监控视频中的车型分类方法
2018-10-08李大湘王小雨
李大湘,王小雨,刘 颖
(1.西安邮电大学通信与信息工程学院,陕西西安710121;2.电子信息现场勘验应用技术公安部重点实验室,陕西西安710121)
随着车辆的迅速增加,智能交通系统(Intelligent Transportation System,ITS)已经成为学术界、工业界和政府的首要议程。ITS最重要的任务之一是车型分类、车辆识别和跟踪[1-3]。近年来,基于图像或视频的车辆分类由于其在智能交通系统中的重要性而引起了越来越多的关注。准确可靠的车型分类系统对于有运输管理、安全监控、执法记录、自主导航等[4]场景任务是必不可少的。例如在警方调查涉嫌车辆犯罪时,由于目前的监控摄像系统只提供视频图像记录,警察需要在大量的交通图像或视频中手动搜索,以找到特定类型的车辆,这种方式耗费大量的时间、人力、物力和财力。因此,车型分类的研究对于警方破案至关重要。
车型分类一般包括三个步骤,首先是对车辆检测,即在视频图像中检测到车辆,然后对检测到的车辆图像进行特征提取,最后根据这些特征分类。本文将从车型分类常用数据集、评价指标、特征提取方法、分类方法这几方面介绍。
1 车型分类数据集
用于车型分类的数据集很多,但是目前常用的车型分类的数据集有:CompCars数据集、StanfordCar数据集、BIT-vehicles数据集。
1.1 CompCars数据集
CompCars数据集[5]是一种比较全面的综合汽车数据集。该数据集的图像主要来自网络图像和监控视频图像,其中13626张车辆整体图(都被标记了包围框、视角、颜色、排量、最大速度),27618张车型属性图,分别为前灯、尾灯、雾灯、进气格栅、中控台、方向盘、仪表盘和变速杆,如图1所示。
该数据集包含163种汽车的1716种型号。该数据集可下载于“http://mmlab.ie.cuhk.edu.hk/datasets/comp_cars/index.html”。

图1 汽车配件
1.2 StanfordCar 数据集
StanfordCar汽车数据集包含196个等级的汽车的16185个图像[6]。这些数据被粗略地分成了两部分,一部分是8144张训练图片,另一部分是8041张测试图像。分类通常在制造商(Make)、型号(Model)、生产年份(Year)等级别进行,比如2012特斯拉Model S或2012宝马M3 coupe。其中BMW10数据集是用于车辆细粒度分类,包含11种不同的“宝马”车型。
图2列举了数据集中的几种不同型号的车型图像。该数据集可下载于“http://ai.stanford.edu/~jkrause/cars/car_dataset.html”。

图2 车型样图
1.3 BIT-vehicles数据集
BIT-Vehicles数据集是由北京理工大学实验室搜集整理的用于车型分类的数据集。共包含9,850张像素为1600*1200或1920*1080的车辆图像,它们分别由两个摄像头在不同时间和地点的拍摄。数据集共有6类车型图像:公共汽车(Bus)、微型客车(Microbus)、小型货车(Minivan)、轿车(Sedan)、SUV(Sport Utility Vehicle,即“运动型多功能车”)和卡车(Truck),如图3所示。
每类车的数量分别为 558、883、476、5922、1392 和822。该数据集可下载于“http://iitlab.bit.edu.cn/mcislab/vehicledb/”。

