基于Hadoop的海量车牌图像处理优化技术
2018-10-15侯向宁
侯向宁
(成都理工大学 工程技术学院,四川 乐山 614007)
0 引 言
面对海量的车牌数据,传统的基于终端的车牌识别系统受到很大的挑战。Hadoop云计算平台具有强大的海量数据分发、存储以及对大数据进行并行运算的能力,是大数据处理领域的首选。HDFS和MapReduce是Hadoop框架的核心,然而,HDFS设计的初衷是为了能够存储和分析大文件,并且在实际应用中取得好的效果,但却不适合处理大小在10 KB~1 MB的海量车牌图像小文件。这是因为HDFS集群下每一个小文件均占据一个Block,海量的小文件会消耗大量NameNode内存,另外,Hadoop会为每个文件启动一个Map任务来处理,大量的时间花费在启动和关闭Map任务上,从而严重降低了执行速率。因此,Hadoop在存储和处理海量小文件时,存储效率和性能会大幅下降。
文中在分析现有解决方案的基础上,利用CFIF将小文件打包分片,以解决HDFS在存储海量小文件时的瓶颈问题,以及MapReduce的执行效率问题。
1 HDFS小文件问题
HDFS(Hadoop distributed file system)[1-3]是用Java开发的能够运行在通用机器上的具有高容错性、高吞吐量的分布式文件系统。HDFS基于M/S模式,由一个NameNode节点和若干DataNode节点构成。NameNode是主控服务器,其职责是维护HDFS命名空间,协调客户端对文件的访问和操作,管理元数据并记录文件数据在每个DataNode节点上的位置和副本信息[4-6]。DataNode是数据存储节点,在NameNode的调度下,负责客户端的读写请求以及本节点的存储管理[7-8]。
1.1 问题描述
(1)NameNode内存瓶颈。
HDFS中所有元数据信息都存储在NameNode内存中。HDFS在设计时,每一个文件、文件夹和Block大约占150 Byte。假设HDFS集群中有100万个小文件,每一个小文件均占据一个Block,就至少需要3G内存[9]。所以,海量的小文件会占用大量NameNode内存,造成NameNode内存的严重浪费,极大限制了集群中文件数量的规模,成为HDFS文件系统的一大瓶颈。
(2)数据访问效率低。
在M/S模式下,所有的数据读写请求大都要经过NameNode,当存储海量小文件时,NameNode会频繁地接受大量地址请求和处理数据块的分配。此外,海量小文件一般分储于不同的DataNode上,访问时要不断地从一个DataNode切换到另一个DataNode,严重影响了访问效率和性能[10-11]。此外,客户端在读取海量小文件时,需要与NameNode节点频繁通信,极大降低了元数据节点的I/O性能。最后,读取海量小文件时,由于小文件存储空间连续性不足,HDFS顺序式文件访问的优势难以发挥。
(3)MapReduce运行效率低。
Hadoop处理海量小文件时,会为每一个小文件启动一个Map任务,因此,大量时间浪费在Map任务的启动和关闭上,严重降低了执行速率。
1.2 现有解决方案
处理小文件一直是Hadoop的一大难题。目前,解决问题的常见方案大致有:Hadoop Archives方案、Sequence File方案、MapFile方案和HBase方案[11-13]。
