基于本体术语学的教育领域多语言本体构建
2018-10-10张丽伟彭悟焯
袁 满, 张丽伟, 彭悟焯
(1. 东北石油大学 计算机与信息技术学院, 黑龙江 大庆 163318; 2. 哈尔滨理工大学 电气与通信工程学院, 哈尔滨 150080)
0 引 言
随着互联网技术的发展和应用规模的不断扩大, 网络上信息呈爆炸式增长, 如何将互联网上的海量多语言信息提供给不同文化背景的用户群体, 让只精通一种语言的用户轻松获取不同语言的信息资源成为各领域学者共同关注的问题[1]。
跨语言信息检索(Cross Language Information Retrieval)是指以一种语言检索出其他语言信息资源的检索方法。目前, 跨语言信息检索是国内外信息检索领域的前沿课题之一。该项技术具有广泛的学术价值和商业价值, 可应用于跨文化交流、 电子商务等许多领域。当前的多语言信息检索系统多采用双语词表和机器翻译等方式, 由于缺乏语义, 检索效果并不理想。本体是一种形式化的知识表达与描述框架, 具有强大的知识表达、 赋值机制与语义推理能力[2], 不仅可描述信息资源体系中十分复杂的概念、 属性和关系, 形成语义知识网络, 还能实现具有语义推理功能的知识检索[3]。而多语言本体是本体在不同语种中的具体表现形式, 可作为语义层应用于跨语言信息检索系统中, 把术语到术语的转换变成术语到概念、 概念再到术语的转换, 将检索提升到语义层面, 具有更大的理论优势[4]。因此, 多语言本体成为目前研究的热点之一[5]。基于此, 笔者在传统本体构建方法的基础上, 引入本体术语学理论构建了教育领域的多语言本体, 可利用此本体实现教育领域信息资源的有效组织和跨语言的语义检索, 有效提高教育资源利用率, 为各国或地区之间的知识共享奠定基础, 也为后续研究提供借鉴。
1 术语学与本体术语学
“本体术语学”建立在术语学理论的基础上。通过语音或文字表达或限定专业概念的约定性符号叫做术语, 术语可以是词, 也可以是词组[6]。在国家标准《术语工作----原则与方法》中术语的定义是“术语是专业领域中概念的语言指称[7]”。国家标准《术语工作----词汇 第一部分: 理论与应用》则将术语定义为: “在特定专业领域中一般概念的词语指称”。而术语学(也叫术语科学)则是指“研究各专业领域中术语的结构、 形成发展、 用法和管理的学科[8]”。术语学的目标是通过标准化手段消除科技语言中的“歧义”, 使表述更加清楚, 无二义性。为实现这个目标, 现代术语学的奠基人维斯特提出: “概念优先于术语(名称), 概念的通用性独立于语言的多样性[9]”。文献[6,7]的术语定义也体现了维斯特的理念。但值得注意的是, 在术语学中概念不能依靠其自身而独立存在, 必须依靠于用自然语言或半形式化语言书写的定义而存在。
在检索时输入的关键词实际上就是术语。在检索过程中, 特别是在检索其他语言资源时, 很容易会因为对术语的表述或理解不同而漏检或错检, 难以找到自己需要的全部资源, 比如, 在检索“苹果”时, 可能会漏掉名为“apple”的资源。与合作者交换信息时也很容易出现歧义。在当今时代, 合作和交换信息正稳步增长, 参与者需要就术语的含义达成一致。在交流出现问题时, 专家们会参照概念间的逻辑形式规范或半形式化的语言(例如公式、 图表、 图示等)使大家达成共识, 而不是依靠自然语言, 这是因为用结构化或半结构化语言书写的概念定义是客观的, 专家们对其内涵有共同的认识。概念系统是超语言的, 不同语言或文化背景下的不同术语可表达同一概念, 概念具有独立于语言多样性的稳定性。可根据概念在概念体系中的位置确定概念的定义, 进而确定与之对应的其他语言的术语。基于此发现, ISO(International Organization for Standardization)国际术语标准项目负责人, 法国萨瓦大学罗什教授引入了术语学的新范式: 本体术语学[10]。本体术语学的主旨是把术语的语言维度和概念维度区分开并确立它们之间的关系。语言维度是由通过语言学关系(比如上下位关系)关联起来的术语构成的。概念维度是用形式化语言编写的语义本体, 在这个本体中, 概念通过概念间的关系(比如is-a和part-of)联系在一起。由于本体术语学中的概念是独立存在的, 所以, 本体术语学既组织术语也组织概念。但是, 术语的语言学维度与概念维度并不是毫无关联的, 术语的含义与概念是相对应的, 因此, 可将不同语言的术语与它们表示的同一个概念关联起来。这样就可依据术语找到与它相对应的概念, 也可进一步得到与此概念对应的其它语言的术语或者信息资源。本体术语学能把术语学的语言学维度和概念维度这两个异构网络联系在一个全球性的连贯系统中, 实现语言的标准化。并且, 它更加体现了维斯特关于概念具有独立于语言多样性的普遍性思想: 本体术语学保留了不同实践群体间语言的多样性, 而不妨碍它们共享共同的学科领域和标准化的概念体系。基于本体术语学理论, 可实现各国之间的知识资源共享和跨语言检索。
