基于闪存固态硬盘内部并行机制的R-树优化方法
2018-09-21陈玉标李建中李英姝李发明
陈玉标 李建中 李英姝,2 李发明 高 宏
1(哈尔滨工业大学计算机科学与技术学院 哈尔滨 150001) 2(佐治亚州立大学计算机科学与技术学院 佐治亚州亚特兰大 30303)(chenyubiao@hit.edu.cn)
从个人电脑到服务器设备,基于闪存的固态硬盘已经被广泛应用.闪存固态硬盘以其耗能低、体积小、高可靠性、读写速度快等特点深受欢迎.与此同时,随着闪存固态硬盘架构的改进,比如集成更多的通道,它具有了丰富的内部并行性.近年来,已经有人对固态硬盘这种性质进行了研究和应用.例如闪存固态硬盘内部并行已经被用来加速关系数据库中索引扫描和聚集[1],也使B+树索引结构的性能得到很大提升[2].
R-树[3]是一种支持高维数据索引的平衡树结构,被广泛用于空间数据管理[4].目前Spatial Hadoop,MySQL,PostgreSQL,ArcGIS等系统都支持R-树索引结构.目前,针对闪存的R-树优化工作[5-7]主要考虑的是读写不对称引发的写问题以及由频繁写带来的固态硬盘寿命缩短问题.但是,这些工作并没有考虑到固态硬盘的内部并行性[8].本文重点研究如何利用固态硬盘内部并行性加速R-树的查询和更新操作.根据我们所知,本文是最早基于固态硬盘内部并行机制对R-树进行优化的文章之一.本文的主要贡献包括5个方面:
1) 提出了适合于固态硬盘内部并行化的批量异步I/O提交技术;
2) 提出了基于R-树的贪心批量查询处理算法;
3) 提出了R-树的批量更新算法,并基于常数级别的缓冲,设计了一个查询更新的系统结构,该系统结构能大幅度加速更新操作;
4) 从理论上证明了具有丰富内部并行性的闪存固态硬盘批量与顺序读和写的期望加速比下界.
5) 针对千万级别的数据,对本文提出的基于R-树的批量查询处理算法和R-树批量更新算法进行了测试,证实了利用固态硬盘内部并行性,可以极大地提高了R-树索引性能.
本文首先介绍利用固态硬盘内部并行特性的相关工作及技术原理; 其次给出使用方法,并进行期望加速比下界的理论证明; 然后,提出基于固态硬盘内部并行性的R-树批量查询算法和批量更新算法; 最后,通过实验对比阐述基于固态硬盘内部并行性的R-树查询和更新算法的性能优势,验证有效性.
1 相关工作
本节介绍R-树在闪存固态硬盘上索引优化的现有研究工作.闪存作为存储器的随机写要比随机读和顺序写慢很多,人们称此性质为读写不对称性.因此,对R-树索引进行优化时,人们通常考虑如何通过额外的随机读操作来减少随机写或者如何把随机写尽可能地转换成顺序写.经过调查发现,利用固态硬盘的R-树优化方法主要分为3类:
1) 优化方法是利用缓存策略来减少随机写.文献[9]使用这种策略提出一种优化R-树,通过更新频繁的树头驻留主存、其余节点按其与树头的距离从小到大的次序优先级驻留内存,实现R-树的缓冲存储,以减少更新带来的随机写.文献[7]基于相同策略提出另一种优化R-树,用批量更新代替即时更新,更新的数据顺序存储在内存,当内存满时实现R-树的批量顺序更新.由于很多更新被延迟,所以能有效地减少闪存的随机写.文献[10]提出了第3种基于缓存策略的优化R-树,更新操作被缓存在主存中,它对不同节点的更改分别建立了Hash索引,能够有效地把同一节点的多次更新合并为一次更新写回闪存.
2) 优化方法是通过存储更新日志的方式使用顺序写和额外读操作来代替随机写.文献[6]使用这种策略提出了一种优化R-树,把每个节点的更新操作信息存储到更新日志中,仅当节点被查询时,R-树中这个节点才被真正更新,大大减少了随机写的次数.这种方法的缺点是每次更新都需要更新日志文件的读写.
3) 优化方法是改造R-树索引,减少R-树节点分裂来减少随机写.在新的节点插入R-树中时,有可能导致R-树节点的分裂,节点的分裂会导致很多额外的随机写操作.因此,文献[6]在非平衡的B-树[11]的基础上提出了非平衡的R-树,通过引入溢出节点的方式来减少分裂节点带来额外的随机写.
上述针对闪存固态硬盘的R-树优化策略,都没有考虑闪存固态硬盘内部丰富的并行性.本文重点研究充分利用闪存固态硬盘内部并行性来优化R-树查询和更新操作的问题.
2 固态硬盘内部并行性
本节介绍固态硬盘内部并行性机理及使用技术和实现方法.
2.1 内部并行性的机理
一个经典的固态硬盘包含4个部分:主机接口逻辑模块、内存缓存模块、固态硬盘控制器模块、闪存包模块,如图1所示.闪存包通过数据通道连接至闪存控制器,多闪存包共享一个通道.一般情况下,一个固态硬盘含有2~10个通道.其中通道之间工作是独立的.闪存包会有很多,不同包之间的工作也是独立的.那么根据上述描述,固态硬盘内部存在2个层级上的并行性:
1) 通道级别并行性.固态硬盘在设计上采用了多通道技术,不同通道之间是独立运行的,从而多通道可以并行运行.如图1所示,如果对闪存包0和闪存包5同时提交访问请求,由于它们连接的是不同的通道,访问可以并行执行.
2) 闪存包级别并行性.为了尽可能地充分利用通道资源,每个通道下都连接一系列闪存包.每个闪存包独立工作,因此闪存包可以并行工作.如图1所示,当对闪存包2和闪存包4的访问同时到来时,它们可以独立并行地处理各自的请求.
