基于孤立点异常度的Web攻击数据挖掘算法∗
2018-09-27张路青
张路青
(海军驻中南地区光电系统军事代表室 武汉 430223)
1 引言
近年来,随着互联网的不断发展,我国网站数量持续增长而网站所面临的安全问题也愈发严重。图1是360互联网络安全中心给出的每月存在高危漏洞的网站个数。其中,9月扫出的有高危漏洞的网站数最多,达到71964个。虽然通过网站的日志分析,网站管理人员可以清楚地获取用户的访问行为,但是由于网站产生的日志文件较大,数据量较多,包含的数据类型多样化,文件格式不统一等原因,手工进行日志文件分析需要消耗大量的人力成本和时间成本,因此如何使网站的管理者从繁重的手工分析日志文件工作中解脱出来,能够有效识别针对网站发起的恶意攻击行为,并深度检测网站是否具有潜在的安全漏洞,保障网站业务能够正常稳定安全的可持续执行,对建设网络信息安全体系有着极为重要的意义。
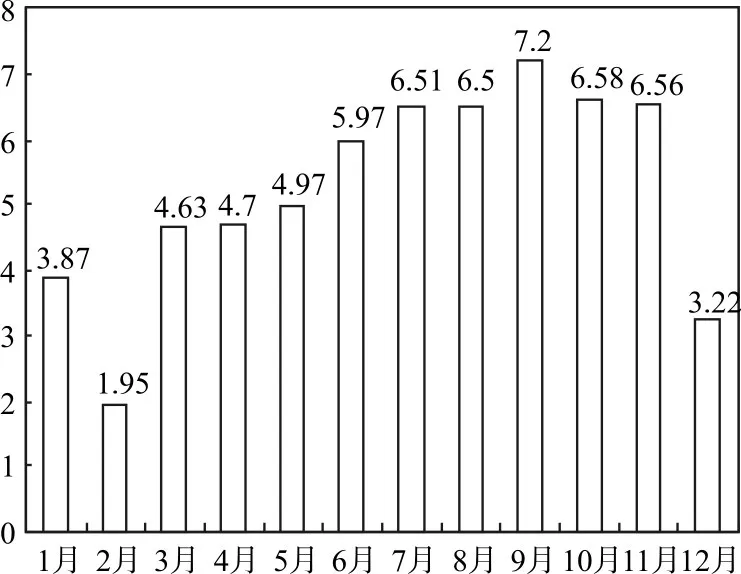
图1 每月存在高危漏洞的网站个数
Web日志挖掘系统的概念由Cooley R首次提出,该系统首先是处理客户访问网站所留下的日志信息,并将日志信息中的数据转换成传统数据挖掘算法能够处理执行的数据格式,从而可以采用传统的挖掘技术进行处理,最终获得有用的信息。Spiliopoulout提出了一种从Web日志中构造聚集树的算法,并建立了一个访问模式挖掘器WUM(Web Utilization Miner),然后使用MINT挖掘语言在WUM中挖掘访问模式[1]。为了发现攻击和异常行为,Suneetha K R利用新的预处理技术与改进Apri⁃ori数组向量算法,提出了一种针对Web日志记录更加优化的处理方法[2]。
以上研究成果对于Web攻击数据挖掘技术研究具有很大的指导和借鉴意义。但是其中还存在一些不足之处:缺乏日志数据隐藏关系的发现,致使数据丰富,信息匮乏的现象;目前对Web日志的分析还是以访问统计及用户查询方面较多,缺乏对日志中的孤立点的挖掘以及对日志中各项之间的关联规则的发现,因此难以达到对Web日志中攻击数据挖掘的要求。论文则从数据挖掘的角度,研究聚类分析的数据挖掘方法,并在此基础上继续展开研究。提出了基于孤立点异常度的攻击数据挖掘算法,针对Web应用漏洞和攻击行为建立了检测模型,并对算法进行了实验验证。
2 Web日志数据挖掘