本体术语学已在欧洲得到实践, 比如, 欧洲加热和冷却应用技术的可持续性项目ASTECH(Application of Advanced Sustainable Energy Technology in Refrigeration and Heating), 此项目旨在为欧洲再生能源技术领域的供应商和用户之间提供共享信息的平台, 其多语言搜索引擎即利用本体术语学原则, 该项目的文献和信息可用9种语言发布和搜索[9]。笔者将本体术语学引入教育领域多语言本体构建中, 以便支持多语言教育知识资源的描述与表达, 为教育资源的跨语种检索和知识资源共享奠定基础。
2 多语言本体中概念及其关系的获取
教育是人类社会的主要活动之一, 自从有人类社会便有了教育活动, 教育理论的发展历经千年, 如今已是一个庞大的科学体系, 其中涵盖的内容非常繁杂, 要从零开始构建教育领域本体非常困难, 因此, 笔者考虑基于现有知识源构建本体。
由于本体与叙词表和分类法在知识表示上的天然联系, 国内外很多学术团体开始利用现有的叙词表、 分类表与分类主题一体化词表构建本体, 并取得了一定的成果。目前, 已经有十多种叙词表通过各种方式转换为本体。比如, 联合国粮农组织(FAO: Food and Agriculture Organization of the United Nations)利用RDFS(Resource Description Framework Schema)将其与欧洲共同体委员会合作开发的多语种的农业受控词表转化为农业本体[11]。有学者将艺术和建筑叙词表(ATT: Art and Architecture Thesaurus)转为本体[12]。邓志鸿等[13]在改造分类法和主题词表的基础上, 运用本体技术构建概念模型, 用于智能导航。任瑞娟[14]在分析《中国分类主题词表》与本体相互关系的基础上, 提出了基于《中国分类主题词表》构建分布式本体的设想, 并设计使用OWL(Web Ontology Language)描述本体系统。鲜国建[15]将《农业科学叙词表》转换为农业本体并总结基于叙词表构建本体的基本原理。何伟等[16]根据叙词表的用、 代、 属、 分、 参等关系符号设计了一种由叙词表向本体OWL快速转换的算法, 并证明该算法可有效提高本体构建速度、 进一步促进叙词表在网络环境的应用。左惠凯等[17]基于《中国主题分类词表》等叙词表中的专有叙词, 参考中外叙词表编制标准, 提出了面向本体的专有叙词关系的调整原则。在教育领域, Qin等[18]将教育资料网关(GEM: Gateway to Educational Materials)中的受控词表转换为本体, 并提出了将受控词表转化为本体的方法与原则框架。刘小乐[19]从《教育主题词表》中抽取教育领域重要概念构建了教育领域顶级本体等。以上文献可为笔者提供一定的理论支持。
《教育主题词表》是我国第1部分类主题一体化词表, 也是我国出版的第1部教育专业叙词表, 内容涉及教育科学的各个领域及其若干相关学科[20], 权威性毋庸置疑, 可为本体构建工作提供支持。《教育主题词表》主要规范教育领域的主题词和检索语言, 同时, 也为教育领域概念术语的提取及属性关系的建立提供参考。它主要由字顺表、 分面分类表、 索引及附表等4部分构成;分面分类表是在分面分类理论指导下建立的词汇分类体系, 每个分面的后面都跟着与其相对应的主题词。总共按照学科领域将教育专业划分为7个基本范畴, 16个大类(见表1)。其中在主表中收集专业词汇2 828个, 在附表中收集词汇1 147个, 共收集词汇3 975个[21]。

表1 《教育主题词表》分面分类范畴与大类
《教育主题词表》与教育领域本体间存在以下共同点: 首先, 它们都在某种程度上表示了教育领域概念以及它们之间的关系; 其次, 它们的类目体系均是等级结构, 主题表提供分类结构或范畴索引, 而本体从整体上提供类的层次等级体系结构[18]。这些共同点为基于教育主题词表构建教育领域本体提供了可能, 主题表中的叙词及词间关系可为本体中概念体系的确定提供重要依据, 节省大量人力物力。