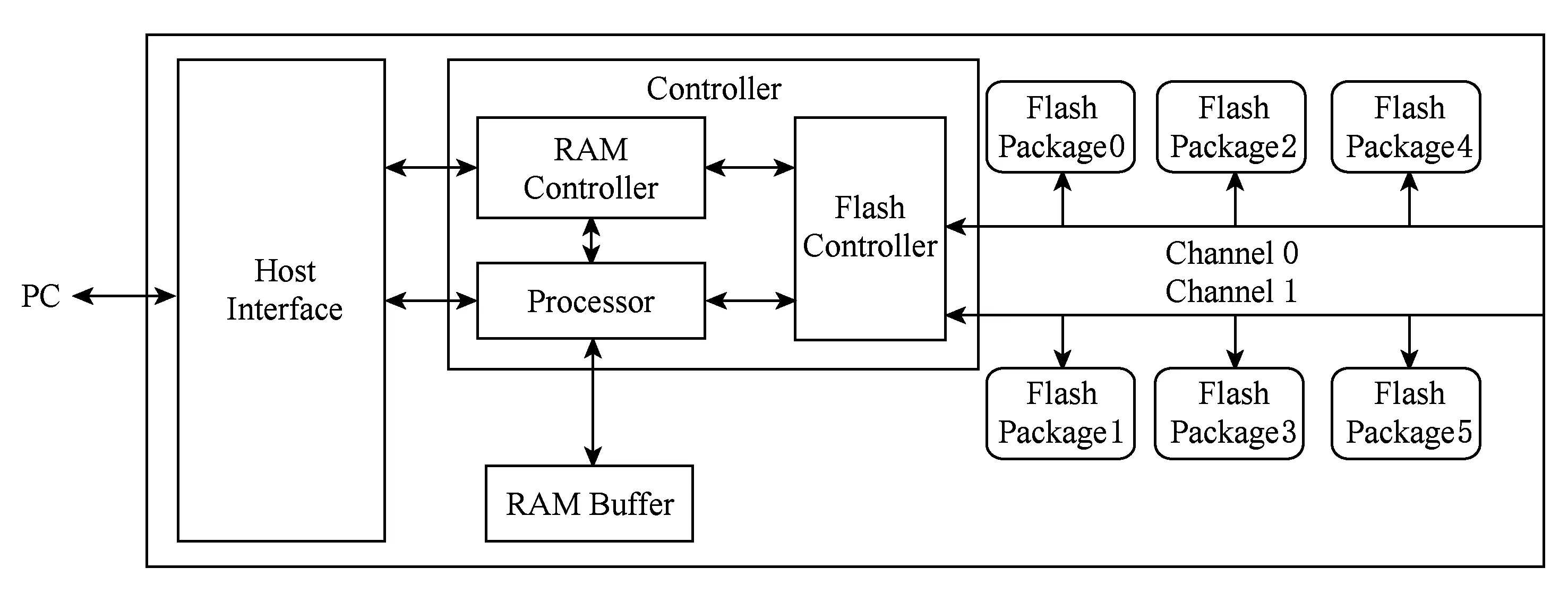
Fig.1 Architecture of solid state disk图1 固态硬盘架构
包级别并行性对加速随机写意义重大.闪存的随机写比随机读慢很多,这种读写不对称性源于闪存的写前擦除机制,擦除操作延迟很大.利用闪存包级的并行性,可以使多个不在同一个闪存包的多个字读写操作并行执行,从而也实现了擦除操作的并行执行,有效地减低了写操作的延时.
2.2 如何利用内部并行性
本文使用Linux操作系统的异步I/O库libaio,通过实现批量提交异步I/O来发挥固态硬盘内部并行性.
1) 当一个闪存固态硬盘读写请求到来时,使用异步I/O库libaio,让Linux操作系统把该请求加入I/O请求队列NCQ(native command queuing)中;
2) Linux操作系统周期地检查NCQ,如果NCQ中具有读写请求,它就将这些请求发送给固态硬盘,然后固态硬盘通过各个通道,分发给相应的闪存包,并启动相应的闪存包,并行处理各自的读写请求.
闪存固态硬盘通过同时自动启动多个数据通道传输数据的方式实现通道级并行性; 让批量提交的读写请求由不同的闪存包执行,实现了闪存包级的并行性.值得注意的是,Linux操作系统周期性地检查NCQ中的读写请求.因此只有批量一次性地提交读写请求,才能保证批量提交的读写请求是被闪存固态硬盘同时处理,才能充分发挥闪存固态硬盘的内部并行性.原因是非一次性提交I/O请求,很有可能被Linux系统的轮询机制给分成多批处理,减弱批量I/O处理的并行性.

Fig.2 4 KB random read/write and mixed testing图2 4 KB随机读写混合测试
为了利用固态硬盘内部并行性,我们在libaio的基础上,实现了一个批量并行读写函数Parallel-IO.它的输入是读写请求集合,输出是批量读写操作结果.Parallel-IO通过libaio把该读写请求集合批量提交给闪存固态硬盘,利用其内部并行性执行读写请求.在使用Parallel-IO时,要注意避免一次批量提交的读写请求中既含有读也含有写,因为读写耦合会导致性能衰退[8].因此,一定要分别批量提交读和写.图2为本文在3款不同固态硬盘上进行的随机读写混合测试实验,本实验对于随机读(如图2(a)所示)和随机写(如图2(b)所示)以及混合读写(如图2(c)所示)这3款固态硬盘的详细参数参考表3描述,从图2可以看出,混合随机读写批量提交的平均带宽比单独批量提交随机读或者单独提交随机写的带宽都要低.因此,本文在进行R-树读写优化时,对于固态硬盘的读写分别进行单独的批量提交,以防止读写混合带来的性能衰退.另外还需注意的是:在实际应用中,Parallel-IO批量提交大量的I/O请求到等待队列中,可能会直接阻塞其他应用的I/O请求,因此对于多应用低延迟的场景,该加速方法不适用.