图3 数据集车型样图
1.4 数据集对比
这三种数据集各有各的特点,表1从数据集大小、车型类别以及属性方面对三种数据集进行对比。BIT-Vehicles数据集只包含六种车的类型,没有关于车的具体属性,而StanfordCar数据集主要包含轿车和SUV车型的多种子类型,对车型的划分具体到制造商、型号、年份等。CompCars数据集不仅集合StanfordCar数据集的车型属性,还专门增加了车型的属性图,包含了更加详细的车的配件信息。BIT-Vehicles数据集多用于传统的底层特征提取,而CompCars数据集和StanfordCar数据集多用于训练和测试深度学习模型。
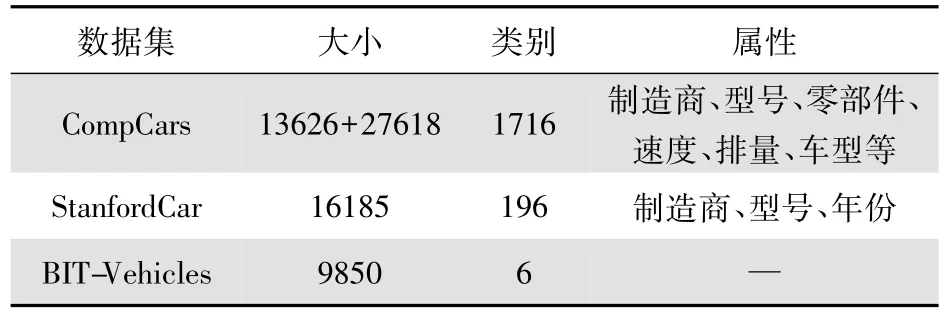
表1 数据集对比
2 评价指标
混淆矩阵是用于比较分类结果和实例之间的匹配信息。如表2所示,在混淆矩阵中,TP表示系统预测为正的正样本数量,FP表示系统预测为正的负样本数量,FN表示系统预测为负的正样本数量,TN表示系统预测为负的负样本数量。

表2 混淆矩阵
由混淆矩阵可以得出一些评价指标。
(1)精确率(Precision)。又称查准率,定义为

(2)召回率(Recall)。又称查全率,定义为

(3)F分数(F-score)。它是查准率和查全率的调和值,用来评估分类模型,定义为

当β=1时,称为F1分数,精确率和召回率权重相同;
当β<1时,精确率更重要;当β>1时,召回率更重要。
(4)准确率(Accuracy)。反映了分类器对整个样本的判定能力,即将正的样本判定为正类,负的样本判定为负类的总比率。定义为

(5)平均精确度mAP。它是多次实验精确度的平均值,由于实验的随机性,多次实验求平均值,以提高实验可靠性。
(6)ROC曲线和AUC。ROC(receive operating characteristic)曲线显示了模型在判别正样本时,当改变其阈值,召回率和精确率的关系如何变化。曲线的坐标分别为正确率和错误率。如图4所示,是一个分类器的ROC曲线。计算ROC曲线下的面积AUC(area under curve),用来量化分类模型的性能,其取值范围是[0,1],度量值越高,则分类性能越好。
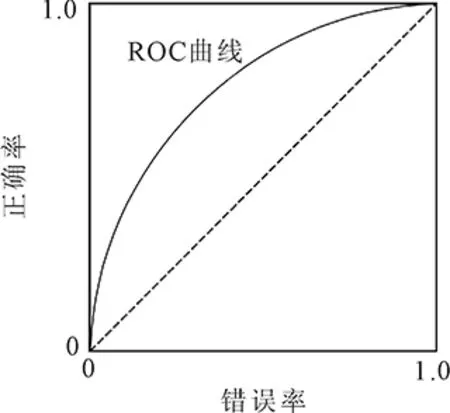
图4 ROC曲线图
3 车型分类中的特征提取技术
3.1 底层特征及特征融合
3.1.1 Gabor/wavelet小波特征
由于Gabor小波在提取目标的局部空间和频域信息方面具有良好的特性。Gabor核函数定义为

