基于栈式自动编码机的语音质量评价方法
2018-10-17杨明极张贵山
杨明极,张贵山
(哈尔滨理工大学 测控技术与通信工程学院,哈尔滨 150080)
1 引 言
语音作为信息传递的重要载体,与其相关构成的通信、处理、存储和编码等语音系统已成为人们信息交流中不可或缺的一部分,且已广泛应用于社会各个领域[1].将语音系统作为通信媒介,其性能优劣直接决定了信息交流是否通畅,而输出的语音质量好坏是评价系统整体性能的关键因素,因此如何有效的对语音质量进行评价是本文研究的重点.
已有文献[2-6]提出了一些对语音质量进行评价的方法.文献[2]为2004年国际电信联盟提出的ITU-T P.563,这是第一个被标准化的无参考语音质量评价方法.文献[3]提出了一种基于无线链路参数的GSM网络语音质量客观评估方法,该方法采用多元回归与主成分分析相结合的建模方法,可以较精准的评价GSM网络中的语音质量.文献[4]中N. Parmar等人将MFCC特征与RPS特征结合起来,用GMM模型作为映射模型,提出了一种只基于输出语音的质量评价方法.文献[5]中RK Dubey等人提出利用听觉特征和MRAM特征作为无参考语音质量评价算法的输入特征.文献[6]中M. Narwaria等人提出了一种基于深度学习的语音质量评价算法.该算法中将能反映人耳特征参数的梅尔频率谱倒数(MFCC)输入到支持向量回归机(SVR)中,直接得到与主观评价相关的分数.尽管上述研究已经取得了良好的研究成果,但是与主观评价的相关性仍然亟待提高.
本文针对现有无参考语音质量评价算法与主观分数相关性不高的缺点以及无法满足应用需求的情况,提出用栈式自动编码机和传统的BP神经网络相结合进行解决.
2 基于栈式自动编码机的语音质量评价方法(SAE-BP)
文中提出的语音质量评价系统训练、测试过程如图 1所示,首先对输入的语音数据进行分帧、取对数功率谱特征等处理,随后将其输入到栈式自动编码机模型中,通过不断调整权值与偏置对栈式编码机进行训练.最后用训练好的栈式自动编码机获取能反应语音本质的特征,将其与相对应的主观MOS分数输入到BP神经网络中进行训练,得到本文所需的语音特征映射到主观分数的网络模型.
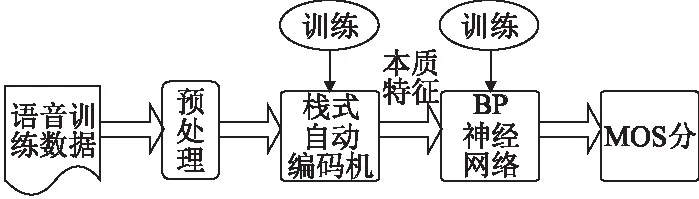
图1 语音质量评价系统训练、测试框架图Fig.1 Evaluation system of speech quality
文中方法主要基于栈式自动编码机和BP神经网络去实现,下面介绍本文所使用的算法.
2.1 栈式自动编码机模型
自动编码机(AE)是是一种尽可能恢复输入层数据的神经网络,主要利用人工神经网络中层次网络的特点[7].假设指定一个神经网络,通过不断调整权值与偏置使其输出与输入结果相同,这样就可以在隐藏层得到输入的另一种表示,这些表示就是特征(representation)[8].栈式自动编码机(SAE)是一个由多个单层自动编码机组合的深度神经网络,其前一层自编码机的输出作为后一层自编码机的输入.栈式自编码神经网络的编程过程就是按照从前向后的顺序执行每一层自编码机.同理,栈式自动编码机的解码过程就是,按照从后往前的顺序执行每一层自编码机的解码[9].
下面介绍自动编码机的编码、解码过程以及重构误差:
1) 式(1)为自动编码机的编码函数,其中x为本文给定的预处理之后的语音对数功率谱特征数据,y为隐藏层的向量,W和b分别为权重矩阵和偏置向量:
y=fn(x)=s(Wx+b)
(1)
为了避免少数样本被"覆盖"并提高其权重,本文对映射函数进行了改进:
y=fθ(x)=s({W⎣x+F(x,cj)」+b)
(2)
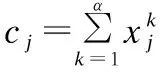
2) 式(3)为自动编码机的解码函数,将隐藏层的表示y作为输入得到输出层表示z,其中θ′={W′,b′}:
z=gθ′(y)=s(W′y+b′)
(3)
3) 损失函数:从上述步骤1和步骤2可知,每一个输入向量x(i)都将映射得到一个与之对应的重构向量z(i)和隐含向量y(i).其中θ和θ′的最优解应使均方误差最小,其表达式如式(4)所示:

(4)
式(4)中损失函数L取为Bernoullis分布(Bx)的距离,以此来更好的表达x和z的离散拓扑结构:
(5)
如果x是一个二元向量,LH(x,z)是x的负对数似然函数.栈式自动编码机就是将叠加的AE逐层进行训练,在最后一层得到所需特征的深度神经网络[11],其构建和训练过程可分为2个步骤:
1) 构建:根据提取语音本质的特征这一要求构建栈式自动编码机,确定所用的单层自动编码机个数以及初始化权重.

