一种基于模糊哈希的Android变种恶意软件检测方法
2018-09-18王文冲
王文冲,凌 捷
广东工业大学 计算机学院,广州 510006
1 引言
恶意代码已经成为当今计算机系统中最严重的安全威胁之一。在Android移动平台中,恶意软件的数目与日剧增。据2016年第二季度MaAfee Labs统计数据表明,新增移动端恶意软件数量近200万,相比于第一季度增长了14%,而总数量则高达1 100万[1]。面对着如此庞大的数字,需要有一个高效快速的方法,来自动对大量的应用软件进行扫描并检测。传统的商业安全软件中,为了能够具备更高的实时检测速度,大都是通过提取字符串作为特征码。在检测过程中,安全软件只需直接判断其是否拥有与已知特征码相同的字符串[2]。然而,这种基于字符串的特征码提取方法有着一定程度上的不足,就是难以检测到多态变形的恶意软件[3]。
当前Android恶意软件检测及分类方法总体可以分为两大类:(1)基于特征码的恶意代码检测方法。(2)基于机器学习算法的恶意代码检测方法。基于特征码的检测方法是通过判断待检测软件中是否拥有与已知恶意代码相匹配的API或者字符串等字节码数据来实现的。这种方法具有极高的检测速度,但是很容易遭受代码混淆攻击[4]。基于机器学习的检测方法[5-8]则是通过提取出应用程序的行为特征,如权限请求、关键API等信息,并运用机器学习算法来对大量的样本数据进行分类检测。然而这些方法都没有结合实际的语义进行分析,因此很大程度上会出现检测错误。因为即使是具备相同的API集合但是调用次序的差异将会直接导致整个软件行为极大的不同。
为了解决此类问题,部分学者提出了对应用软件进行语义分析,以图表的形式来表示整个应用软件中代码间的调用情况。文献[9-11]是直接将已知待检测应用软件调用图与恶意代码库中调用图进行匹配,当一致时则表明为恶意软件。然而,直接利用这种精确匹配的方法难以抵抗代码混淆攻击[12],并且无法检测出未知恶意软件。随后很多学者在此基础上对该方法进行了改进,其中,文献[13]提出一种度量各API调用图间相似度的方法,能够有效地检测出各类多态变形软件。文献[14-15]利用消息标记的方法来跟踪应用程序代码中敏感信息的流向。文献[16]则利用调用图来反向跟踪敏感行为触发的上下文环境。然而,直接利用这种利用调用图的分析方法,在检测的时候,需要对整个文件逻辑进行分析,极大地降低了检测效率,特别面对复杂调用图匹时,其计算复杂度急剧增长。因此该类方法并不适用于当今巨大的病毒样本。文献[17]中利用机器学习的方法来提取Android应用程序中所使用权限的特征,并用于恶意代码检测。在文献[18]中则是利用数据挖掘中神经网络算法来对恶意代码行为进行分析。文献[19]以大量的样本数据为基础,从中提取与已知恶意软件的特征,并利用这些特征来用于对新样本的检测。而文献[20]则是根据每个应用程序的执行权限、API调用流程等特征,利用KNN算法来对不同种类的应用程序进行分类。随后的文献[21-23]相继使用SVM、贝叶斯等算法来实现恶意软件的分类。然而,这种基于机器学习的方法是从统计学的角度去提取特征,很容易出现误检现象。
目前为止,仍未能够有一种有效的方法来对未知恶意软件进行检测,很大程度上依赖于人工分析来实现。然而,由于恶意软件的数量与日俱增,其中存在大量的变种病毒。因此需要有一种快速高效的方法对未知的样本进行过滤,从而来降低人工分析成本。针对此问题,Jesse等人[24]利用模糊哈希算法来识别检测相同类别的恶意软件。然而该方法只能对相似文件进行检测,一旦文件结构出现变化,将无法检测。在此基础上,本文通过自动化提取Apk中字符串以及函数长度分布信息来生成模糊哈希值,具有更高的抗干扰性,同时通过简化病毒库来提高检测速度。
2 基本思路
在本文中,首先对Apk字符串以及函数长度这两方面的信息特征提取,并将其映射为模糊哈希值的形式,使得相同种类的恶意软件之间具有相似的哈希值。再将已知的恶意软件样本生成的模糊哈希值作为特征库,用于对变种的检测。同时为了提高检测效率,在病毒库中使用k-means算法对其进行聚类,并将每一类别的质点来代表该种类中其他所有的变种病毒,从而简化整个病毒库,并提高检测效率。系统框架如图1所示。

