基于改进均值—方差模型的电力系统经济调度
2018-10-12张依强杨佳俊
张依强 ,孙 鹏 ,杨佳俊
(1.国网山东省电力公司菏泽供电公司,山东 菏泽 274000;2.国网山东省电力公司莱芜供电公司,山东 莱芜 271100)
0 引言
几十年来,电力系统经济调度问题一直受到研究人员的重视。传统电力系统经济调度的本质是在已知机组组合计划的前提下,通过合理分配各台机组的有功出力,使得总的发电成本最小。随着能源需求的不断加大,以及环境保护意识的不断加强,传统火力发电越来越不能满足社会发展需要,而风力发电作为一种新能源应用越来越广泛。虽然风力发电资源有很好的清洁性和经济性,但随着风力发电并网规模不断增大,风力发电所具有的不确定性给电力系统调度研究带来不可忽视的影响。
文献[1]引入正、负旋转备用约束来应对风力发电预测误差对系统的影响,但不能准确描述风力发电的不确定性。针对确定性建模方法的不足,研究人员一般采用模糊建模和概率建模来模拟风力发电不确定性[2-8]。文献[2]采用模糊理论建立含风力发电场的电力系统动态经济调度模糊模型,能更好地适应风机输出功率的不确定性。文献[3-4]研究风速长期分布情况,并用Weibull分布作为风速模型,同时在风力发电成本目标函数中加入惩罚因子,计及风力发电功率高估或低估对总成本的影响。文献[5]通过分析江苏某风力发电场中地理位置相邻的9台机组的实际运行数据,分析得出4个季度的风速概率分布曲线近似服从Weibull分布的结论,虽然Weibull分布模型适用于描述长期风速不确定性问题,但对于电力系统经济调度这一短期操作并不合适[6]。 文献[7-8]提出利用高斯分布模拟风速预测误差,但是常规的高斯分布模型对于风速预测误差模拟仍存在其局限,其准确性有待提高。
在风力发电不确定性建模的基础上进行目标函数优化是解决经济调度问题的关键。文献[9]将抽水蓄能电站和风力发电场结合,提出了风蓄联合系统削峰的调度策略,把最大化风蓄联合出力作为目标函数优化。文献[10]提出考虑错估风力发电功率的目标函数,通过正态分布模型模拟风力发电功率预测误差,并采用传统等耗量微增率准则进行模型求解。文献[11]综合考虑机组强迫停运率等条件,建立以最小化系统发电成本和期望停电成本为目标函数的数学模型,将风力发电功率的不确定性以概率形式引入机组停运容量的计算中。文献[12]分别把风力发电场运行总费用、常规机组发电总耗量函数和污染排放量作为目标函数进行优化。以上文献均把总风力发电成本作为目标函数进行优化,只能反映其调度方案的预期收益,无法在目标函数中体现出风力发电不确定性特性带来的影响。
H.M.Markowitz在1952年提出均值—方差模型[13],在组合投资领域广泛应用,用以保证利润最大化和风险最小化。近年来,该模型也被应用于电力系统中[14-15]。但是这些应用主要基于几种标准预测误差分布,模型的准确性依赖于预测误差分布拟合的准确性。
为增加高斯模型拟合风速误差的准确性,提出基于相关性理论的改进高斯模型参数整定方法,建立了含风力发电的电力系统经济调度均值—方差模型,最后提出一种基于最优概念的全局改进差分进化算法用于模型的求解。
1 基于相关性理论的风力发电不确定性模拟
1.1 传统高斯模型
由于高斯概率分布函数模型更加适用于短期的风速误差模拟,因此选择该分布对风速不确定性进行模拟。
根据高斯概率分布原理[16],假设风速预测值为v′,则实际风速 v=v′+Δv,其分布函数为