图2 自动编码机结构图Fig.2 Architecture of an autoencoder
2) 训练:图2为单层自动编码机的原理图,本文选用图3所示的两个AE进行叠加的栈式自动编码机进行后续实验.首先将预处理的语音特征x输入到自动编码机中,通过训练第一层AE来学习第一层的特征h;将训练的得到的语音特征h输入到第二个AE中,最后得到本文所需的能够反应语音本质的特征[12].
栈式自动编码机主要是提取能够表征语音质量的特征,还不能使主观MOS分与其特征相对应.因此需要添加映射模型,本文使用BP神经网络作为映射模型.

图3 栈式自动编码机结构图Fig.3 Architecture of an stacked autoencoder
2.2 BP神经网模型
由于语音特征和主观评价MOS分之间的映射模型为多元非线性的,难以准确地应用常规数学知识进行建模,因此本文通过BP神经网络来表示这种多元非线性.BP神经网络是一种采用反向传播误差方法进行训练的多层前馈网络.此外它由大量神经元连接构成来模仿人体大脑的神经网络,具有转移、加权与求和等功能[13].
语音特征映射到主观评价MOS分的BP神经网络训练步骤如下:
2.2.1 初始化神经网络
根据系统输入矩阵(x1,x2)采用SAE提取的语音本质特征和和主观MOS分数二维矩阵作为输入层神经元,确定隐含层节点数,给定学习速率,确定隐含层激励函数:
(6)
2.2.2 隐藏层映射计算
根据公式(7)计算隐藏层神经元值,其中n为隐藏层节点个数,Wij为隐藏层和输入层间的权值,H是第n个隐藏层神经元值,q为神经元阈值.
(7)
2.2.3 输出层映射计算
根据公式(8)计算输出层神经元Yk,其中H为隐藏层神经元值,p为输出层神经元的个数,wjk和r分别为权值和神经元阈值.

(8)
2.2.4 计算误差
将Yk与实际的主观MOS分进行比较,计算误差ek:
ek=Yk-MOSscorek,k=1,2,…,p
(9)
2.2.5 更新权值
更新输入层和隐藏层通过上上述中的得到的ek,输出层和隐藏层权值分别为Wij和Wjk

(10)
2.2.6 阈值更新
根据步骤4中得到的误差ek来更新阈值:
(11)
得到语音特征和主观评价MOS分相映射的BP神经网络.
2.3 SAE-BP算法过程
本文结合栈式自动编码机和BP神经网络进行有效的语音质量评价,具体过程如下:
1) 利用语音数据库中所有训练样本依次对多个自动编码机进行学习.
2) 将多个AE组合成一个深度神经网络.
3) 利用学习到的栈式自动编码机提取本文系统所需的语音特征.
4) 将提取的特征以及主观分数输入到BP神经网络中进行训练.
3 仿真实验结果和分析
3.1 实验数据集
本文系统选用的是ITU-T P. Supplement-23 database语音库,语音库中包含原始语音,经过处理的失真语音以及对应的MOS分数,国际电信联盟提出的P.563就是利用该语音库进行无参考的语音质量评价.为了证明文中系统的有效性和评价语音质量的性能,因此选用的训练和测试语音库与ITU-T P.563标准是一致的.其中测试和训练所需的1328条语句是16kHz采样,16bits量化,长度为8s.每个失真语句都已经标明了主观MOS分值,分值范围是1~5分.本文选取90%语句作为训练数据,10%语句作为测试数据.
3.2 算法评定指标
语音质量评价系统性能采用相关系数(R)和均方误差(RMSE)两个指标进行评估.
根据公式(12)计算客观评价与主观评价间的相关系数:
(12)
式中:D(X)是主观MOS分数X的方差,D(Y)是客观MOS分数Y的方差,Cov(X,Y)是X和Y的协方差.R的值介于0~1之间,其值越接近1,说明客观语音质量评价越接近主观语音质量评价.
根据均方误差公式(13)来表征主观评价值和客观评价值相关系数的偏差程度:
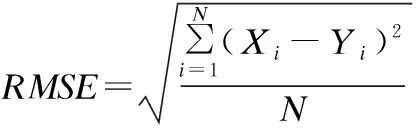
(13)
这里N是测试语句个数.
根据公式(14)和公式(15)来表征三种不同的客观评价算法的性能差异:
(14)

