近似存储技术综述
2018-09-21刘人萍任津廷陈咸彰
吴 宇 杨 涓 刘人萍 任津廷 陈咸彰,2 石 亮 刘 铎
1(重庆大学计算机学院 重庆 400044) 2 (重庆大学通信学院 重庆 400044) (wuyucqu@163.com)
随着云计算与物联网业务的快速发展,Dennard缩放定律[1]及Moore定律带来的功耗与性能优化逐渐难以满足新兴应用对计算机系统性能与功耗不断增长的需求.同时,物联网等新兴应用产生的信息量呈指数型增长趋势,使得计算机需要存储爆炸增长的数据,对存储系统的性能、功耗和可用存储资源带来巨大的挑战.
为了解决存储领域面临的资源短缺问题,Google、微软和阿里巴巴等大规模数据密集型企业建立配备有数千台高性能服务器的大型数据中心.然而,大型数据中心能耗极高,每年需耗费上千亿千瓦时电量,服务器数量的增长率仅为数据量增长率的五分之一[2],简单地扩大存储规模不能解决存储资源紧张问题.此外,现代计算机系统的处理器通过多核并行计算的方式,理论上能以指数提高计算效率,然而存储器访问数据的物理极限导致并行计算的效率不能以指数提升[3].资源过度配置的传统方法不能有效地解决计算机存储资源紧张的问题.因此,空间开销大、能耗高、访问性能低已成为存储领域面临的巨大挑战.
近似存储技术作为缓解存储难题的一个重要途径,近年来受到越来越多的关注.作为近似计算的子领域,近似存储严格遵循近似计算牺牲输出质量以换取高性能的思想.与传统的精确存储数据技术不同,近似存储技术利用应用程序固有的容错特性,通过近似存储数据或读取近似数据的方式,在满足用户需求的条件下降低应用的输出质量,从而减少存储空间开销、提升访问效率和降低存储能耗的优势.
当前广泛使用的大量应用,如图像渲染、信号处理、增强现实、数据挖掘、语言识别、多媒体处理、机器学习和传感数据分析等,对不精确的输出具有内在容忍度[4-9],用户可以接受降低一定质量的输出结果.因此,计算机系统可以针对这些应用使用近似存储技术,获取性能、能耗、存储寿命等方面的优化.
近似存储技术是近年来存储相关工作的研究重点,将近似应用于程序运行的存储阶段能提升存储访问效率、增大存储容量、降低存储能耗,未来可能成为解决存储领域难题的必要手段.
1 近似存储技术的研究背景
1.1 近似存储的定义
近似存储作为一种解决存储资源紧张的必要技术,利用应用程序固有的对不精确输出的容错特性,通过近似存储数据或读取近似数据的方式,权衡输出结果精确度和应用性能,以在满足用户需求的同时提升性能和能效.
近似存储是近似计算的子领域,近似计算的思想是通过降低输出质量以获取应用的高性能,降低输出质量的方式是通过改变程序运行过程中的计算模式,而近似存储是只针对计算模式中与存储相关的部分,包括数据的存储与读取.目前,针对近似技术的研究大多不是只针对存储,但有相当一部分研究涉及到近似存储,本文主要针对涉及存储并非只针对存储的近似技术作介绍.

Fig.1 Differences of accurate and approximate storage图1 精确存储与近似存储方式差异
图1展示了近似存储技术与传统存储技术的差异.从应用领域看,近似存储技术只适用于容错应用,而传统存储使用于容错应用和精确应用;从数据的处理方式看,近似存储可以近似地缓存数据或者从内存近似加载指令,传统存储只能缓存精确的数据;从数据的存储方式看,近似存储可以在主存和外存中存储近似数据,而传统存储必须存储精确的数据.
近似存储最根本的因素是应用程序能容忍不精确的输出.诸如数字信号处理,图像、音频和视频处理,无线通信,网络搜索和数据分析等应用在识别、挖掘和合成(mining and synthesis, RMS)[10]等新兴应用领域都能容忍不精确质量的输出.近似存储技术的应用领域如表1所示.近似存储具有无限潜力,推动计算的发展以适应信息高速增长的变化.利用应用程序的容错性质提升性能、节省能源,缓解存储资源紧张的难题.

Table 1 Approximate Storage Technology Applications表1 近似存储技术应用领域
应用程序内在的容错因素来源于2个方面:1)应用程序的数据集存在显著的噪声和冗余[4,26-27].现实世界纷繁复杂、大量重复的信息以及通过传感器等不精确器件采集数据都导致输入数据集冗余.在输入数据存在噪声和冗余的情况下,精确计算与存储得到的结果本质上是非精确的,同时浪费大量的资源.2)程序本质的计算模式,如统计聚合、迭代改进等会衰减或纠正由近似引起的误差[4].
1.2 近似存储的发展动力
近似存储牺牲了应用输出结果的精度,与传统的追求高精度输出结果的观点相悖,但是近似存储仍然作为一种新兴的技术在存储领域快速发展,并越来越受到关注.近似存储的发展动力主要体现在4个方面:
1) 海量数据存在大量冗余.从移动设备到数据中心,数据量不断增长,所需的存储资源不断增加,但是存储资源的增长速度不能与信息的增长速度相提并论.这些爆炸式增长的数据存在大量冗余,极大地浪费了紧缺的存储资源.如何在不增加存储资源的情况下,利用有限的存储资源存储更多的数据被越来越多的研究人员所关注.利用近似存储可以有效地解决数据冗余,提升存储空间的利用率.