其概率分布模型为
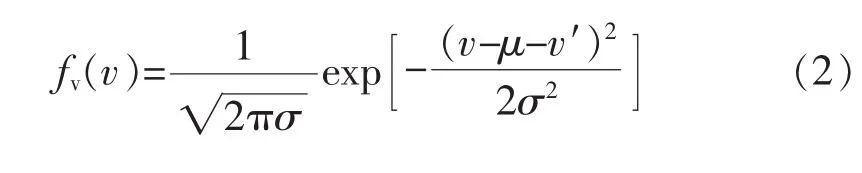
根据高斯分布理论可知,参数μ(标准差)和参数σ2(方差)对于误差模拟的精确度影响很大,而风速误差模型的准确性直接影响电力系统经济调度模型是否合理。一般高斯参数的整定方法是通过已有的数据进行拟合确定,现有某地某月2 984个时刻风速预测误差数据,数据间隔为15 min。为了分析误差值出现的频率,将数据进行分组。确定21个数据误差区间,以0.5 m/s作为分组区间宽度,统计分布在每个区间内预测风速误差值个数,并求出对应频率,利用高斯分布拟合频率分布,拟合结果如图1所示。
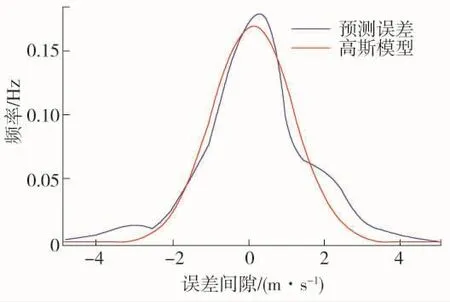
图1 风速预测误差分布拟合
高斯模型拟合结果是μ=0.05,σ=2.112,由图1可知,传统高斯模型拟合结果大致符合风速预测误差分布情况。
通过下述4个指标对MATLAB拟合性能进行评价:
1)和方差。用来衡量拟合值和数据之间的偏差,该值越接近于0,拟合性能越好。
2)决定系数R2。用于衡量拟合曲线是否能贴近数据变化方式,该值越接近于1,拟合性能越好。
3)校正决定系数。通常用于增加额外参数指标后的拟合结果评价,该值越接近于1,拟合性能越好。
4)均方根误差。该值越接近于0,拟合性能越好。
通过上述指标对传统高斯模型拟合结果进行评价后,所得评价结果如表1所示。