2007年,文[7]提出一种基于Gabor小波滤波银行(Gabor Filter Bank)的车辆抽样模型算法。由于不同类型车辆之间的差异(例如前后部的形状、车窗的位置等)主要在车的上部,在图像上部取一定比例进行抽样,用抽样后的Gabor特征表示图像。文[8]用Gabor小波提取车辆的Gabor特征作为车辆的特征表示,然后对Gabor特征进行主成分分析(principal component analysis,PCA)得到最终的车型图像特征。文[9]提出一种基于变换半环投影(transformations-semi-ring-projection,TSRP)和离散小波变换(discrete wavelet transformation,DWT)分形特征融合的图像特征表示方法。变换环投影(transformation-ring-projection,TRP)具有尺度和二维旋转不变性,可以将二维模式转换为一维模式。选择TRP作为基本工具从二进制文件中获得车辆的形状特性,使用4次TRP在车辆图像平面上的不同位置获得四个一维模式,利用DWT将四个一维模式分解4个层次,得到四个近似信号,然后计算Boxdimensions并生成形状描述符。
3.1.2 特征融合及稀疏编码
近年来,研究者们发现将车型图像的底层特征融合并进行稀疏编码,对车型分类效果较好。稀疏编码代价函数定义为
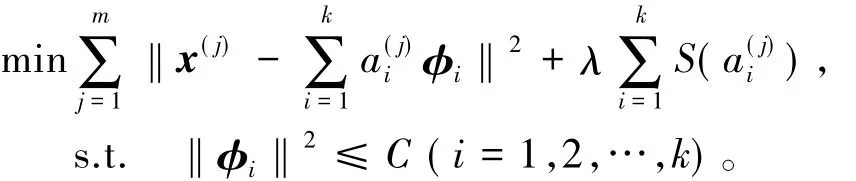
文[10]在2009年提出用稀疏编码对线性空间金字塔匹配(spatial pyramid matching,SPM)对图像进行分类的方法。通过构造与自然图像局部区域相一致的高维抽象的图像特征,稀疏特征表示备受青睐,基于稀疏编码的图像分类,在一些公开的数据集,如 NORB,Caltech,MNIST,ImageNet中,准确度最高。于是,文[11]对车辆图像进行稀疏特征表示,用学习字典的稀疏线性组合来表示车辆图像,除了少数非零值外,大部分对应系数都消失了,稀疏编码特征揭示了车辆图像的自然稀疏性的最基本的特征。文[12]将得到的稀疏特征直方图进行空间金字塔池化来表示图像。文[13]在前人的基础上,引入核方法,提出一种中心增强SPM(center enhanced SPM,CE-SPM)的核稀疏表示来表征车辆图像特征的方法。
文[14]先得到方向梯度直方图(histogram of oriented gradient,HOG)和 HU 矩(HU Moments)这样的空间局部信息,然后把这些空间局部信息稀疏表示,最后得到图像特征。文[15]先对图像提取尺度不变特征(scale invariant feature transform,SIFT),再对SIFT特征进行稀疏编码,然后对编码后的SIFT特征进行多尺度空间最大池化(max pooling),得到图像局部特征。图像全局结构特征用颜色密度值表示,最终将局部特征和整体颜色特征结合构成图像的特征表示。
3.2 2D/3D 模型特征
文[16]在2012年提出一种三维模型匹配方法来表示图像特征。文[17]2013年提出一种三维图像表示方法。在车辆的三维外观表面进行补丁采样,然后在修正补丁上密集地采样了RootSIFT[18]描述符,进而可以得到一个三维金字塔(3D spatial pyramid,SPM-3D)和三维气泡银行(3D bubble bank,BB-3D),接着分别通过三维池化,得到相应三维特征表示。
文[19]在2016年提出了一种在车辆的三维模型上提取矢量长度和角度特征的方法。通过跟踪车辆上的两个兴趣点(points of interest,PoI),可以让这些点组成三维几何图形,这对于每类车型是独一无二的。通过技术兴趣点间的矢量长度和角度,得到车辆图像的表示特征。他在2017年对该方法进行了改进增强,将两个兴趣点扩展到三个兴趣点,并增加了多个欧拉角等额外的特征矢量。
3.3 不同特征提取方法对比
从BIT-Vehicles数据集中随机选取660张车型图像,每类车型图像110张,用每类中50张图像作训练集,剩余的作测试集。分别提取车型图像的小波和HOG直方图特征,HOG直方图和HU矩特征,SIFT特征,然后用标准SVM进行分类。分析不同特征提取方法的性能。
三种不同特征提取方法的分类效果如表3所示。其中B1~B6分别表示公共汽车、微型客车、小型货车、轿车、运动型多功能车和卡车。mAP是平均分类精度,因为训练和测试时的数据是随机的,所以选取10次试验的平均值。由表3中可以看出,图像的小波和HOG直方图特征的分类平均准确度是72.17%,比其他两种特征提取方法都高。是因为:小波特征是纹理特征,HOG和HU矩是形状特征,小波和HOG融合是两种不同类型特征的融合,而HOG和HU矩是同一类型的特征,融合起来效果没有不同类型特征融合的效果好。对图像提取单特征(SIFT特征)进行分类,分类准确度为61.37%,不及两种特征融合的方法。