图1 系统框架流程图
3 恶意特征提取方法
在Apk中不同应用程序所使用的字符串以及函数长度的分布情况都不一样,然而对于同一种类的变种Apk中只是对少部分字符串以及功能函数做修改。因此,将字符串以及函数长度分布这两方面来作为特征信息,用于对变种病毒的识别。分别如下:
(1)字符串特征,提取出应用软件中特有的字符串信息。文献[25]中通过提取将PC端应用软件中字符串来对恶意软件进行分类,并取得较好的效果。本文在此基础上,根据Apk字节码的结构特点,并结合布隆过滤器(Bloom Filter),提出一种高效字符串的特征向量生成方法。
(2)函数长度分布特征,即提取代码中不同长度函数的数量各自所占比例信息。在这一部分将文献[26]所提出的方法做稍微修改并应用到Android平台的应用软件中。
字符串以及函数特征所生成的向量组合在一起,从而生成该应用程序对应的模糊哈希值。由于在同一个Apk中包名进行字符串混淆时,常使得字符串特征向量出现变化,但其函数特征向量仍然不变。同样的,在某些Apk包中函数数量较小时,彼此函数特征向量的彼此距离并不明显。因此,将两种特征向量结合,并作为该Apk包的模糊哈希值,能够更为准确地描述整个Apk包,并使得相同种类的Apk包具有相近的模糊哈希值。
3.1 模糊哈希算法相关理论
文本中常包含大量的信息,对其进行比较时常需要在高纬度空间中查找最近邻关系。特别是当文本较大时,其计算复杂度以及存储空间将剧增。为了解决此问题,需要对文本进行降维处理。运用具有局部敏感特性的哈希函数h,将文件映射为低维数据,并以散列值的形式来表示。对文件相似性比较时,期望内容近似但数据并不完全相同的源文件拥有相似或相同的哈希值。
记高维空间中存在任意两个数据点x,y,其度量函数为d(x,y),给定两个距离d1,d2(0 其中,p1>p2,则称h为模糊哈希函数。 通常使用对文件进行分片的形式来实现,并使用高效检索哈希或加密哈希算法计算出每一片的哈希值,最后将所有分片的哈希值串联起来作为文件的哈希值进行比较。分片哈希可以将哈希值的变化限制在文件内容发生变化的分片之内,而保持其他分片的哈希值不变。本文将在此基础上提出一种针对Apk包的模糊哈希值产生方法,使其具有更高的计算速度以及抗干扰性。 在Apk应用程序中,每一种类别Apk都会有自己特有的字符串信息,在此通过解析dex文件可以提取其所使用的字符串,图2为某一Apk包中所使用的部分字符串列表。 图2 字符串列表 不同应用程序所使用的字符串都不一样,然而对于同一种类的变种Apk中只是对少部分字符串做修改,它们彼此含有大量相同的字符串。因此,可以将字符串的相似程度来作为特征来实现对变种应用程序的识别。 然而,直接对每个应用程序中所有字符串进行匹配,来计算彼此包含的相同字符串的数量是很不现实的。因为每个Apk包中字符串的数量成千上万个,时间复杂度高达O(n2)。 在本文中,使用哈希算法,将Apk中所有字符串映射成一个特征向量。当两个Apk含有相同字符串越多,其对应的特征向量间距离越小。 记Apk中字符串集合为: 哈希函数为Hash(x),使其满足: 图3 字符串映射 具体实现算法如下: 算法1字符串特征向量生成 输入:初始化Apk字符串集合S。 输出:特征向量SV。 该算法中,首先提取出应用程序所包含的所有字符串,再利用哈希函数Hash()来计算各个字符串的哈希值,再将特征向量中该哈希值所对应的位置数值加1。从而得到该Apk的字符串特征向量SV={sv1,sv2,…,svm}。 每个不同的Apk应用程序包中所包含的函数数量以及各个函数的长度均有所不同,在此以函数中所包含指令的字节数来表示其的长度。 下面通过解析Apk中dex文件来获取各个函数的长度,并根据长度从大到小的顺序对函数进行排序,如图4所示。其中每一个点的坐标(x,y)表示第x个函数的长度值为y。图中蓝色与绿色分别表示两个不同Apk包中函数的长度分布情况。 图4 函数长度分布图 在此,同样需要将Apk包的函数分别特征映射为特征向量的形式。 记Apk中各个函数的长度集合为: 其中 fi表示第i个函数的长度,n为Apk中包含的函数数量,且 fi≤fi+1,1≤i≤n。 根据应用程序中函数的长度特征,选取指数模型(y=aekx+b)来表征各个区间的取值范围,其中a,b,k为常数,x=1,2,…,m。记函数的最大长度为L,记为 fn,为了满足y(0)=1,y(m)=L,在此可令a=1,b=0,k=ln(L)/m。则此时每个区间记为: 其中,x=0,2,…,m-1。 下面以一个例子来说明,设某一Apk应用程序中函数长度分布分别为:(2,2,3,6,8,8,10,11,15,20,24,33,45,70,77,132)。 其最大值L=132,分组数m=4。此时各个区间分别为: [1,3.4),[3.4,11.5),[11.5,38.8),[38.8,132) 因此,其函数分布特征向量:FV={3,5,4,4}。 本文结合前面提到两种方法分别来提取应用程序的字符串特征以及函数特征,并用于生成模糊哈希值。