2) I/O瓶颈问题有待解决.简单地增加存储器资源不能从根本解决存储资源紧张的问题,反而会由于存储器容量的增加,加大整体的能耗.且在计算能力与需求不断提高的现状下,处理器与存储器之间的性能差距也越来越大,I/O瓶颈问题也越来越严重.利用近似存储可以减小存储器带宽与处理器带宽的差距.
3) 存储器件需要更高的稳定性.深入到存储器内部,随着半导体技术进入纳米级别,电路集成度不断提高,电路集成度越高越容易受到环境的影响.alpha粒子、宇宙射线的照射等环境是造成瞬时故障的主要原因,据统计,存储系统中发生的故障98%都是瞬时故障[28].电路对具有先进技术节点的参数变化和故障敏感度会随着电路集成度的增加而增加,传统的无故障计算为实现容错和纠错需要在不同级别的层次上设计保护带和冗余,浪费了大量的能源[26].因此可以通过近似存储技术降低数据精度要求,节约能源,获得性能的提升.
4) 用户能容忍不精确输出.对用户而言,由于人类感知能力有限,完全精确和近似精确的计算结果可能没有任何差异.例如有损压缩利用人类对图像或声波中的某些频率成分不敏感的特性,允许压缩过程中损失一定的信息;视频播放过程中某一特定帧的丢失可能不会被用户发现.没有唯一的黄金输出的限制,对应用的改进提供了动力.与人类感官相关的应用,放松精度的限制,提供足够精确的结果而不是绝对精确的结果,对性能的提升非常必要.用户的关注重点不一定是应用程序的精确度,如智能手机、平板电脑等常用的日常设备,人们对电池的续航时间的关心通常会超过对某一应用程序的精确度.
2 近似存储概述
近似存储作为近似计算的分支领域,其一般过程与近似计算的一般过程[26]相似,可分为3个阶段:近似区域识别[29]、执行近似存储操作、评估近似输出质量.近似存储作为一种能有效解决存储资源紧张的关键技术,并非适用于所有的存储数据.本节将简要介绍近似存储的一般过程和近似存储的重要前提,即近似区域识别,并简要总结近似存储及近似计算的相关技术.
2.1 近似存储的一般过程
近似存储作为近似计算的一个分支,其过程与近似计算的过程类似,可以分为3个阶段,如图2所示.识别可近似区域并标识可近似代码段是近似存储的前提,对近似区域数据执行近似存储操作是核心,控制与评估输出质量是对近似存储方案的可靠性保证.本节将介绍近似存储一般意义上的3个阶段,并对涉及的相关技术作简单总结.
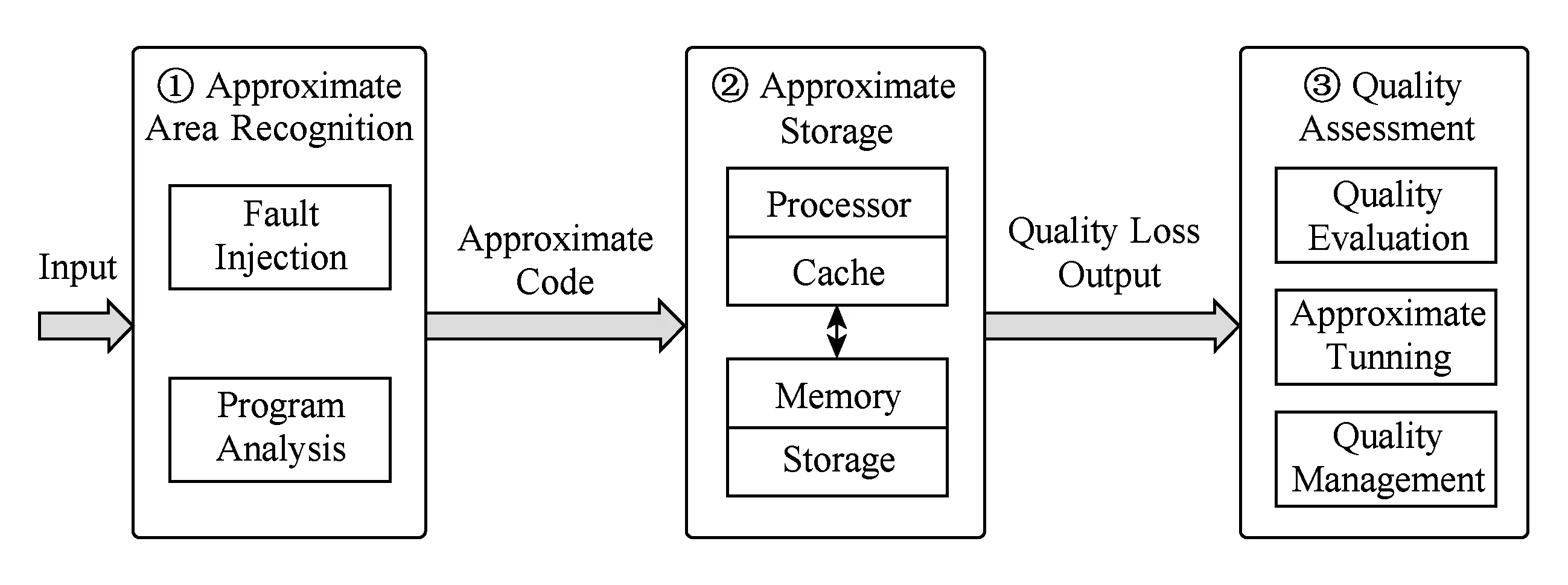
Fig.2 The process of approximate storage图2 近似存储的一般过程
表2分别对近似区域识别技术、近似存储技术、近似计算技术、质量控制与评估方案作总结.近似区域识别总结了具有代表性的一些技术,无论近似计算还是近似存储,都需要先识别近似区域,表2中介绍的技术基本适用于近似存储;近似存储总结近似计算中与涉及到存储的技术,表2中所列举的技术有的是部分涉及存储,如文献[16,24,30]等都不只是针对存储作近似;近似计算列举一些与存储关联

Table 2 Approximate Storage Related Technique Summary表2 近似存储相关技术总结
较小甚至不涉及存储的近似技术,近似存储作为近似计算的小部分,涉及的技术远少于近似计算,这部分内容扩展对近似存储的认识,不作过多介绍;质量控制与评估总结一些具有一定通用性的评估方案,表2中所列举的评估方案都不是只针对近似存储,一般来说更适用于近似计算,通常这些近似计算中涉及到存储方面的近似工作.