Web日志主要是服务器用来将客户在网上的访问记录或在站点上进行的一系列操作的行为记录保存在服务器的日志文件上,以作为日后处理问题的一个追溯和根据[3]。随着计算机技术的高速发展和大容量存储设备的出现,使得Web服务器可以存储海量的Web日志文件数据。Web日志挖掘就是通过分析日志文件中的记录可以审查客户浏览Web页面的模式和执行的操作,进而推断客户访问行为[4]。
2.1 Web日志挖掘的过程
如图2所示是Web日志挖掘的总体流程[5]。
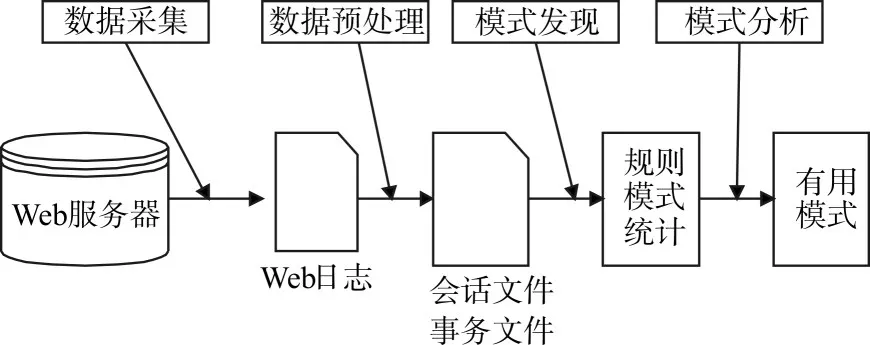
图2 Web日志挖掘的主要过程
首先通过数据采集从Web服务器中取出所需要的Web日志文件;然后经过数据预处理对这些日志文件进行按要求的处理,往往是删除冗余数据与系统噪声,得到的是经过清理之后的会话文件与事务文件;再通过模式发现建立数据项之间的规则或者模式,其中模式发现可以选择多种不同的分析技术,如关联分析与聚类分析等;最后采用有用的模式进行分析,挖掘出最终的结果。
2.2 Web日志数据预处理
由于在数据收集阶段采集回来的数据不能保证是完整的,且在结构上存在多种格式,或有许多冗余的数据。针对这个问题,需要先对原始Web日志文件进行数据预处理,将数据转换成结构化的统一格式,并过滤掉重复的或无用的信息才能提高数据分析的效率。
对于攻击数据挖掘来说,Web日志数据预处理主要需要进行数据清理、用户识别、会话识别与路径补全这四个方面的操作[6]。
2.2.1 数据清理
数据清理主要是指通过填写缺少的数值、识别或删除离群点、删除对挖掘结果无用的数据来“清理”数据。它主要是用来清理数据文件中出现的误差,以及一些可能对挖掘结果影响较大的特殊值。数据清理需要达到以下几个目标:格式标准化、异常数据清除、错误纠正以及重复数据清除[7]。对Web日志进行数据清理有多种方法,且目的不尽相同,因此需要根据每次挖掘任务的不同,选择合适的处理方法对Web日志进行清理。
2.2.2 用户识别
在Web日志数据挖掘之前,需要对用户进行识别,来确定这些数据是否都来源于同一用户还是多个用户。因此可以利用以下的启发式规则来进行用户识别:
1)以IP地址来识别用户。
2)如果IP相同,则以浏览器或操作系统版本来识别用户。
3)如果IP相同,且浏览器与操作系统也相同,那么可通过网站的拓扑结构来识别用户。
2.2.3 会话识别
会话识别是指将用户的访问请求按时序进行分片,形成多个相互独立的序列,每一个会话序列对应着用户那一段时间内的连续操作,因此研究分片后的会话序列,更有利于发现用户的访问模式以及浏览爱好,甚至可以察觉哪些会话可能属于攻击行为。
