基于数据级任务分解的大范围地质灾害预警并行计算架构设计与应用
2018-10-16李朝奎吴柏燕陈爱民
李 杨,李朝奎,方 军,吴柏燕,陈爱民
(1. 湖南科技大学 地理空间信息技术国家地方联合工程实验室,湖南 湘潭 411201;2. 湖南科技大学 地理空间信息湖南省工程实验室,湖南 湘潭 411201;3. 湘潭市地理空间信息应用工程技术研究中心,湖南 湘潭 411000)
0 引 言
社会经济的高速发展对自然环境的影响日益加剧,造成地质灾害频发。如何有效监测并预警地质灾害的发生、减少灾害对人类的损失是一项长期而艰巨的任务。一直以来,很多学者通过建立各种灾害预测模型来对地质灾害进行预警,比如文献[1]以模糊综合评判法和地质-气象耦合模型为基础对滑坡灾害进行预警;文献[2]初步建立了较为完善的地质灾害综合监测自动预警方法体系,实现了对不同灾害类型的自动预警。但上述地质灾害预警方法仅限于对单个地质灾害点进行灾变监测与分析预警,对于大范围地质灾害发生的情况,预警速度很慢,难以保证预警的时效性。采用并行计算的方法对大规模数据进行快速处理和计算,能有效提高地质灾害预警效率,但并行计算架构的构建却是一个较难解决的问题。首先,地质灾害预警所采用的数据是由多种监测仪器采集的多源数据,并行计算架构中对多源数据的存储和调用是需要解决的问题之一;其次,在地质灾害并行计算中需要使用到矢量空间数据和多源监测数据在计算节点间的通信[3],这又是需要解决的另一问题;再次,采用怎样的并行计算方法对计算任务分解能最大限度地达到提高预警效率的目的,同样是要思考的问题。
当前较为主流的并行计算框架有Hadoop MapReduce、Spark、Phoenix、Disco、Mars等,但这些并行计算框架的共同特点是需要搭建大型的并行计算平台,而高性能服务器较为昂贵,而且要进行适合多源数据的开发,过程较为复杂。相对于上述并行计算框架,采用基于消息传递机制(MPI)的并行计算方法可直接使用MPI提供的接口进行编程实现,使用普通的PC机即可完成并行计算环境的搭建,同时,使用Socket套接字来进行并行计算节点间矢量空间数据的传输,可避免MPI因信道拥堵而带来的通信故障,确保了本文倡导的地质灾害预警并行计算架构的可行性和稳定性。
从算法设计的角度分析,并行计算可分为数据级并行和任务级并行。数据级并行对计算对象进行分解,各线程操作相同,且相互独立;任务级并行则对计算任务进行分解,每个线程执行不同计算任务且依赖其他线程。地质灾害预警的计算目标是研究区内的地质灾害隐患点,地质灾害隐患点的潜在危险等级受其自身的岩土构成、水系、植被、地势起伏等因素影响,发生地质灾害的诱发因素包括降雨、地表位移、深部位移、土体含水率等。因此对每个地质灾害隐患点的预警相互独立且操作相同,在预警数据预处理的基础上,采用基于数据级任务分解的并行计算方法[4],以地质灾害隐患点为计算单元的子任务进行并行计算。
