基于高频词扩展的短文本分类方法研究
2018-10-12付学敏陈旭东
付学敏,陈旭东
安徽新闻出版职业技术学院,合肥,230601
1 问题提出与相关研究
移动互联网的快速发展,使得微博、在线评论、电子邮件等形式的短文本呈现出爆炸性的增长。由于短文本与长文本相比具有其独特的特点,例如长度较短、描述概念信号弱等,利用传统的文本分类方法实现短文本分类很难取得较好的分类效果。
目前,在短文本领域的研究方法主要分为两类:(1)通过外部库的短文本特征扩展方法;(2)基于短文本自身的无特征扩展方法。Metzler等人通过搜索引擎返回的结果和Web语义核函数确定短文本的相似度[1-2],但计算结果对搜索引擎作为唯一标准进行文本之间的相似判定时依赖度较高,Phan等通过LDA主题模型对维基百科进行隐含主题挖掘来实现短文本分类[3],但并没有明显改变短文本稀疏性对分类带来的影响;Chen在短文本分类中利用多粒度主题模型实现文本扩展和最优主题选择技术,并采用了新的特征拓展算法[4],这种方法能有效扩展短文本,降低特征稀疏带来的影响,但扩展的过程时间长,且分类效果对外部语料的质量依赖明显。
本文通过一种基于高频词扩展的方法SC-HFW(Short Text Classification Based on Extension with High Frequency Word)实现短文本分类。该方法首先抽取每个类别的高频词来组成向量空间,然后从特征空间中抽取与文本中具有高共现性的特征加入文本进行扩充,可有效丰富短文本的语义表征能力并提高短文本分类的效果。
2 算法原理
2.1 整体流程
SC-HFW算法的整体流程图如图1所示。通过用词的频数即词频来衡量一个词的权重大小,通过选取的高频词进行特征空间的组成,然后利用特征空间对短文本数据集进行向量化表示,在一些极端情况下,会出现短文本包含的特征词不在特征空间中,特别是选择的特征词较少时,这种情况很可能会出现[5]。为了解决这个问题,采用特征之间的共现关系来进行短文本的补充。最后,在向量化的文本上利用已有的Weka分类工具进行训练分类和对测试文本标签预测。