基于Web日志请求的用户会话识别需要设定超时阈值,通常有两种方法判断用户是否开启了新的会话,第一种是判断整个会话时间是否已经超时;第二种是判断两个请求页面的时间差是否达到超时阈值。
2.2.4 路径补全
路径补全就是对用户的访问路径进行补充,在日志引用不完整的情况下,可以利用网站的拓扑结构来补充路径[8]。只有构造出完整的用户访问路径,才好分析用户的行为是否存在恶意攻击。目前主流的路径补全算法是利用网站本身的拓扑结构来进行用户路径补充,而算法的主要问题是如何判断用户浏览序列中两个连续页面间需要做路径补充。这里提出一种判断方法,即:对于同一用户的连续浏览页面P1、P2,如果P1是P2的引用页面,则无需做路径补充;如果P1与P2并无直接相连关系,则说明用户在浏览了P1页面之后又浏览了其他页面或点击了回退操作再去浏览P2页面的,这里就需要对P1和P2间做路径补充。
这里通过寻找匹配父节点来进行路径补充。即当P1和P2间需要进行路径补充时,首先判断P2与P1的父节点是否相同,如果相同,则P1与P2都是通过此父节点访问的,否则就进一步寻找各自的父节点,并依次比较,直到找到相同的父节点。
2.3 Web日志分析
经有效处理后的Web日志存有多种HTTP请求信息,这些请求信息包含有很多的参数,而且参数的类型也不完全一样,可以分为数值型参数和分类型参数两种。HTTP请求信息主要涉及的参数有HTTP请求方法、服务器返回码、响应包长度以及URI的各种参数等。将这些属性设置为HTTP请求的属性向量,并将它们分成方法属性、统计属性以及参数属性三类,如表1所示。

表1 HTTP请求中各属性及其类型
3 基于聚类分析的孤立点挖掘技术研究
聚类分析是将有共同特征的对象实例聚成一类的过程。聚类与分类不同的是,在做聚类分析前并不知道会以何种方式或根据来分类,因此聚类分析的学习过程并不依赖于预先设定的训练样本[9]。
典型的聚类分析过程可以分为三步,如图3所示。

图3 聚类分析过程
模式表示的是聚类算法的基础,通过特征提取或选择用来生成新的簇。
模式相似性是聚类分析的最基本问题,通常通过定义模式间的距离函数或异常度来描述。
聚类划分是聚类分析的核心,如何将对象划分到不同的簇中,直接影响到聚类的结果。
3.1 孤立点挖掘