Hadoop Archives即HAR,是Hadoop系统自带的一种解决方案[14]。其原理是先把文件打包,然后做上标记以便查询。HAR的缺点是两级索引增加了系统搜索和处理文件的时间,HAR没有对文件进行合并,文件的数量没有明显减少。这一方面会耗费NameNode内存,另一方面MapReduce要给每个小文件各启动一个Map任务,总的Map任务数并没有减少,因此在MapReduce上运行时效率很低。
Sequence File基于文件合并,它把多个小文件归并成一个大文件,通过减少文件数来减轻系统的内存消耗和性能。但是它没有设置索引方式,导致每次查找合并序列中的小文件都要从整个系统的磁盘中去查找,严重影响了系统的效率。
MapFile是排序后的Sequence File,MapFile由索引文件(Index)和数据文件(Data)两大部分构成。Index作为文件的数据索引,主要记录了每个小文件的键值,以及该小文件在大文件中的偏移位置。其缺点是当访问MapFile时,索引文件会被加载到内存,因此会消耗一部分内存来存储Index数据。
HBase以MapFile方式存储数据,通过文件合并与分解提高文件的存储效率[15]。其缺点主要是:HBase规定数据的最大长度是64 KB,因此不能存储大于64 KB的小文件。另外, HBase只支持字符串类型,要存储图像、音频、视频等类型还需用户做相关的处理。还有,随着文件数的增多,HBase需要进行大量的合并与分解操作,这样既占用系统资源又影响系统性能[13]。
总之,通过对以上常用方案的分析,发现都不适合解决海量车牌图像的存储与执行效率问题。因此,下节将采用另外一种方案来解决当前所面临的困境。
2 基于CFIF的海量车牌处理
Hadoop在新版本中引入了CombineFileInputFormat(简称CFIF)抽象类[16],其原理是利用CFIF将来自多个小文件的分片打包到一个大分片中,这种打包只是逻辑上的组合,让Map以为这些小文件来自同一分片,每个大分片只启动一个Map任务来执行,通过减少Map任务的启动数量,节省了频繁启动和关闭大量Map任务所带来的性能损失,提高了处理海量小文件的效率。另外,CFIF在将多个小文件分片打包到一个大分片时会充分考虑数据本地性,因此节省了数据在节点间传输所带来的时间开销。
CFIF只是一个抽象类,并没有具体的实现,需要自定义。文中利用CFIF处理海量车牌小文件,具体流程设计如图1所示。
由图1可知,要利用CFIF来实现海量车牌图像小文件的处理,需要做如下工作:
(1)设计Hadoop图像接口类,因为Hadoop没有提供图像处理接口,不能处理图像文件数据,因此必须自己定义。
(2)继承CFIF类,定义CombineImageInputFormat类将海量图像小文件打包成分片,作为MapReduce的输入格式。
(3)实现CombineImageRecordReader,它是CombineFileSplit的通用RecordReader,就是为来自不同文件的分片创建相对应的记录读取器,负责分片中文件的处理。因为Hadoop中已经提供了CombineFileSplit的实现,因此CombineFileSplit无须再设计。继承CombineImageRecordReader类,定义ImageRecordReader实现对CombineFileSplit分片中单个小文件记录的读取。
