一种微博POI签到数据的四叉树格网获取方法
2018-10-16许大璐杜清运李浪姣
黄 磊,许大璐,任 福,杜清运,李浪姣,张 琛
(1. 武汉大学 资源与环境科学学院,湖北 武汉 430079;2. 浙江省地理信息中心,浙江 杭州 310012)
0 引 言
如何快速高效地获取大规模签到数据是进行人类活动有关的数据分析和挖掘必须解决的问题。新浪微博作为我国最活跃的社交媒体平台之一,月活跃用户达3.13亿,日活跃用户为1.39亿[10]。庞大的新浪微博用户群体状态信息更新频繁,产生大量的活动信息。本文以抓取新浪微博兴趣点(Point of Interest, POI)签到数据为例,设计了一种四叉树动态格网抓取数据方法,由于新浪微博为了防止客户端的过度采集导致服务器资源的滥用,对返回的POI数量作了一定的限制,因此,本文在设计四叉树格网时对采集的POI数量设定了阈值,当某一格网内返回的POI数量达到阈值时,就采用四叉树分裂法动态分割当前格网递归获取数据,从而保证数据采集的完整性。与传统的规则格网的获取方式相比,四叉树格网在获取数据的完整性方面有明显的优势,从获取数据的结果分布来看,采用规则格网方式的数据缺失主要集中在高密度的POI地区,并没有将高密度区域的POI数据采集完毕,而采用四叉树方式能避免此问题。在现行的开放平台都对开发者作了相应限制的背景下,采用四叉树划分格网的方法对于获取完整的研究数据具有一定的实际作用。
1 常规的数据获取方式
目前常见的新浪微博数据获取主要有3种方式:通过网络爬虫的方式、调用新浪微博开放平台API的方式和将网络爬虫与微博API相结合的策略。
1.1 网络爬虫的数据获取
网络爬虫(Web Crawler)也称网络蜘蛛(Web Spider),是一种按照特定规则抓取网页信息的程序。抓取网页的过程,实际上和平时使用浏览器访问网页的原理是一样的。在浏览器地址栏输入某个网址之后,打开网页的过程其实是浏览器作为客户端,向服务器发送一个请求。经过DNS服务器,找到服务器主机,经服务器解析,将请求的资源返回给浏览器,浏览器最终将这些内容经过解析处理之后在页面上呈现给用户。目前,通过网络爬虫采集微博数据的技术应用较为广泛。主要通过采集用户的带有位置信息的微博,从中提取POI签到信息,统计各个POI的累计签到次数作为该POI总的签到次数,从而得到微博POI签到数据。文献[11]提出了基于模拟登陆的网络爬虫采集方案,解决了传统网络爬虫需要身份验证的问题。文献[12]开发了一款支持并行微博数据获取的应用,提供了一种基于广度优先搜索的算法来获取微博数据。文献[13]利用队列的思想实现了非递归爬虫,实现了大规模数据的快速高效获取。随着新浪微博的不断升级,反爬虫机制更加严格,该方法不仅受到的限制多,而且数据采集的范围有限、程序设计更加复杂、数据采集周期更长、数据处理难度大。
1.2 调用微博开放平台API的数据获取
开放平台(Open Platform)是指软件系统向第三方开发者提供应用程序编程接口(Application Programming Interface, API)或函数,使得开发者能够调用该系统的资源以实现满足自己需求的程序或增加该系统的功能,而不需要更改系统的源代码。2010年新浪推出了新浪微博开放平台,通过接入第三方合作伙伴的方式,向用户提供更加丰富的应用和完善的服务[14]。文献[15]通过调用API实现了某景区一年的微博数据采集。文献[16]以固定大小的格网调用微博API进行签到数据的获取。利用该方法采集POI数据会造成高密度区域的数据目标丢失,很难保证数据采集的完整性。文献[17]在数据采集过程中对高密度的数据区域采用更加精细的格网进行数据获取。此方法设计缺乏灵活性,难以满足大范围内的数据获取需求。
1.3 综合数据获取策略
由于新浪微博开放平台API对开发者访问次数的限制,大多数学者采用将网络爬虫与微博API相结合的策略采集微博数据[18-19]。通过这种综合策略的方式可以最大效率的采集微博数据,完成新浪微博API中由于权限等问题无法获取的数据。由于网络爬虫采集的微博POI信息与通过API方式采集的信息存在一定的差异,一般调用API方式返回的信息比网络爬虫方式丰富。因此,很难将两种方式采集的微博POI数据融合到一起。
从已有的研究可以看出,大多数采集方案并没有对研究区域进行处理,容易造成高密度数据区域目标丢失的问题。而随着新浪微博的不断升级,通过网络爬虫方式采集数据受到的限制逐渐增多,难以满足大范围内的海量POI数据采集。因此,本文提出一种四叉树动态格网的数据采集方法。能够避免由于API限制导致数据目标丢失的问题,最大程度地保证数据采集的完整性。
2 四叉树动态格网的数据获取
本文在分析了传统规则格网的数据获取方式所存在缺陷的基础上,采用了四叉树思想动态划分格网来获取数据,能够最大程度地保证数据采集的完整性,并兼顾了不同数据密度区域下的采集效率,适用于大范围内的微博POI签到数据采集。
今《全宋文》收有陈景沂文两篇,一是《全芳备祖序》,另一是《招隐寺玉蕊花记》,出《全芳备祖》前集卷六,见《全宋文》卷七九三○、第343册第292-293页,题目均为编者所加。由于所据版本的缺陷,两文与我们校点整理所得都有个别字词出入,此依其题,全文罗列如下。
2.1 基础格网划分
1)API参数说明
本文主要使用获取附近的地点等接口来采集微博POI数据,通过输入相应的参数,如经纬度、半径、返回的页数、每页记录数等,就可以获取到附近位置的微博POI签到数据。接口请求参数见表1。

