基于最小传播误差的室内定位方法研究
2018-10-18周雪松
周雪松
(江苏自动化研究所,江苏 连云港 222061)
目前,位置感知已经成为许多无线网络应用的一个重要特征,包括位置跟踪、映射、定位路由、覆盖管理、协同信号处理等[1-2]。例如,基于位置的路由协议,路由和数据转发都是基于地理位置的。如果节点的位置能够更精确地定位,网络的数据传输将会更加有效。
然而,由于成本和能量限制,并非所有节点都可能具有可靠的位置信息源,例如GPS接收器。需要与卫星时钟精确同步的每个节点的GPS解决方案都不适合大规模无线网络[3]。 因此,位置系统通常通过全球定位系统(GPS)或人工布局将一些信息分布到网络中的其他地方,然后通过计算节点的阳极位置来计算其通信范围,并在邻域有足够的锚节点[4]。
在大多数情况下,领域没有足够的锚节点。当锚节点数量较少时,例如平均少于三个通信范围内的锚节点时,传统方法无法正常工作[5-6]。在实际应用中,由于项目成本,可用于支持室内定位的节点数量并不多。因此,当少量锚节点存在时,需要一种室内定位方法。本文提供了一种新的位置方法来估计位置,通过选择最小估计误差传播的有用邻居(锚节点和正规节点)。考虑到这些节点的移动性,算法可以动态地利用节点记录的信息,而不需要过度交换数据或算法信息。根据所选择的位置和来自邻居的误差估计信息,新到达节点可以计算自己的位置和误差估计信息并将其广播到具有较少锚节点的邻域。
1 传统最大似然估计方法
当通信范围内的锚节点的数量大于2时,可以使用最大似然估计(MLE)的方法来估计该未知节点的位置。 具体程序如下。
假设有n(n>2)个锚节点,坐标依次为(x1,y1),(x2,y2),…(xn,yn), 它们到未知节点P(x,y)的距离是d1,d2,…dn,于是,我们有等式:
(1)
从第一个等式开始,每个等式都减去最后一个等式,得到等式:
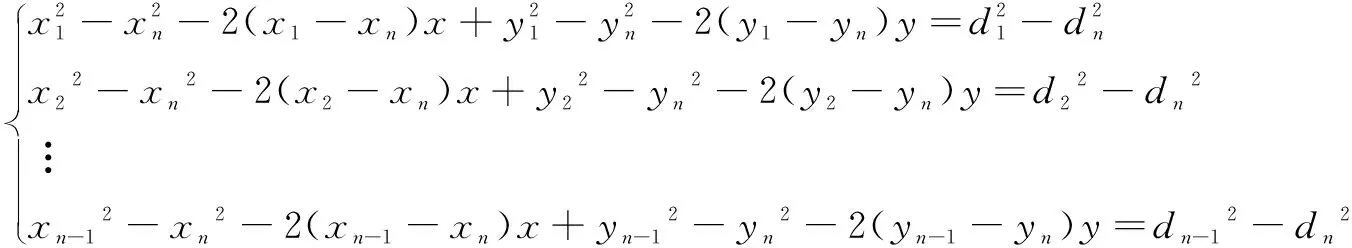
(2)
可以使用矩阵表达式AX=b表示,其中:
(3)

(4)

(5)
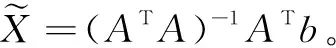
当n=3时,定位常用的另外一种方法是最大似然估计的三边法。
另一种常见的方法是n=3的MLE例子。然而,在最大似然估计方法仅仅当锚节点数量小于3时才能够工作。当锚节点的数量不足或分布不均匀时,传统的最大似然估计法无法工作。