1) 识别近似区域.识别近似区域代码段是近似存储技术的必要前提.应用程序的代码段,并非都能作近似处理,因此需要标识近似代码段,然后对其执行近似存储操作.近似区域代码通常有2个特征:①代码段能容忍错误,因为具有容错特性的近似代码段在执行近似操作后输出质量降低不明显;②代码段的执行频率高,一般地说,高频执行的代码占整体开销的比重大,近似存储能提升程序的整体性能并减少程序运行的整体开销.将在2.2节详细地介绍近似区域识别技术.
2) 执行近似存储操作.近似存储技术使可近似代码段能近似存储或从存储器获取近似数据.程序执行过程中,存储操作占据大部分开销,通过近似存储,达到减少能耗、节约资源、提高效率的目的.虽然识别可近似代码段有额外开销,但通过近似存储能有效地减少大量开销,从而在整体上降低能耗.将在第3节更详细地介绍近似存储技术.
3) 控制与评估输出质量.近似存储的方法本质上是通过降低质量来换取更高的效率和更少的资源消耗,因此必须控制与评估近似输出结果,确定输出质量是否可接受.输出质量的评估标准有2种:①由开发人员直接指定输出质量阈值,这比较简便;②被终端用户可接受的输出.实现第2个评估标准具有挑战性,因为不同的用户对输出质量的标准不同,因此难以确定统一的输出质量阈值.
实际上并非所有的近似存储或近似计算过程都严格按照以上流程实现,但所有近似计算和近似存储都必须经历以上过程.有的近似计算方案在执行近似操作的过程中监视输出质量,并不断回滚来调整输出质量,如SAGE[46]、动态工作度量DES[47];上述使用故障注入方法识别近似区域的近似计算,在确定近似区域代码段时候直接根据输出质量决定.而SNNAP[48],Neuralizer[49],BRAINIAC[50],Precimonious[53]和专用SAGE静态编译器[46]等近似计算技术都遵循上述流程.文献[64]中的近似存储方法也遵循上述流程,该方法为可近似的数据设计近似内存,通过维护故障映射表,将近似数据映射到近似内存执行.表2列举了近似存储的相关技术,包括近似区域的识别、质量控制与评估、近似存储技术与近似计算技术.将在第3节更详细地介绍近似存储技术.
2.2 近似区域的识别
作为近似计算的重要分支,近似存储的一个重要步骤也是对近似区域的识别.即便是可近似的应用程序,也存在某些程序段在执行近似操作后导致应用输出存在较大误差,产生用户无法接受的结果.所以,近似存储的一个关键问题是要安全地区分可近似代码段与不可近似码段,保证只对可近似代码区域执行近似存储操作.识别近似区域有2种方法[26,65],即故障注入与程序分析.不同的近似存储技术应根据需求,选择合适的近似区域识别方法标识可近似代码段.
2.2.1 故障注入
故障注入,即向原始程序注入故障,观察注入故障后对程序运行时的影响,注入故障后,不会导致程序崩溃或运算结果出错的代码段标识为可近似的.故障注入的方法具有一般性,但耗时较长,它先向原始程序注入故障,然后观察它对程序执行结果的影响.注入的故障覆盖范围越广、故障类型越多,分析得到的弹性代码段越精确.故障注入的方法经历了3个阶段:
1) 随机故障注入.Li等人提出的故障注入方法[6]向3个硬件结构,即物理寄存器文件、获取队列和问题队列,随机注入故障.
2) 代表性故障注入.Chippa等人提出的ARC[4]框架选择具有代表性的指令进行故障注入实验,描述近似代码段的特征.
3) 等价类故障注入.Relyzer[31]方法与ARC不同,仅针对等价类错误进行故障注入,对那些检测到故障与输出结果为无声数据损坏(silent data corrup-tion, SDC)的代码段又利用静态和动态的控制流和数据流启发式方法捕获到不同指令类型的相似故障,把它们归为等价类.Venkatagiri等人在Relyzer基础上提出了Approxilyzer[32],关注所有高精度动态指令的1位错误对输出结果的影响.
2.2.2 程序分析
程序分析,一般是根据程序的语法和语义,通过观察与分析,找到程序的可近似区域代码.相对于故障注入,程序分析虽然不具备一般性,但是效率更高,如Feng等人提出的Shoestring[33],Cong等人[34]和Sampson等人[35]提出的程序分析方法.文献[34]中的程序分析方法无法分析所有的系统故障,文献[35]中的方法只针对Java语言.
2.3 质量控制与评估
近似存储的方法通过降低质量以换取更高的效率和更少的能耗,然而质量不可能无限制地降低,因此必须控制与评估近似输出结果的质量,确定输出质量是否可接受.
输出质量的控制与评估很少有通用的设计方案,一般地说,评估工作与近似存储技术紧密相关,无论是近似计算还是近似存储,都根据需求设计相应的评估方案.动态的输出质量控制方案在程序执行过程中监视输出质量,并不断回滚来调整输出质量,如SAGE[46]、动态工作度量DES[48]等.