3 利用本体术语学构建教育领域多语言本体
目前比较成熟的本体构建方法主要包括: 骨架法、 AFM(Activity-First Method)法、 评价法、 五步循环法和七步法等[22]。斯坦福大学的七步法主要用于构建领域本体, 是一种比较通用的方法。笔者采用七步法和protégé工具构建教育领域多语言本体。
3.1 多语言本体的概念等级关系构建
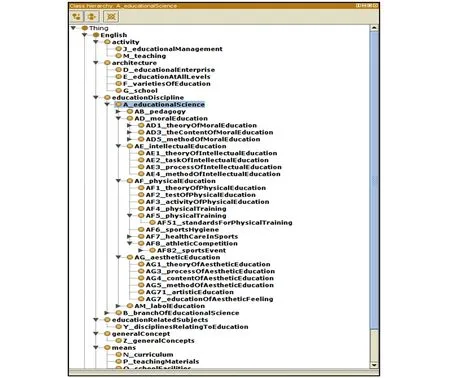
图1 多语言本体概念体系Fig.1 Conceptual system of multilingual ontology
在构建本体前, 首先要确定本体中概念的等级关系, 等级体系是确定其它属性关系的基础。《教育主题词表》几乎涵盖了教育领域的全部术语, 术语又与概念有着一一对应关系[23]。因此可将《教育主题词表》中的叙词转换为本体中的概念。基本过程是把《教育主题词表》中的7个基本范畴定义为1级类, 将《教育主题词表》中16个大类定义为2级类, 然后按照“分面分类表”中的等级结构关系逐步扩展下位类。这样, 就得到了教育领域多语言本体的概念等级体系。出于通用性的考虑, 笔者选择英语作为中心语言表示本体中的概念及属性, 构建出的概念等级体系如图1所示。
3.2 多语言本体属性的定义
等级关系形成后, 要确定本体中概念间的其他关系和属性。属性界定了概念之间的关系, 可为语义检索与推理奠定基础。属性分为对象属性与数据属性, 对象属性主要描述类与类之间或实例与实例之间的关系, 数据属性则主要是实例与数据之间的关系。《教育主题词表》中的词间关系主要有3种: 等同关系、 属分关系和相关关系, 通过“用、 代、 分、 属、 族、 参”等参照项描述。笔者将叙词表中的词间关系映射为本体中明确的概念之间的关系(见表2)。数据属性主要包括author,resourceName,ISBN,resourceType等。

表2 词间关系与OWL本体中概念关系映射
3.3 基于本体术语学的多语种映射
依据本体术语学概念具有独立于语言多样性的稳定性思想, 采用国际通用语言英语作为本体构建要素构建出标准化的中心语言本体, 描述的教育领域中概念及其关系具有稳定性, 可作为术语的概念维度。将其他语言的术语按照语言学关系相互关联形成独立的术语体系(每种语言的术语按照自己的语言学关系进行关联), 作为术语的语言学维度。通过equivalentClass属性分别将用各个语言书写的术语与概念维度中的概念关联[24]。这样, 就实现了概念维度与语言维度的相互关联, 不同语言的术语被有序地组织到相应的概念下, 而术语之间的语言学关系也得到了保留。当想要加入一种新的民族语言时, 只需针对共享的概念给出自己语言所特有的语言学术语定义, 然后与本体中的概念相关联即可。笔者选定英语作为中心语言, 汉语、 德语和丹麦语作为多语言本体的语言样本进行试验, 以概念教育学为例, 其OWL代码展示如下:
〈Class rdf: about=“&education_ontology;AB_pedagogy”〉
〈equivalentClass rdf: resource=“&education_ontology;教育学”/〉
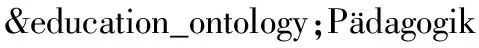
〈equivalentClass rdf: resource=“&education_ontology;uddannelse”/〉
〈rdfs:subClassOf rdf: resource=“&education_ontology;A_educationalScience”/〉
〈/Class〉
OntoGraf中可视化展示如图2所示。

图2 多语种映射可视化展示Fig.2 Visual display of mlti-lingual mapping
3.4 多语言本体实例定义
将各资源的元数据记录按照主题关联到对应的概念节点下, 作为对应概念节点的实例, 此过程相当于元数据的上架[12]。每个概念相当于一个文件夹, 把相关的文档收在一起, 而不用考虑它的书写语言。在检索时不论采用什么语言的术语进行检索, 最终都指向与它们相对应的同一个概念, 进而找到概念下的其他语言术语和用不同语言书写的教育资源, 实现多语种查询, 进一步提高查全率。本体可被看作一个概念地图, 在系统中起到承上启下的中间层的作用。在这个概念地图中, 专家可通过父类-子类和is-a等关系进行导航, 查找相关信息资源。
