基于深度卷积神经网络的非法摊位检测
2018-10-15宋乐陶刘正熙熊运余
宋乐陶,刘正熙,熊运余
(四川大学计算机学院,成都 610065)
0 引言
随着城市现代化发展,越来越多的非法摆摊现象涌现出来,对城市环境秩序、居民的日常生活造成严重干扰,因此有必要有一种智能非法摊位检测算法,来对各类非法水果摊、小吃摊等进行智能识别检测,减少城市管理人员负担。非法摊位各式各样,是不同运输工具,不同货物的组合,因此采用传统机器学习目标检测的方法,很难刻画非法摊位的特征,效果很不理想。
相比于一些形态单一、刚性的物体,摊位则复杂许多:不同的摊位是不同载体,不同物体的组合体,更为复杂。传统的机器学习目标检测算法使用滑动窗口策略,一般包含三个步骤:设定不同大小的窗口,将窗口作为候选区,并不断在图片上滑动;利用手工设置的特征如行人识别的HOG(Histogram Orientation of Gradi⁃ent)特征[1]、人脸识别的 Haar特征[2],对候选区进行特征提取操作;利用特定的分类器如SVM(Support Vector Machine)[3]对特征进行分类,判断候选区是否包含目标及目标类别;最后将同一类别相交候选区合并,计算出每个类别的候选框,完成目标检测。
传统目标检测方法使用的特征是人为设计的特征,这种特征是非常低维度的特征,表达能力差,分类效果差,而且往往具有单一性,对特定物体的效果或许尚可,如使用HOG特征进行行人检测,对于复杂多样的物体检测效果则极差。
传统目标检测方法中,多尺度形变部件模型DPM(Deformable PartModel)最为出色[4],连续获得 VOC(Vi⁃sualObjectClass)2007到2009的检测冠军,DPM把一个物体看作不同部件所组成的,并通过部件之间的关系来描述一个物体,是HOG+SVM的升级,但是检测速度极慢,一度成为目标检测的瓶颈。为了自动提取高维度、高鲁棒性的特征,Hinton提出深度学习来自动提取高维度特征[5],相比传统手工设计的特征,这种特征有着更高的维度,更强的特征表达能力。随着发展,卷积神经网络通过多层卷积提取特征,在图像分类方面取得卓越成果。之后基于深度学习的目标检测框架R-CNN(Region-based ConvolutionalNeuralNetworks)不管在速度还是精度上都超越了传统方法[6],R-CNN是基于区域的卷积神经网络,首先在一张图片上提取约2000个建议框(Region Proposal),然后将这些建议框放入到卷积神经网络中进行训练得到特征,将得到的特征放入SVM分类器分类,最后将得到目标检测结果,达到 58%的 mAP(mean Average Precision),47 秒/张的速度。
这种基于建议框的目标检测方法引领了深度学习目标检测的潮流,为了解决需要对2000个建议框进行2000次卷积神经网络特征提取耗时的问题,进而出现SPP-NET[7]和 Fast R-CNN[8],相较于 R-CNN,Fast RCNN只对整张特征图进行一次卷积操作,然后对得到的特征图通过空间金字塔池化层映射为特征向量,最后通过全连接层进行分类、预测边框,以及边框修正。但是这种方法同样不能避免一开始先提取2000个建议框耗时的问题,Faster R-CNN[9]由FastR-CNN网络和 RPN(Region Proposal Network)两部分构成,使用RPN网络来提取高质量建议框,从而大大缩短了时间;提取的建议框再交由FastR-CNN进行目标分类,对候选建议框的修正,实现端到端(end-to-end)的训练,使用VGG16网络达到73%的mAP,5fps的检测速度。
本文实验使用基于Caffe框架的Faster R-CNN算法,对非法摊位进行智能检测。
1 卷积神经网络
1.1 卷积神经网络概述
1962年,生物学家Hubel和Wiesel过对猫脑视觉皮层进行研究,发现视觉皮层中一系列复杂的细胞,而不同的细胞对视觉输入的不同局部敏感,所以被称作感受野。并且这些视觉细胞有层次结构,由低级到高级,逐步理解。CNN也由此受启发,由不同的卷积核作为感受野,提取局部信息,由池化核来适应位移和形变,CNN在图像识别任务中取得良好分类效果。
卷积神经网络(CNN)是对普通 BP(Back Propaga⁃tion)神经网络的改进,与BP神经网络相同的是:都使用前向传播计算输出值,再通过反向传播调整模型中的权重和偏置;不同在于:卷积神经网络包含了由卷积层、池化层构成的特征提取器,卷积层通过卷积核来提取特征图,池化层则对提取到的特征图进行压缩,降低模型参数,提高训练速度以及模型的泛化能力,在图像识别方面有良好效果[10-13]。
卷积神经网络是一个层次结构,包含输入层、卷积层、池化层、全连接层、输出层,输入图像经多个卷积、池化层进行特征提取,逐渐提取出高维特征,最后提取到的高维特征经全连接层、输出层,输出一个一维向量,向量中每个元素是一个得分值/概率值,也即是该图像属于各个类别的概率。
在工业界中常用的网络有 LeNet-5、AlexNet、VGG16、ZFNET、ResNet等,本文所使用的网络结构基于小型网络ZFNET[14]、大型网络VGG16[15]。
1.2 卷积神经网络结构
卷积层是卷积神经网络最核心的部分,作用是通过卷积操作提取特征,卷积核通过对输入图片或上层特征图进行滑动窗口操作,逐一进行卷积。
如图1所示,卷积神经网络是一个层次结构,包含输入层、卷积层、池化层、全连接层和输出层,卷积神经网络输入是原始图像,卷积层利用卷积操作提取特征,假设i代表第i层卷积层,Li-1是前一层的特征图,Li是第i层卷积之后所得到的特征图,该层过程为:

其中Wi为第i层的权重向量,⊗代表卷积操作,第i层的权重与i-1层的特征图进行卷积操作,然后与第i层的偏移向量相加,最后通过非线性激励函数 f(x)得到第i层的特征图。通常第1层卷积层提取的是边缘、线条等低级特征,越高层的卷积核逐步提取更高级的特征。
激励函数的作用,是增加模型的非线性,目前CNN中常使用ReLU函数作为激励函数,相较于sigmoid、tanh函数,能够解决梯度爆炸、梯度消失等问题,同时能够加快收敛速度。ReLU函数如下:

图1 卷积神经网络典型结构

池化层在卷积层和激活函数之后,主要作用是对特征图降维,以使得训练加快,同时保证特征的尺度不变形,一定程度上避免过拟合,池化过程为:

常见的池化操作有最大池化、均值池化等,经多个卷积层、池化层交替,卷积神经网络逐步提取高维度特征。
经过多层卷积、池化处理后,会接一层或多层全连接层,全连接层中神经元与前一层所有神经元相连,旨在整合类别的局部信息,全连接层会根据输出层任务,有针对性的对高层特征进行映射。最后一层全连接层的输出值输入到输出层,输出层面向具体任务,例如用CNN来进行分类,那么输出层可以采用如Softmax层来进行分类,输出一个n维向量y=(y1,y2...yn)T,其中n为类别数,每个值代表相应类别的置信度。
2 Faster R-CNN摊位检测架构
2.1 网络参数初始化
在训练网络前,有一个重要的任务是如何对网络中权重参数进行初始化,神经网络的训练其实质就是不断调节权重参数和偏移参数的过程,有了这些参数就知道了每一层所代表的特征,如果一层中所有参数都相同,那么他们表征的特征就是相同的,即使在这层中有很多节点,其实和只有一个节点没有任何区别。如果每一层参数都是相同的,那么这个神经网络模型就退化为线性模型了。
最早有个貌似很合理的思想,是一开始把所有权重参数初始化为0,但是权重参数的更新规则为:

其中i表示是第i层,α表示学习率。
将参数初始化为0,导致前向传播时每一层的输出是相同的,反向传播时dW是相同的,进而每一层都是一样的,此时网络是完全对称的。
既然权重不能全部初始化为0,那么一种自然而然的思想就是把权重随机初始化为一些小的数,来打破对称性,这个思想是神经元一开始是独一无二的、随机的,它们会计算出不同的更新来调整整个网络,例如高斯初始化,它的权重矩阵如同:

其中randn是从均值为0的单位标准高斯分布进行取样,通过这个函数,使得权重参数初始化为一个从多维高斯分布取样的随机向量。
还有一些其他的参数初始化方法如均匀分布初始化、Xavier初始化、MSRA初始化。
2.2 迁移学习
神经网络需要通过训练数据来训练,从中获得相应信息并转化为权重。在实际应用中,通常没有太多的数据集用于训练,因此从头进行初始化训练网络并不好。在人类的文明中,上一代会将知识传授给下一代,下一代只需要在此基础上进行学习即可,而不需要从头开始,神经网络也借鉴这一思想,可以对已有的模型进行微调(fine-turn),来完成我们的自己任务,可以从别的模型中提取权重,并迁移到自己的任务上。
ImageNet数据集是一个大型数据集,包含1400万张图片,超过200万个类别,是目前深度学习领域应用的非常多的公开数据集。由于ImageNet数据集过大,所以有公开的已经在ImageNet数据集上训练得到的模型参数,本文以此作为预训练模型(pre-trainedmodel)用来对网络进行初始化。接下来fine-turn整个神经网络,替换掉输入层(图片数据),使用自己的实验数据集进行训练,可以对部分层进行微调,也可以对全部层进行微调,通常前面的层提取到的是图像的通用特征(如边缘特征、色彩特征),这些特征对许多任务都有用,因此只对后面的层进行调整。
与重新训练整个网络相比,使用迁移学习需要使用更小的学习率(本文实验使用的学习率learning rate为0.001,而训练ImageNet数据集使用的学习率为0.01),因为预训练模型的参数已经很平滑,我们不希望太快去扭曲它们。
2.3 Faster R-CNN检测流程
FastR-CNN解决了需要重复对建议区域进行特征提取,耗费大量时间的问题,此时目标检测速度的瓶颈在于依然要预先通过Selective Search等方法提取建议区域。Faster R-CNN提出区域生成网络RPN(Re⁃gion ProposalNetwork),把建议区域的生成糅合到卷积神经网络中,进一步提高了速度。
Faster R-CNN框架由两个模块组成:
(1)RPN模块用于生成建议区域
(2)FastR-CNN模块用于对RPN提取的建议区域识别目标
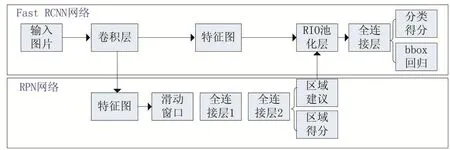
图2 Faster R-CNN检测架构
从R-CNN到Faster R-CNN,目标检测的四个步骤:候选区域生成、特征提取、分类、位置精修被融入到一个网络中,实现了端到端(end-to-end)训练。
2.4 训练过程
通过反向传播(BP,Back Propagation)和随机梯度下降(SGD,Stochastic Gradient Descent)进行端到端的训练。
(1)RPN网络预训练:
以ImageNet训练好的网络ZF/VGG-16来进行参数初始化,以标准差0.01均值0的高斯分布对新层进行随机初始化。
(2)FastR-CNN网络预训练:
以ImageNet训练好的网络ZF/VGG-16来进行参数初始化。
(3)RPN网络微调训练:
以与Ground Truth相交IoU最大的anchor以及IoU>=0.7的anchor作为正样本;以IoU<0.3的作为负样本,同FastR-CNN网络,采取“image-centric”方式采样,即层次采样,先对图像取样,再对anchors取样,同一图像的anchors共享计算和内存。每个mini-batch包含从一张图中随机提取的256个anchors,正负样本比例为1:1,来计算一个mini-batch的损失函数,如果一张图中不够128个正样本,拿负样本补凑齐。训练超参数选择:在数据集上前60k次迭代学习率为0.001,后20k次迭代学习率为0.0001;动量设置为0.9,权重衰减设置为0.0005。
一张图片多任务损失函数(分类损失+回归损失)如下:

其中,i表示一个mini-batch中某个anchor的下标,pi表示anchor i预测为物体的概率;当anchor为正样本时,,当anchor为负样本时,由此可以看出回归损失项仅在anchor为正样本情况下才被激活;ti表示正样本anchor到预测区域的4个平移缩放参数(以anchor为基准的变换);t*i表示正样本anchor到Ground Truth的4个平移缩放参数(以anchor为基准的变换);
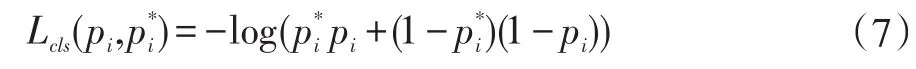
回归损失函数Lcls表达式:

R函数定义:
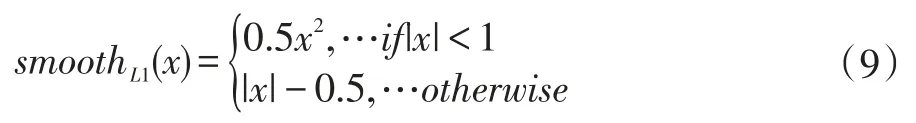
RPN和FastR-CNN都是独立训练的,要用不同方式修改它们的卷积层。因此需要开发一种允许两个网络间共享卷积层的技术,而不是分别学习两个网络。RPN在提取得到proposals后,使用Fast R-CNN实现最终目标的检测和识别。RPN和FastR-CNN共用了13个VGG的卷积层,将这两个网络完全孤立训练不是明智的选择,所以采用交替训练(Alternating Training)阶段卷积层特征共享:
(1)用ImageNet预训练的模型初始化,得到初试参数W0,并端到端微调用于区域建议任务;
(2)从W0开始训练RPN,得到训练集上的候选区域;
(3)从W0开始,用候选区域训练Fast R-CNN,得到参数W1;
(4)从W1开始训练RPN。
3 实验结果
实验环境为:CPU:Intel i7 6700K,显卡:GeForce GTX 1070,显存 8GB。
实验所使用训练数据集,大多来自于真实摄像头下截取的图片,以及一些网络上找的图片以提高泛化能力,图片的长宽比(width/height)在 0.463-6.828之间,在最初的数据集基础上,训练出模型进行测试,并将漏检、误检的图片重新加入到训练集中进行再次训练,不断得到鲁棒性更高、泛化性更强的模型,如表所示:
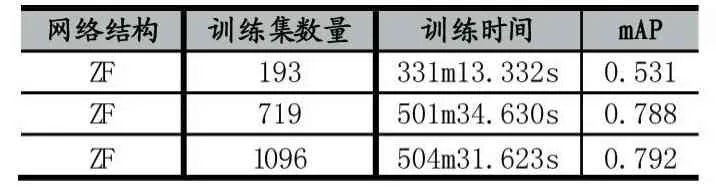
表2 训练集数量对训练结果的影响
目标检测中衡量识别精度的指标是mAP,在多类别目标检测中,每个类别都根据recall和precision绘制一条曲线,AP就是该曲线下的面积。
由表2可知,不断增加样本,平均准确度也不断上升,尤其是初期样本比较少时,将难例增加到训练集中对整体效果提升非常明显,提升了46.7个百分点;当然由于训练的数量加大,训练时间也随之增加。最终训练集有1096张图片,已经能达到0.792的mAP。
虽然ZF网络已经能达到不错的效果,但是ZF网络只有5层的卷积来提取特征,因而对复杂场景如阴影、光照、部分遮挡等效果并不好,很容易出现漏检,如图3。

图3 ZF网络下部分漏检图
针对ZF网络深度较浅,提取出的特征维度不高,因而容易出现漏检的问题,在网络结构上加以改进,使用深度更高的VGG16网络,VGG16网络共16层,有13层卷积、池化层来提取更高维度的特征,3个全连接层,如3表:

表3 ZF、VGG-16训练结果对比
使用更深的网络,会提取出更好的特征,提高模型的鲁棒性;同时更深的网络拥有更多的参数,会计算更多的卷积操作,所以训练时间也会明显提升。
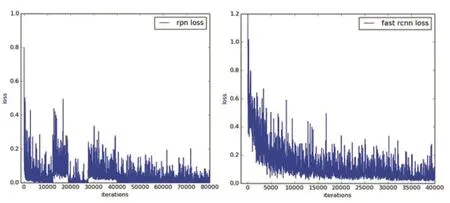
图4 损失函数变化图
从图4可以看到在训练RPN和FastR-CNN阶段的损失函数变化,RPN阶段损失函数在30000次迭代前变化起伏比较大,30000次之后逐渐收敛,40000次迭代已经区域稳定;FastR-CNN阶段一开始损失函数比较大,接下来逐渐收敛,到20000次迭代时趋于稳定。由于使用了迁移学习策略,最终训练获得了比较好的收敛效果。
在得到两种网络训练出的模型后,使用282张不同类别(如手推车摊位、三轮车摊位、小货车摊位)的测试图片对两种模型分别进行测试,使用的测试集区别于训练集中图片,并且都来自真实场景。

表4 ZF、VGG-16模型测试结果
可见,VGG16训练出的模型,相比于ZF模型,在漏检问题上有明显提升,以下是两种模型的实际检测效果:

图5 ZF(左)与VGG(右)效果对比
从实验结果不难发现,ZF模型由于提取特征层次较浅,在复杂环境(如光照、阴影、部分遮挡)下,很难有效对目标进行检测;VGG16训练的模型有强大的鲁棒性,即便在复杂环境下同样具有强大的目标捕捉能力。
4 结语
本文所使用的Faster R-CNN+VGG16网络结构,在迁移学习和交替优化策略下对非法摊位进行检测,实验表明能达到80%的平均准确度,5fps,可应用到实际场景中,对不同类别非法摊位进行智能检测。但是对于小物体(目标在整张图片中占比过小)以及强光下检测效果不理想;并且对一些车辆、人群有时会出现误检;同时能否进一步提升fps以适应实时要求,也是接下来要研究的工作。