由于同一变种恶意软件中常常具有相同或相似的字符串或函数长度分布特征,因此,在对变种病毒进行检测时,通过利用模糊哈希值之间的距离计算即可,当彼此具有相近的距离时,表示检测到变种病毒。 令模糊哈希值FH=(SV,FV),并以曼哈顿距离来度量两个模糊哈希值间的相似程度。 记两个模糊哈希值分别为: 则,其距离定义为: 对变种病毒进行检测时,直接通过对模糊哈希值间距离的计算即可匹配到相似的Apk,极大地提高了检测效率。 在实现对变种恶意软件检测时,首先计算病毒库中样本的模糊哈希值FH,利用k-means算法对模糊哈希值进行聚类,并将聚类后各类别的质点来代表该类中其他所有点。当需要对未知的恶意软件进行检测时,只需计算该恶意软件的模糊哈希值与各类别的质点之间的距离,当距离小于某一阈值时,则说明该恶意软件属于某一类别病毒的变种。这样可以无需对病毒库中所有模糊哈希值进行距离的计算,极大地提高了检测速度,且压缩病毒库的存储空间。 利用模糊哈希值以及k-means算法来生成能用于检测变种的病毒特征库。 算法2病毒样本特征库生成 输入:变种家族数k,模糊哈希值集合{FH1,FH2,…,FHN},N为样本数量。 输出:病毒样本特征库V。 1.随机选取 k 个聚类质点为 μ1,μ2,…,μk 2.重复下面过程直到收敛 对每个样本i,计算其所属家族类 对每一个家族类 j,重新计算质心 3.将所有质点μ添加到特征库V中 以质心代表整个样本族中所有样本,极大地降低了特征库的大小,从而提高检测速度。对于每一个新样本的检测,只需计算其模糊哈希值与各变种家族的质心之间的距离,当距离小于该变种家族中的最大距离时,则表示其该新样本属于该家族。在添加新样本后再重新计算该变种家族的质心μ。 算法3病毒样本特征库生成 输入:病毒特征库V,新样本FH 输出:更新病毒特征库V′ 为了验证本文所提出方法在对变种恶意软件检测的有效性,分别从检测准确率、误检率以及检测速度三方面进行分析评估。文中实验样本是由文献[27]提供的Android恶意软件样本库作,以及从应用市场下载的200个正常应用软件为测试数据。 本实验中将字符串特征向量以及函数特征向量的维度m均取值为5,产生模糊哈希值。再对300多个Android恶意软件样本抽样,并生成病毒库。之后再利用k-means聚类,来得到各家族的质点,从而实现对病毒库的简化。如表1所示,在此只列举25个样本数据。 表1 病毒库聚类 图5 检测准确率及误检率 为了能够评估本文所提出方法的有效性,分别从检测准确率、误检率这两方面进行度量。其中记能被检测到的恶意软件数量为TM,未能被检测到的恶意软件数量为FM,被误检的正常软件数量为TN,没被误检的正常软件数量为FN,则: 检测准确率:P=TM/(TM+FM) 误检率:E=TN/(TN+FN) 下面分别用ssdeep及本文方法(Ours),对300多个Android恶意软件样本家族聚类的准确率以及对200个正常软件的误检率进行对比,如图5所示。 在上面实验中,由于FakeNotify、Pjapps、DroidKungFu2这三种类别的恶意软件家族中部分样本的资源文件以及部分指令发生了修改,造成了使用ssdeep算法计算出来的模糊哈希值存在较大的变化。本文提出的方法是从dex文件中的字符串以及函数中来提取特征产生模糊哈希值,能够具有较高的抗干扰效果。对于Kmin以及DroidKungFu3这两种类别的恶意软件,是由正常应用中插入了少量的恶意代码,使得与原正常应用差异较小,因此其误检率相对较高。为解决此问题,可以使用白名单以及签名验证的方式来避免。 同时,在对运行效率分析时,模拟对样本数量为5 000、10 000以及500 000的病毒库进行扫描,产生样本特征库所用时间进行对比,如图6。 图6 运行时间对比 由于ssdeep是逐字节读取固定长度的内容,以固定窗口的形式进行滑动,每次对窗口内的内容进行计算,最终再将各个窗口的哈希值进行组合产生模糊哈希值,并以加权编辑距离来度量任意两个模糊哈希值之间的相似度。这需要耗费大量的计算。而本文中所提出的方法是直接解析dex文件,提取出里面字符串以及函数的信息并生成模糊哈希值,具有较高的运算速度。 本文从字符串以及函数长度分布这两个方面来提取Apk应用程序包的特征信息,用于产生模糊哈希值。该值能够准确地描述样本特征,并使得相似的Apk包的模糊哈希值之间的距离较短。再利用k-means聚类算法来对样本库中所有模糊哈希值进行聚类,得到每一家族样本的质点。在对新样本进行检测时,只需计算与各家族样本的质点之间相似度,减少了病毒库中样本数,从而提高了检测速度。
3.2 字符串特征提取方法

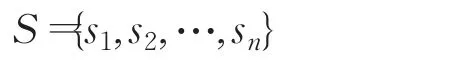



3.3 函数长度分布信息提取

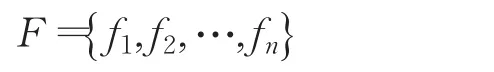

4 特征病毒库生成及变种检测





5 实验结果与分析



6 结束语