孤立点是指数据集中的那些小模式数据,也称为异常点或离群点。它有可能是测试或执行错误时引起的,也可能是数据的某种变异性的结果。目前学术界对孤立点并没有一个确切的定义,但却有多种描述性定义。Hawkins给出了其本质性定义:孤立点是在数据集中与众不同的数据,使人怀疑这些数据并非随机偏差,而是产生于完全不同的机制[10]。Weisberg将孤立点定义为“数据集中与其他数据不服从于同一统计模型的数据”[11]。
在普通的数据挖掘中,孤立点一般是要被清除掉的,因为它相当于数据中的噪声,对挖掘结果或多或少会产生影响。不同的是,在对网络用户攻击行为进行数据挖掘时,孤立点反而是必不可少的,一个孤立点就有可能是一种攻击数据源。目前常用的孤立点挖掘方法大体可分为以下几类:基于统计学方法、基于距离的方法、基于密度的方法以及基于偏离的方法[12]。
3.2 距离函数
在对于孤立点挖掘算法中,对象间的距离定义是非常重要的。HTTP请求中的对象属性往往包含多种类型属性,如表1所示。HTTP请求中的属性一般可分为数值属性和分类属性,其中分类属性又可以根据数值的类别分为布尔属性、符号属性、顺序属性等。因此,在定义距离函数时,不仅要计算不同属性之间的距离,还得考虑不同属性的权值问题,以平衡不同属性对对象的贡献程度的差异。
4 基于孤立点异常度的Web攻击数据挖掘算法
4.1 异常度
给定数据对象集合T,对象p=[p1,p2,…,pn],q=[q1,q2,……qn],p,q∈T。其维度为 n(对象的属性个数,其中na是数值属性个数,nb是na分类属性的个数,n=na+nb)。
定义1 数值属性的质心为对象各数值属性值的算数平均值,即:
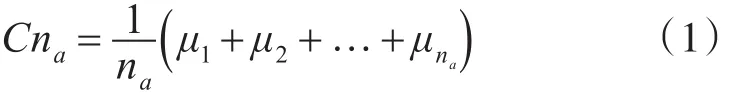
定义2 分类属性的质心为对象各分类属性中取值频率最高的值的算数平均值,即:

这里假定T中第k(na<k≤n)个分类属性的取值范围为{a1,a2,…,an},count(ai)表示属性k取值为ai的次数,则Fk(ai)表示属性k取值为ai的频率。Fm(k)为属性k中取值最大的频率,Vk为属性k中最大频率出现时的取值,则有:

综合得到数据集T的质心如式(6)所示:
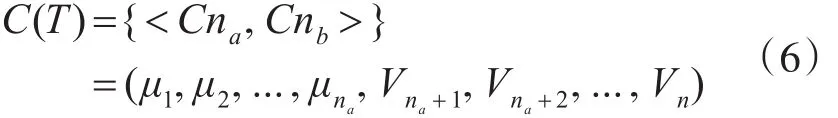
定义3 对象p在数据集T中的异常度OF(p)为p与数据集T质心的距离。
这里把数据集T的质心看作是一个虚拟的对象o,然后根据多维属性距离函数计算出对象p的异常度:
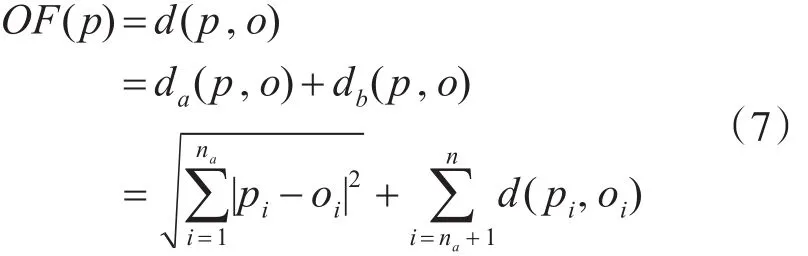
4.2 有约束聚类
