一种面向网络安全的图像文字敏感词过滤方法
2018-10-08仵晨阳张悦健张滏钰
刘 伟,何 瑶,仵晨阳,张悦健,张滏钰
(1.电子信息现场勘验应用技术公安部重点实验室,陕西西安710121;2.陕西省无线通信与信息处理技术国际合作研究中心,陕西西安710121;3.西安邮电大学计算机学院,陕西西安710121)
互联网已成为我国居民检索信息、分享知识、获取服务的首选平台[1]。互联网具有自由、开放和交互等特点,这使得利用互联网进行诈骗、销售枪支炸药、贩卖毒品、制造和传播谣言、恐怖活动等犯罪活动成为可能,严重危害着社会安全与稳定,侵害了广大人民群众的利益[2-4]。复杂严峻的网络安全问题,是公共信息网络安全监察相关职能部门及相关研究单位共同关注和重点研究的热点。
电子论坛、微博、QQ、微信等社交工具是网络时代下网民交流的主要平台,网络犯罪嫌疑人主要利用这些平台进行违法犯罪活动。监控与过滤犯罪嫌疑人在这些平台上发布的敏感信息是预防和打击犯罪的重要环节。
有很多方法可以用来监控和过滤敏感文本信息。结合语义和统计模型筛选Web上敏感文本的方法,是对敏感文本的统计和语义特征进行分析[5];通过文本模式匹配,过滤社交网络用户所发布评论中的敏感信息系统[6];利用敏感词的组合信息改进过滤效果,在核方法的框架下特征共现行为建模的原则[7];基于Patricia前缀树建立分级敏感词库的方法,应用于社交网站中敏感信息的过滤,用以解决网站中的敏感信息安全问题[8];内网敏感信息检测系统采用全文检索和增量文件实时监控技术,通过建立敏感文件判定规则和敏感文件黑白名单机制,提高对内网终端计算机违规存储敏感信息检查的准确率和效率[9];针对传统文本特征抽取方法在应用于敏感信息过滤时出现的时间滞后、准确性低等问题,结合敏感信息特征,提出的融合意见挖掘和自然语言处理技术的敏感信息动态特征抽取方法[10];网络安全审计中敏感词检测系统的原型[11];基于网页敏感度的敏感网页分类监测策略以及基于敏感信息摘要的去重策略[12];基于敏感信息的挖掘算法提出的网络热点自动发现以及主题追踪的有效解决方案[13];商业化敏感文本信息监控与过滤平台,例如网易、百度和腾讯的敏感词分析和过滤平台[14-16],都取得了较好的应用效果。
近年来,有一些敏感文本信息被嵌入图像,躲过文本信息监控,发布到了社交平台上。检测图像中的敏感文字信息首先要自动识别图像中的文字,这是光学字符识别问题(optical character recognition,OCR)[17-18]。OCR 算法识别出的结果是单独字符,必须将其结构化才有意义,而目前的OCR平台和软件未考虑识别出字符的结构化问题[14-16,19]。已有的图像敏感文字检测研究中,采用BP神经网络算法和深信度网络对敏感信息进行检测,但是仅对背景简单、布局规范的文字[20];文献[21]研究了复杂图像文本提取方法并构建基于关键词的敏感网络图像过滤系统,但未深入讨论识别出字符的结构化问题。
针对上述不足,本文采用图像处理、文字识别和中文语言处理方法,提出一种面向网络安全的图像文字敏感词过滤方法。该方法首先采用连通域分析、连通域合并及倾斜矫正方法来定位与分割图像中的单个字符;之后使用预训练的卷积神经网络对单个字符进行识别;最后借助于预先定义的敏感词数据库,使用中文分词和字符串编辑距离来检测敏感词。
1 算法设计
1.1 算法框架
待检测的文本图像来自电子论坛、微博、QQ、微信等社交平台。对原始图像进行预处理(包括灰度化、二值化、去噪和形态学膨胀等运算),采用连通域算法对二值化图像处理得到各个联通区域;根据连通域的面积大小、长宽比等参数,确定文本区域;之后对单个字符进行分割与合并;最后判断识别出的字符是否倾斜,如果倾斜则进行倾斜矫正。单个字符分割结束后使用一个预先训练的卷积神经网络对单个字符进行识别;最后采用中文分词技术将识别出的汉字组织为一系列有意义的词语,并借助敏感词数据库判定其是否包含敏感词。算法原理如图1所示。
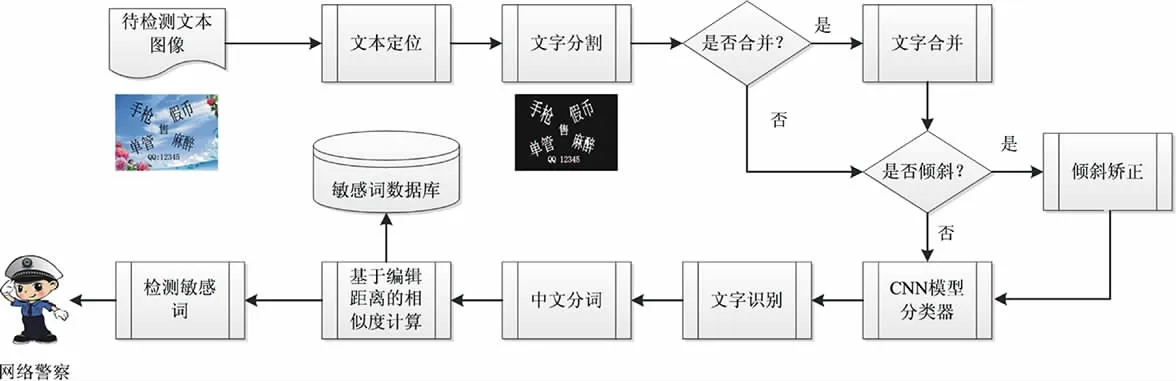
图1 算法原理
1.2 文本定位
文本定位是所提方法的第一个关键步骤。很多文字识别的场景中文字排列比较规范且背景简单(如文档识别),可以采用投影法等来分割字符。本文所处理的图像中的文字信息排列不规范,且图像背景较为复杂,因此采用基于八邻域标记的连通域方法进行文本定位。分析得到各个连通域,根据文字的特点采用一些预先设置的规则去除非文字区域从而得到最终的文字区域。判定非文字区域的规则包括连通域大小占图像一半尺寸甚至更多、连通域的长宽比例较大(可能是一条直线)或较小、连通域面积过小等。图2为处理示例。