3.5 多语言本体的存储

图3 本体存储在数据库中的表Fig.3 The table in which the ontologyis stored in the database
多语言本体构建完成后需对其进行存储, 本体的存储方式主要有基于文本的存储和基于数据库的存储两种。这两种存储方式各有优劣, 文件方式存储简单快捷、 管理方便、 同时方便扩展, 可保留完整的语义信息, 但系统效率低, 适合小规模本体存储。关系数据库存储方式效率高, 可充分利用SQL语言的优势, 技术很成熟, 但语义支持差, 主要用于大规模本体存储[25]。考虑到多语言本体概念较多, 笔者采用关系数据库存储。存储过程为: 首先新建一个数据库, 然后配置好数据库连接, 最后将OWL文件转换为字节流后存储到数据库中。整个过程由Jena API完成, Jena是惠普公司开发的一个构造语义网应用程序的Java框架, 它有着完整的本体解析、 存储、 推理和查询函数以及相关调用接口, 可便捷实现本体的数据库存储[26]。本体存储到数据库后, 将生成图3所示的7个表。
4 教育领域多语言检索系统的实现
笔者构建的系统主要用于教育领域信息资源的跨语言检索, 用户在系统中输入任意语言的某个术语后, 系统就会自动输出与此术语相对应的本体概念、 其他语言的术语和相关学习资源的元数据信息, 供用户下载和查看。例如, 输入汉语术语教育学后, 查询结果如图4所示。本系统主要利用Jena API对存储到数据库中的本体数据进行查询, Jena提供了ARQ(A SPARQL Processor for Jena)查询引擎, 支持RDQL(RDF Data Query Language)和SPARQL(SPARQL Protocol and RDF Query Language)查询语言, 从而可利用它对本体模型进行查询[27,28]。其中, 依据用户输入的术语确定与其相对应的概念部分主要过程为: 1) 实现数据库连接; 2) 创建本体模型, 将本体信息读入内存; 3) 对本体中的概念进行遍历, 找到与所输入术语相关联的概念; 4) 将查询结果即目标概念输出。核心代码如下。
OntModel model;
ModelMaker maker=ModelFactory.createModelRDBMaker(con);
Model base=maker.getModel(“educationDB”);
OntModelSpec spec=new OntModelSpec(OntModelSpec.OWL_MEM);
spec.setImportModelMaker(maker);
model=ModelFactory.createOntologyModel(spec,base);
for(Iterator i=model.listClasses(); i.hasNext();) {
OntClass c=(OntClass) i.next();
OntClass h=c.getEquivalentClass();
if(h.getURI().equals(URI+“教育学”))
System.out.println(“此术语对应的概念为”+c.getLocalName());}
从图4中的系统运行结果可见, 利用笔者构建的多语言本体, 可实现教育领域信息资源的有效组织与跨语言检索。

图4 基于多语言本体的信息检索系统界面Fig.4 The interface of information retrieval system based on multi-language ontology
5 结 语
跨语言信息检索是目前国内外信息检索领域的前沿课题之一, 笔者为解决教育领域信息资源的跨语言检索问题, 引入国际标准化组织罗什教授最新提出的本体术语学理论, 并结合教育领域叙词标准----《教育主题词表》构建出标准化的教育领域多语言本体, 实现了概念、 不同语言术语和资源的有效组织。并利用此本体构建出跨语言信息检索系统, 结果表明, 该系统所构建的多语言本体能很好地实现多语言知识组织, 促进跨语言信息检索向语义化发展。在多语言本体构建过程中, 笔者发现仅仅依据叙词表本身进行本体构建缺乏属性类叙词的标准化数据类型, 这是一个亟待解决的问题, 下一步将针对这些问题继续进行深入研究。