表1 传统高斯分布拟合曲线指标
由表1中可知,传统高斯分布的拟合结果基本达到所需要的要求,因此可以根据已有风速数据样本,利用高斯分布分析未来风速误差分布。
1.2 反常预测误差数据分析
分析上述拟合结果可以发现传统高斯分布拟合仍存在误差,从图1中可以看出对于误差绝对值超过3 m/s的数据分布和拟合曲线有很大差距,将频率超过高斯分布特征的数据定义为反常预测误差数据。
将2984组数据根据时间顺序进行编号,为了进一步分析反常数据分布情况,从总体数据中筛选出反常预测误差数据,得出反常预测误差数据分布情况如图2所示。
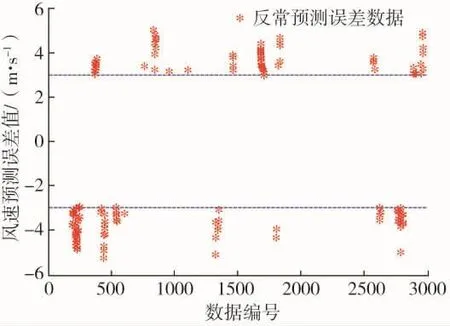
图2 反常预测误差分布
由图2可知,共有167个反常预测误差数据,主要集中在有限的几个区域中,说明反常预测误差数据分布具有明显集中特性。根据实际情况分析,反常预测误差的出现来源有预测方法的局限、反常的气象变化等[13],而这些原因导致的反常预测误差都有集中化的特点。根据这一分布特点,可以得出反常预测误差数据出现之间有很强的相关性。
1.3 基于相关性的改进高斯分布模型
1.3.1 相关性理论
相关性理论是用于分析两个或者多个事物 (变量)之间关联密切程度的方法[17]。在统计学中相关性分析是指对事物或者某系统的多重指标之间,以及指标与其所确定的评价目标的相关性评价过程。利用肯德尔相关系数来确定反常误差数据出现的相关性问题。
肯德尔相关系数是通过对两组变量的一致性进行计算得到的统计值,首先需要比较两组变量之间成对元素大小趋势关系并进行分类,具体分类方法如图3所示。
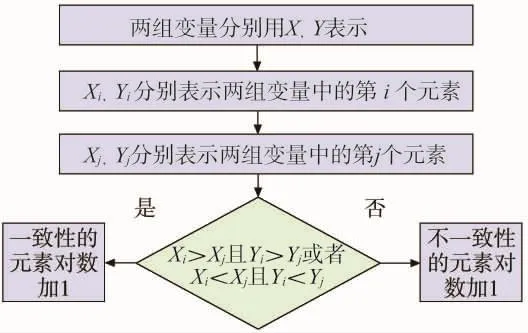
图3 肯德尔相关系数一致性判断方法
肯德尔相关系数是一个统计值,不同于其他相关系数数学定义,其数学定义为
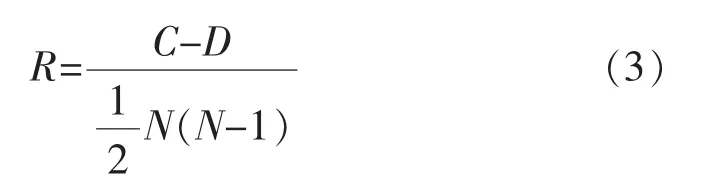
式中:C为X与Y中拥有一致性的元素对数 (两个元素为一对);D为X与Y中拥有不一致性的元素对数;N为元素总数。
1.3.2 基于相关性的改进高斯分布模型
为了研究反常预测误差数据出现的规律,分析当前时刻出现反常预测误差数据与前一小时内的预测误差的方差、均值和历史同期误差值的相关系数分别为 0.172 0,0.660 8,0.217 3。
由分析可知,前1h预测误差均值与当前时刻预测误差相关性最大,呈显著相关关系,而和同期历史数据、前1h内预测误差方差相关性很小。为了进一步研究下一时刻预测误差值与其之前预测误差均值之间的相关性,改变之前时刻数据时间间隔,即取当前时刻到前24 h内的预测误差数据,计算均值和下一时刻误差相关系数,从而寻找最大相关性变量。首先计算前15 min内预测误差值均值和当前时刻预测误差值相关系数,然后计算前30 min内预测误差值均值和当前时刻预测误差值相关系数,以此类推,直到计算前24 h内预测误差值均值和当前时刻预测误差值相关系数,计算结果如图 4所示。
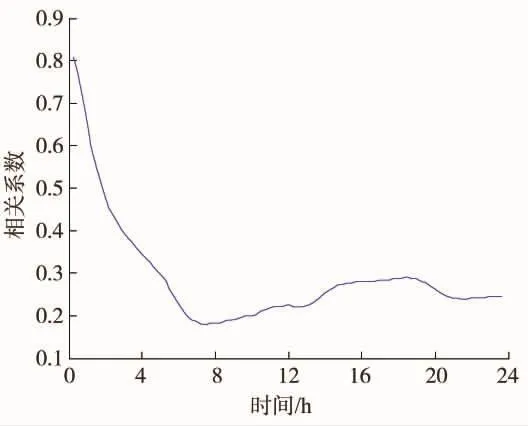
图4 相关系数变化曲线
由图4可知,随着时间跨度增大,相关系数不断减小,从显著相关减弱到低相关。前15 min的预测误差和当前时刻预测误差相关性最大,相关系数可达到0.8,说明离该时刻越远的数据对于该时刻预测误差影响越小,预测当前时刻预测误差时,与该时刻越接近的预测误差值越有参考价值。
从上述数据分析结果可知,反常误差数据集中在短时间内出现,当出现一个反常预测误差数据后,下一时刻误差值也很可能与该值相近。因此,当利用高斯分布模拟风速误差时,如果出现反常预测误差数据,可以通过改变高斯分布的参数来增加模拟准确性,此时可将参数μ整定为上一时刻的预测误差,而把参数σ设定成0.2μ。
利用改进高斯模型进行风速预测误差数据模拟,首先利用已有数据拟合高斯分布模拟数据,再通过与实际数据进行实时比较,比较结果如图5所示。当出现反常预测误差数据时,按上述方法修改参数后进行数据模拟,最终将模拟所得的2 914个数据与实际数据进行拟合比较,拟合曲线指标如表2所示。
由图5和表2可知,利用改进高斯分布仿真得到的数据更加贴近实际数据,特别是在反常数据分布模拟方面的准确性大大高于传统高斯分布模拟,说明通过改进的高斯模型可以有效用于风速预测误差模拟研究。