为了便于阅读,表1列出了本文常用的符号定义.

Table 1 The Symbols to Describe R-tree Optimization 表1 用于描述R-树优化算法符号解释
3 批量IO并行处理算法
本节分为2部分,介绍批量并行读写函数Parallel-IO.第1部分介绍Parallel-IO的算法实现;第2部分对Parallel-IO的加速效果进行了理论分析.
3.1 算法实现
如算法1所示,伪代码展示了如何利用libaio实现Parallel-IO进行批量提交.它的输入是读写请求集合,例如输入request_queue是读队列,bufs作为存储读取数据缓存,返回bufs作为批量读取结果.无论是批量读请求还是批量写请求,Parallel-IO均通过libaio库把该读写请求集合批量提交给闪存固态硬盘,利用其内部并行性执行读写请求.详情见算法1.
算法1.ParallelIO(request_queue,bufs).
输入:request_queue是读写操作队列,当其为写队列时,bufs为写数据缓存;
输出:request_queue是读队列时,返回是读结果.
① 用io_setup创建批量提交的上下文ctx
② 创建NCQ-size大小的IO提交缓存cbs;
③memalign_bufs←获取request_queue个
512 B对齐的读写单元;
④ if (request_queue是写队列) then
⑤memalign_bufs←bufs;
⑥ end if
⑦ if (request_queue是写队列) then
⑧ 通过io_prep_pwrite把写请求写进cbs;
⑨ else
⑩ 通过io_prep_pread把读请求写进cbs;
3) 行④~⑥判断如果request_queue是写队列,那么需要先把写的内容bufs先写进memalign_bufs以写进外存.
3.2 算法分析
本节对于Parallel-IO函数的加速效果进行分析.由于固态硬盘内部为商业保密对用户不可见,因此通过Parallel-IO函数批量提交的异步I/O请求,并不能保证其中每一个异步I/O都通过不同的通道并行工作.不同异步I/O共用通道会引起拥塞,而导致I/O在通道级别的顺序执行.但是通过理论分析可以发现,即使存在异步I/O请求使用相同通道的情况,Parallel-IO依然可以提供一个可观的加速比.本节将提供理论证明.
3.2.1 问题定义
对于一个通道数为n的固态硬盘,假设一次批量提交m(m≤NCQ-size)个读写类型相同的异步IO请求,并且访问的存储位置和每个通道相连的概率相等.在只考虑通道级别并行加速效果的情况下,求由Parallel-IO批量提交的并行随机访问相较于同步顺序随机访问相比的期望加速比下界.
3.2.2 度量标准
因为对于固态硬盘的读和写只是数据移动方向不同,对加速比下界分析无影响,因此不失一般性,接下来均以读为例来分析理论加速比下界.假设完成一个读写存储单元的读操作,闪存包上执行的时间为t1,通道通过的时间为t2,那么对m个读写存储单元的读操作顺序执行时间为
Tseq=m×(t1+t2).
(1)
如果将上述m个读写单元的读操作,通过Parallel-IO批量提交.假设通过n通道时,最多出现k个读请求通过同一个通道,那么k个读请求执行时间为
Tasy≤k×(t1+t2),
(2)
其中,采取“≤”是因为闪存固态硬盘内部还存在闪存包级别的并行性,最差的情况是通道和闪存包都顺序执行.所以理论加速比为
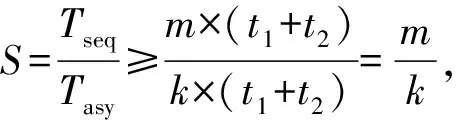
(3)
所以,m个请求通过n个通道,同一个通道最多有k个请求的加速比:

(4)
从式(4)可见mk的期望值即是期望加速比下界.
3.2.3 求解期望加速比下界
因为访问的存储位置和每个通道相连的概率相等,那么m个访问中每个访问通过n个通道的概率都相等,且都为1n.对于第i个通道,通过它的访问恰好有k个的概率为

(5)
所以通道i中至少有k个访问的概率为

(6)
根据式(5)放缩得:
所以得到:
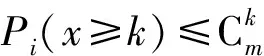
(7)
所以n个通道中存在一个通道至少有k个访问的概率为

因此得到:
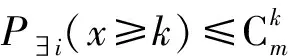
(8)
所以n个通道中至多有k个访问的概率为
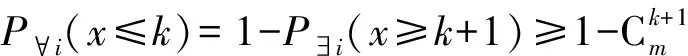

Fig.3 A R-tree example of MAXNODES=2, MINNODES=1图3 一个MAXNODES=2, MINNODES=1的R-树例子
因此可得:

(9)
设m个读写单元的读操作通过n个通道时,单个通道中出现最多k个读写操作的概率为p(x),可以得到结论:
(10)
根据式(8)~(10)可推导出期望加速比下界:

(11)
由于k是任意的,所以式(11)可得:
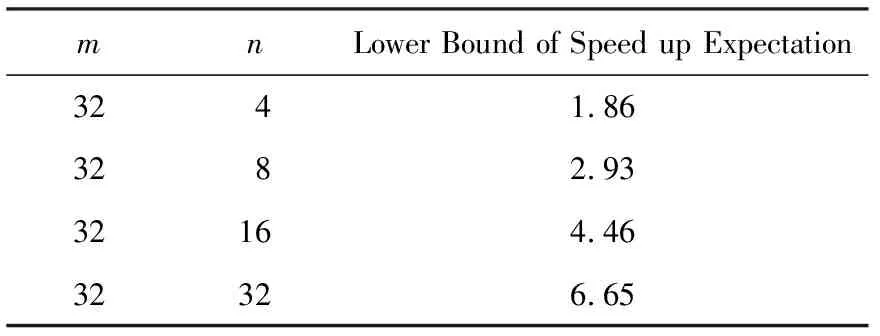
Table 2 Lower Bound of Speed Up Expectation表2 期望加速比下界
Notes:mmeans batch-submitting I/O number,nmeans channel number.