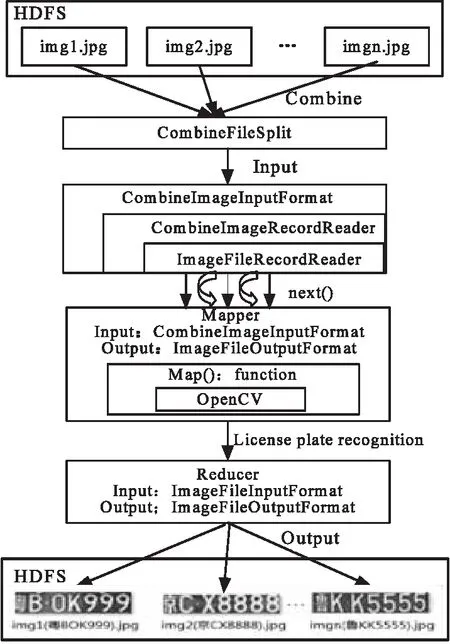
图1 海量车牌图像小文件处理流程
(4)配置MapReduce以实现对海量车牌图像的处理。
2.1 Hadoop图像接口类
Hadoop没有提供专用的图像接口,因此不能直接处理车牌图像数据。Hadoop的Writable接口定义了一种二进制输入流方法和一种二进制输出流方法,这两种方法可以实现数据的序列化和反序列化。因此,要处理图像数据,需要继承Writable接口,定义一个图像类接口Image类,并在Image类中重写Writable类的readFields和write两种方法,分别用于写入和读出图像的相关数据信息。经过设计的Image类图如图2所示。
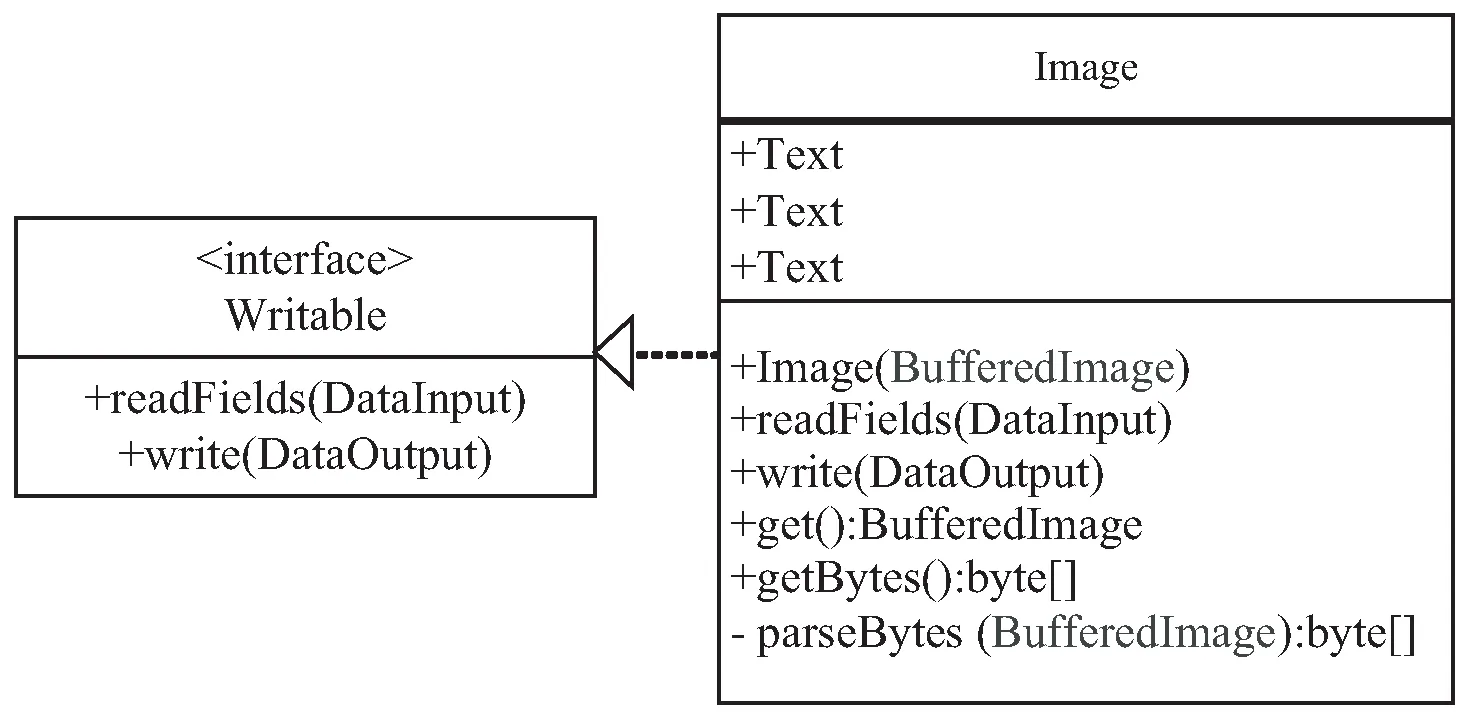
图2 Image类图
2.2 主要类的实现
CFIF作为Mapper的输入格式,将来自多个小文件的分片打包到一个大的输入分片中,因此需要从CFIF类继承一个CombineImageInputFormat类,并在CombineImageInputFormat类中创建CombineImageRecordReader。CombineFileRecordReader是针对CombineFileSplit的通用RecordReader,是为来自不同文件的分片创建相对应的记录读取器,负责分片中文件的处理,即读取CombineFileSplit中的文件Block并转化为
(1)CombineImageRecordReader类。
从RecordReader继承一个CombineImageRecordReader类,把CombineFileSplit中的每一个小文件分片转化为
CombineImageRecordReader extends RecordReader
CombineImageRecordReader(CombineFileSplit,split,TaskAttemptContext context,Integer index) {CombineFileSplit ThisSplit=split; //获取文件分片
//对缓冲区中的图像解码,img用作键值对的值
img=new Image(BufferedImage)};
//获取当前输入文件分片的路径,用作键值对的键
filePath=ThisSplit.getPath(index);}}
(2)CombineImageInputFormat类。
继承CFIF类,定义CombineImageInputFormat作为Mapper的图像输入格式,具体代码如下:
CombineImageInputFormat extends CFIF
//设置RecordReader为CombineImageRecordReader
RecordReader
return newCombineImageRecordReader
//不对单个图像文件分片