输出质量的评估标准有2种:1)由开发人员直接指定输出质量阈值,这比较简便,本文列举的近似存储技术基本都是采用这种方案;2)被终端用户可接受的输出,AxGames[66]是一种通用的评估用户可接受质量损失阈值的方案.实现第2个评估标准具有挑战性,因为不同的用户对输出质量的标准不同,因此难以确定统一的输出质量阈值.
3 近似存储技术
近似存储技术通过少量降低程序执行的质量,达到提高存储访问性能、减少空间开销或降低能耗的目的.现有近似存储技术分别适用于高速缓存、主存、外存3个存储层次,它们分别用于优化存储访问效率、降低空间开销、提高可靠性、减少存储单元的磨损或降低能耗.表3总结了近年来具有代表性的近似存储技术,从存储层次上对这些技术进行归纳,并总结这些技术的主要改进目标.

Table 3 Summary of Approximate Storage Techniques表3 近似存储技术总结
Note: “√” represents the main improvement goals for approximate storage technology.
如图3所示,近似存储技术按所属的存储层次可分为3类:1)面向高速缓存的近似存储技术,主要研究如何提高高速缓存的访问效率和减少高速缓存的存储开销;2)面向内存的近似存储技术,主要针对DRAM动态刷新存储单元的特点优化访存性能与存储能耗;3)面向外存的近似存储技术,主要针对闪存特性优化数据存储开销和存储单元的磨损.
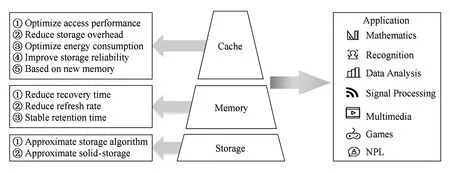
Fig.3 Approximate classification based on storage hierarchy图3 基于存储层级的近似技术分类
3.1 针对高速缓存的近似技术
缓存作为处理器与存储器之间的交换缓冲区,具有访问速度快的特点,但是缓存的高速访问仍然无法跟上处理器的处理速度,同时还存在缓存容量小和能耗高的缺点.利用近似存储技术能克服缓存的这些缺点,本节将针对如何提高访问效率、减小能耗和缓存存储开销,介绍高速缓存的近似存储技术.
英特尔出产的芯片多处理器(chip multiprocessor, CPM)中,高速缓存已占芯片面积的30%[67],现代处理器利用多层缓存层次结构提高访问效率,大型服务器应用程序工作集通过构建更大的缓存来提高性能,但都未从根本上解决问题.因此,利用近似存储技术降低高速缓存的能耗、提高性能势在必行.
3.1.1 提高存储访问效率
由于处理器的并行处理,导致存储带宽无法跟上处理器带宽.为了减少带宽差距,需要提高存储器的访问效率.利用近似存储技术,在缓存缺失时近似估计需要从存储器加载的数据,隐藏缓存未命中导致的延迟,提高存储访问的效率.

Fig.4 Load value approximation overview[16]图4 Load value近似器概述[16]
Load value近似器[16]作为一种高效存储访问技术,主要针对图形应用程序中的load指令在访问缓存缺失时执行近似操作,执行过程如图4所示.在编译阶段,访问高速缓存未命中时,不需要从内存读取数据,而是利用load value近似器近似地预测数据,从而不间断地在处理器中执行程序,大大减少了内存访问延迟.与传统预测器不同,访问缓存未命中时,近似器会同时访问内存,将读取到的数据作为load value近似器的输入进行训练,以评估近似值预测的正确性.因为图形应用程序的高容忍度,能够接受不精确的输出,因此可以消除回滚机制.如果近似器的精度足够高,还可以放松置信区间对缺失值进行估计.load value近似器在输出质量忽略不计的情况下,能显著节约能源和提高效率.
RFVP[11]也是一种预测缺失值来提高存储器访问效率的近似存储技术,其原理是在 L1 cache缺失时预测缺失值来避免检测与重新执行,且仅针对那些执行次数较多却能导致大量缓存缺失率的load指令进行预测.因为GPU中的每个数据请求都是单指令多数据流(single instruction multiple data, SIMD),它为多个并发线程生成数据,为每个线程执行预测会产生大额开销,因此RFVP利用相邻线程访问值的相似性来设计仅具有2个并行专用预测器的多值预测器.多值预测器合成了2个two-delta[36]预测器,一个用于线程0~15,另一个用于线程16~31.RFVP技术能提高存储访问效率,解决处理器与存储器带宽延迟的问题.
3.1.2 降低缓存存储开销
高速缓存虽然访问速度快,但其容量较小,经常出现缓存访问缺失的情况,但由于缓存价格昂贵以及工艺的局限性,不可能无限制扩大缓存,在有限容量的缓存中存储更多的数据是解决这一问题的有效方案,在传统的cache器件和新型的非易失性器件中都能设计近似存储方案降低数据存储的开销.
1) 基于传统缓存的相似值存储
基于相似值的解决方案主要是利用缓存值的相似性,删除重复值和冗余数据,减少存储数据.
Sutherland等人提出的近似存储技术[37]适用于各种数据密集型应用,它利用load value近似器和texture硬件生成近似值.其中texture是位于线程和高速缓存之间的存储单元,能够在多个相邻高速缓存条目之间插值.利用texture的内插功能,使用浮点数据作为高速缓存的索引.基于空间局部性与时间局部性,可以选取2个从全局存储器连续读取的值之差进行近似,其中差值用训练集生成.
