别;Azadi等[14]在基于短语的IMT方法中,通过为编辑距离添加跳转操作的方法,改善图搜索中重排序的不足,并搜索最佳后缀提供给用户;Ye等[15]针对短语模型的固有缺陷,通过引入句法对齐信息来改进交互式翻译系统的翻译性能。
除此之外,还有一些研究者从交互方式角度对传统IMT方法进行改进: González-Rubio等[16]设计了一个自由校对规则,通过允许译员确认或修改任意位置的译文以减少译员的编辑量和认知负担;Green等[19]分析总结了协同翻译、混合主动互动原则等多种计算机辅助翻译方法,提出了一种新的预测翻译记忆方法,根据用户使用习惯重新设计了源语言端的理解、目标语言实时更新和译文生成等部分的UI界面,并在两种大规模语料上进行翻译实验,翻译结果表明该系统可以进一步提高翻译效率;Ye[20]等通过增加正向片段,改善搜索算法、扩展假设规则、为正向片段匹配评分和假设多样性等方式对传统交互式方法进行改进,提高译员工作效率;Peris等[7]将神经机器翻译与IMT结合到一起,允许译员对译文的正确片段进行标记,提高传统基于短语的IMT系统的工作效率。以上方法均采用在目标语言中识别正确译文片段的交互方式,然而,机器译文中既有选词错误又有顺序错误,要从里面识别正确译文对于译员来说比较困难。若对照源语言来进行正确译文的选择,能更好地减轻译员的认知负担。Cheng等[21]提出了一种基于选择—修正的交互框架,将交互过程分为选择错误和修改翻译两个过程,并分别建立自动建议模型,有效提高了人机交互的效率。与该方法相比,本文根据译员的翻译认知过程设计一个将源语言与目标语言对齐的交互界面,由译员从短语译项表中选择正确译项,为系统提供指导,既操作方便,又保证了译文准确性,同时对短语译项表进行多样性处理,采用人工评测的方式进行实验,将翻译时间作为评价指标,更加真实地反映翻译效率。
2 基于双语短语约束的IMT方法
基于双语短语约束的交互式机器翻译方法以基于短语的机器翻译模型为基础,对系统的输入和解码两个部分进行改进,允许译员选择双语短语作为约束,与前缀一同指导计算机解码,其系统流程如图2所示。
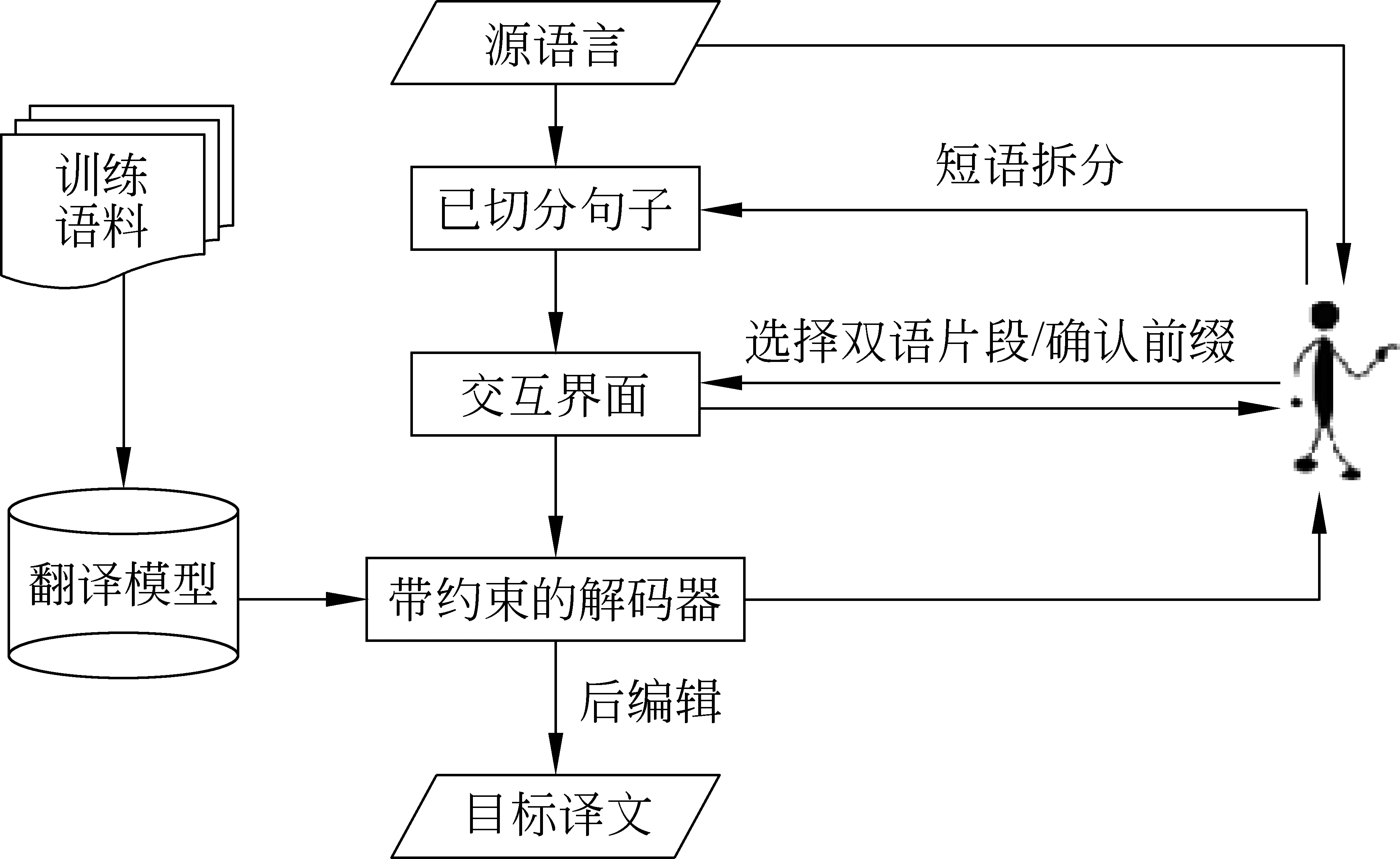
图2 基于双语短语约束的交互式机器翻译系统
本节将从交互方式、设计原则、短语译项重排序和解码算法四个方面介绍该方法。
2.1 交互方式