(15)
其中ΔR为本文算法相对于对比算法相关系数的增长率,▽RMSE为本文算法相对于对比算法均方误差的下降率,下标″proposed″为文中提出的算法,″compare″为P.563或者基于FSVM的语音质量评价算法[14].值为正,证明本文算法和对比算法相比提高了与主观质量评价的相关性,值为负,表明本文算法降低了与主观质量评价的相关性.
3.3 算法测试效果
本文应用栈式自动编码机提取更好表征语音本质的特征,学习率为0.1,训练次数500次.已有文献[15]中说明对于多层自动编码机,采用513维语音对数功率谱特征作为输入、第一个AE隐层单元数为250时更适用于语音特征的提取,因此本文选择上述栈式自动编码机用于后续实验.
针对本文语音质量评价系统,如何选取第二个AE隐层单元数尤为重要,因此文中进行了不同实验并进行了数据对比.图 4 描述了系统的相关系数和均方误差在不同隐层单元数下得到的结果.
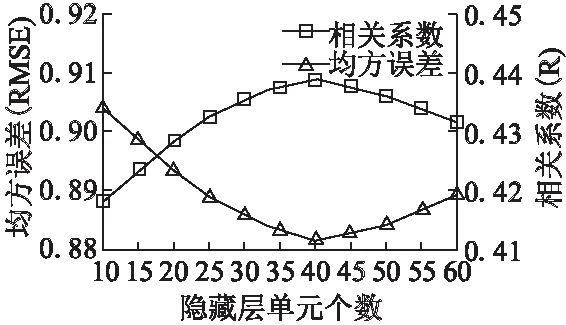
图4 隐层单元数对语音质量评价的影响Fig.4 Influence of the number of hidden layer elements on the evaluation of speech quality
由图4可知,语音质量评价模型的相关系数随着隐层单元数的增加而增加,且均方误差随之减少.当个数为40时,相关系数达到最高点,均方误差达到最低点,这是因为隐藏层太紧密和太稀疏都不能有效地表征语音特征.
3.4 结果分析
将栈式自动编码机提取的特征输入到训练好的BP神经网络中得到MOS分数.图5-图8分别是本文算法、基于FSVM算法、p.563算法和只基于BP神经网络得到的测试样本客观评价值与主观评价值的散点图.图中对角线由横纵坐标均为主观MOS分的点组成,而圆形的点是横坐标为主观MOS分值,纵坐标为客观MOS分值.
判断一种语音质量评价方法的优劣是看其与主观评价的相关度,相关度越高,该语音质量评价方法就越是理想.散点图中的对角线代表主观分数和客观评价分数完全一致的理想状态,数据点分布越靠近对角线,说明评价结果越接近主观评价.很明显,SAE和BP(图 5)相结合的方法较只基于BP神经网络的方法(图 8)有巨大的提升,验证了将栈式编码机应用到语音质量评价中有杰出的表现.此外,本文提出的方法(图 5)测试数据分数分布较已有的ITU-T P.563方法(图 7)


图5 本文算法性能(R=0.9089,RMSE=0.4115)Fig.5 Performance of the article图6 基于FSVM算法的性能(R=0.8427,RMSE=0.7250)Fig.6 Performance based on FSVM algorithm图7 P.563算法的性能(R= 0.6051,RMSE= 1.3214)Fig.7 Performance of P.563 algorithm
和基于FSVM方法(图 6)更接近对角线,说明文中方法具有更高的相关系数,较小的均方误差.图 9分别将三种方法下的得到的相关系数和均方误差进行了对比.


图8 基于BP算法的性能(R=0.4028,RMSE=1.4198)Fig.8 Performance based on BP algorithm图9 三种方法下性能对比Fig.9 Performance comparison under three methods
根据公式(14)和公式(15)可以计算出,相比于P.563语音质量评价方法,本文算法相关系数提高了76.93%,均方误差降低了68.86%;相比于基于FSVM的语音质量评价算法,本文算法相关系数提高了42.09%,均方误差降低了43.24%.实验结果表明,文中提出的方法在语音质量评价中具有较高的性能.
4 结 论
本文提出了一种栈式自动编码机和BP神经网络相结合的语音质量评价方法.首先将预处理的语音特征输入到栈式自动编码机中,提取更能表征语音的本质特征,随后将该特征输入到BP神经网络中,训练语音特征与主观评价MOS分之间的映射模型.仿真结果表明,本文提出的算法与已有的ITU-T P.563和基于FSVM(模糊支持向量机)的语音质量评价方法相比,降低了均方误差,与主观评价的相关系数有明显的提高,系统整体性能得到了极大的增强.同时也证实了栈式自动编码机在提出语音特征时有杰出的表现.
