基于深度学习的军事命名实体识别方法
2018-10-19王学锋杨若鹏
王学锋, 杨若鹏, 朱 巍
(国防科技大学信息通信学院联合作战信息通信系, 湖北 武汉 430010)
随着大数据、云计算、物联网在军事领域的广泛应用,各类军事文电信息呈指数级增长,无论是平时情报数据采集还是战时战场信息处理,各级指挥员面临的“战争迷雾”从“信息不足”演变到“信息过载”。海量的信息短时间内涌入指挥信息系统,不仅给通信带宽造成沉重负荷,同时也让指挥员无所适从,如何从海量的军事文电信息中自动提取指挥员感兴趣的关键信息是当前亟待解决的问题之一。信息抽取技术能将大量非结构化的文本信息自动转化成指挥员所需的结构化的文本信息,不仅提高了指挥信息系统内信息的互操作性和复用性,而且对作战数据库的动态更新、军事情报的智能处理、作战要图的自动生成具有重要意义。
军事命名实体识别是军事文本信息抽取的基础环节,主要任务是识别出军事文本中的部队、时间、地理位置、武器装备、设施机构等专有名称并加以归类。目前,在通用领域命名实体识别的方法主要有基于规则的方法、基于统计与机器学习的方法和基于深度学习的方法。其中:基于规则的方法精度高,但是覆盖度、移植性差且开发成本高;基于统计与机器学习的方法开发成本低,然而对特征工程和中文分词依赖性强;基于深度学习的方法精度高,可移植性强,但是构建词向量仍然需要分词,同时对计算能力和语料规模要求高[1]。随着计算能力、算法和语料的不断发展,基于深度学习的方法应用于军事领域将成为未来军事命名实体识别的趋势。
近年来,军事命名实体识别的研究逐渐受到重视。GUO等[2]基于规则和词典的方法,从战术报告中抽取出有意义的实体;单赫源等[3]利用条件随机场(Conditional Random Field,CRF)模型学习文本特征,对作战文书中的军事命名实体进行了识别;宋瑞亮[4]基于半监督的CRF模型,对军用文书和军事新闻中的军事命名实体进行了识别;姜文志等[5]采用CRF与规则相结合的方法,对军事命名实体进行了识别;冯蕴天等[6]采用CRF结合词典和规则的方法提取文本特征,比仅用CRF识别效果更好;胡斌等[7]基于模板的方法,从文书中提取标绘信息进而自动标图。以上研究主要采用传统方法,在识别效果和可扩展性上略显不足,已经难以适应军事理论、武器装备和作战力量日新月异的变化,也不能满足海量大数据自动化、智能化处理的需求。目前,军事命名实体识别主要存在以下问题:1)军事命名实体存在大量组合、嵌套、简称等多种形式,且由于个体语言风格和习惯各异,军事文本语言表述没有固定模式,即使是作战文书也只是对部分内容进行规范,因此难以构建全面合理的实体特征;2)现有的分词工具主要适用于通用领域,对军事领域分词准确率不高,特别是专业军事术语在通用领域少见,即使加入军语词典也难以包含所有军事实体,因此,这种对分词依赖性强的方法的识别效果难以突破目前瓶颈。随着字向量的提出,基于深度学习的方法有了新的突破,为此,笔者在前人研究的基础上,提出基于深度学习的军事命名实体识别方法,采用基于字向量的双向长短时记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)神经网络提取文本特征,不仅能避免人工提取特征的高成本和复杂性,而且能有效降低对分词的依赖性,可以大幅提高军事命名实体识别效果并降低系统开发成本。
1 军事命名实体识别模型
针对军事命名实体的特点,笔者构建了基于深度学习的军事命名实体识别模型,结构如图1所示。
模型由3部分组成:字向量(character embedding)表示层、Bi-LSTM神经网络层、CRF层。文本序列的每个字xi通过字向量表示层转化为模型输入的字向量ei;字向量序列经过Bi-LSTM神经网络层提取上下文特征并输出特征向量pi;CRF层根据特征向量标注命名实体并输出相应标签,实体的标注采用BIO标注规则[3]。
1.1 字向量表示层
模型的第1层是字向量表示层,字(词)向量表示是基于深度学习的文本处理的核心。字向量有one-hot[8]和character embedding[9]2种表示方法,由于character embedding能避免维数灾难,同时也能体现字之间的语义相关性,因此,本文选择character embedding表示字向量,具体步骤如下:
1) 将文本序列以句子为单位进行分隔,含有N个字的句子(字的序列)记作x=(x1,x2,…,xN)。
2) 将文本序列的每个字xi对应转化成字向量矩阵Wd∈Rd×V中的一个字向量ei,其中:V为语料中字典的总字数,一般使用常用汉字、数字及字母作为字典;d为字向量的维度,在训练字向量时可以作为预设的参数。字向量矩阵既可以选择前人研究中预训练好的字向量,也可以根据构建的语料重新训练。将字xi转化成字向量ei的计算公式如下:
ei=Wdvi。
式中:向量vi的维度为V,其元素取值规则为第i行的值取1,其他行的值取0。
3) 将句子转化为字向量序列e=(e1,e2,…,eN),并输入到模型下一层[9]。
1.2 Bi-LSTM神经网络层