图5 改进的高斯分布模型模拟数据与实际数据比较

表2 改进高斯分布拟合曲线指标
上述对于风速不确定性的高斯概率模型的研究为保证下文的动态经济调度模型的准确性奠定基础,通过动态整定参数使得风力发电并网后的调度模型具有实时性。
2 基于均值—方差的经济调度模型
2.1 考虑火电燃烧成本
在研究风力发电并网后的发电成本时一般都忽略风力发电自身的发电成本,风力发电并网的经济性一般都体现在减少火电输出功率,从而减少总发电成本,因此需要先对火力发电成本进行研究。火力发电成本绝大部分都是燃烧成本,应用最为广泛的火力燃烧成本目标函数为
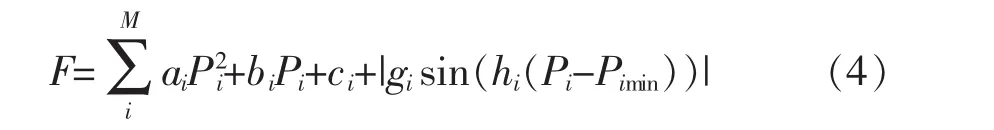
式中:F为电力系统中发电成本;M为该系统中火电机组数量;Pi为第i台火电机组发电功率;Pimin为第i台火电机组最小发电功率;ai,bi,ci分别为第 i台机组发电功率与燃烧成本相应系数;gi与hi为阀点效应系数。
2.2 基于改进高斯分布的均值—方差模型
文献[14]提出利用H.M.Markowitz的均值-方差模型解决含风力发电不确定性的电力系统经济调度问题,其均值—方差模型为
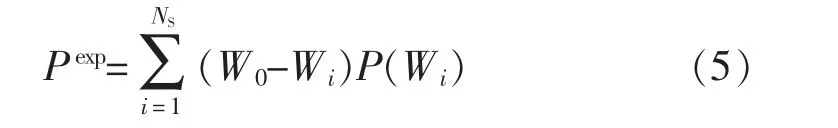
式中:Pexp为利润均值;W0为纯火电机组输出一定功率时的总成本,包含燃烧成本和污染物排放总成本;Wi为发出同等功率时第i个取样样本的风力发电输出功率的总成本;NS为概率模型取样点个数;P(Wi)为第i个取样样本的概率。
均值目标函数表示发电方案在不同风力发电功率输出情;况下得到利润的均值,根据风险性的定义,可以用偏离风险作为方案风险性的指标,具体目标函数为

式中:V为均值目标函数。
方差目标函数用于衡量发电策略风险性指标。在该均值方差模型的基础上加以改进,利用提出的改进高斯分布模型描述取样概率,从而使模型在出现反常预测误差时能够保证模型准确性。
3 改进的差分进化算法
为提高算法寻优效率,将粒子群(PSO)算法运用全局最优点更新粒子的方法引入到差分进化算法中。差分进化算法步骤如下[19]。
1)初始化种群。
初始种群根据以下表达式随机产生:
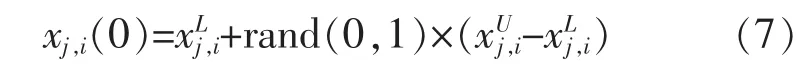
式中:xi(0)为种群中的初代第 i个个体;xj,i(0)为初代的第 i个个体的第 j个“基因”;rand(0,1)为分布在区间 (0,1)范围内的随机数;U为种群中个体最大值;L为种群中个体最小值。
2)变异操作。
具体措施是建立一个储备集CB来保存算法每一代得到的非支配解(较好解),种群每一代中出现一个新的非支配解都需要和储备集中的解比较,如果该解不被储备集中任意解支配,则将其加入储备集;若该解支配储备集中的解,则把被支配的解从储备集中删除,将新解加入。然后在变异操作过程中,按一定的概率从储备解中选取个体作为变异个体,表达式如下:式中:p为选择储备集解的概率大小;Gj为储备集CB中随机取得任意一个解;F为缩放因子,F一般取0~2,影响偏差分量的放缩比例。F取值较小时,收敛速度较快,但如果过小,就可能使迭代早熟;F取较大值时,虽然可以找到较好的最优解,但收敛速度过慢。 所以,F 取值调整为[21]


式中:t为当前代数;T为进化代数。
3)交叉操作。
通过对第 g 代种群 xi(g)及其变异的中间体 vi(g)进行操作得到中间个体,具体表达式如下:

式中:CR为交叉概率;jrand为[1,2,…,D]的随机整数,D为样本总数。交叉算子CR取值为0~1,决定一个新个体中的元素来自随机选择的变异个体还是原来个体的概率。
4)选择操作。
差分进化算法采用优值选取算法来选择下—代种群的个体,表达式如下:

改进的差分进化算法步骤如下:
1)设置算法参数,种群大小NP,种群维数D,进化代数T,缩放因子F,交叉概率CR;
2)初始化种群,计算每个个体适应值,并根据Pareto关系建立储备集CB,迭代次数为t=1;
3)利用上述改进差分算法理论中的变异操作,生成中间个体;
4)利用上述差分算法理论中的交叉操作,生成新个体;
5)利用上述差分算法理论中进行选择操作,得到子代种群;
6)利用子代种群中较好解更新储备集CB,迭代次数 t=t+1;
7)判断迭代次数是否满足设置的代数,若满足则输出储备集,不满足则回到步骤3,继续迭代。
4 算例分析
以IEEE-57节点系统为例,验证基于均值—方差的电力系统经济调度模型和改进差分进化算法的可行性。算法仿真所用电脑配置为:AMD双核处理器,2G内存,64位操作系统。IEEE-57节点系统有7台火力发电机,机组出力上下限,燃烧成本参数如表3所示,其中机组出力单位是100 MW。
首先计算IEEE-57节点系统的火电机组发电成本,再考虑3个符合相同高斯分布模型的风场并网后的利润均值和方差来判断其并网后的经济性和风险性。为了比较不同高斯分布风场并网对于方差目标函数的影响,分析符合2个不同高斯分布模型的风场分别并网后的结果差异。
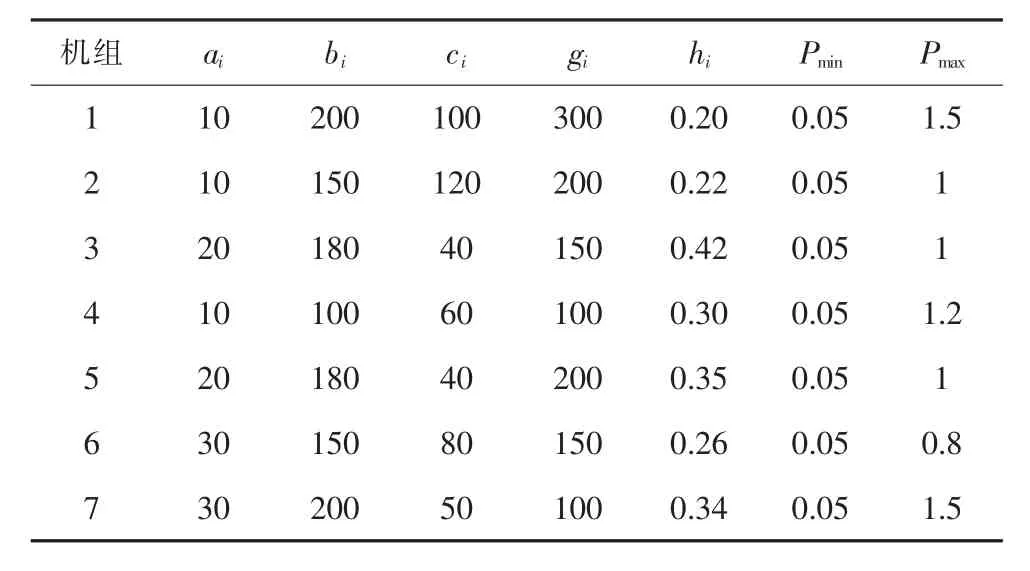
表3 IEEE-57节点系统燃烧成本参数
4.1 风速预测误差符合相同高斯分布
风场机组数量和风速预测如表4所示,3个风场的风速预测误差分布属于相同的高斯分布,参数为μ=0,σ=2,风场的风力发电机都是双馈感应发电机组,额定功率为2 MW,切入风速为4 m/s,切出风速为 20 m/s,额定风速为 12.5 m/s,利用 LHS取 400个样本,继续进行仿真,仿真结果如表5、图6所示。

表4 风场预测风速和风力发电机组数量

图6 不同寻优算法所得Pareto解集

表5 不同算法优化结果比较
为了更加准确分析3种算法所得Pareto解集优劣,同样用SP测度对非支配解集进行测试,将算法运行20次,分别记录所得最优值,最劣值和平均值如表6所示。