本文为基于双语短语约束的IMT系统设计了交互界面,将传统交互过程分解为“短语拆分—短语译项确认—重解码”三个过程,实现译员在源语言的短语译项表中选取正确译项的功能。图3为基于双语短语的IMT系统翻译过程实例。

图3 基于双语短语约束的IMT实例
系统在译前为源语言Source加载候选译项列表,译员根据需求在短语译项表中选取 “水密门”的译项为“watertight doors”,选取“建造及测试”的译项为“construction and testing”,Iter-0为系统根据双语短语约束搜索的译文,译员输入前缀“c”再次解码得到Iter-1,与参考译文一致,翻译结束。
2.2 设计原则
经过对本文方法中的约束条件和译员翻译行为进行分析,本文提出如下几个界面设计原则。
(1) 译前选词: 译员在翻译过程中不是按顺序逐词翻译,而是重点关注关键词。本文译前选择短语译项的方法不考虑译文顺序,且便于译员观察思考,保证译文准确性。
(2) 短语拆分: 译员希望尽量选择较长短语的译项,但并不是所有长短语的译项都正确。本文提出短语拆分的方法,允许短语之间自由组合,变化更加灵活。
(3) 双语短语对齐显示: 短语译项表加载多个候选译项为译员提供参考,源语言与目标语言对齐显示使译员更容易识别正确译项,减轻译员的认知负担,保证译文准确性。
短语拆分和短语译项确认界面如图4所示。

图4 短语拆分和短语译项确认界面
系统为源语言加载短语译项表,将鼠标移动到源语言上,下方会自动加载该短语的译项列表,译员单击鼠标确认正确译项;若是该短语的组合不符合译员期望,可以先单击短语上方的双向箭头对短语进行拆分或合并,再为其选择合适译项。图4中,(a)是系统最初为源语言目标短语提供的分词参考,并为每组短语加载了短语译项表,译员可以根据自己的需求对短语进行再处理,对短语进行拆分或合并;(b)为译员从短语译项表中选择合适译项;(c)是完成短语译项选择的结果。
2.3 短语译项重排序
本文系统中的短语译项表来自于翻译模型训练得到的短语表,首先短语表中包含了训练语料中所有可能的短语组合,以及它们对应的目标语言,满足长短语进行拆分合并的功能;其次,短语表中给出了源语言和目标语言之间互为翻译的概率,能够优先推荐质量高的目标译文。然而短语表中常见短语的候选译项多达上百个,按翻译概率打分,较高的译项十分相似。为了在翻译过程中给译员更多的选择和启发,并考虑到实际交互界面的限制,本文提出了一个短语译项的重排序算法,用以提高短语译项的多样性,如图5所示。

图5 基于多样性的短语译项重排序算法
