Hadoop平台下Mahout随机森林算法的分析与实现∗
2018-09-27曹蒙蒙郭朝有
曹蒙蒙 郭朝有
(海军工程大学动力工程学院 武汉 430033)
1 引言
随着信息技术、物联网及互联网的快速发展,数据正在以空前的速度产生和被收集。目前,各个行业都存储了海量的数据,如何从这些海量的数据中挖掘出有价值的信息是亟需解决的问题。分类方法可以有效地解决该问题,它通过对已知类别的数据集进行学习,从中找出分类规则,进而对新的数据集进行预测判断。但海量数据的处理对传统分类算法提出了新的要求。为了提高分类算法的准确率和减轻计算机的计算负载,采用大规模计算机集群对海量数据进行分布式处理是一种有效的方法。
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,其源于Google的云计算基础架构系统,核心组成是HDFS分布式文件系统架构和MapReduce分布式处理机制,可用于实现大规模分布式计算和并行处理。Mahout是来自Apache的、开源的机器学习软件库,它基于MapReduce模式封装了大量的适用于数据挖掘的经典算法,其中的部分算法通过转换可以直接在Hadoop框架上进行使用,从而大大降低了大数据应用中并行数据挖掘产品的开发[1]。在大数据的处理上,目前Hadoop已经成为搭建云计算平台的主流,国外IBM的蓝云、雅虎及英特尔的“云计划”等,国内阿里巴巴、百度等云平台均是基于Hadoop基础架构实现的[2]。而Mahout算法库的机器学习主要集中在三个领域,即协同过滤(推荐引擎)、聚类和分类。分类模块作为其中一种重要的方法具体包括Logistic Regression(逻辑回归)、Naive Bayesian(朴素贝叶斯)、Support Vector Machine(支持向量机)、Random Forests(随机森林)和Hidden Markov Models(隐马尔科夫模型)。目前Mahout分类算法在Hadoop平台上的应用包括:第一,基于Hadoop平台的分类算法在某方面的具体应用,如高一男等[3]基于Hadoop平台,利用Mahout的贝叶斯算法通过对邮件进行特征提取以检测是否为钓鱼邮件,并通过真实邮件数据进行测试,取得较好效果;梁世磊[4]基于Hadoop平台利用MapReduce并行计算模型分布式设计了随机森林算法,提高了图像的分类效率;满蔚仕等[5]通过将传统的网格法与粒子群算法结合,提出一种新型卫星并行粒子群算法,相比于单机支持向量机(SVM),Hadoop平台分布式SVM在分类准确率和计算速度上均有明显提高。第二,在Hadoop、Spark等不同云计算平台中比较Mahout中的分类算法的运行效率和效果,如郭成林[6]在Hadoop和Spark平台分别实现了决策树、贝叶斯等机器学习算法并对改进算法进行了试验和比较分析。
综上所述,基于Hadoop的云计算平台已经是大数据分析与应用的重要基础架构,而将传统的分类算法运用到以MapReduce为模式的并行计算编程框架上,能够有效解决对海量数据处理的瓶颈问题。因此,本文在搭建Hadoop物理集群平台的基础上,对Mahout分类算法中的随机森林算法进行深入分析与研究,最后通过实际数据分析传统森林算法在分布式环境下的优点与不足。