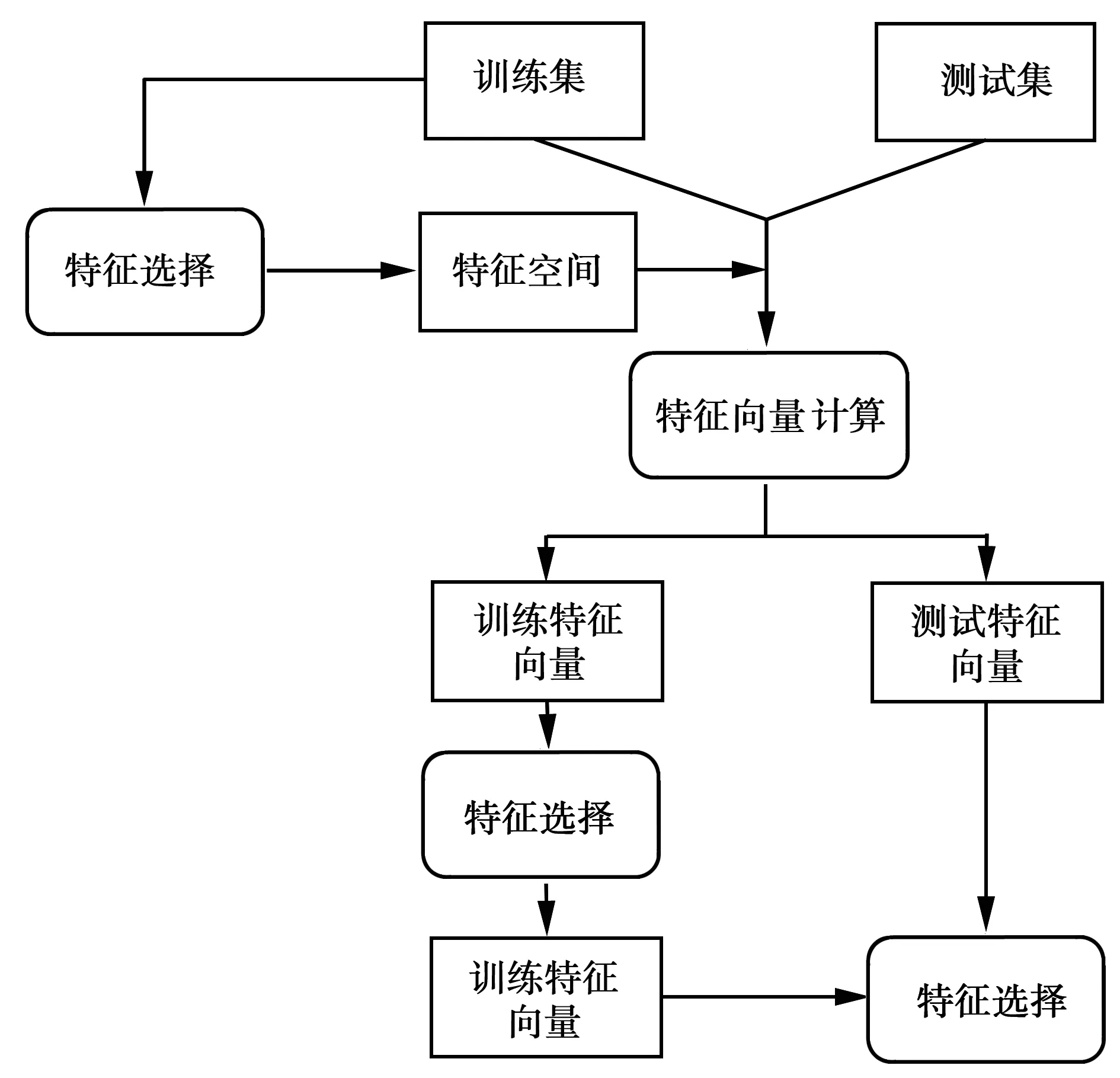
图1 算法流程
2.2 组建特征空间
在训练集中选择对类别指示性高的特征词构建特征空间,通常对一篇短文本进行相应的预处理后会得到一个含有名词、形容词、动词等词性标记的结果,不同的词性对文本主题的表征贡献程度不同。研究发现,高频词对短文本主题的识别贡献度较大,而低频词对短文本主题的识别贡献度较小。如果在词典中加入识别贡献度小的低频词,不仅对后期的分类效果帮助不大,反而会为短文本带来噪声,影响分类器对短文本的识别,降低分类的效率。因此,本文对短文本数据集抽取出现次数较高的高频词,过滤掉噪声和冗余的低频词。在特征选择上不仅考虑特征词出现的频数,还会分别在每个类别中进行选择,即按相同的比例进行每个类别中特征词的抽取,例如,类C1中总共包含50个特征,类C2中总共包含150个特征,在C1和C2中各抽取出现次数在前50%的特征词进行合并。这种方法可以在选择对类别有高贡献度的特征词的同时,兼顾短文本数据集类分布不平衡的问题,避免出现小类被大类覆盖的可能。
特征词选取的步骤如下:
(1)短文本数据集预处理,即进行分词、去停用词[6]等;
(2)对于每个类别,抽取相同比例k的高频特征词;
(3)用提取的高频特征词组成特征空间F。
2.3 特征扩展
SC-HFW方法特征扩展的目标为利用构建好的特征空间对短文本进行扩展并进行向量化。在这个阶段,当一条短文本中的特征fk在特征空间F中时,则将F中与fk共现次数最大的特征加入短文本中;另一种情况,当构建的特征空间维数不高,且短文本包含的特征不在特征空间时,方法SC-HFW将与短文本自身所包含的特征fk有最大共现次数[7]的特征加入短文本中进行扩展。
算法SC-HFW的相关描述如下:
(1)对于短文本集D中的一条短文本T
(2)对于T中的一个特征t
(3)如特征空间F中包含t
将短文本向量FV(T)中相应特征位置置为1
(4)如短文本向量为空
(5)对于T中的一个特征t
(6)计算t与特征空间中所有特征的共现次数Co(t,ft)