该算法使用翻译概率对短语表进行过滤,选取翻译概率最高的前n个候选译项,按以下步骤对短语译项表中各译项进行排序。
(1) 将概率最高的译项放入短语译项表中,并对其他所有译项进行还原处理。
(2) 计算每个译项与短语译项表中已有译项之间的共现概率,共现概率越小,两个短语之间的多样性越大。
(3) 选择所有待排序译项中与短语译项表之间差异最大的一个译项放入短语译项表中。
(4) 重复步骤(2)和步骤(3),直到所有译项完成重排序,选取短语译项表的前10个译项显示于系统界面供译员参考和选择。
短语译项多样性的计算公式如式(1)所示,D描述了两个短语译项之间的差异大小,其中ti和tj为短语译项中词的原形,c(ti,tj)为ti和tj之间的重复词数。
(1)
2.4 解码算法的改进
基于短语模型的交互式机器翻译方法[22]可以描述为: 给定一个源语言句子s,用户在系统的推荐译文上确认前缀信息tp,系统根据前缀信息的约束通过假设扩展的方式对其进行解码,在指定的目标语言中搜索到一个满足前缀信息的后缀译文ts,其翻译模型的公式如式(2)所示。
(2)
式(2)可以转换为式(3):
(3)
该方法利用对数线性模型,将语言模型、调序模型和翻译概率等模型作为重要特征对源语言和目标语言建模,如式(4)所示。
(4)
基于前缀的IMT方法在解码过程中只考虑前缀与翻译假设的匹配,系统根据翻译模型为源语言建立一个候选翻译列表并组织翻译假设,搜索合适的译文。在建立候选翻译列表的过程中,系统直接从短语表中找到不同组合的源语言短语及其对应的目标译文,将这些译文选项按翻译概率从高到低排序并保留前n个作为候选翻译选项。
为了搜索最优翻译假设,本文利用多栈搜索[23-24]的解码方法搜索满足前缀条件的最佳后缀译文,其过程如图6所示。
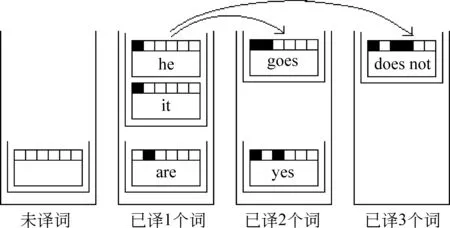
图6 基于多栈搜索的统计机器翻译解码方法
在多栈解码中,系统根据源语言中被扩展的短语数量对翻译假设进行分类,将覆盖短语数相同的翻译假设放在同一个栈中。翻译初始只包含空假设,通过假设扩展的方式不断地从短语表中搜索合适的翻译假设,将其添加到原有假设后面,形成新的假设并存入栈中,直到源语言中所有短语都被覆盖,翻译结束。
本文将双语短语与前缀一同作为约束信息指导IMT系统解码,双语短语包含了源语言、源语言位置和对应的目标语言译项。其中源语言与目标语言是对齐的,短语译项表提供了多个翻译选项,译员可以确认形如