4 R-树的优化
基于Parallel-IO批量并行读写函数,本节设计了R-树的贪心批量查询处理优化算法Batch-Search和基于常数级别缓存的批量更新优化算法Batch-Update.
为了便于理解,这里首先给出一个R-树例子.图3(b)是一个在2维平面点上建立的R-树.图3(a)是对应2维平面的结构图.图3中的P1~P6是已经插入到R-树中的点,I1和I2是即将插入到R-树中的点.图3中实线矩阵对应R-树节点的最小覆盖矩形MBR,E和F对应的虚线矩形是插入I1和I2后得到的MBR,此前E和F分别仅包含点P3和P4.这里假设每个数据点和节点都占据一个闪存读写单位页.
4.1 查询操作优化
本节针对区域查询操作采用最小化批量提交次数的贪心策略来加速查询处理速度.
查询操作定义:对于一棵外存R-树,已知根节点已载入内存称为root,输入查询区域为m,从根节点root查询返回所有和m有交集的数据.
由查询操作的定义知,这里的查询是区域查询.在图3中,对应虚线查询区域m,可以通过观察快速得知,查询结果为{P2,P3,P4,P5}.在R-树上的传统查询过程如下:从根节点A开始搜索,A有2个branch记做branch1和branch2分别指向B,C2个子节点.因为branch1.MBR和branch2.MBR都和查询范围m相交,因此从外存读入B,C.然后按照同样的方式分别处理B,C,直到处理到叶子节点为止.当处理到叶子节点D,E,F,G,返回所有和m相交的数据索引,此时,判断发现D中P2,E中P3,F中P4和G的P5对应的MBR和m相交,把它们的外存索引集合ptr返回,最终根据ptr从外存中读入P2,P3,P4,P5,作为查询结果返回.
设存储例子R-树的固态硬盘具有2个数据通道,每个数据通道连接3个闪存包,且{B,C,D,E,F,G}均匀地分布在6个闪存包上.使用Parallel-IO函数,利用闪存固态硬盘的内部并行性,上述查询处理可以进行优化地处理:
如果B,D,F存储在第1个数据通道连接的闪存包中,C,E,G存储在第2个数据通道连接的闪存包中.Parallel-IO只需要3(T1+T2)的IO时间,性能比顺序IO提高了1倍.
如果B,D,F分别存储在第1个数据通道连接的3个闪存包中,C,E,G存储在第2个数据通道连接的3个闪存包中.Parallel-IO可以更优化地处理上述查询:
这种查询处理方法只需要2T1+3T2的IO时间.
算法2.BatchSearch(root,m).
输入:root为R树根节点、m是搜索范围MBR;
输出:满足m查询范围的数据索引集合.
①request_queue,node_queue,dataptr_queue
←∅;
②node_queue.pushback(root);
③ while (node_queue或request_queue≠∅)
do
④ while (node_queue≠∅) do
⑤node←取出node_queue首元素;
⑥ if (node不是叶子节点) then
⑦ for (tinnode.branchs) do
⑧ if (t.MBR与m相交) then
⑨request_queue.pushback(t.ptr);
⑩ end if
then
元素;
算法2维护3个队列:查询队列request_queue、节点队列node_queue和数据队列dataptr_queue,其中request_queue存放待载入内存节点的索引,node_queue存放已经载入的内存节点,dataptr_queue存放结果数据索引.
算法2终止条件:当node_queue和request_queue都为空时,意味着所有可能和m有交集的节点都搜索完毕,算法终止.算法行③是判断算法是否停止的条件.
算法2主体分为2部分.
1)node_queue≠∅时的处理过程详见行④~.该部分遍历node_queue中所有节点,找出所有和m相交的非叶子节点,把它们存放到request_queue中用以形成批量提交集合,详见行⑥~.把所有和m相交的叶子节点放入dataptr_queue作为结果返回集合,详见行~.
2)request_queue≠∅时的处理过程,详见行~.固态硬盘的NCQ队列的上限值记为NCQ-size.因此,Parallel-IO最多1次批量提交NCQ-size个IO请求.算法构建具有NCQ-size个读请求的批量IO请求集合(详见行~).如果request_queue中请求数小于NCQ-size,且没有内存节点可以遍历来为request_queue增加新的IO请求,则把request_queue中所有IO请求作为一个批量请求集合.最后,并行读入批量请求集合中的所有节点到内存,详见行~.
当整个算法node_queue和request_queue都为空时,遍历结束.最终返回dataptr_queue中数据索引(详见行).
算法的伪代码详见算法2.
4.2 更新操作优化
本节介绍基于闪存固态硬盘内部并行性的R-树批量更新的优化算法.
更新操作定义:对于一棵外存R-树,已知根节点已载入内存为root,向R-树中插入数据、修改R-树中的数据以及删除R-树中数据的操作,统称为更新操作.