图2 文字定位
1.3 文本合并与倾斜校正
连通域分析方法会定位出汉字的连通域,由于汉字本身的结构特征,该方法往往会把汉字的各个偏旁部首分割成不同的连通域,如图2(a)中的“管”字。必须将这些“离散”的连通域合并为一个汉字。
合并规则[22]:任取两个连通域,如果它们在水平和垂直方向上都足够靠近则合并为一个连通域。执行此步骤直至重叠字符中再没有连通域满足合并条件。这一级中在水平和垂直方向上对连通域合并的条件都有限制。上述合并法则中,水平方向上的“足够靠近”可以用该方向上的字符重叠率

式(1)中c1,c3分别是两个联通域最左边的列标号,c2,c4分别是两个连通域最右边的列标号,Tol是一个常量,设为0.4。类似也可以定义垂直方向上的重复率rolv。合并方法可以有效地将分离的汉字偏旁部首合并为单个完整的汉字。汉字合并示例如图3所示。图3(a)中的汉字“管”在连通域分析时被“分割”成不同的部分,通过合并算法将其合并,图3(b)中用反色显示。

图3 汉字合并
为了对抗OCR软件与敏感文本信息过滤系统,一些嵌入图像的文字往往会被设置为倾斜状态。这种情况需要将倾斜的文本进行校正以便于后续识别。本文在合并汉字偏旁部首后,根据图像中文字的几何位置将其划分为不同的区域,同一个区域中包含了几何位置上相邻的文字。之后计算每个区域中各个文字连通域的质心,如果发现这些质心的连线不在水平线上,说明文字是倾斜的,要采用校正算法将其校正为水平位置从而便于后续的文字识别。本文采用的校正算法是最小二乘法,即根据同一区域中各个文字连通域的质心拟合一条直线,然后利用得到的直线计算出文本行的倾斜角度,通过图像的旋转进行文本行的倾斜校正。
1.4 文字识别与敏感词检测
采用卷积神经网络用于单个字符识别。针对字母数字及汉字的识别分别采用2种网络模型。2种网络模型的结构类似,仅描述汉字识别网络,如图5所示。该网络输入为汉字二值影像,大小为32×32。前两层为卷积层,其卷积核的数目为16和32,卷积核的尺寸为分别为5×5和3×3。第3层和第5层为池化层,所采用的池化算法为最大值池化,池化操作的尺寸为2×2。最后一层卷积层的卷积核尺寸为3×3。第6层为全连接层。通过soft max进行字符的分类识别。优化方法选用随机梯度下降法,损失函数选取交叉熵法。