本文着重探讨了大范围地质灾害预警并行计算架构的设计与应用中的关键技术难题,包括:①搭建地质灾害预警并行计算架构;②解决并行计算架构中的关键技术问题,包括地质灾害预警模型、数据管理、任务监控与调度以及节点通信;③地质灾害预警并行计算架构实验验证。
1 并行计算架构设计
1.1 并行计算架构
根据层次结构划分,并行计算架构可以划分为四层,如图1所示。各层功能如下:
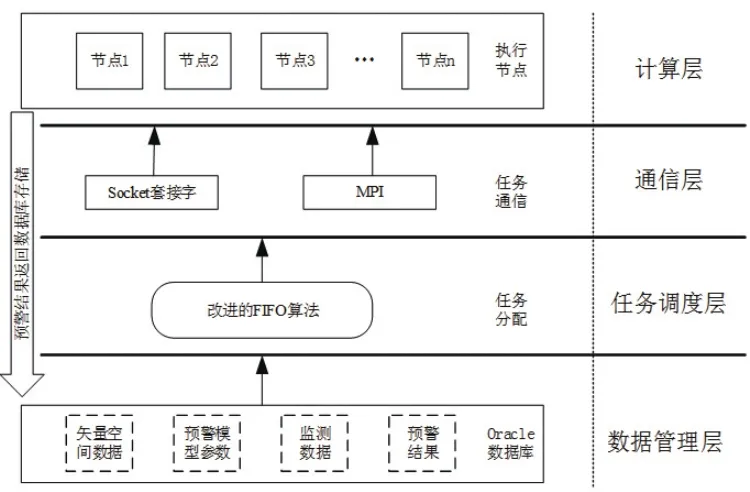
图1 并行计算架构图Fig.1 Parallel computing frame
1)数据管理层:矢量空间数据、预警模型相关配置参数、监测数据以及预警结果等均存储在Oracle数据库中,计算过程中的中间结果在Oracle数据库创建的临时表中进行存储。
2)任务调度层:是整个并行计算架构的核心部分,主要负责将任务分配到各计算节点上,达到负载均衡的目的。并行计算和传统的串行计算最大的区别就是并行计算需要考虑各计算节点的运行状态,计算任务在各个节点的分配以及计算结果的整合等。计算任务在任务提交管理器排队等待提交,等待集群资源空闲时才可提交计算任务[5]。
3)通信层:对于通讯量较小的算法输入参数等消息采用MPI进行通信,对于通讯量较大的空间矢量数据采用底层Socket管道进行快速文件传输[6]。
4)计算层:主要由并行地质灾害预警模型算法模块组成。各个节点分别部署一个并行地质灾害预警模型算法包。本部分是整个并行计算架构的核心内容,结合MPI多进程技术从底层研发,有效提升并行计算性能[7]。该地质灾害预警模型选取了潜势度算法和模糊综合评判法对地质灾害预警模型进行并行化封装,其目的是最大限度地提升地质灾害预警并行计算的效率。
1.2 并行计算的关键技术
本文提出的地质灾害预警并行计算架构以Oracle为数据库支撑,MPI和Socket套接字负责并行计算节点的通信减少人工控制通信的开发成本,并行计算架构的任务管理与调度采用优先队列式管理,通过Master节点监控集群工作状态,合理分配任务到各计算节点,实现负载均衡[8]。本文地质灾害预警并行计算架构中,计算任务读取由串行计算完成;自计算任务由数据级任务分解成子任务开始,直到各执行进程分别将计算结果传回Oracle数据库的各阶段计算工作均由并行计算完成。
1.2.1 地质灾害预警算法模型