表3 不同特征提取方法分类结果(%)

B6 75.36 76.79 65.36 mAP 72.17 69.49 61.37
图5展示了每类车型三种不同的特征提取方法的AUC值对比结果。对于客车、轿车和卡车,用小波和HOG特征与HOG和HU矩特征进行分类,效果较好,是因为这三种车型的外形差异较大。而对于微型客车、小型货车和运动型多功能车,这几种特征提取方法的分类效果均不理想,是因为这几种车型相似度大。
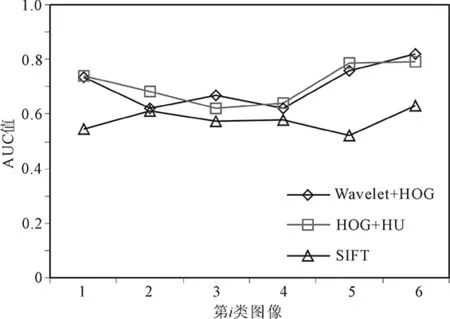
图5 第i类图像的AUC值
图6 中给出卡车图像小波和HOG特征、HOG和HU矩特征和SIFT特征的ROC曲线和AUC值,可以看出,基于卡车的小波和HOG特征和HOG和HU矩特征的分类性能都较好,且分类性能比较相近。但基于SIFT特征的分类性能差。
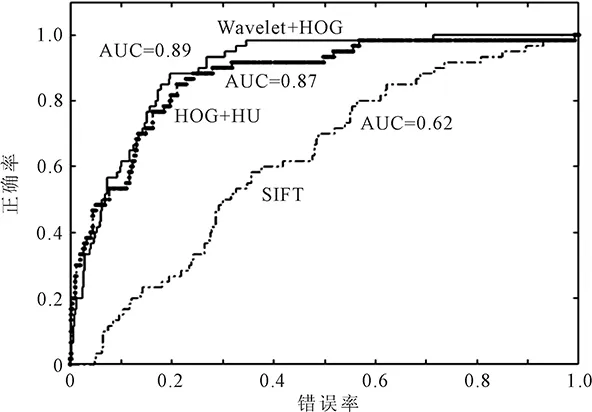
图6 卡车的ROC曲线和AUC值
4 经典车型分类方法分析
4.1 基于深度学习的分类方法
文[20]用反向传播(back propagation,BP)神经网络在视频图像中进行车辆分类,达到了86%的正确率。文[21]从视频中获取了1000张车辆图像用BP神经网络分类,正确率达到93.60%。文[22]用神经网络将包含5类共622张车辆图像进行分类,正确率为 91.50%。文[23]用量子神经网络(quantum neural network)进行车辆分类,在120张的数据集中把车分为4类,正确率达到96.70%。
文[24]提出一种基于视觉注意力(visual attention)的 CNN(convolutional neural network)模型,简称为“CNNVA”。该模型采用强化学习(reinforcement learning)算法对视觉注意力进行可视化处理,通过对车辆图像的引导索引和视觉关注来捕获车辆图像的关键区域,然后送入CNN进行分类。在CompCars数据集上进行分类训练,达到了96.40%的正确率。文[25]从监控视频中获得车辆图像,用CNN对有标签图像进行分类训练,正确率达到 98.79%。文[26]使用 JF(Jint Fine-tuning)[27]微调整个CNN模型。传统的dropout[28]算法是防止深度神经网络的过拟合,作者提出droping CNN算法,最大化JF的性能,以提高分类正确率。
文[29]用深度置信网络(deep belief network,DBN)把车辆分成四类,准确率达到89.53%。
4.2 传统机器学习的分类方法
(1)K最近邻