以插入更新操作为例来阐述优化思路,如图3所示,I1和I2为新插入点.在I1插入时,根据R-树插入规则,每次都选择使得I1加入后MBR扩充面积最小的节点进行插入操作,因此I1插入路径是{A,B,E}.最终,I1插入到E节点.插入I1后,E节点产生了更改,同时扩充了E的边界MBR,而E的MBR存储在B中,因此,B也有更改,因此插入I1产生了2个节点E,B的更新.更改的节点需要写入外存固态硬盘,所以,插入I1共计产生2次读和2次写.仅仅只考虑I1的插入过程,2次读操作无法并行执行,因为E和B存在依赖关系.而2次写可以批量提交并行执行,因此整个过程需要3次批量请求.插入I2的路径为{A,C,F},需要2次读操作读入C和F,F的插入使得F原来的MBR扩充,因此C和F节点都被更新,需要写回外存固态硬盘,C和F的读入因为依赖关系只能顺序执行,因此需要2次读请求,C和F作为更改节点写回外存需要1次批量写请求.共计3次读写请求;那么I1和I2的2次插入过程总共需要6次批量读写请求.而顺序操作也只需要8次读写请求,速度提升并不高.速度提升不高的原因有2个:
1) 插入单个元素的插入过程,需依次读入待插入节点的过程由于存在依赖关系只能顺序执行.
2) 写操作虽然可以批量提交,但是插入1个元素造成的更改非常少,固态硬盘的内部并行性并不能发挥优势.
但是更新操作相比于查询操作还是存在很大的优化空间,因为查询操作必须实时立即返回查询结果,而更新操作并没有这个限制,它可以延迟执行.如考虑把I1和I2插入操作合并进行,那么上述插入过程可进行优化:
1) 读入{B,C}的过程,可以建立1个批量IO请求.
2) 读入{E,F}的过程可以建立1个批量IO请求.
3) 对{B,C,E,F}的写操作建立1个批量IO请求.
4.2.1 更新队列

Fig.4 Process of search and update operation with UDQ图4 基于UDQ查询和更新操作工作流程
更新队列UDQ,在更新操作优化中用以存储延迟更新操作,以达到批量提交提高I/O并行性的目的.此时的R-树,由于更新操作被延迟,当有新的查询操作到来时,R-树本身并非含有最新版本的数据.因此,必须要将查询操作直接得到的结果进行UDQ更新处理后,获取最新版本查询数据.如图4所示,当请求操作op为更新操作时,将该操作op放入UDQ,这时判断UDQ是否满,满则批量更新至外存R-树上,清空UDQ;如果op是查询操作,需先向外存R-树提交查询op请求,获取查询结果Q,然后依次将UDQ按照入队顺序对Q进行更新,以保证查询结果的正确性,将最终的Q作为查询结果返回.
具体算法详见算法3,行④Batch-Update为算法4所示的批量更新算法.这里面涉及到UDQ-size大小的选择问题,直观上讲UDQ-size越大,并行性越高,但是UDQ-size并不能无限大.在Batch-Update算法中,最多MINNODES个插入操作可以1次批量提交.因此UDQ-size=MINNODES.这是由于R-树的节点分裂策略决定,接下来解释原因.这里先介绍分裂策略,本文采用最经典的R-树节点分裂策略.
算法3.Execute(op).
输入:op——R-树操作(查询、插入、修改、删除);
输出:查询结果.
① if (op是更新操作) then
②UDQ←UDQ∪op;
③ if (UDQ已满) then
④BatchUpdate(UDQ);
⑤ end if
⑥UDQ←∅;
⑦ else if (op是查询操作)
⑧Q←BatchSearch(op);
⑨ for (opiinUDQ) then
⑩opi作用在Q上;
例:设节点node拥有b1,b2,…,bm共m个分支,对应的最小矩形为MBR1,MBR2,…,MBRm,其中m>MAXNODES.此时,需要对node节点进行分裂.分裂步骤如下:
1) 创建2个新节点node1,node2随机选取2个不同的分支bi,bj分别加入到node1和node2中.
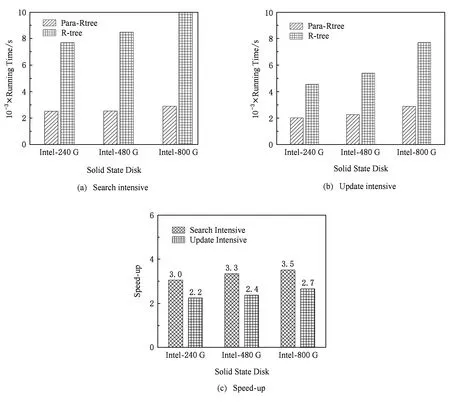
2) 枚举bk∈{b1,b2,…,bm}(k≠i,j),设D1=MBR(node1∪bk)-MBR(node1),D2=MBR(node2∪bk)-MBR(node2).如果D1 3) 将node的分支从父节点中删除,将node1和node2的分支加入父节点,依次递归判断父节点的分裂. 假设批量UDQ-size最大为x,那么极端情况通过Batch-Update 1次批量提交x个插入操作,均插入到同一个节点上,设该节点最多拥有MAXNODES个分支,那么,依照例子中给出的分裂策略,如果x>MINNODES.就可能出现节点分裂后,一个节点只有MINNODES个分支, 而另外一个拥有大于 MAXNODES个分支情况,不满足R-树的平衡性.因此,UDQ-size≤MINNODES. 4.2.2 批量更新算法 首先,阐述批量更新算法的思想: 1) 把UDQ每个更新操作下推到作用的叶子节点进行处理. 2) 对每个叶子节点的更新过程中,保证严格按照更新操作入队的时间顺序进行,确保算法的正确性. 