表1 API请求参数说明Tab.1 The acquisition parameters of microblog API
由于新浪微博开放平台API提供的参数是某一半径的搜索圆,所以想要获取一定范围内的POI数据,需要根据半径参数对研究区域进行格网化处理,并保留合适的重叠范围,从而保证数据采集的完整性。
2)格网间距计算
合理的格网间距既要能够保证采集范围的有效重叠,又不能使得采集范围重叠过多导致大量的重复采集。如图1所示,采用搜索圆的内接矩形作为基本的格网单元,假定搜索圆的半径为r,那么格网边长为2r,格网点间距应小于等于2r,这样才能实现格网单元的有效重叠,避免某些区域数据目标的缺失。本文采用的搜索圆半径为2km、格网间距采用2.8 km。

图1 格网划分示意图Fig.1 The display of grid partition
3)格网点生成
首先利用ArcGIS的渔网工具对目标区域进行格网化处理,得到格网中心点坐标,以格网中心点作为数据坐标采集中心点来调用API获取全国范围内的POI数据。
2.2 数据采集
1)规则格网的数据获取
规则格网的数据获取首先通过读取坐标采集中心点经纬度,调用新浪微博开放平台相应的API,结合网页解析技术,从返回的数据中提取有价值的字段信息存储到数据库中,直到遍历完所有的坐标采集中心点为止。技术流程如图2所示。

图2 规则格网数据获取流程图Fig.2 The fl ow chart of data fetching based on regular grid
2)动态格网的数据获取
动态格网的数据获取首先采用类似规则格网的方式去调用API,检查当前格网内返回的POI总数,如果超过一定的阈值(200),则采用四叉树分裂法对该格网进行动态分割,分成4个小的格网递归获取数据。直到返回的数据小于设定的阈值时,表明当前格网内的POI数据采集完毕,否则继续动态分割格网。四叉树动态格网划分示意图如图3所示。
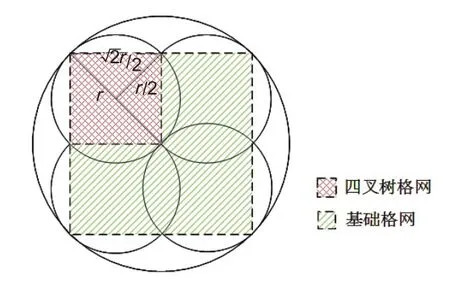
图3 四叉树动态格网划分示意图Fig.3 The display of quadtree dynamic grid partition
四叉树动态格网的数据获取技术流程如图4所示。