K最近邻(K-nearest neighbors,KNN)算法是1968年由Cover和Hart提出,应用在字符识别、文本分类、图像识别等领域。KNN是通过测量不同特征值之间的距离进行分类。选取未知样本x的k个近邻,在这k个近邻中,大多数属于哪一类,就把x归为哪一类。其优点是实现简单,分类结果比较好。其主要缺点是对计算机的存储量和计算量的要求很大,耗费大量测试时间;没有考虑决策的风险;对其错误率的分析都是建立在渐进理论基础上的。文[30]运用三维点云(3D point cloud)特征用KNN模型将车分为摩托车和汽车两类,正确率达到95.80%。
(2)支持向量机
支持向量机 (support vector machine,SVM)[31-32],通过找到一个分类平面,将数据分隔在平面两侧,从而达到分类目的。如图7所示,空心点和实心点分别代表不同的类别,直线是分类线。SVM有线性和非线性两种。非线性SVM分类器在训练中有O(n3)的计算复杂度,在测试中有O(n)的计算复杂度。高计算复杂度意味着非线性SVM分类器在实际应用中的可扩展性差,训练规模通常很大。与此相反,线性SVM分类器在训练中的计算复度较低,并且在测试中具有恒定的复杂度,其显著低于非线性SVM。文[33]对车辆图像稀疏编码后的SIFT特征进行线性SVM分类,把车分为六类,准确率达到96.12%。文[34]将车辆图像的HOG特征送入线性SVM分类器,错误率是10%。
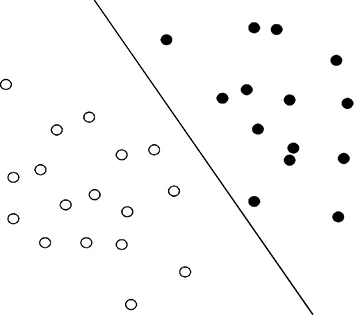
图7 SVM的最优分类线
4.3 分类算法对比
表4中给出了基于深度学习的分类方法和传统机器学习的分类方法对照。可以看出,在基于深度学习的分类方法中,用CNN进行分类,分类效果最好,但其对硬件设备要求高,所需的训练数据量大,耗费时间长。传统的SVM分类,若提取的特征恰当,分类效果也较好,其分类能力可以和CNN媲美,但是不适用于大样本数据。同样是二分类,KNN的分类效果比BP神经网络好,说明样本类数少时,传统的分类方法要比神经网络效果好,但是KNN要耗费大量测试时间。
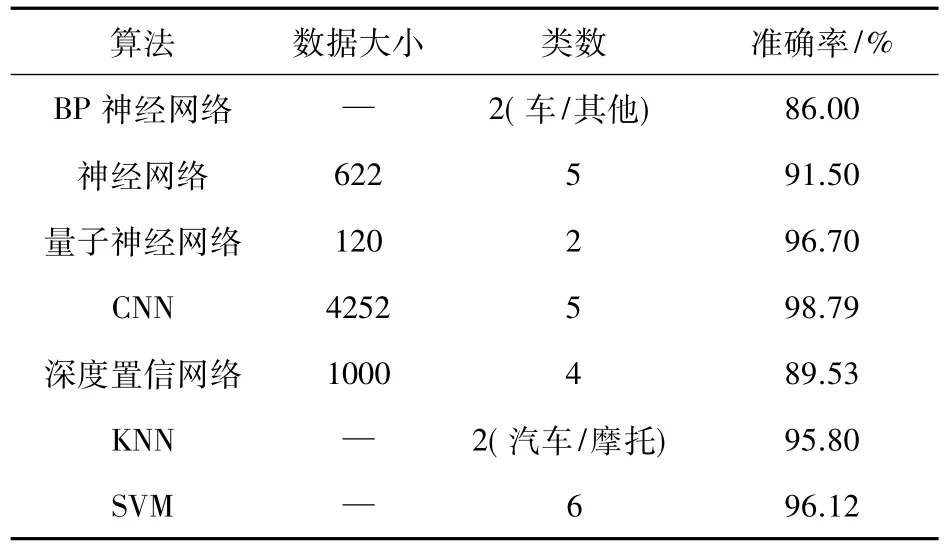
表4 各种分类算法结果对比
5 结语
文中介绍了近些年来,对于车型分类问题,研究人员常用的特征提取方法和分类方法,在数据集上实验,结果较好。但是,在现实中由于光照、天气、摄像头清晰度等因素,从监控视频中获取来的图像不清晰,这对图像的特征提取造成很大干扰,需要进一步研究更加有效的特征提取方法,例如将传统的特征提取技术和深度学习相结合等。对于极相似车型的分类还不够准确,因此,细粒度车型分类算法也还有待于探索研究。