算法以URI作为类别标志,把不同的URI聚集在不同的簇中,然后再分别进行孤立点挖掘。对于同一个簇来说,它们拥有相同的URI,并且各个参数也基本相同,选出一些合适的参数作为参考属性,这样就构成了一个具有多维属性的数据对象。
有约束聚类的过程如图4所示。
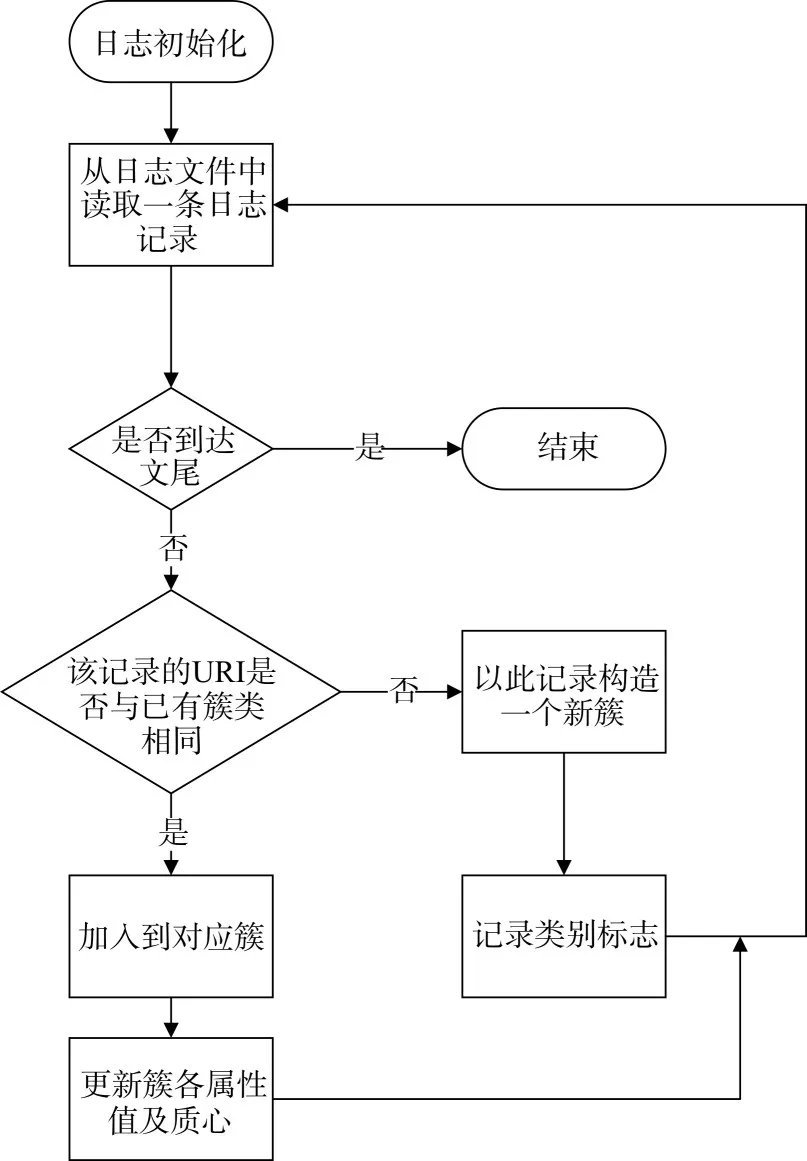
图4 Web日志有约束聚类过程
首先进行Web日志文件初始化,读入一条记录并构成一个新的簇,并将该记录的URI作为这个簇的类别标志,然后再继续读入下一条记录,若此记录的URI与已经存在的簇的类别标志相同,则将此记录存入对应的簇中,并更新该簇的各类属性的质心,否则,以此记录的URI建立一个新的簇并标志。依次重复之前的操作,直到读完Web日志文件的每一条记录,最终完成有约束聚类过程。
4.3 挖掘算法
基于异常度的孤立点挖掘是针对大量的日志文件来进行的,因此可以引用统计学方法中的中心极限定理,即大量相互独立的随机变量,其均值的分布以正态分布为极限。
令随机变量X服从正态分布,即 X~N(μ,σ2),查表可得知:

从以上结果中可得知,当1≤β≤2时,可以将概率P(X≥μ+βσ)控制在一个很小的范围内。而在大样本的情况下,异常度OF(p)可以近似地看做服从正太分布。因此,可以设计挖掘算法如下:
第一步,按照不同的HTTP请求的URI生成有约束的聚类T={T1,T2,…,Ti,…,Tn},并计算各聚类的质心。
第二步,扫描每个聚类Ti,计算Ti中的每个对象p的异常度OF(p)、平均值μ_OF(p)以及标准差σ_OF(p)。如果满足式(9)则判断对象p为孤立点。
OF(p)≥ μ_OF(p)+ β*σ_OF(p) (1 ≤ β ≤ 2)(9)
5 实验分析
5.1 数据准备
5.1.1 数据源
测试数据主要来源于两台服务器主机的Web日志,一台采用的Windows2003系统并搭建的Apache服务器,另一台采用的Centos系统并搭建的Nginx服务器。其中Apache服务器主要搭建的是渗透测试平台,因此其日志中会存在大量的攻击数据;Nginx服务器搭建的是常见cms系统,因此其日志中将会以正常数据为主。
5.1.2 测试环境
本机测试环境为系统版本为Windows 7旗舰版,处理器为 Intel(R)Core(TM)i5-2400 CPU@3.10GHz,内存为4G,采用python语言进行算法编程及实验。
5.1.3 数据预处理