地质灾害预警算法模型如图2子任务计算[9]部分,首先对预警数据进行预处理操作,剔除未返回监测数据的地质灾害隐患点,将有监测数据的地质灾害隐患点根据威胁人口数量的优先级进行排序,然后判断同一个地质灾害隐患点返回的监测指标种类,若返回的监测指标种类未超过两种则进入单指标预警模型,反之,则进入多指标预警模型对该地质灾害隐患点进行预警计算。
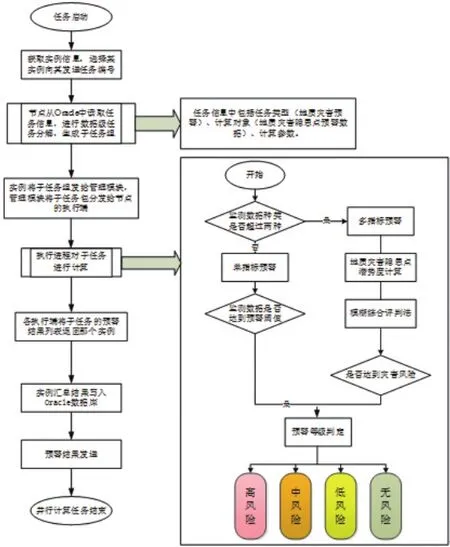
图2 地质灾害预警并行计算实现流程图Fig.2 Parallel computing of geological disaster early warning
1)单指标预警模型
单指标预警模型主要根据研究区内历史地质灾害的相关经验[10],对不同监测指标的各级预警设定一定的预警阈值,当该监测指标的数值达到某个预警阈值时则判定该地质灾害隐患点处于该级预警风险等级。
2)多指标预警模型
多指标预警模型主要采用地质灾害潜势度[11]和模糊综合评判法[12]作为算法依据。
首先,通过地质灾害潜势度计算各地质灾害隐患点的地质灾害风险等级,计算地质灾害潜势度的值(G)。
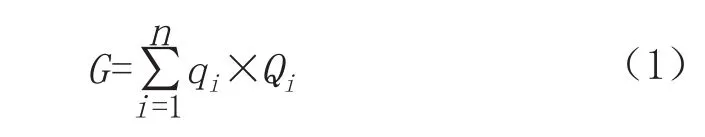
式(1)中,qi为各因子权重;Qi为因子定量值(CF值)
然后,将地质灾害风险等级作为地质灾害预警的评价因子之一,其他评价因子有降雨量,表面位移,深部位移,GNSS位移,含水率,泥位等。模糊评价集[12-15]分为高风险、中风险、低风险和无风险。该方法利用模糊数学的隶属度理论对收到若干因素影响的事物或对象做出了定量的总体评价,适合地质灾害预警分级这样的非确定性问题的解决[16-19]。
1.2.2 数据级任务分解
数据级任务分解是与任务级任务分解相对而言的,其特点是对计算对象进行分解,各线程操作相同,且相互独立。地质灾害预警的计算目标是研究区内的地质灾害隐患点。地质灾害隐患点的潜在危险等级受其自身的岩土构成、水系、植被、地势起伏等因素影响,发生地质灾害的诱发因素包括降雨、地表位移、深部位移、土体含水率等。因此对每个地质灾害隐患点的预警相互独立且操作相同,在预警数据预处理的基础上,以地质灾害隐患点为分析计算单元,采用基于数据级任务分解的并行计算方法,对并行计算任务作并行计算是行之有效的途径。
1.2.3 数据管理
地质灾害预警并行计算需要用到的数据包括矢量空间数据、监测数据、预警模型参数等,这些数据均存储在Master服务器的Oracle数据库中。在并行计算过程中,数据读操作远大于写操作,因此如何快速读取数据而避免数据库访问并发性问题是并行计算读取数据必须要解决的问题。为提高并行计算过程中数据访问效率,减少数据读操作等待时间,采用Oracle高级复制机制的过程级复制。当存在对数据进行大规模更新和批处理操作时采用这种复制方案[20],正好符合地质灾害预警并行计算时监测数据的大量读取操作。这个功能在大规模读写操作中非常实用,而且可以提高并行计算性能的稳定性和负载平衡。