(5)
在建立候选翻译列表过程中,若是当前搜索短语包含双语短语,需要根据双语短语对当前词的候选译文选项进行过滤,仅保留符合约束条件的译文放入候选翻译列表。翻译选项是否符合双语短语约束的判断方法如下:
(1)若当前搜索的短语不包含双语短语中的源语言,在短语表中找到该短语的译文作为当前短语的翻译选项。
(2)若当前短语包含双语短语中的源语言,且短语长度为1,将双语短语中的目标语言作为该源语言的翻译选项。
(3)若当前短语包含双语短语,且短语长度大于1,遍历该短语在短语表中的所有译文,若译文包含对应的译项,保留该翻译选项。
图7给出了短语译项过滤算法的伪代码。

图7 短语译项过滤算法
为了搜索到最优翻译假设,使用多栈搜索的解码方法,搜索同时满足前缀约束和双语短语约束的最佳后缀译文,对翻译选项进行扩展,直到整个句子被完全覆盖则翻译完成。
3 实验
3.1 实验设置
交互式机器翻译的评测主要分为人工评测和自动评测,人工评测需要耗费的人力多、时间长,目前有关交互式机器翻译方法的评测大多采用自动评测的方式。自动评测只记录译员的操作次数,不计算时间,忽略了译员的思考与认知行为,无法准确地反映译员真实翻译情况和工作效率。因此本文选取译员对测试语料进行翻译,并开展人工评测实验,采用交叉实验的方式,让译员在真实的翻译环境中进行实验,统计译员的翻译时间和翻译行为,确保得到更加真实、公正的实验结果。
本文借鉴Barrachina等[22]的方法,在Silk Road机器翻译系统的基础上实现了一个基于前缀的交互式机器翻译系统作为Baseline,并在该系统上进行改进: 加入双语短语约束的IMT系统作为System1,加入双语短语约束并对短语表进行多样性排序处理的系统作为System2。除文中进行的改进之外,Baseline与System1、System2的翻译框架、加载模型及各参数均相同。
实验中所有中文语料都采用ICTCLAS[注]http://ictclas.nlpir.org /分词,并进行词形还原和小写化处理;词对齐训练工具为GIZA++;英文语料的语言模型是由IRSTLM训练的5-gram模型;统计翻译模型使用Moses[注]http://www.statmt.org/moses/训练。
实验选取LDC2000[注]http://ldc.upenn.edu/的香港议会记录汉英平行语料和法律汉英平行语料作为语料,表1给出了实验数据的相关信息。