在数兆字节的最后一级缓存(last level cache, LLC)中,许多相同或相似的值可能会跨多个块缓存,极大地浪费了缓存的容量.Miguel等人观察到最后一级高速缓存中大多数的缓存值表现出相似性,具体来说,跨缓存块的值不相同但是相似,若近似地将相似的数据看作冗余数据,删除重复和冗余数据,可更好的利用缓存的存储空间.由此,Miguel等人设计了一种新颖的LLC架构——Doppelganger[38],一种专门适用于近似计算的缓存架构,将存在相似值的高速缓存块(即使跨缓存块也可以)作为单个数据块存储在缓存中,其整体架构如图5所示.通过识别相似的高速缓存块,并把这些块与数据数组中的单个条目关联起来,使得多个块共享一个数据条目,虽然这牺牲了数据的精确度,但却能在更小的数据阵列中存储更多非冗余的数据.
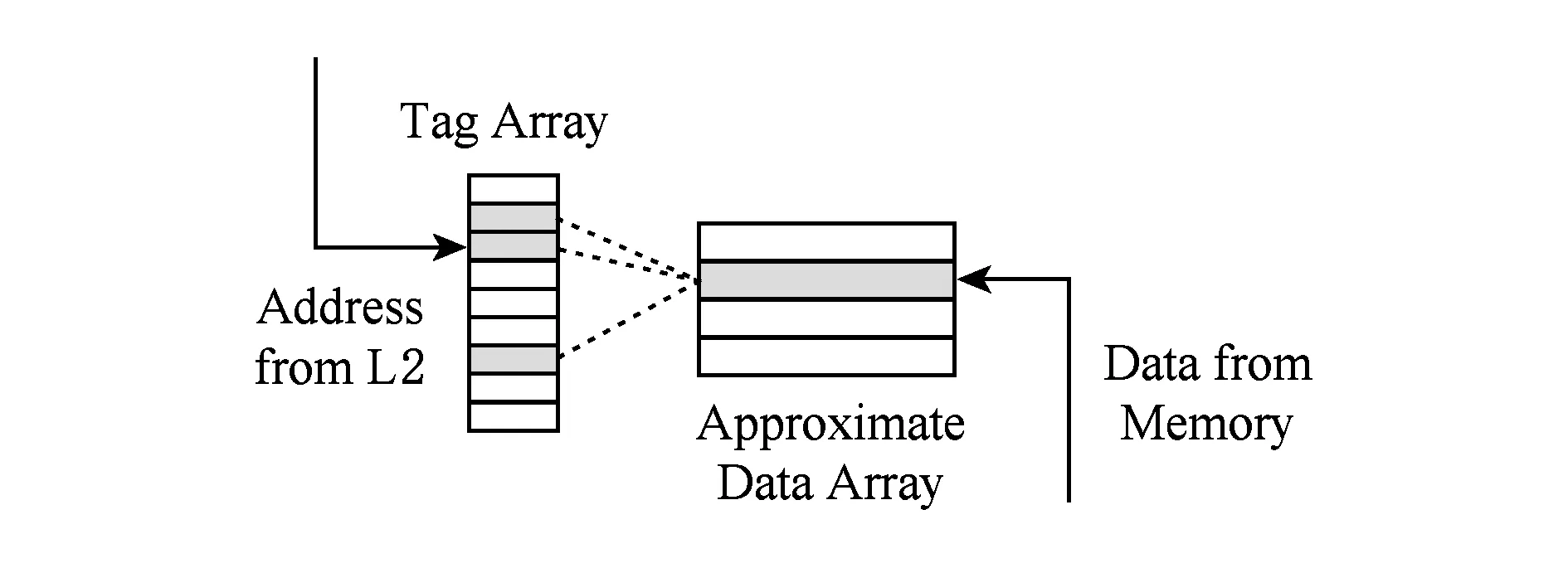
Fig.5 Doppelganger: Tags of approximately similar blocks are associated with the same data entry[38]图5 Doppelganger将相似块近似到相同数据条目上[38]
2) 基于新型器件的近似值存储
随着工艺特征尺寸的逐渐减小,互补金属氧化物半导体(complementary metal oxide semiconductor, CMOS)缩放面临着诸多挑战,如高泄漏功耗、低可靠性、低密度等问题.研究人员正开发新的器件来取代它,新型器件为计算机系统的设计带来了新的机会.基于新型器件缓存架构的近似值存储方案能有效解决上述问题.
Sjalander等人提出的新型器件缓存架构[39],可以存储近似数据和精确数据,根据片上高速缓存的存储资源对精度需求的不同,以可调精度的方式对资源进行分配.当应用程序放松对数据的精度的要求时,数据会以四进制的形式近似存储在四元存储单元,精确的数据以二进制的形式存储在存储单元中,精确的数据需要两倍的存储单元数量.高速缓存行只能存储近似数据或精确数据,不能混合存储2种数据.为了支持四进制的近似存储架构,他们设计了新的寻址方案.将近似计算与新兴多值设备结合,使相同的近似存储单元数存储更多的数据.
3.1.3 降低缓存能耗
SRAM单元主要用作高速缓存,它使用晶体管存储数据,存在高泄漏功耗的问题,降低电源电压的近似存储方案能节约能源.
Kumar对降低SRAM电源电压进行研究发现,其错误率主要由读取翻转和写入失败的概率决定[68].对90 nm和60 nm工艺下的SRAM采取电源电压减低技术可以降低60%的泄漏功率.电源电压缩放是降低能耗非常受欢迎的技术,但为保证数据的正常执行,SRAM的最小电源电压Vmin应高于电源电压的阈值VDD,因此找到合适的电源电压是关键.图6展示了图形应用程序的误码率(bit error rate,BER)和信噪比(peak signal-to-noise ratio,RNSR)与VDD的关系.