在批量提交更新过程中,算法Batch-Update首先按照广度优先搜索的顺序,把更新操作集合由根节点层层推送到叶子节点.在此过程中,需要读取节点数据,通过调用Parallel-IO进行批量的读取操作.而对于所有更改的节点数据,聚集起来通过Parallel-IO进行批量提交.如图5所示,UDQ的更新操作集合批量更新推送到叶子节点的例子: 例:图5中UDQ包含{op1,op2,…,opi}共i个更新操作.批量更新时,从root节点开始下推,以叶子节点LeafNode1为例,假设作用于它的更新操作为:{op1,op3,op7}.这3个操作分别是插入、修改、删除.那么,它们将下推至LeafNode1,而对于LeafNode1的更新过程为:顺序对LeafNode1执行op1,op3,op7,即插入、修改、删除操作.如果LeafNode1不满足平衡约束,那么分裂或者重新插入儿子节点至R-树,该操作在算法5的Balance-Rtree中进行. Fig.5 An example of update operation pushing down图5 更新操作下推例子 通过插入例子和更新下推例子,不难发现批量更新过程有2个特点: 1) 增加单次批量提交的数量,可增加单次批量提交I/O数量; 2) 更新操作之间可能会有重叠的作用节点. 这2个特点会增加R-树更新操作的I/O效率.下面具体介绍批量更新算法实现. 批量更新算法主要分为2个部分:1)批量更新操作,详见算法4;2)R-树的平衡维护算法,详见算法5. 算法4为批量更新操作部分.同算法2的逻辑,算法4的输入是R-树根节点root和更新操作集合batchs,该部分维护了3个队列:查询队列request_queue、节点队列node_queue和数据队列dataptr_queue. 算法4.BatchUpdate(root,batchs). 输入:root为根节点、batchs为更新操作集合; ①balance_stack,read_queue,dataptr_queue←∅; ②root.batchs←batchs; ③node_queue.pushback(root); ④ while (node_queue≠∅‖read_queue≠∅) do ⑤ while (node_queue≠∅) do ⑥node←取出read_queue队首节点; ⑦balancestack.push(node); ⑧ if (node非叶子节点) then ⑨ for (opinnode.batchs) do ⑩ if (op是插入操作) then 算法4终止条件:当node_queue和request_queue都为空时,意味着所有可能有更新的节点都搜索完毕,算法终止.见算法4行④. 当node_queue≠∅时的详细处理过程详见算法4行⑤~.该部分遍历所有的节点,找出所有batchs可能作用到的非叶子节点,把它们放入read_queue以形成批量提交集合,详见算法4行⑧~.遍历所有的叶子节点,将对应的插入操作对其进行作用,详见算法4行~;将非插入操作加入到数据子节点的更新操作中去,详见算法4行~.最后把有含有更新操作的数据节点加入的dataptr_queue中去.详见算法4行~. read_queue≠∅时的处理过程详见算法4行~.固态硬盘的NCQ队列的上限值记为NCQ-size.因此,Parallel-IO最多一次批量提交NCQ-size个IO请求.算法4构建具有NCQ-size个读请求的批量IO请求集合(详见算法4行~).如果read_queue中请求数小于NCQ-size,且没有内存节点可以遍历来为read_queue增加新的IO请求,则把read_queue中所有IO请求作为1个批量请求集合.最后,并行读入批量请求集合中的所有节点到内存,详见算法4行~. 算法5.BalanceRtree(balance_stack). 输入:balance_stack:广度优先遍历节点的入栈集合; ① writequeue←∅;*存储有更新的节点* ②reinsert_list←∅; ③ while(balance_stack≠∅) do ④node←取出balance_stack栈顶元素; ⑤ if (node有更改) then ⑥ if (node.branchs>MAXNODES) then ⑦node,split_node←分裂node成左右节点; ⑧ 重新计算node.MBR,split_node.MBR; ⑨ 添加split_node到node.father.branchs; ⑩ if (node是根节点) then then 如算法5所示,它有1个输入参数是balance_stack.在算法4中,把遍历到的节点按照广度优先的顺序放进balance_stack堆栈(如算法4行⑦),那么按照balance_stack的出栈顺序,就是算法4中广度优先遍历的逆序进行对R-树自底向上维护平衡结构,详见算法5行③~.