(7)取前n共现次数最大(Max(Co(t,ft)))的特征加入到短文本向量FV(T)中
(8)else
从F中选取与FV(T)非0位置特征共现次数最大的特征加入到FV(T)
(9)返回短文本特征向量FV(T)
(10)结束
参数解释:
D:短文本数据集T:D中的一条短文本
t:短文本中的特征F:构建的特征空间
ft:特征空间中的一个特征Co(t,ft):t与ft的相关度
FV(T):短文本特征向量
3 实验验证与分析
通过实验验证方法SC-HFW的有效性,主要包括实验的设置、SC-HFW方法的参数讨论、SC-HFW方法与对比算法的准确率比较、不同分类器对SC-HFW方法影响。
3.1 实验设置
对实验各类参数进行设置,主要包括以下四个方面:实验环境设置、数据集设置、实验参数设置及对比算法设置。
(1)实验环境
Windows 8操作系统,4GB内存,Intel(R)Core(TM)2 Duo 2.93Hz CPU。开发环境为java平台,编译运行环境是jdk1.6。
(2)实验数据集
为验证SC-HFW方法的有效性,采用Web snippet数据集,此数据集为Google的搜索片段Web snippet数据集,数据集总共包含8类:即Business、Computers、Culture-Arts-Entertainment、Education-Science、Engineering、Health、Politics-Society和Sports,其中训练集包含10 060条样本,测试集包含2 280条样本,数据集的具体描述如表1所示:

表1 Web snippet数据信息
(3)参数设置
经过实验调整,统一采用如下参数设置:抽取比例k为1/40,选取的补充特征个数n为2。
(4)对比算法设置
为了验证方法的有效性,设置了以下对比实验算法:
①MaxEnt:传统的最大熵分类算法。
②TFClarity:采用特征频率和KL距离相结合进行特征选择的分类方法。
3.2 参数讨论
SC-HFW算法中关键参数为k和n的取值,特征词抽取比例k直接影响特征空间的维度,特征词抽取的比例越大,特征空间维度越大,反之越小。