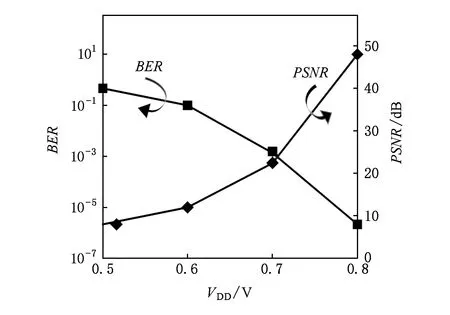
Fig.6 Measured BER and resulting PSNR versus VDD[42]图6 测量误码率和信噪比与VDD的关系[42]
Frustaci等人提出了具有动态能源-质量管理作用的SRAM[41],提出了利用DUAL-VDD最低对有效位(least significant bit,LSB)的降压技术.低位精度可以被接受时,禁用对应于给定数量的最低有效位线,以线性地降低质量的能源.
Gilani等人提出的一种暂存器存储器设计[42]能减少片上存储器的面积,通过权衡必须的最小工作电压(VDD min)和应用输出质量设计存储器.此外,对于数字信号处理应用,允许将电压调整到VDD min以下进一步节能,与短字长存储器相比,这种方法的平均误差更低;而对于错误敏感的应用程序,可以通过重新配置存储器的组织结构,以较低的VDD min实现更高的内存容量.
3.1.4 提高存储可靠性
由于SRAM单元容易受到粒子撞击,造成位翻转,导致数据错误,因此保护SRAM免受粒子撞击的近似存储技术能提高数据存储的可靠性.
Palframan等人提出的方法[43]是一种为GPU的执行逻辑和寄存器文件提出的精确感知保护方法,他们提出的架构优化了整数计算的错误覆盖率,并结合选择性逻辑强化、目标检查器电路和智能寄存器文件编码,他们的方法通过保护免受粒子撞击,提高了存储访问的可靠性和性能.
3.1.5 基于新型存储器的综合近似方案
目前高速缓存使用的主流器件是SRAM单元,它使用晶体管存储数据,但是存在高泄漏功耗、低靠性与低密度等问题.而新型存储器件,如STT-MRAM,具有接近零泄漏、高耐用性、高密度的性质,因此使用新兴的新型存储器件代替SRAM在缓存层进行近似存储是一种能有效解决多种问题的方案.新型非易失性存介质将颠覆传统的缓存结构[69],然而目前研究这种方法的人不多,但是这种设计思路具有很好的应用前景,将来可能成为主流的设计手段.
Monazzah等人提出了一种基于近似计算,使用可靠性-能量旋钮细粒度地对近似STT-MRAM缓存实现质量可调配的软/硬件方法:QuARK[17].利用程序员对应用程序源代码中的可近似数据的声明,将该信息传递给以硬件方式实现的2个主要的STT-MRAM可靠性-能量旋钮:读取电流和写入电流.对于可近似数据的读写操作,2个旋钮都将设置为满足编译器制定的近似的可接受水平的最低电流.若输入质量不被接受,可在运行时改变对该数据精度的要求,从而提高可靠性水平.
Ranjan等人提出STAxCache[12],一种基于STT-MRAM的近似二级缓存架构.其保留了传统缓存的灵活性,同时允许在程序内存地址空间的不同区域进行不同级别的近似.该架构扩展了指令集体系结构(instruction set architecture, ISA),并提供接口,使程序员能快速的指定质量要求.整个架构采用低保留和高保留的高速缓存方式组合形成的异构高速缓存加固,每个高速缓存组合都使用质量可配置的数据阵列,以实现各种精度级别的读写操作.该架构还提供一张质量表和指令感知的高速缓存控制器.质量表用于捕获地址空间区域的质量要求,跟踪每个区域跳过刷新的次数.控制器用于强制执行特定的质量约束.
3.2 针对内存的近似技术
目前针对内存的近似存储技术大多是针对DRAM的动态刷新等特性所作的优化,不适用于基于新型非易失性存储器(non-volatile storage, NVM)的内存.1)NVM具有无需动态刷新和可持久化保存数据等DRAM不具备的特性,使得针对DRAM的近似存储技术所解决的问题不复存在.例如,NVM不需要动态刷新存储单元,所以无需降低存储单元刷新频率和保留时间的近似存储技术.2)NVM存在DRAM没有的缺陷,例如读写不对称和写耐久度低.因此,针对NVM特性的近似存储技术还有待探索.
DRAM单元将数据存储为电容器上的电荷,三星对DRAM行业进行研究确定了3个主要的威胁:延长恢复时间、频繁刷新和可变保留时间(VRT,variable retention time)[70].本节针对这3个威胁对DRAM的相关近似技术进行了介绍.
1) 减少恢复时间
由于晶体管-电容器之间触点的电阻增加以及较小的晶体管的驱动能力的降低导致需要更长的时间将电量充至目标电压,这种现象称为延长恢复时间.
Zhang等人提出了一种新的细粒度精确感知的DRAM恢复调度技术DrMP[13],并介绍了DrMP的3种变体:DrMP-A,DrMP-P和DrMP-U.它们都能大幅减少恢复时间,DrMP-A通过将重要数据位映射到快速行段来支持近似计算,以减少恢复时间提高性能,并降低了应用级错误.DrMP-P将内存行配对在一起(一行具有快速回复时间、一行具有较慢的回复时间),以减少精确计算的平均恢复时间.DrMP-U结合了DrMP-A和DrMP-P,可以更好地交换性能,能耗和计算精度.