isSplitable(JobContext context,Path file){return false;}}
2.3 配置MapReduce
在Mapper阶段,从CombineImageRecordReader那里得到
在Reducer阶段,新key表示输出路径,其中图像文件以“原主文件名(车牌号).jpg”的形式命名,并把image特征图以新key为路径保存。
3 实 验
3.1 实验环境与实验方案
采用伪分布式搭建Hadoop云计算平台,该云计算平台由一个NameNode节点和三个DataNode节点组成。各节点的配置如表1所示,所需软件配置如表2所示。

表1 Hadoop集群节点配置

表2 软件配置
为了测试CFIF方式在内存消耗与运行时间方面的性能,特意设计两组对比实验,准备6组(1 000,2 000,3 000,4 000,5 000,6 000)车牌图像文件,在不同方案下,分别通过分布式环境运行每组等量的车牌识别任务。
(1)测试HDFS(即传统的单文件单Map任务)、Hadoop Archives(HAR)、MapFile(简称MF)及CFIF方案下,处理6组车牌图像文件的完成时间。
(2)测试HDFS、HAR、MF和CFIF四种方案下NameNode节点所占用的内存百分比。
3.2 实验结果与分析
两组实验的测试结果分别如图3、图4所示。
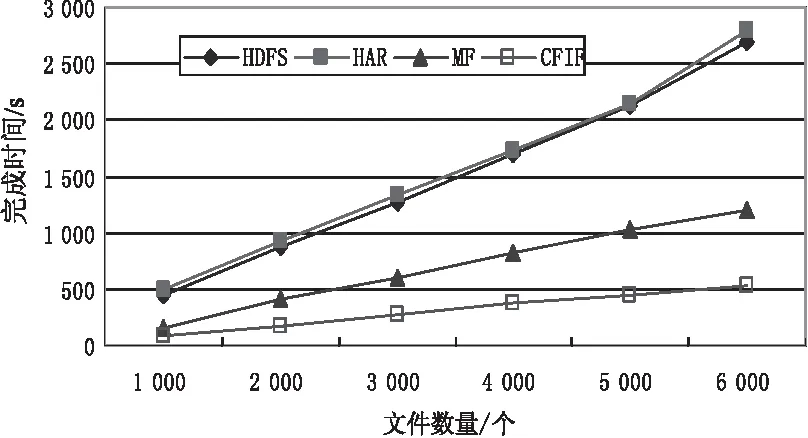
图3 完成时间对比
由图3可见,在运行效率方面,CFIF在四种方案中表现最好,原因在于CFIF方案把小文件分片打包成了大分片,减少了Map任务的数量,从而避免了频繁开启和关闭Map所带来的时间损耗。MapFile的处理效率稍逊于CFIF,原因是CFIF在将多个小文件的分片打包到一个大分片时,充分考虑了数据的本地性原则,即尽量将同一节点的小文件打包,因此节省了数据在节点间传输所带来的时间开销,而MF方案在合并文件时没有考虑这点。HAR与HDFS方案在运行效率上相当,虽然HAR将多个图像小文件打包作为MapReduce的输入,但HAR没有对文件进行合并,MapReduce还是给每个图像小文件各启动了一个Map任务,这并没有减少总的Map任务数,因此HAR并不比HDFS在运行效率上有效。

图4 NameNode内存占用率对比
由图4可见,在NameNode内存消耗方面,HAR、MF和CFIF远低于HDFS,这是因为HDFS集群下每一个小文件均占据一个Block,海量的小文件会消耗大量NameNode内存。从图中还可以看出,HAR、MF和CFIF的表现不相上下,原因是三者通过对文件打包及合并,减少了元数据所占用的NameNode内存空间,因此NameNode内存消耗不明显。
4 结束语
文中深入分析了Hadoop存储及处理海量小文件时所引发的性能问题,并对现有的几种解决方案的缺点进行了详细的分析。在此基础上,采用CFIF抽象类将多个小文件分片打包到大分片中,以减少Map任务的启动数量,从而提高处理海量小文件的效率。对CFIF抽象类给出了具体实现,并通过实验与常规HDFS、HAR和MF方案在NameNode内存空间和运行效率方面进行了对比。实验结果表明,CFIF在NameNode内存占用率和运行效率方面都有很好的表现。