2 Hadoop简介
Hadoop是一种典型的Master∕Slave架构,由一个Master节点和多个Slave节点组成,Master节点负责Slave节点上的任务调度,是整个系统的控制和调度中心,Slave节点负责数据的存储和具体任务的执行。其核心组成是HDFS分布式文件系统和MapReduce分布式并行计算框架[7]。Hadoop基本架构如图1所示。
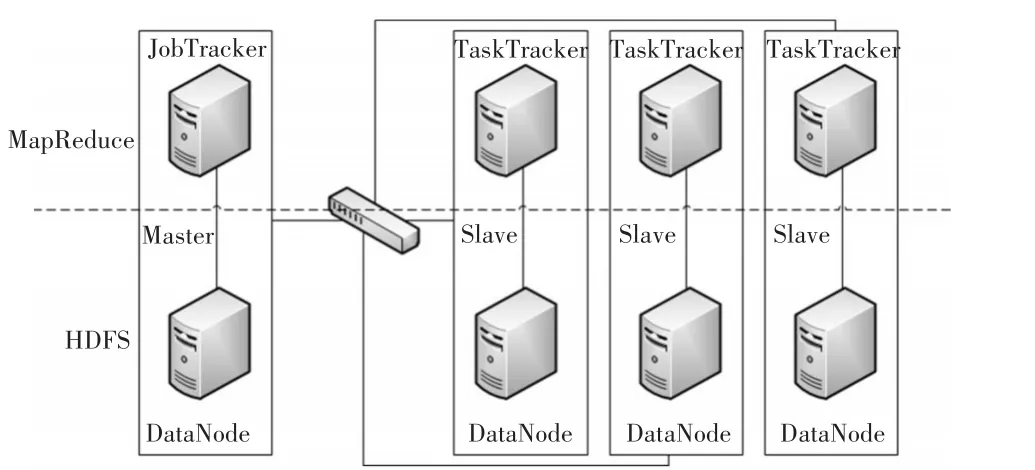
图1 Hadoop基本架构
由图1可知,Master节点由NameNode和Job⁃Tracker组成,其中NameNode是HDFS的Master,主要负责Hadoop分布式文件系统元数据的管理工作,包括文件系统的名字空间(namespace)以及客户端对文件的访问;JobTracker是MapReduce的Master,主要任务是启动、跟踪和调度各个Task⁃Tracker的任务执行。Slave节点由DataNode和TaskTracker组成,其中DataNode主要负责数据的存储并对数据进行冗余备份;TaskTracker主要根据任务需求然后结合本地数据执行Map和Reduce任务。
3 随机森林算法
Leo Breiman[8]最早提出随机森林算法(Ran⁃dom Forests,RF),它是集成学习Bagging算法的一个扩展。随机森林是由多棵决策树组成的组合分类器,分类时使用森林里的多棵决策树同时对某一对象进行分类,结果遵循“以少服多”的原则,并且相同深度的每一棵决策树和每一个节点都能独立进行训练和分类,因此它的训练效率和分类效果非常高[9]。决策树是随机森林的组成部分,下面首先对决策树进行简单介绍。
3.1 决策树
决策树是一种有监督的分类学习方法,通过对对象的各个特征属性进行分类然后形成树状预测模型[10]。在建立决策树的过程中,决策树的属性和类别之间的关系需要根据属性度量值来决定,其中熵和信息增益是两种重要的度量准则[11]。
熵的计算公式如(1)所示:
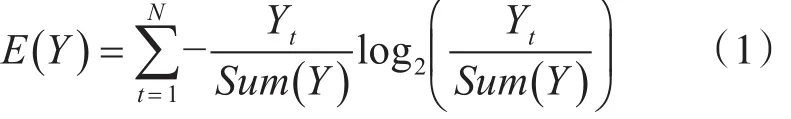
其中,Yt表示类别Y中的第代表类别Y的总记录数,N为类别Y的总数目。
增益的计算公式如(2)所示:
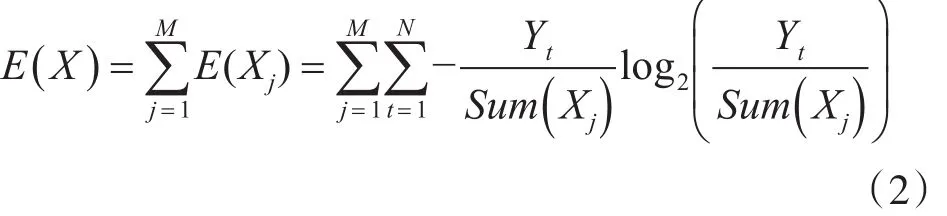
3.2 随机森林算法工作原理
随机森林方法原理可以大致描述为从N个原始数据集中,采用bootstrap抽样方式(即有放回抽样)抽取N次,形成一组包含N个训练集的训练样本;按照上述方式,重复T次,形成新的训练样本集D;从训练样本集D中选取m个特征属性,并从中选择最优属性以最佳的分裂方式形成决策树;将T棵决策树组合形成随机森林,最后以“投票”的方式对测试集进行评估。随机森林算法形成的流程图如图2所示。
4 Mahout中随机森林算法的实现过程
在Mahout中,随机森林算法的实现可由以下三个步骤完成[12]:第一,根据原始数据生成描述性
文件;第二,根据描述性文件、输入数据及其他参数通过决策树算法生成多棵决策树,然后将这些决策树转换成随机森林模型;第三,使用测试数据对上面生成的随机森林模型进行评估,以检验生成模型的好坏。