2) 降低刷新频率
DRAM单元必须进行定期的刷新以防止数据丢失.这些刷新操作干扰了内存访问,随着DRAM器件容量的增加,DRAM刷新的负面影响也随之增加.DRAM的刷新操作所消耗的能源占DRAM总能量消耗的很大一部分,其刷新频率通常由少量的弱单元决定.为了减少DRAM能源消耗,可以通过近似存储技术降低其刷新频率,降低刷新率可能会导致数据的错误率的上升,但是却能以较低的错误率大幅度的降低功耗.
Liu等人提出近似感知的DRAM系统Flikker[15],如图7所示.Flikker将数据划分为关键和非关键组,运行时系统将数据分配到不同的内存部分,包含关键数据的内存部分以常规的刷新频率刷新,而包含近似(非关键组)数据的行刷新率被降低.
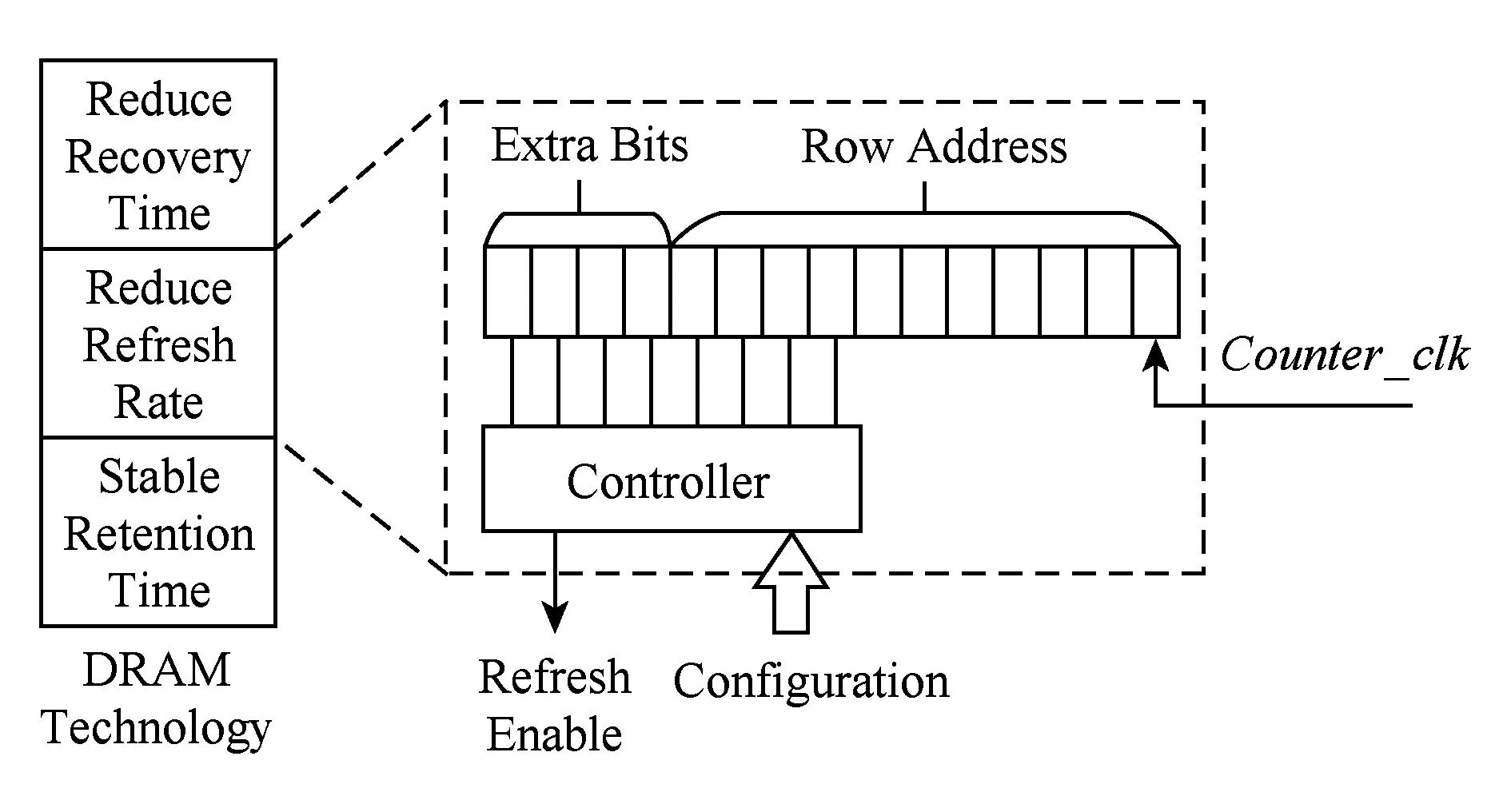
Fig.7 DRAM approximate technique[15]图7 DRAM近似技术[15]
Liu等人提出了感知智能DRAM刷新机制RAIDR[18],根据其保留数据所需的刷新率将DRAM行分组为多个“容器”,每个容器中的行以不同的速率刷新.RAIDR还在内存控制器中存储了保留时间,避免了修改DRAM设备的需要.
3) 稳定的保留时间
DRAM单元可以安全地保留数据而不被刷新的时间量称为单元的保留时间.在当前的系统中,所有DRAM单元都以保证电池完整性所需的频率刷新.可变保留时间对利用保留时间的差异减少不必要刷新带来了难度.
Liu等人从5家主要DRAM供应商的248种商品DDR3 DRAM芯片中收集保留时间信息.他们发现了2种重要现象[71]:1)数据模式依赖,即每个DRAM单元的保留时间受存储在其他DRAM单元中的数据的显着影响;2)可变保留时间,DRAM单元的保留时间随时间不可预知地变化.对未来DRAM扩展和保留时间测量机制提供了方向.