当node.branchs>MAXNODES时,进行分裂操作(行⑥~);当node.branchs 基于本文提出的优化技术,在加州大学伯克利分校Antonin Guttman and Michael Stonebraker提供的开源内存R-树[12]的基础上,实现经典外存R-树和优化的R-树,这里称为Para-Rtree. 1) 测试平台.本文测试Para-Rtree的平台为Dell PowerEdge R730,配置为:2×6核Intel Xeon处理器;主频1.90 GHz;32 GB内存;系统盘为2TB 7200rpm机械硬盘;操作系统CentOS7.1,内核版本为3.10.0,Linux内部并行实现[13]的libaio库版本为0.3.109;实验对象为表3三块固态硬盘.为了表达方便,下面将SSDSC2BB480G6R称为Intel-480 G,SSDSC2BB800G6称为Intel-800 G,SSDSC2KW240H6X1称为Intel-240 G.为了消除文件缓存给实验结果造成的影响,文件打开模式为O_DIRECT.所有固态硬盘均为新购买固态硬盘,实验前并未进行特别的磨损处理(warm up). 2) 数据集合.测试使用的真实数据集合为美国50个州的路网数据,该数据来源于美国国家地理块数据库[14],共计11 278 412条数据,每个元组包含经纬度坐标和一组字符串属性.查询、更新操作的数据均由其随机抽样产生. 3) 实验测试.本文实验针对Para-Rtree和传统R-树性能对比进行实验,5.2节索引构建,用以测试Batch-Update对于插入操作的加速效果.在5.3,5.4节中,分别对于查询、修改、删除操作的加速效果进行实验,并测试范围对于加速效果的影响.最后,在5.5节中,对于查询密集和更新密集2种情况的数据操作特点进行测试,检验Para-Rtree在2种情况下的加速效果. Table 3 Testing SSD Parameters表3 待测固态硬盘规格参数 下面测试Para-Rtree构建的时间代价和加速比.在构建过程中,测试不同数据规模对于构建代价和加速比的影响.索引构建即是连续插入操作,因此本测试用以测试Batch-Update对于批量插入的优化性能. 图6描述了Para-Rtree的构建时间和加速比随着数据量的变化趋势.这里从数据集合随机抽取2×106~10×106条数据的数据形成数据集合{D2,D4,D6,D8,D10},包含5组测试数据.用这5组测试数据集分别在Intel-240 G,Intel-480 G和Intel-800 G这3个固态硬盘上进行测试.如图6(a)~(c)所示,横坐标是构建索引数据量,纵坐标为构建时间.可以看出Para-Rtree和R-树的构建时间和数据规模基本成线性关系.图6(d)展示了Para-Rtree在3款固态硬盘上对于索引构建的加速效果,从图6中可以看出3款固态硬盘,对于批量插入操作的加速效果差别很小,都在2倍上下. Fig.6 Effects of object number on speed-up图6 数据量对构建加速的影响 下面测试Para-Rtree的查询处理性能,测试内容包含:不同查询范围对于Para-Rtree的查询时间和加速效果的影响.设P为查询范围占整个数据集合MBR的比例.在索引构建过程中,随机生成的D10数据集合,构建后会生成索引称为Full-Index.下面所有的查询和更新实验都针对该索引进行.为了测试Para-Rtree对于查询速度的提升以及范围对于查询加速效果的影响,分别生成覆盖整个Full-Index区间MBR的0.1%,1%和10%这3组查询操作,其中每个组查询操作均有1 000个,这里针对Para-Rtree的Batch-Search和R-树的传统搜索算法分别进行实验,并计算出每个操作的平均执行时间. 如图7所示,图像展现了不同查询范围Para-Rtree和R-树对查询操作加速效果的影响.图7(a)~(c)的横坐标为3款不同的固态硬盘,纵坐标为单条查询操作平均执行时间,P用以区分不同的数据集合.图7(d)展示了不同查询范围3款固态硬盘上Para-Rtree对于查询的加速比.从图7可以看出Intel-240 G和Intel-480 G对于查询范围的敏感程度低,而Intel-800 G查询范围越大,加速比越大.可以推测出Intel-800 G的内部并行性更丰富,使得Para-Rtree对于查询操作的加速效果更明显.整体上来观察,Para-Rtree提供了2.6以上的加速比,说明Para-Rtree能提供一个比较好的查询加速效果. 下面测试Para-Rtree更新处理性能,测试内容包括:不同的修改范围对于修改操作加速性能的影响;不同的删除范围对于删除操作加速性能的影响.插入操作已经在索引构建时进行了测试,因此本节不再包含插入操作的性能测试.设P为查询范围占整个数据集合MBR的比例.同查询测试,用D10构建索引Full-Index,下面的更新测试均以该索引作为测试对象.