1.2.4 任务监控与调度
地质灾害预警并行计算的任务调度由资源管理器和任务调度器组成[4],负责计算任务的提交、排队分发和状态监控。资源管理器负责实时获取子节点心跳信息,解析该节点的现状,包括内存、CPU占有率、硬盘资源等,根据资源管理器提供的监控结果,对计算任务进行分配,以做到合理利用资源保证并行计算效率。
任务调度器采用改进的FIFO算法[6],即在监测数据预处理的基础上,对计算任务内的地质灾害隐患点以威胁人口的数量从多到少的顺序进行任务提交。根据理论分析,可以通过改变任务执行顺序来实现负载平衡。本文改进的任务调度算法可抽象理解为以下几个步骤:①将地质灾害预警接受任务汇总到提交任务管理器;②对任务提交管理器中的任务使用调度算法,得到任务待提交队列;③资源管理器实时监控集群计算资源状况,当计算资源空闲且存在待提交计算任务,按照任务排序依次提交;当计算资源满载则暂停提交。
1.2.5 节点通信
消息传递接口(MPI)只适用于浮点型、字符型和整型3种数据类型,适合传递简单的输入参数或小型矩阵数组[7],一旦数据量过大很容易造成信道阻塞。本地质灾害预警并行计算架构中MPI主要负责启动地质灾害预警算法包和并行计算节点间小容量数据的通信[5]。
对于并行计算中较大容量的数据传输则直接利用Socket套接字进行通信,避免因MPI的信道阻塞[3]而带来的通信故障。
2 实验验证
2.1 并行环境搭建
搭建由4台普通PC机组成的集群,其中1台作为主控制节点(命名为Master),另外3台是工作节点(命名为Slave1--3),1Gbps高速交换机作为集群互联网络。试验集群的配置见表1。
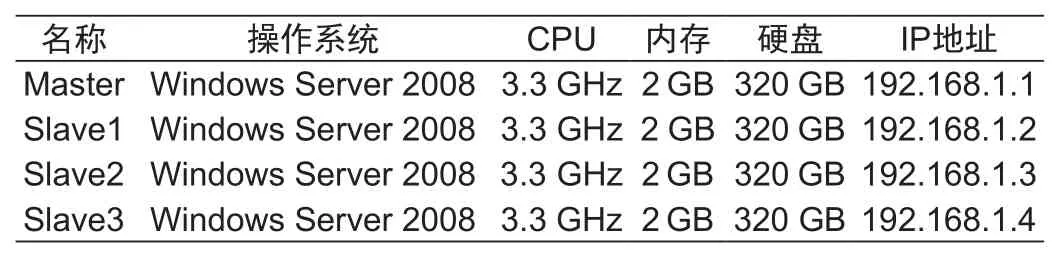
表1 集群配置表Tab.1 Conf i guration able of PC clusters
2.2 并行计算与结果分析
地质灾害并行计算实现流程如图2所示。为验证该地质灾害预警并行计算架构的实际计算能力,本文将该并行计算架构应用于某省2016年8月2~4日台风造成的大范围强降雨进行地质灾害预警工作。该测试算例包括2 657个地质灾害隐患点,监测数据共计达900多万条。并行计算环境如2.1节所述。通过使用不等数量的执行进程,依次对测试进行计算实验,计算结果见表2。