Jung等人提出一个全面的模拟环境[44],用于对近似DRAM进行研究.他们依靠SystemC事务级模型(transaction level model, TLM)进行快速准确的模拟,构建基于模块化的DRAMSys框架,主要由4个关键部分组成:DRAM和核心模型、DRAM功耗模型、散热模型、DRAM保留错误模型.
3.3 针对外存的近似技术
外存具有容量大和访问速度慢的特点,针对外存的近似存储技术更关注如何存储更多的存储数据和减少存储器的磨损.本节针对上述2个问题,阐述了基于外存的相关近似存储技术,如图8所示.

Fig.8 Approximate storage technique for storage图8 针对外存的近似存储技术
3.3.1 近似固态存储技术
固态存储器既可以作为外存存储永久数据,又能够作为主存存储瞬时数据.固态存储器的缺点表现在2个方面:1)磨损不均衡导致寿命不长,厂商标称单级单元(single-level unit, SLC)类型的闪存寿命只有10万次,多级单元(multi-level unit, MLC)类型的寿命更短,只有1万次[72];2)为了向存储单元存储或检索更多的状态导致的长时间等待延迟.
Sampson等人针对上述问题,提出一种近似固态存储技术[5],它能在质量损失忽略不计的情况下,通过将近似数据映射到耗尽硬件纠错资源的块上,以减轻磨损、延长固态存储器的使用寿命;并通过近似配置多级单元,以降低存储或检索的延迟.
最近,Qing等人提出一种能扩大存储容量的高密度图像近似存储算法[19],主张不同的比特单元对应不同的近似程度,这种算法以图像编码算法PTC[20]为基础,与近似存储系统[5]协作,以增加存储单元的密度,存储更多的数据.
3.3.2 降低存储开销的近似技术
诸如图像与视频这样的视觉应用程序在存储时耗费大量的存储空间,尤其是监控类视频更要求码率恒定与持续服务[73].为了节约资源,可以近似存储数据,以减少空间开销.压缩存储能有效节约资源,例如著名的JPEG[56],然而这种商用压缩技术仅用于压缩纹理和颜色数据.后来有研究人员在JPEG的基础上提出了JPEG XR[21].
Dufaux等人提出的图像近似存储算法[22]利用GPGPU工作负载中浮点数的特性,在截断其最低有效位后对浮点数无损压缩.使用这种方法要先研究满足需要的微体系结构,其必须支持GPU和片外存储器之间传输数据的无损压缩技术.这种方法对图像整体计算精度的影响很小.
3.4 近似存储技术小结
从存储的层次结构,缓存、主存、外存3个方面介绍近似存储技术.针对高速缓存,主要介绍了提高缓存访问效率、减小缓存空间开销、降低缓存能耗、提高缓存可靠性的近似存储技术;针对主存,主要对如何克服DRAM延长恢复时间、频繁刷新和可变保留时间的3个缺点分别介绍了相应的近似存储技术;针对外存,主要介绍了近似固态存储技术与降低存储开销的算法.
近似存储作为一项新兴的技术,是近年来存储相关工作的研究重点,本文介绍了部分近年来具有代表性的近似存储技术.一些其他与近似存储相关的技术,应用于存储的多个层次,如表3中Mixed Layer所示,Chisel[14]优化运行在近似硬件平台的内核以自动选择可能存储在近似内存中的近似指令和数据,UncertainT[24]为近似数据在近似硬件平台上设计一种近似编程语言以映射到近似器件运行和存储,文献[23]的技术基于SIMD体系结构通过重用程序运行中的局部结果以减小错误恢复的成本,文献[10]通过重新构建新的指令集使程序能近似计算与存储.
4 总结与展望
近似存储技术作为解决存储资源紧张的必要手段,是近年来存储相关工作的研究重点.本文简要介绍了近似存储以及近似存储的一般过程,并依据存储架构的主要层次,分别从基于高速缓存、内存、外存3个方面,详细介绍近似存储技术的研究现状.
近似存储技术对应用程序中可近似数据采取不精确的存储方法,提高存储空间的利用率、加速存储访问效率、节约能源消耗、减少器件磨损,从而提升存储器性能,以解决目前存储领域面临的存储资源紧张、能源消耗高、读取速度低等问题.
但是,目前的近似存储研究工作仍然存在不足与待改进之处体现在4个方面:
1) 目前的近似存储技术为了区分程序的近似与精确部分,需要对程序进行预处理.然而,现有预处理方法复杂高且不具有一般性.因此,简便高效、通用的近似区域查找方法是未来近似存储领域的一项重要研究内容.
2) 现有提高存储访问效率的近似存储技术集中在缓存层面,用于缩小内存与处理器之间的访问速度差距.然而,如何利用近似存储技术缩小内外存之间的数据访问速度差异是亟待解决的问题.
3) 近年来,新型非易失性存储器件飞速发展,展现出DRAM级数据访问速度、数据掉电不丢失和存储密度大等优点,是可以用作高速缓存、内存或外存的下一代存储设备.然而,基于新型非易失性存储器的近似技术研究进展缓慢.面向各个存储层次,研究优化新型非易失性存储器中的数据访问性能、存储开销和存储磨损度的近似存储技术是一个极具前景的研究方向.
4) 由于每个用户对输出质量损失的接受程度不同,在近似存储技术权衡数据精确度与输出质量时,如何找到一个令大部分用户满意的质量下降阈值是一个难题.为此,保证近似存储可靠性的质量下降阈值设定方法是未来必须研究的近似存储关键技术.