表6 不同算法Pareto解集的SP测度
分别利用改进DE,普通DE和PSO在均值—方差模型中寻优得到的Pareto最优解集。
分析图6可知,改进DE算法得出的非支配解相比于DE和PSO的解集,分布更加均匀,Pareto前沿也比较平滑。不仅如此,具体分析3种算法解得分布可以发现,改进DE算法所得解集分布范围明显大于其他两者,说明改进的DE进化算法具有良好的寻优能力。
无论在平均值还是标准差方面,改进DE算法都有明显的优势,可见改进的DE算法所得的非劣解均匀分布在空间中,有着优于其他算法的Pareto前沿,进一步证明改进DE算法在IEEE-57节点系统模型的有效性。
图6中绿星表示通过满意隶属度在Pareto解集中选取的折中解。记录3种算法所得折中解如表7所示。
比较根据决策者满意度来判断得到的折中解,改进DE算法得到的折中解的利润均值大于其他两个,且方差也低于另两个折中解,说明改进DE寻优所得方案都优于其他两种算法,能够有效求解兼顾经济性和稳定性的发电方案。
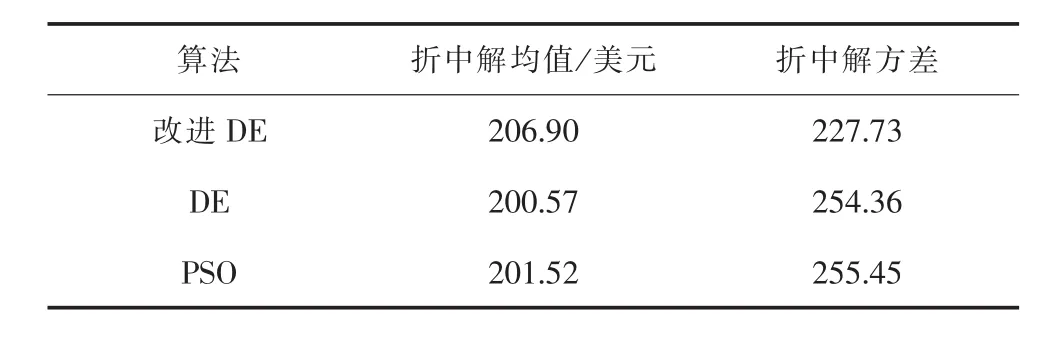
表7 不同算法Pareto解集中的折中解
为了证明折中解的求取的重要性,从图6中取均值最大解(方案D)和方差最小解(方案E)与折中解(方案F)进行比较。 均值最大解范围为[260.365,578.675],方差最小解范围为=[142.582,260.365],3 个解的 400个样本值利润分布如图7所示。

图7 3个解中400个风速样本对应利润值分布
从图7可以看出,方案D虽然可以得到超过E和F的利润均值,但方案D的样本利润分布差距太大。方案D中许多风速样本对应利润都要低于方案F,说明方案D会出现实际利润大大低于预期值,从投资角度看,该方案存在较大的下行风险,因此放弃方案D。方案E虽然利润分布稳定,但预期利润值过低。因此,考虑到预期利润和风险值,选择折中解,即方案F。
4.2 风速预测误差符合不同高斯分布
为了进一步验证风速不确定性对于不同风场的方差目标函数的影响程度,假设3个风场风速预测误差分布属于不同参数的高斯分布,参数如表8所示。

表8 不同风场高斯模型参数
由表9可知,风场1的参数μ和σ较小,代表风速实际风速值偏离预测值幅度较小,风场2参数μ和σ较大,代表风速预测误差不管从平均值还是偏离程度上都比风场1大,说明实际风速大幅度偏离预测风速。现假设某时刻预测风速为8 m/s,将两个风场分别并网之后,进行均值—方差目标函数求解。
为了进一步验证高斯模型参数不同的影响,在12个时刻将2个风力发电场分别并网,假设每个时刻预测风速值与实际风速相同,记录12个时间段的3个风力发电场并网后利润方差函数值和每个风场并入风力发电功率均值,如表9所示。

表9 不同风力发电场方差目标函数值和并网风力发电功率
从表9可以看出,针对不同时刻并网功率来看,风力发电场1的并网功率均值均大于风电场2,原因为不同风速分布模型参数导致的风速样本分布不一样。风电场2的风速预测误差过大,为了减少其不确定性对于整个系统的影响,大幅度减小其并网的风电功率。随着预测风速的增加,风场1的并网均值功率增加近14 MW,风场2仅增加6.6 MW,为保证系统稳定性,通过减小高风险性风场的并网功率以减小发电方案的风险性。
5 结语
通过大量风速预测误差数据对风速不确定性模拟方法进行研究,利用相关性理论对传统高斯概率模型进行改进,以此作为基础引入均值—方差模型解决含风电的电力系统经济调度问题,并用改进的差分进化算法对模型求解。仿真结果表明,改进差分进化算法能够求解出更好的多目标Pareto解集,同时均值—方差模型可以根据不同风场风速分布特性进行风电并网功率选择。