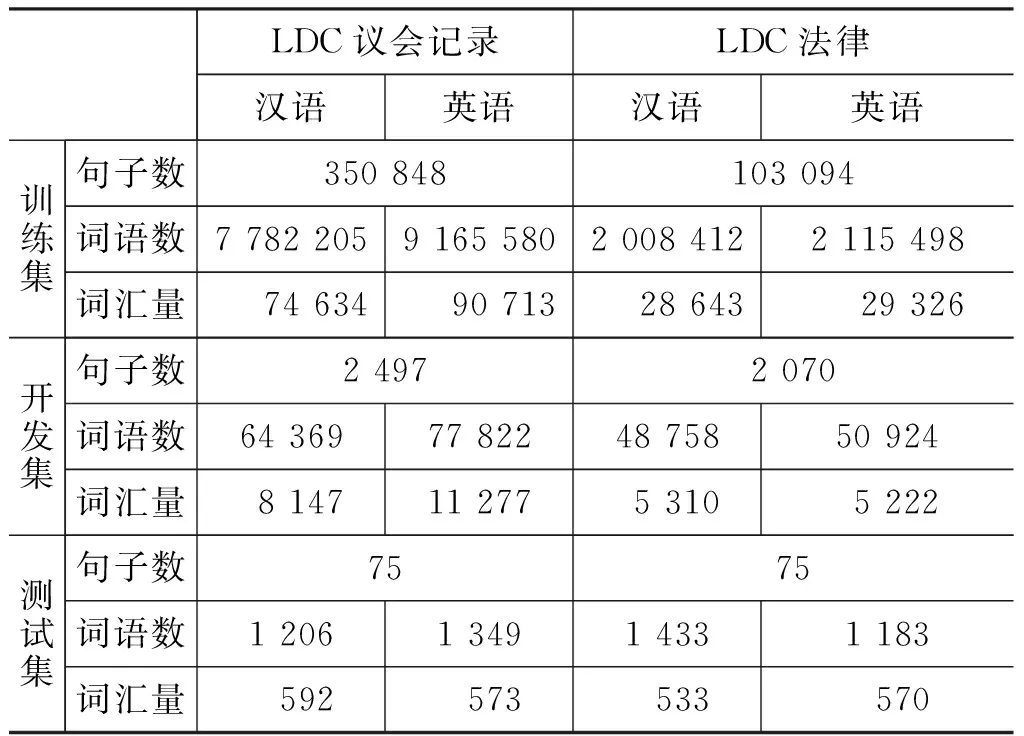
表1 语料的统计特性
3.2 评测方法
本文参考Vicent等[25]的交叉实验方式,选取英语水平相同的九名译员分为三组(G1,G2,G3),每种语料各75句并分为三组(C1,C2,C3)进行人工评测。为确保每份测试语料不会被重复翻译,每组译员分别使用不同系统翻译三份不同的测试语料,交叉进行实验测试后再计算每个系统的平均实验结果,实验分组设置如表2所示。
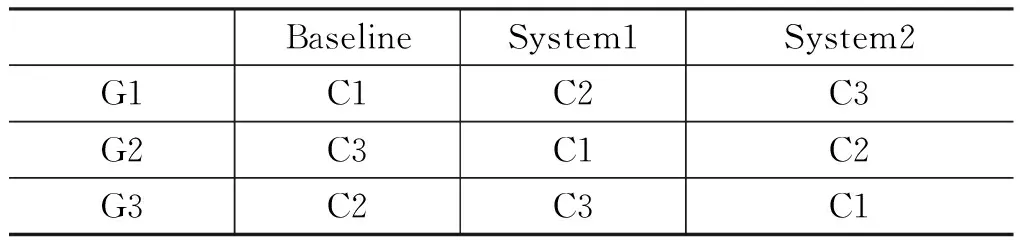
表2 实验分组
时间是衡量交互式机器翻译方法效率最真实的标准,平均翻译一个句子花费时间更少的交互式机器翻译方法具有更好的辅助效果,因此本文将平均翻译时间作为主要评测标准。
本文同时将KSMR值、解码次数和BLEU值[26]作为参考评测标准。KSMR用来衡量译员的操作次数,计算如式(6)所示。
(6)
鼠标和键盘的点击次数不能完全代表译员工作量,因此本文将解码次数作为另一个辅助评测指标,解码次数是指IMT系统根据新约束重新解码并推荐机器译文的次数。
BLEU值是译文质量的评测指标[27],本文使用BLEU值作为参考,比较两个系统的翻译译文质量,当译文质量在同一水平时,平均翻译一个句子的时间更少的系统效果更好。
3.3 实验结果
表3为译员分别使用不同系统在两组语料上进行交叉翻译实验的平均时间,单位为“s/句”。
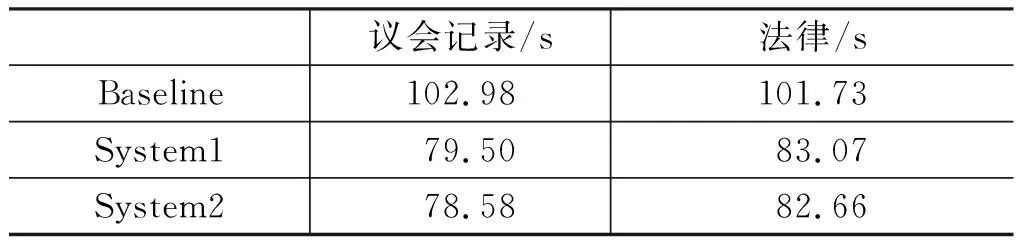
表3 不同系统的平均翻译时间
实验结果表明,本文实现的系统在不同语料上的翻译时间均明显缩短。以议会记录为例,System1的平均翻译时间为79.50s,比Baseline缩短了22.80%,说明本文方法在翻译效率上较传统方法有很大的提升,其原因有以下三点。
(1) 本文方法可以为译员提供翻译参考,减少译员的思考时间和认知负担,提高翻译效率;
(2) 短语译项的选择是在译前进行的独立过程,译员无需在既有词语错误又有顺序错误的译文中确认正确译文片段,减少译员认知负担。
(3) 译员可以同时确认双语短语作为约束,减小解码过程中的搜索空间,提升解码效率。