图4 四叉树动态格网的数据获取技术流程图Fig.4 Technical workf l ow of data fetching based dynamic quadtree grid
3 数据获取结果分析
为了最大程度保证数据获取的完整性,数据采集格网存在一定的重叠,因此,在数据采集完成之后需要对其进行分析并去掉冗余数据。调用API返回的数据格式为json格式,数据存储在MongoDB中,MongoDB是一种面向文档的,采用BSON的格式存储的数据库,可以对比较复杂的数据类型进行存储,对文档索引提供了十分广泛的支持,能够很好地解决这种大量的非结构化的微博POI数据的存储问题。
通过规则格网方式最终得到有效数据415 655条,而利用四叉树动态格网方式得到有效数据为1963 851条。两种数据获取方案的对比见表2。

表2 数据获取结果的对比Tab.2 The results of data acquisition
以北京市微博POI数据为例,按照一定经纬度或距离划分格网,统计单位格网内的POI总数,对比两种方式获取的数据结果的分布。规则格网的数据获取结果分布如图5所示,四叉树格网的数据获取结果如图6所示,规则格网相比于四叉树格网所缺失数据的分布如图7所示。

图5 规则格网的数据获取结果分布图Fig.5 The distribution of data acquisition based on regular grid

图6 四叉树数据获取结果分布图Fig.6 The distribution of data acquisition based on quadtree grid

图7 规则格网相较于四叉树格网缺失数据分布Fig.7 The distribution of missing data compared with regular grid to quadtree grid
从以上数据获取结果的分布可以看出,规则格网相较于四叉树格网所缺失的数据主要分布在内城区等POI比较密集的区域,如西城区、东城区、朝阳区、海定区、石景山区、丰台区等。其他像昌平区、顺义区、通州区等城中心区域缺失的也比较多。POI越密集区域,规则格网所造成的数据缺失越多。城郊地区本身POI相对较少,所以缺失的数据也相对较少。
下面以2 km、6 km、10 km半径去检索北京故宫博物院附近的POI数据,数据获取结果见表3。

表3 不同半径的检索结果对比Tab.3 The results of data acquisition based on diあerent radius
由此可以发现,在调用新浪微博API时,返回数据的最大值为200,所以通过规则格网的数据获取方式在高密度数据区域容易造成数据目标丢失的问题,难以保证数据采集的完整性。
通过前面的实验结果对比,四叉树动态格网的获取方式在获取数据的完整性上具有明显的优势,能够很好地适应大范围内的微博POI采集。另外,通过规则格网的方式获得同等规模的数据就需要将格网划分的足够小,此时就会导致在低密度数据区域的采集效率大大降低。而四叉树动态格网方式只会在高密度数据区域进行动态分割为更加细小的格网,因此,四叉树动态格网方式能够兼顾不同密度区域下的数据采集效率。为了规范API的使用,防止服务器资源被滥用,新浪微博API对返回的数据量有一定的限制,所以四叉树动态格网的获取方式能够最大程度地保证数据获取的完整性。事实上,目前主流的开放平台API都采取类似的措施从而防止API资源的滥用,如百度地图API、高德地图API等。
4 结束语
本文按照一定的经纬度将研究区域进行格网化处理,通过调用新浪微博开放平台API获取微博POI数据,由于该平台的限制,在POI数据密集区域采用四叉树动态格网获取数据,从而保证数据采集的完整性,能够适应大范围内的海量微博POI签到数据采集。与通过网络爬虫的方式相比,本方案具有程序设计简单、限制少、数据处理简单、数据质量高等特点,相同数据量下的采集周期更短。与传统的采用规则格网的方式相比,该方案很好地解决了高密度数据区域数据目标容易丢失的问题,能够最大程度地保证数据采集的完整性。利用四叉树思想动态划分格网的方法同样适用于其他开放平台的数据采集,如百度地图API、高德地图API等。