2 基于误差估计的最小化误差传播定位方法
本文提出一种新的定位方法,它通过选择有用的邻节点并以最小误差的原则来估算位置。依据本文的一个实例,提供一种定位算法,包括收集每个邻居节点的位置信息;测量待定位节点和每个邻居节点之间的距离,并估计误差;根据邻居节点的位置信息,选择具有最小传播估计误差的节点;利用选择好的邻居节点的位置和距离,来计算位置并估计误差。本文提出了当已知的锚节点数量受限时的一种定位新方法。新节点将根据它和邻居节点的传播误差最小原理,来计算它位置。

图1 基于传播误差最小原理的锚节点数量受限时的定位流程图
第一步:收集每个邻居节点的位置信息
开始的时候,该节点发送MEPLE定位请求,相邻节点将返回它们的位置信息(如图2所示)。此位置信息包括:估计的位置坐标(x,y)和这些坐标的估计误差(σx,σy)。这里,对于每个锚节点来说,坐标估计误差为零。而对于尚未执行MEPLE计算的节点,位置信息被设置为NULL。
图2 从邻居节点收集位置信息
第二步:测量和每个邻居节点之间的距离,并估计计算误差
许多测量距离的技术已经被提出,如到来角(AOA)方法,到达时间方法(TOA),到达时间差方法(TDOA)和接收信号强度方法(RSSI)等技术。这里,我们取RSSI方法作为例子来说明该步骤。首先,节点将测量每个邻居节点k的RSSI值RSSIk;然后,该节点使用距离和功率之间的映射公式来计算估计距离。
Pr(dBm)=A-10·n·lgr
(6)
然后我们有
d=ρ(RSSIk)=10(A-RSSIk)/(10·n)
(7)
其中A是在1米距离时收到信号强度,d是距离发送者的长度,n为信号传播常量,也叫传播指数。同时,这里有一个距离d的估计误差,假设它的测量误差为σ(RSSIk),我们就可以由统计信息得到这个值。
第三步:从邻居节点的位置信息中,选择具有最小传播估计误差的节点
当收集并计算来自邻居节点的位置信息(x,y,d,σx,σy,σd)后,在所有的邻居节点中,选择一个具有最小估计传播误差的邻居节点对Pair(i,j)。具体而言,我们选择的邻居节点对满足:
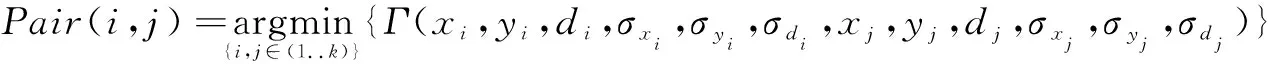
(8)
其中Γ函数定义为:
Γ(xi,yi,di,σxi,σyi,σdi,xj,yj,dj,σxj,σyj,σdj)=σ2=
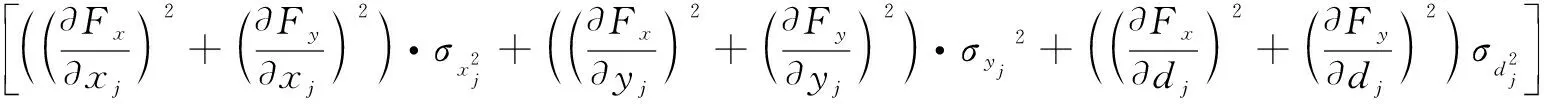