在设置dropout[10]后,接入一个线性层,将隐状态向量hi从d维映射到K(K是标注集的标签数)维,从而得到自动提取的句子特征,记作矩阵P=(p1,p2,…,pN)∈RN×K。可以把pi∈RK的每一维Pij都视作将字xi分类到第j个标签的打分值,如果再对P进行Softmax[11],就相当于按K类对各个位置独立进行分类。但是,这样对各个位置进行标注时无法利用已经标注过的信息,需接入一个CRF层来进行标注。
1.3 CRF层
模型的第3层是CRF层,该层用来学习标注特征,其可为最后预测的标签添加一些约束以保证预测的标签是合法的,如在B-ORG标签后面不能再出现I-LOC标签,且这些约束可以在数据训练过程中通过CRF层自动学习,CRF层的转移矩阵A∈R(K+2)×(K+2),其元素Aij表示从第i个标签到第j个标签的转移得分,进而在为一个位置进行标注时可以利用此前已经标注过的标签,K+2表示句子首部、尾部分别添加一个起始状态和一个终止状态。如果记一个长度等于句子长度的标签序列y=(y1,y2,…,yN),那么模型对句子x的标签y的打分
可以看出:整个序列的打分等于各个位置的打分之和,而每个位置的打分由2部分得到,一部分由Bi-LSTM输出的矩阵P决定,另一部分则由CRF的转移矩阵A决定。模型训练时通过最大化对数似然函数,即可求得文本的最佳得分序列。
2 识别方法步骤
2.1 构建字典和字向量矩阵
在神经网络的输入层进行字向量随机初始化时需要用到字典,输入层首先读取每个字的索引,再转化为one-hot向量,进而转化为character embedding向量。字典是将原始文本中所用到的所有汉字、标点、数字及其他标志符进行统计,然后对每个字建立一个数字索引。如:字典包含5 000个常用字,字典的格式为{‘基’:1,‘本’:2,‘指’:3,‘挥’:4,…,‘所’:5 000}。
字向量矩阵可以用开源的word2vec[9]工具训练得到。字向量是字的数值向量形式,每个数值均有固定的维度,在训练过程中可以自行设定,根据语料规模可以设定为50~1 000维,每个维度表示一个特征,维度影响模型的精度。字向量矩阵也可以随机初始化,视其为一组参数在模型训练过程中自动进行调优,进而得到所需的字向量矩阵。
2.2 军事命名实体标注
实体标注是对文本序列中的每个元素标注一个标签,文本序列一般以句子为单位,元素是句子中的每个词。结合军事命名实体识别的军事需求,预定义8类军事命名实体,分别是部队、机构、时间、地名、武器、设施、环境和数量[12]。针对嵌套、组合和多重实体,构建军事命名实体标注规则[13]。如:“第1机步师指挥所”既含有部队,又含有机构,作为一个整体标注,应标注为机构;对于“第1集团军第2装甲旅炮兵营”类型的组合实体,不进行拆分或重复标注,应标注为一个实体部队;对于多重含义的实体,根据语境进行标注,如“飞机撞毁五角大楼”中的“五角大楼”应标注为地理位置,而“五角大楼发言人”中的“五角大楼”应标注为机构。针对军事命名实体专业术语多、歧义少的特征,采用更加简便高效的BIO标注方法。标注过程中采取人工和自动标注相结合的方式,首先人工对原始文本进行预处理,然后使用开源工具包YEDDA对文本进行标注并自动生成标签。BIO标注是对数据集中的每个字进行标注,即B用来表示命名实体的第1个字,I用来表示命名实体的内部和结尾字,O表示不是命名实体中的字符。实体标注方法如表1所示。
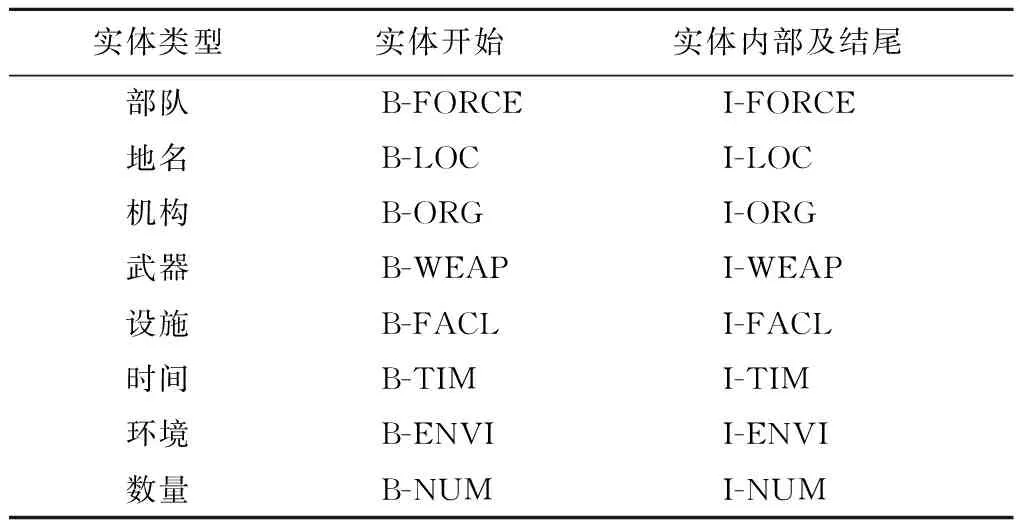
表1 实体标注方法
2.3 数据集划分
根据文本数据样本的数量选择训练集和测试集的比例,为提高模型的学习效果,可以加上验证集对模型进行优化。由于目前收集的军事文本数据样本有限,因此采取如表2、3所示的数据集划分方式。