图2 随机森林算法形成流程图
4.1 生成描述性文件
描述性文件是对原始输入数据数据属性的集中概括,如每个特征属性的数据格式、不参与建模的属性列及输出类别属性列等。在Mahout中,用I(Ignore)表示不参与建模属性列;用C(Categorical)表 示 离散的属性列;用N(Numerical)表示连续的属性列;用L(Label)表示输出类别属性列。下面用一个实例说明描述性文件的生成策略,具体见表1。

表1 随机森林算法输入数据训练集
首先对原始数据进行分析,由表1可以看出,第一列为行号,不参与建模;第二、三列为连续属性的数据格式;第四列为离散属性的数据格式;第五列为输出类别。因此,描述性字符串为[I 2 N C L],其中[2 N]即为[N N]。然后,将其存入描述性文件。
4.2 构建随机森林模型
随机森林模型由多棵决策树组合而成,形成随机森林模型的过程如流程图2所示。在构建随机森林的过程中,每生成一棵决策树就会将其写入文件,直至所有的树都建立完成,这时所有的决策树都存在同一个文件,然后再将这些树封装成一个链表,形成一个变量,即为随机森林模型。
4.3 评估随机森林模型
随机森林模型建好之后的效果需要利用测试数据集进行测试,并根据分类的质量进行评价。随机森林模型评估过程描述如下:利用测试集对构建的随机森林模型进行评估,首先预设变量i为0;遍历随机森林中每棵决策树对测试集的每条记录进行分类,分类结果采用投票方式,选取分类次数重复最多的作为分类结果;将分类结果与原始数据集进行比较,如果分类正确则变量i循环增加,否则进行测试集中下一条记录的分类,直至测试集中的N条记录分类完毕;分类正确率由i∕N计算得出。随机森林模型的评估的具体流程如图3。
5 实验及结果分析
5.1 实验环境搭建及部署
本实验环境基于物理机搭建了完全分布式的Hadoop集群,形成了以服务器为主节点,三台PC机为从节点的主从架构,集群环境部署如下:
1)硬件环境
实验室共有服务器一台,闲置电脑3台。基于这4台机器搭建Hadoop完全分布式物理集群。其中服务器作为NameNode主节点,其余四台机器作为DataNode从节点,各机器硬件配置信息如表2所示。

图3 随机森林模型评估流程图
2)软件环境
软件环境具体配置如表3所示。
软件环境配置说明:由于服务器和PC机的操作系统分别是64位和32位,因此上述各软件版本有64位和32位之分。具体配置如下:在服务器 上 安 装 VM⁃ware-worksta⁃
tion-full-12.0版本的虚拟机,并安装Cen⁃tos-7 64位桌面版Linux操作系统,然后安装对应64位的JDK,即 JDK-8u144 64位,最后安装Java开发工具Eclipse。在3台PC机中任选2台安装VMware-work⁃station-full-10.0虚拟机,并安装Centos-7 32位桌面版Linux操作系统,然后安装对应的32位JDK,即JDK-8u144 32位。在剩余一台PC机上直接安装Linux系统,即Cen⁃tos-7 32位桌面版操作系统和32位的JDK。