(9)
函数Γ的具体计算和理论分析如下:
位置估计误差(σx,σy)可以通过如下计算:

(10)
方差估计σ定义为:
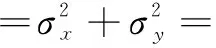
(11)
从方程中,我们可以看到,定位的估计误差(σx,σy)来自三部分组成,具体到一个邻居节点i(xi,yi,di):
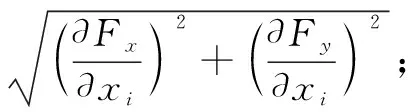
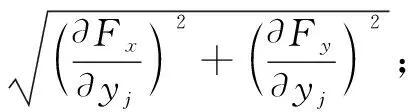
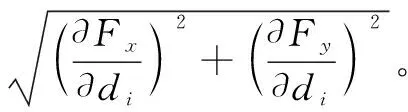
现在,我们将解释如何计算这些影响因素:
我们有两个邻居的定位信息,那就是:
(12)
将以上公式对x进行偏微分,我们可以得到:
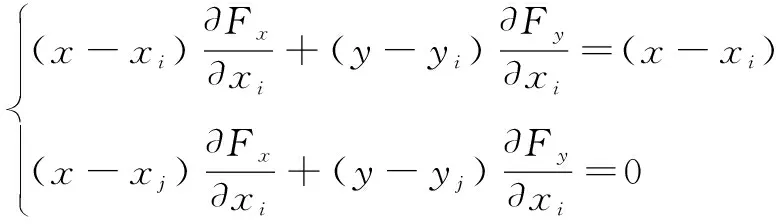
(13)
求解该方程,我们可以得到:
(14)
用同样的方法,取y和d的偏微分方程,分别可得:
(15)

(16)
现在,我们给出函数Γ(xi,yi,di,σxi,σyi,σdi,xj,yj,dj,σxj,σyj,σdj)的定义。并利用此函数来选择邻居节点对(i,j),以使给需要计算位置的节点(x,y)带来最小估计误差。
Γ(xi,yi,di,σxi,σyi,σdi,xj,yj,dj,σxj,σyj,σdj)=σ2=
(17)
最后,我们使用选定的邻居节点对(xi,yi,di)和(xj,yj,dj)作为数据源,来计算方程组:

(18)
并且使用第三个邻居节点,来判断唯一的节点坐标(x,y)。
而这个节点(x,y)的估计误差(σx,σy)为:
(19)
因此,新节点的位置信息是x,y,σx,σy。
第四步 利用选择好的邻居节点的位置信息和距离,来计算位置和估计误差
在第三步中,我们已经选择好邻居节点对Pair(i,j)。使用此节点序列对的定位信息,可以计算出一个新节点的估计位置和估计误差。
我们仍然在这里使用的RSSI距离测量方法,如图3所示。
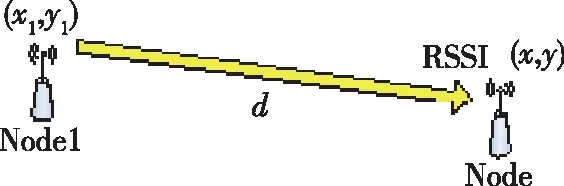
图3 基于RSSI的距离估计
(20)
其中,
(21)
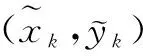