为了测试Para-Rtree的Batch-Update对于修改和删除算法的提升,分别生成覆盖整个Full-Index区间MBR的0.1%,1%和10%这3组修改和删除操作,其中每个组有1 000个操作,这里针对Para-Rtree的Batch-Update和R-树的传统修改和删除算法分别进行实验,并计算出每个操作的平均执行时间. 图8展现了不同修改范围对Para-Rtree修改操作加速效果的影响.图8(a)~(c)的横坐标表示3款不同的固态硬盘,纵坐标为单条修改操作平均执行时间,P用以区分不同的数据集合.图8(d)展示了 Fig.7 Effects of search range on speed-up图7 范围对查询操作加速的影响 Fig.8 Effects of modify range on speed-up图8 范围对修改操作加速的影响 不同查询范围对于3款固态硬盘上Para-Rtree修改操作加速的影响.从图8中可以观察到,无论是Intel-240 G,Intel-480 G还是Intel-800 G,修改范围对于3款固态硬盘加速效果影响很小.但是与查询测试的加速效果相比,Intel-240 G和Intel-480 G加速效果降低,而Intel-800 G却有很大的提升.因此,进一步验证:不同固态硬盘内部并行性存在差异,这也导致Para-Rtree的加速效果存在差异.因此,对于内部并行性丰富的固态硬盘,Para-Rtree能提供一个很可观的修改操作加速效果. 图9展现了不同修改范围对Para-Rtree删除操作加速效果的影响.图9(a)~(c)的横坐标表示3款不同的固态硬盘,纵坐标为单条删除操作的平均执行时间,P用以区分不同的数据集合.图9(d)展示了不同删除范围,对于3款固态硬盘上Para-Rtree删除操作加速的影响.可以观察到删除操作的加速比相对于查询和修改都比较小,这是由于删除会带来R-树和Para-Rtree索引的部分节点不满足儿子节点的数量限制,需要先进行索引再平衡,大量的额外操作会削弱Para-Rtree的I/O并行性.尽管如此,Para-Rtree还是提供了一个可观的加速比.从范围对删除操作加速的影响来看,3款固态硬盘加速效果相差无几,且和删除范围没有明显的相关性. Fig.9 Effects of remove range on speed-up图9 范围对删除操作加速的影响 由图8、图9的更新测试实验,可以得出结论:Para-Rtree对于修改的加速效果最明显,对于删除的效果最小.对于修改操作,不同固态硬盘加速效果差别较大,而删除操作差别就很小.操作范围扩大对于提升加速比有一定的提升,但是提升不显著. 图10显示查询密集和更新密集2种情况下,Para-Rtree的加速比测试结果,本实验用以验证Para-Rtree在不同使用需求下的加速效果. Fig.10 Effects of search intensive and update intensive on speed-up图10 查询密集和更新密集对加速效果影响 本次实验共生成2组规模达106的查询和更新范围相同的实验数据:第1组为查询密集型数据,查询数据占80%,更新数据占20%,在更新数据中插入、修改、删除各占1/3;第2组为更新密集型数据,查询数据占20%,而更新数据占80%,其中更新数据中插入、修改、删除比例也均等.如图10(a)为查询密集型数据在3款不同固态硬盘上对Para-Rtree的测试时间图,横坐标为3款不同的固态硬盘,纵坐标为运行时间;图10(b)为更新密集型数据在3款不同固态硬盘上对Para-Rtree的测试时间图,横纵坐标同图10(a)所述;图10(c)给出了加速效果对比图,可以清晰观察到,查询密集型数据的加速要比更新密集数据的加速效果更好.这和5.2节查询测试和5.3节更新测试的结果一致. 因此可以得出结论:Para-Rtree对于查询密集加速效果突出,对于更新密集依然可以提供一个很好的加速效果. 本文基于批量式异步I/O提交技术,利用固态硬盘内部并行性去加速R-树查询和更新操作,为此,根据R-树的查询和更新特点,提出Batch-Search和Batch-Update算法和协助实现批量提交增加并行性的UDQ队列.通过理论分析和实验证明,确定其能有效的提高效率.在实验中发现不同的固态硬盘,内部并行性存在差异.因此在选择固态硬盘用作数据库存储盘时,考虑内部并行资源丰富的固态硬盘作为存储盘,以其能提供更高的并行带宽.随着闪存技术的进步和为扩充容量集成进越来越多的闪存包,固态硬盘内部并行性越来越丰富,它将能起到更好的加速效果.因此,该工作有很大发展前景.目前批量式异步I/O提交技术是在文件系统之上实现,这样以来,数据在固态硬盘上的分布对开发者来讲就是一个黑箱,要想进一步提高加速比,需要直接操作固态硬盘来进行数据的分布和读写.因此考虑如何在文件系统下,利用固态硬盘内部并行性进行查询和更新加速是未来一个研究方向.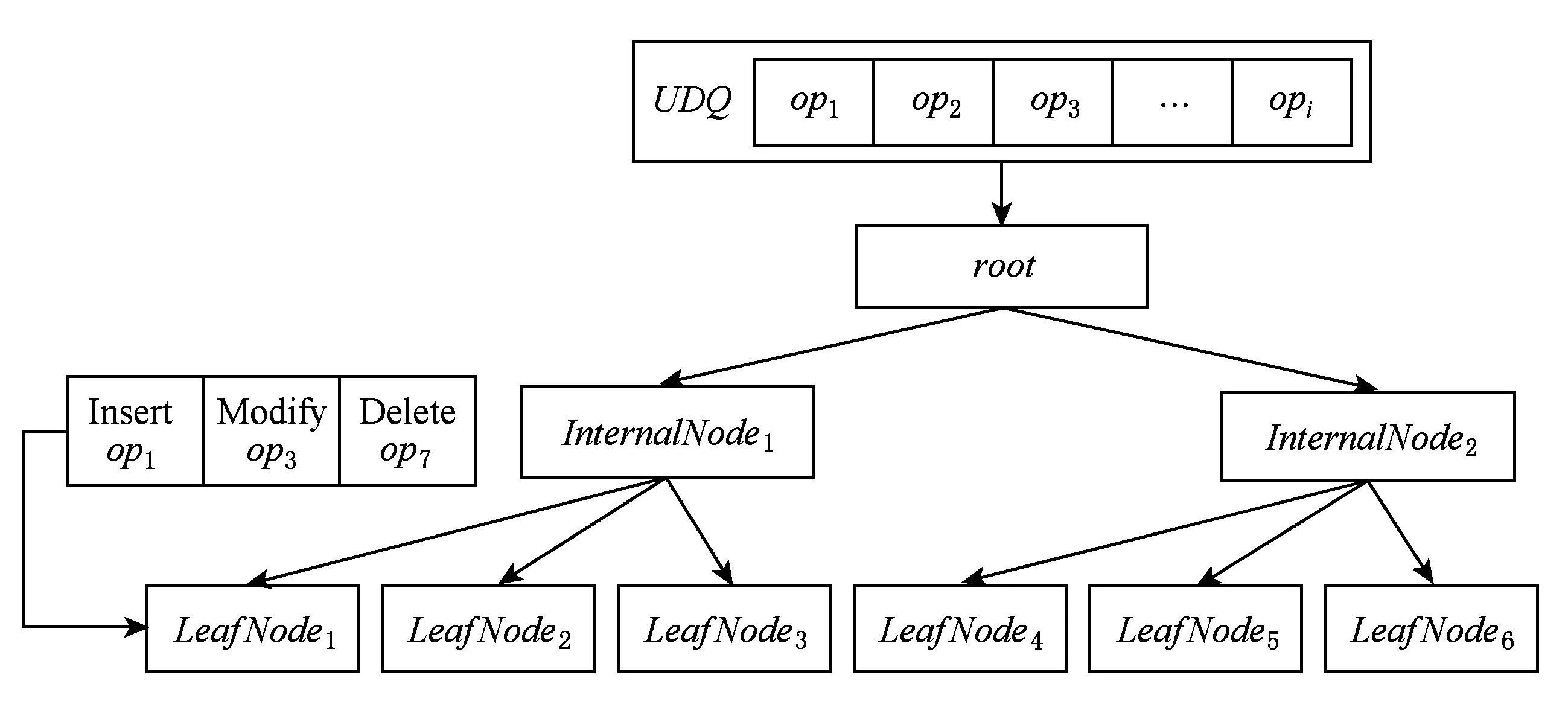
5 性能测试
5.1 实验设置

5.2 索引构建

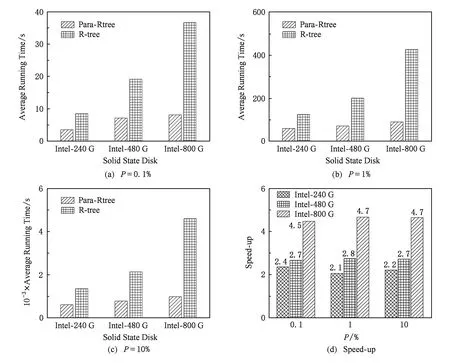
5.3 查询测试
5.4 更新测试


5.5 混合测试
6 总结和未来工作