图2表示在实验数据集上SC-HFW方法的准确率随特征词提取比例的变化曲线图,在短文本中补充加入特征词的个数n,比较不加入特征词和分别加入1、2、3、4个特征词后的结果,从图中可以看出,当选择加入2个共现特征时,短文本的扩充效果最好,实验最终选择的n值为2。另外,从图2中还可以看出,随着特征词抽取比例k的变化,短文本分类的准确率先上升,随后逐步趋向稳定甚至出现少许下滑,主要原因在于特征词提取比率较小时,部分具有较高的类别指示性的特征被排除,从而影响分类精度。实验最终选择的k值为1/40。
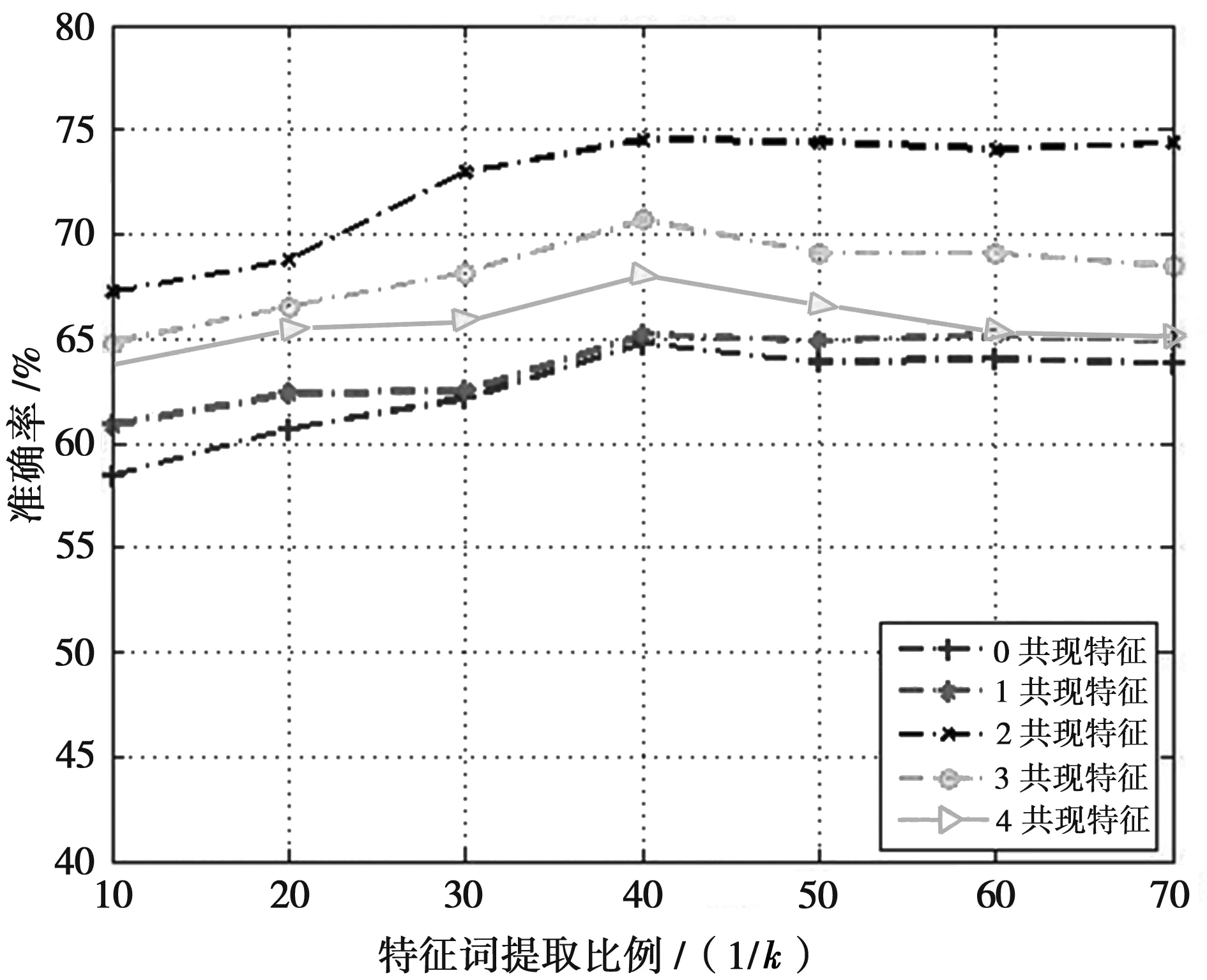
图2 SC-HFW方法的准确率在数据集上的变化曲线图
3.3 方法准确率对比
通过与已有的其他分类方法对比来说明SC-HFW方法的有效性,图3显示在实验数据集上各方法准确率的对比结果。可知,与传统的分类方法MaxEnt及现有的短文本分类方法TFClarity相比,SC-HFW在准确率上分别提高了8.74%和4.73%,说明SC-HFW方法在一定程度上解决了短文本的特征稀疏问题。
3.4 不同分类器的分类结果
在不同分类器上进行实验,验证方法SC-HFW对分类器的敏感度。这里直接利用Weka中三种分

图3 各方法的分类准确率对比
类器即RandomForest、J48和NaiveBayes,图4表示实验数据集在不同分类器上的分类结果,从图中可以看出,在不同的分类器上,随着特征提取比例的变化,分类结果整体变化趋势几乎一致,且准确率差距不大,说明不同的分类器对SC-HFW方法的影响不大,该方法具有很好的普适性。

图4 SC-HFW方法在不同分类器上的分类结果
4 结 语
本文提出了一种基于高频词扩展的短文本分类方法,通过借助外界资源,利用特征词出现的频数高低及特征词之间的共现关系,对短文本特征词进行选择并进行特征扩充。针对短文本的特征稀疏等特性,通过对特征空间构成的研究,在降低特征空间维数的同时,也丰富了短文本自身的内容。实验结果表明,在实际的数据集上,本文所提的方法在分类精度及普适性上均有一定的效果。