解方程,我们可以得到两个对称的节点的位置,如图4所示。使用第三邻居节点的距离信息,我们可以识别,如图5所示,其中一个是真正的节点位置,简单表示为:
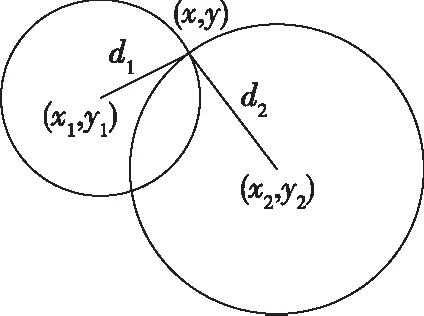
图4 基于两个相邻节点坐标的位置计算
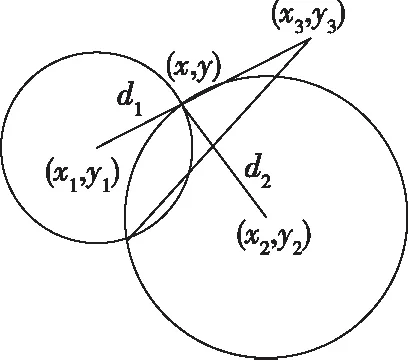
图5 基于第三节点的距离来识别位置
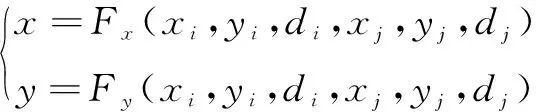
(22)
3 仿真计算
本节给出一些性能评估,以比较提出的MEPLE解决方案与传统的MLE方法。仿真在100个独立随机生成的图上运行,如图6所示。
图6 100个节点随机分布在100 m*100 m的区域中
图7说明了现有MLE方法和MEPLE方法中常规节点的平均位置误差(以米为单位)。据观察,估计误差与锚节点的数量成反比增长。 当锚节点数量较少时,如10~20之间时,MEPLE的性能优于MLE,平均估计误差减少50~80%,平均估计误差小于5 m。 随着锚节点数量增加到30个以上,MLE算法可以与所提出的MEPLE算法密切相关。 这是因为在传输范围内,将会有更多的附近锚节点可用于MLE计算。 在大多数情况下,这些锚节点与MEPLE方法选择的节点相同,因此性能差异很小。
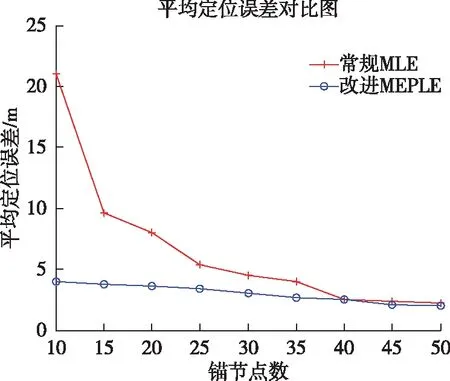
图7 平均位置误差
每个常规节点的位置估计误差的累积分布函数(CDF)曲线如图8所示。这里,总节点的10%被设置为锚节点。从图中可以看出,采用MEPLE方法,对于80%以上的用户,位置估计误差小于5 m; 而对于MLE,只有60%的用户估算误差低于5 m。 对于MEPLE,最大估计误差为22 m,只有4%的用户误差超过10 m; 对于MLE,20%的用户误差超过10 m,大约10%的用户由于附近缺乏锚节点而无法计算其位置。
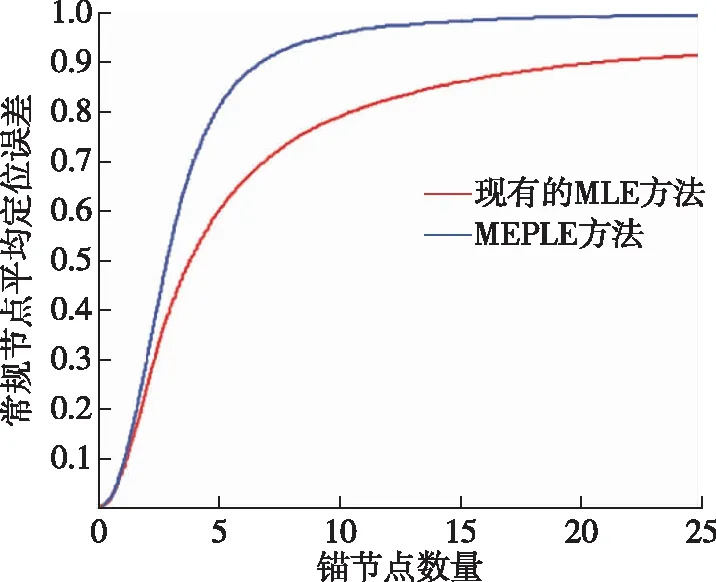
图8 累积分布函数(CDF)定位估计误差
4 结束语
为了估计未知节点的位置,本文描述了MLE的当前方法。提出了一种利用MEPLE选择有价值邻居(锚节点和规则节点)估计位置的新方法。 根据仿真结果,MEPLE总体上优于MLE,尤其是当锚节点数量较少(如10到20)时,MEPLE平均可以减少50-80%的估计误差。 未来的工作将会采用MEPLE实验方法进行研究。