本测试数据并没有达到海量数据的要求,但也应按规范在数据挖掘前进行数据预处理。比如对于服务器返回状态码为206(Partial Content,部分内容)、304(Not Modified,未修改,采用缓存拷贝)、408(Request Timeout,请求超时)这几种确定不是攻击数据或对挖掘攻击数据无帮助的记录可以事先清理掉。
在预存格式的时候,因为这里主要研究的是基于行为的Web攻击数据挖掘技术,并无探讨到攻击数据挖掘后的攻击溯源,所以在测试时,关于IP项以及客户端浏览器信息记录项都可删除。
又由于日志记录本身是按时间进行排序的,在数据预处理统一格式后可以删除时间项,这样又可以节省出部分的数据空间。
5.2 结果分析
从服务器日志中提取出20000条日志记录,其中包含有19120条正常HTTP请求以及890条攻击数据。根据第四章的基于异常度的孤立点挖掘算法得到检测结果如表2所示。
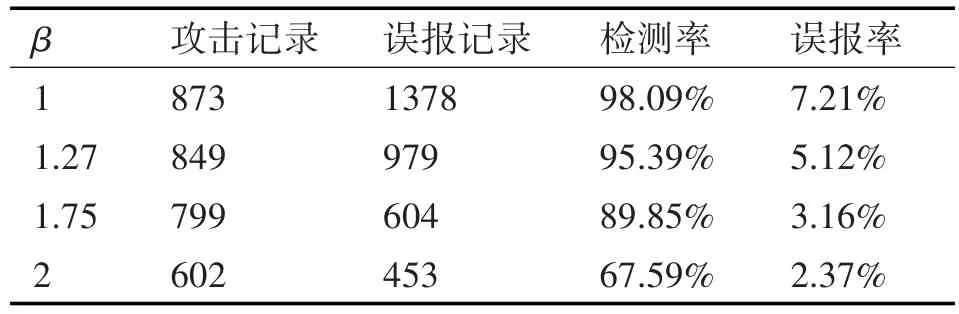
表2 基于异常度的孤立点挖掘检测结果
由表2可以看出,基于异常度的孤立点挖掘算法能够有效地检测出攻击行为,并且检测率与β的大小成反比,即β越小,检测率越高,但同时误报率也越高。通常需要对β进行合理的取值,一般可将β取值1.27左右,既能保证很高的检测率,而且也仅有5%左右的误报率。
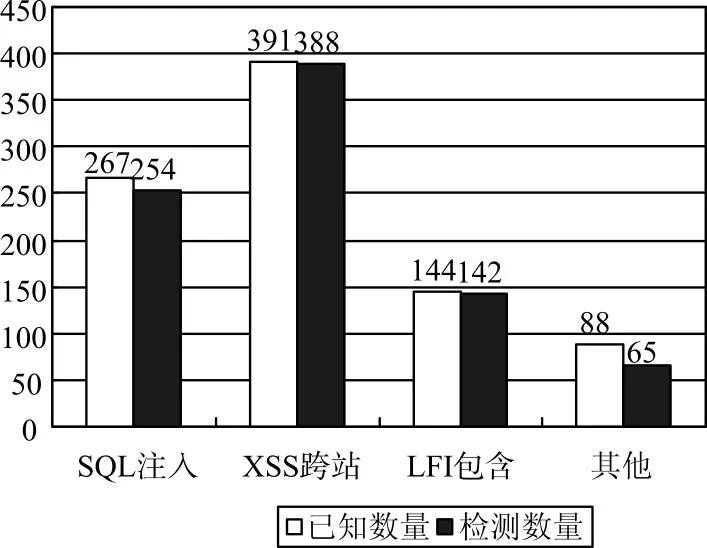
图5 针对已知漏洞的检测率
图5显示的是基于孤立点异常度的挖掘算法对已知漏洞的检测效率图,给出的890条样本攻击数据主要可分为四种类型,即SQL注入攻击、XSS跨站攻击、LFI本地文件包含攻击以及其他攻击。可以看出针对URI攻击特征很明显的XSS跨站攻击数据与LFI本地文件包含攻击数据的检测率极高,仅有个别案例逃过了检测。同时SQL注入攻击数据的检测率也较高,只是一些特殊的或经过精心编码绕过的攻击行为未能检测出来,而其他类型的攻击有些并不属于孤立点范畴,则应继续采用其他的挖掘算法进行辅助测试分析。
6 结语
文中首先分析了Web日志HTTP请求包信息的特点,利用约束聚类方法对Web日志中的HTTP请求数据进行聚类,并定义了簇的质心,给出了异常度函数计算公式,然后利用统计学的思想,提出了一种利用近似正太分布的检测模型,研究出基于孤立点异常度的Web攻击数据挖掘算法。实验证明该算法对XSS跨站攻击、LFI本地文件包含攻击以及常规SQL注入攻击有较高的检测率。后续的工作将致力于分布式挖掘研究以应对真实海量的Web日志系统。