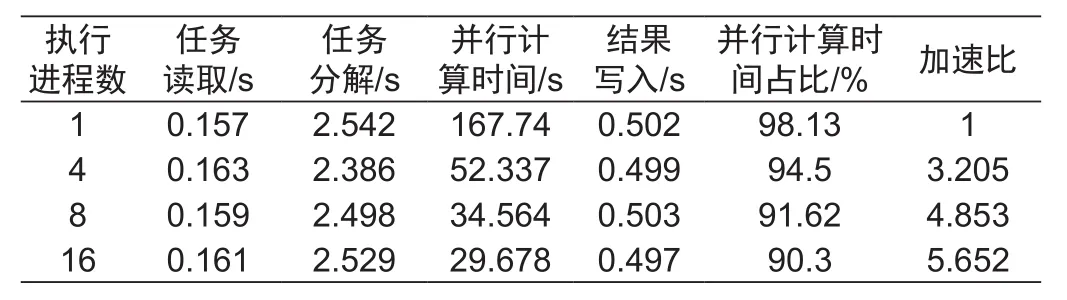
表2 地质灾害监测预警并行计算耗费时间Tab.2 Parallel computing time of geological disaster early warning
表2中:当进程数为1时,表示串行计算模式;当进程数为4、8、16时为并行计算模式。并行计算总耗时为任务读取时间、任务分解时间、子任务并行计算时间和通信时间相加之总和。本实验通过改变执行进程数量,测试不同进程数量并行计算所需要的时间。当运行一个执行进程时用时167.74 s,随着执行进程数量的增加,地质灾害预警并行计算总用时逐渐减少,当执行进程数量增加到16个时,计算时间为19.678s。此时,并行计算对地质灾害预警的计算用时得到了大幅缩减。并行计算耗时如图3所示。
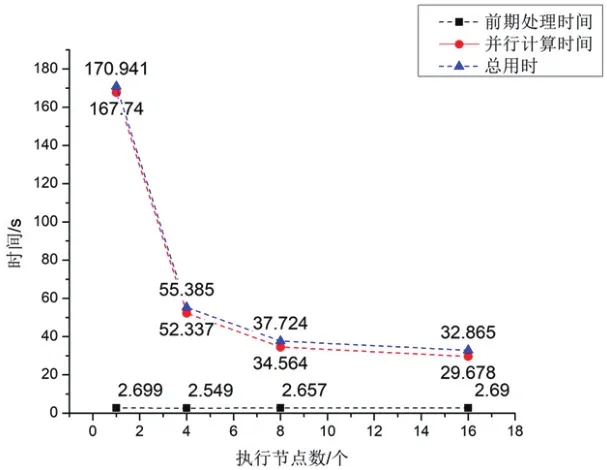
图3 并行计算耗时与节点数关系Fig.3 Relationship between the number of nodes and parallel computing cost time
以执行一个进程总的耗费时间作为地质灾害预警并行计算为基准[15],计算运行不同数量进程时的加速比,如图4所示。加速比随执行进程数目的增加而增大,但随着执行进程的增加,各个执行进程之间的通信时间增加,加速比曲线斜率逐渐减小。
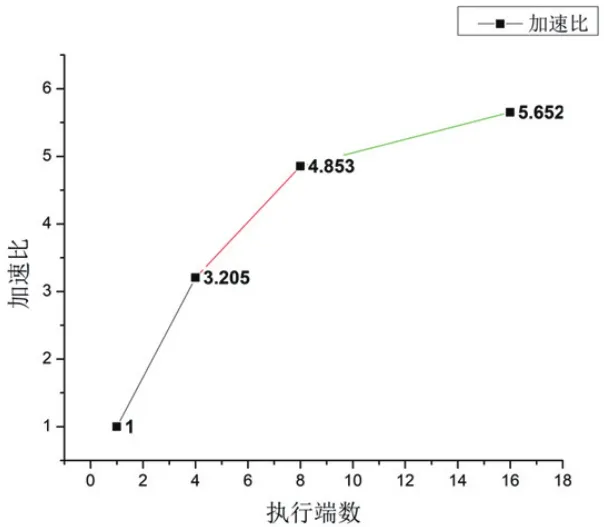
图4 并行加速比Fig.4 Parallel acceleration ratio
实验结果表明:
1)以地质灾害隐患点为单位对地质灾害预警计算进行数据级任务分解,启用多个执行进程进行并行计算可以大幅减少地质灾害预警的计算时间,能够获得一定的加速比。
2)本文提出的地质灾害预警并行计算架构可以进行大规模地质灾害隐患点预警的并行计算,满足地质灾害预警时效性的需求[16-20]。
3 结束语
采用数据级任务分解方法对地质灾害预警计算任务进行分解,设计了并行计算架构。将该并行计算架构应用于某省2016年8月2~4日台风造成的大范围强降雨进行地质灾害预警工作,得到如下结论:
1)采用Oracle高级复制机制极大地避免了并行计算过程中数据访问并发性问题。
2)采用改进的FIFO算法保证了并行计算的负载均衡。
3)使用消息传递接口(MPI)和Socket套接字分别对小容量的模型参数和大容量空间数据进行通信。
4)将本文设计的地质灾害预警并行计算架构应用到实际地质灾害预警工作中,取得了良好的效果,大幅缩短了大范围地质灾害预警所需的时间,满足了地质灾害实时预警的需要。