表2 训练、验证、测试集划分方式

表3 训练、测试集划分方式
3 实验
为验证基于深度学习的军事命名实体识别方法的效果,笔者在军事想定数据集上进行实验。
3.1 实验环境及评价指标
实验环境如表4所示。实验采用准确率P、召回率R和F值3个指标对识别效果进行评价[14],其中,F值能够体现整体测试效果。3种评价指标的计算公式如下:

表4 实验环境
3.2 实验数据
实验数据来源于学员训练用的联合作战演习想定文档和指挥所演练想定文档等,选择想定30余份,约15.4万字、2 238句;选择其中的1 791句作为训练集,447句作为测试集,训练集占80%,测试集占20%;在增加验证集的情况下,训练集、验证集、测试集比例为7∶ 1.5∶ 1.5,各类标注实体在训练集、验证集和测试集中分布均匀[15]。
3.3 实验结果分析
3.3.1 不同方法对结果的影响
实验采取3种方法进行对比验证,其中包括本文提出的方法1和方法2:方法1采用随机初始化的字向量矩阵,采用Bi-LSTM神经网络进行特征提取,采用CRF作为分类器;方法2采用预训练的字向量矩阵,并增加验证集,其他与方法1相同。方法3采用单赫源等[3]提出的方法,在相同的语料和实体分类的情况下进行实验,并与基于深度学习的方法进行对比。3种方法测试结果如表5所示。

表5 3种方法测试结果
由表5可知:方法2比方法1识别效果好,说明根据相应语料预训练的字向量比随机初始化的字向量更能表达字(词)之间的语义关系;方法1和方法2比方法3识别效果好,说明基于深度学习的模型比CRF模型能学到更多的文本特征。这是由于人工选取军事文本数据特征有一定的局限性,一方面难以穷尽所有特征,另一方面特征之间可能会有重叠或矛盾的地方,基于深度学习模型通过自动逐层学习文本特征解决了以上问题。
3.3.2 不同超参数设置对结果的影响
为降低训练时间和计算成本,选取方法1在不同字向量维度下进行测试,维度设置在50~600,测试结果如图2所示。可以看出:当维度在50~250之间增加时,P、R、F值快速上升;当维度在250~500之间增加时,P、R、F值缓慢上升,并在维度为500时达到最大;当维度大于500时,P、R、F值随维度增加而趋于稳定。实验结果表明:字向量维度并不是越大越好,在语料规模保持不变的情况下,一定的维度能够表示文本的语义特征,通常情况下,字向量维度设置在250~500比较合理。
3.3.3 语料规模对结果的影响
为检验语料规模对深度学习实验效果的影响,随机选取方法1在不同语料规模下进行实验,语料的数量为0.7~15万字,实验结果如图3所示。可以看出:P、R、F值随着语料数量的增大而增大,说明实体识别效果随着语料规模的增大而增强,这也证明基于深度的学习方法对数据量要求较高。
4 结论
针对传统军事命名实体识别方法存在人工构建特征不充分、军事领域中文分词不准确的问题,笔者提出了基于深度学习的军事命名实体识别方法,并采用军事想定数据集进行实验验证。结果表明:与其他方法相比,该方法的准确率、召回率、F值更高,泛化能力和鲁棒性更强,有效弥补了传统方法的不足,是军事命名实体识别的理想方法。当然,目前由于受到数据规模、计算能力以及成本的限制,仍然需要综合运用多种方法来提升识别效果[15],未来随着迁移学习、无监督学习技术的深入发展,必将在较小数据规模和较少标注的情况下取得更好的识别效果。