System2的平均翻译时间为78.58s,在System1的基础上缩短了0.89%,说明加入短语译项表多样性排序后的系统性能略有提升。其中,System2中短语译项表在多样性排序后扩大了候选译项的多样性,同时增加了正确译项在短语译项表中的概率,当译员在System1的候选译项表中找不到合适的选项而在System2中可以找到时,System2的翻译效果会有提升;但是,当两个系统的短语译项表中都包含译员期望的译项时,译员使用两个系统的翻译效果是一样的。因此与System1相比,System2的性能只是略有提升,但并不明显。
表4为译员使用不同系统进行实验的KSMR值。
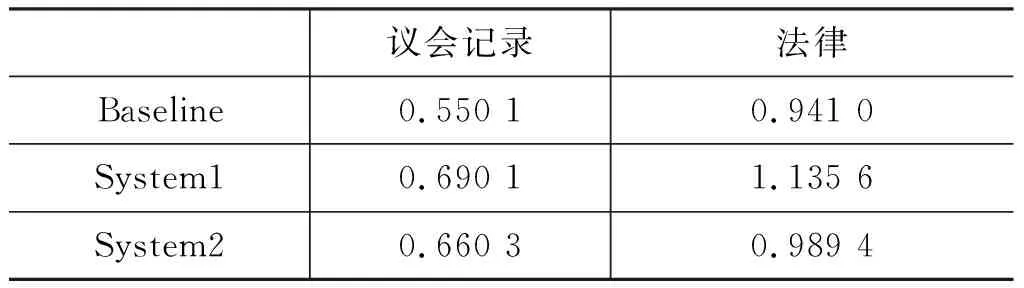
表4 不同系统的KSMR值
实验结果中,System1和System2的KSMR值均高于Baseline,因为译员使用Baseline只需要用键盘输入新前缀并单击按键进行翻译,本文系统除Baseline中的基本操作外,还需要单击译文对源语言进行短语拆分和短语译项确认操作。短语拆分过程中大量的拆分和合并操作增加了鼠标点击量,这些操作简单方便,不会耗费太多时间,而Baseline中译员每次输入新前缀解码前都需要耗费大量时间去思考,在实际翻译中占用更多时间,因此KSMR值并不能完全代替翻译效率。
不同语料上System2的KSMR值均略低于System1是因为System2进行了短语译项表多样性处理,译员在选择译项时的选择空间更大,能够更快地确认正确译文,减少了操作次数。
表5为不同系统在实验中的解码次数。
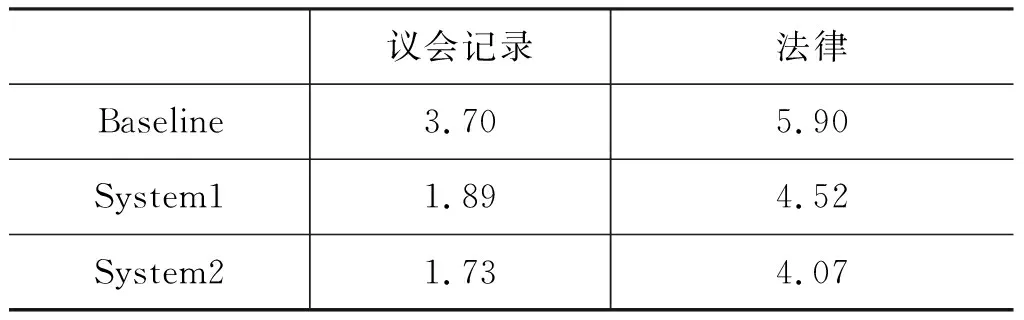
表5 不同系统的解码次数
在议会记录语料上,System1和System2的解码次数分别比Baseline减少了48.9%和53.24%,法律语料上分别比Baseline减少了23.39%和31.02%,解码次数下降的幅度十分大。译员将双语短语作为约束传入翻译系统进行解码,相比于Baseline系统,减少了需要输入多次前缀来确认一个短语的情况,正确的译文后缀也不会因为更改前缀而重新解码,因此在解码次数上,本文系统的翻译效果较Baseline有很大的提升。由此证明KSMR值的增加主要是因为短语拆分和短语译项确认操作需要大量的鼠标单击次数,但是这些操作并没有影响翻译效率,反而减少了译员的认知负担和系统的解码次数,提高了翻译效率。
同一语料的解码次数中,System2比System1略有减少,因为增加了多样性的候选译项表,能够给译员提供更大的选择范围,正确译项出现在短语译项表中的可能性更大,译员能够更快、更准地找到正确译项,减少了使用前缀解码来确定译文的次数。