图5 汉字识别卷积神经网络模型
经过图5识别出的结果为包含单个字符的字符串,必须将其结构化才有意义。采用中文分词技术检测字符串中有意义的中文单词,基于预先定义的敏感词数据库判定识别出的中文单词是否包含敏感词。中文分词是较为成熟的技术,本文使用了结巴分词[23]。分词结束后要判断分词结果中是否包含敏感词。基于预先定义的敏感词数据库,采用字符串编辑距离的计算方法进行敏感词判定。定义度量值

式中,length(a)为字符串 a的长度,edit(a,b)为字符串a和字符串b的编辑距离。max(length(a),length(b))为a和b两个字符串长度的最大值。度量值S越大,表明两个字符串越相似。
2 实验结果与分析
2.1 实验环境与数据
实验计算机配置为CPU为Inter Core i5双核(64位处理器),2.50GHz;显卡为内存为 4G;GPU为NVIDIA GeForce 940MX;操作系统为Windows 7旗舰版(64位系统);实验程序用Matlab 2013b编写。
实验中的数据库包括3种:(1)用于识别单个字符的文字数据库,包括HCL2000手写数据库[24]、自建的一级汉字标准训练数据库(包括宋体、楷体、黑体等十几种常用字体)、数字和字母数据库(用于识别图像中的手机号码、QQ号码等敏感信息);(2)自建的复杂背景与布局下的文字图像数据库,包括210张图像,其中包含有敏感词的图像数据为100张。这些数据部分采集自互联网(如引发舆情的谣言文字图像)、部分数据是本文作者根据敏感词语料库合成的数据;(3)从网上下载的敏感词语料文字数据库,包括暴恐、反动、民生等词库。
2.2 结果与分析
为了对比文字识别结果,将分割后的单个字符归一化到同一尺寸,分别使用卷积神经网络(CNN)、支持向量机(SVM)和决策树算法(DT)进行字符识别比较。支持向量机采用多项式核函数进行多分类(预先实验表明多项式核可以取得最佳识别率),特征选用文字图像的Gabor特征。实验结果如表1所示。由表1可知,CNN模型取得了较高的识别正确率。

表1 字符识别结果
使用中文分词技术(结巴分词)对识别后的字符串进行分词以进行后续的敏感词检测工作。结巴分词支持全模式、精确模式和搜索引擎模式三种方式。由于下一步要进行文本分析,本文采用精准模式下的分词结果。分词结束后,使用字符串之间的编辑距离作为检测敏感词的度量函数,相似度较高的视为敏感词。本文对一些疑似敏感词进行识别处理,这些疑似敏感词可能源于文字图像识别错误,也可能源于人为因素的蓄意为之。表2给出了若干示例(表中“分词结果”一栏中用分隔线表示分词结果),表中有下划线的词语是疑似敏感词校正后结果。

表2 敏感词检测示例
从包含敏感词的文本图像数据库中随机挑选25、50、75、100幅样本图像进行检测,分别计算查准率、查全率及F1指标,结果如表3所示。

表3 敏感词检测结果

?
由表3可知,由于随机挑选的文本图像中可能包含敏感词(每幅图像中包含的敏感词个数也不一致),也可能不包含,计算的查全率和F1值随着数据的增大而增加,最高的查准率接近80%。这表明本文方法具有较好的检测效果。分别与文献[20]和文献[21]的实验结果进行对比,文献[20]对1 000个样本的最好识别率为93.7%;文献[21]对100个敏感文字图像样本的召回率为77%。由于文献[20]的研究对象是背景简单、布局规范的文字,所以本文实验结果和文献[21]的结果对比更合适。由表3可以看出,针对100个样本本文方法的召回率为82.24%,优于文献[21]的结果。由此说明本文方法的有效性。
3 结语
面向网络安全的图像文字敏感词过滤方法针对复杂背景与布局下的文本图像信息,采用OCR方法识别单个字符,并基于中文分词技术和敏感词数据库检测文本图像中包含的敏感词。实验结果证实了本文方法的有效性。