表2 实验环境硬件配置

表3 实验环境软件配置
5.2 实验数据分析
本次实验原始数据集使用的是UCI公开数据库中的banknote authentication数据集,它是利用小波变换工具对纸币图像进行鉴别,然后从图片中进行特征提取的。该数据集共有1372条记录,每条记录含5列数据,其中前4列为样本特征属性,均为连续数值型数据格式,最后一列为样本的类别标签即真钞或伪造钞票。该数据集的特征属性分别为小波变换图像的方差、小波变换图像的偏度、小波变换图像的峰度以及图像熵。图4为部分数据集的数据格式。

图4 原始数据集部分数据
5.3 实验过程
1)将数据集分为训练集和测试集
由于该数据集并没有提供测试数据集,因此首先用Mahout提供的split方法将原始数据集分为训练集和测试集两部分,其中,选择原始数据集的20%作为测试集。
2)生成描述性文件
由图4分析可知,描述性字符串为[4 N L]。[4 N]说明数据集前4列为连续数值型数据,L表明这一列为类别标签。图5显示了生成描述性文件的运行结果。
3)用训练集构建随机森林模型
在建树的过程中,决策树的个数不同,生成的随机森林模型就不相同。本实验分别选择使用3棵、5棵和10棵决策树形成随机森林,并对生成的随机森林模型进行比较分析。
4)用测试集评估随机森林模型
用测试集去检验分别由3棵、5棵和10棵决策树生成的随机森林模型,结果如下。
5.4 结果分析
由图5可知,描述性文件已经生成且存入HDFS文件系统上了。从图6、图7和图8可以看出测试集总记录条数为274,即随机从原始数据选择20%作为测试集的数目,该结果与预先设置一致;从不同决策树形成的随机森林模型评估结果来看,3棵决策树形成的随机森林模型分类正确率为96.7153%,5棵决策树形成的随机森林模型分类正确率为98.5401%,而10棵决策树形成的随机森林模型分类正确率为98.1752%。由此可见,随机森林模型的评估质量非常高。此外,由该结果还能得出,随机森林模型的评估效果并不是决策树越多准确率就越高。

图5 生成描述性文件运行结果信息

图6 3棵决策树形成的随机森林模型评估结果运行信息

图7 5棵决策树形成的随机森林模型评估结果运行信息

图8 10棵决策树形成的随机森林模型评估结果运行信息
由以上三图给出的混淆矩阵,可以得出,a、b分别表示分类结果,即a=0、b=1,代表真钞和伪造钞票;Classified as表示本应该分到此类的数目,以图6为例,分到a类的记录条数应该为149,但实际只分了144条记录,即a类有5条记录是被误分了。因此,从混淆矩阵可以分析出哪些类别容易被误分以及分错的个数和其他信息等。
6 结语
本文基于Hadoop平台实现了Mahout中的随机森林算法,并利用banknote authentication数据集对生成的随机森林模型进行效果评估。实验结果表明,利用随机森林算法对该数据集进行分类,准确率高达96%以上,说明了随机森林模型分类精确度较高、性能较稳定。此外,本实验还选取了不同决策树的个数以生成不同的随机森林模型并分别进行验证,结果表明随机森林算法的鲁棒性较高、分类效果较好。
但是,本文也存在一定的不足。从随机森林模型的评估效果来看,分类准确率基本上都在96%以上,这与原始数据集的数据模式简单、数据特征质量高有一定的关系。因此,下一步,还将针对包含较多特征属性及数据有一定缺失值的数据集展开针对性研究,以期对Mahout中的随机森林算法的效果做出更进一步的评估。