表6为实验结果中译文的BLEU值。
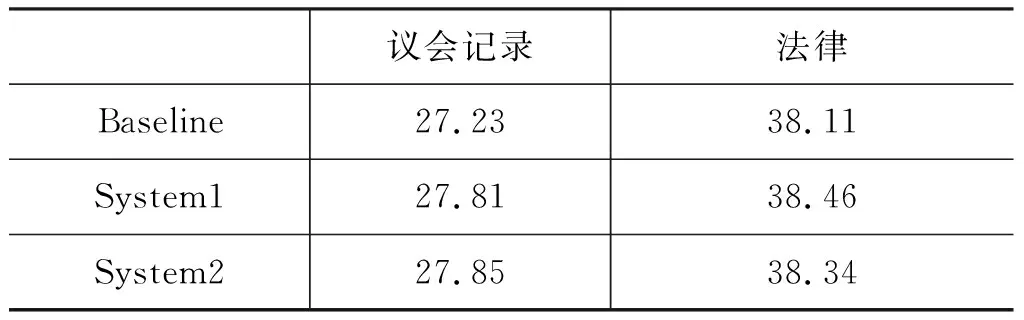
表6 不同系统的BLEU值
议会记录语料最初的系统推荐译文BLEU值为19.71,经三个系统翻译后的最终译文BLEU值分别为27.23、27.81和27.85,均在同一水平,说明在译文质量相似的情况下,使用本文方法的翻译时间比传统方法更短,效率更高; 不同语料上System1和System2的译文BLEU值均高于Baseline,译文质量的提升说明候选译项表可以有效地为译员在翻译过程中提供参考,提高译文的准确性,减少译员的认知负担。
3.4 实例分析
图8为使用不同系统进行翻译的实例。
如图8所示,使用Baseline进行翻译的解码次数为八次,而使用本文方法仅需解码两次,解码效率得到了显著提升。使用Baseline翻译短语“由 香港政府 使用”共需输入四次前缀并重新解码才能得到正确译文,本文方法允许用户在译前选择该短语的译项“used by the Hong Kong Government”,只需解码一次便可得到正确译文,与Baseline相比译员的翻译效率得到了显著提升。

图8 不同系统的翻译实例
上述实例表明,本文方法的短语译项表允许译员在译前选择短语的译项,减轻了译员的认知负担,选择双语短语作为约束指导解码器进行解码,能够减少译员重复输入多次前缀来确认一个短语的工作,显著缩短译员的翻译时间,提高翻译效率和译文质量。
该方法对短句子或某些句型简单的句子翻译效果不如传统IMT方法,因为传统IMT方法通过前缀约束很快可以得到正确译文。
4 结论与展望
本文提出一种基于双语短语约束的交互式机器翻译方法,从交互方式和解码算法两个方面对传统IMT方法进行改进: 通过加载短语译项表和短语表多样性处理等方式提供更多信息辅助译员翻译,改善了译员在翻译过程中的体验,并减轻了译员的认知负担;设计交互界面允许译员在译前选择双语短语作为约束,更加充分地指导解码过程,在保证译文准确性的同时提高了翻译效率。本文在LDC汉英平行语料上进行人工评测实验,结果显示在实际应用中基于双语短语约束的交互式机器翻译方法能够减少翻译时间,提升翻译效率和译文质量。
在未来工作中,将根据译员选择短语译项的历史信息自动调整短语译项表中译项的顺序,让译员更快、更准地选择正确译项;同时改进翻译模型和解码算法,将神经机器翻译模型与本文方法结合,提高原始译文的质量,进一步提高译员翻译效率。
