基于包含度和频繁模式的文本特征选择方法
2018-09-18池云仙赵书良李仁杰
池云仙, 赵书良, 李仁杰
(1. 河北师范大学 资源与环境科学学院,河北 石家庄 050024;2. 河北师范大学 数学与信息科学学院,河北 石家庄 050024)
0 引言
文本数据维度在大数据时代下呈迅猛增长趋势。在影响数据挖掘性能的各因素中,特征选择成为其中至关重要的环节之一。特征选择通过提取特征子集来有效缩小高维特征空间,可有效提高数据挖掘性能,故各领域学者均致力于特征选择方法的研究。Zhao等基于特征选择算法“保留样本相似性”的共同点,提出一种通用的相似性保留特征选择框架[1]。Zhuang等提出基于主题模型进行特征选择以提高模型预测性能的ssLDA模型[2]。Song等提出基于图论聚类模型的高维数据子类划分与关联特征子集速选方法[3]。Li等提出基于文档与特征关联性的关联特征选择方法[4]。张延祥等针对数据不平衡问题提出基于类别区分力的文本特征选择方法DA[5]。
“基于词语”的特征选择方法,因其被“同义词、一词多义及噪声词语”等问题所困扰,特征提取效率大打折扣。相比之下,“基于模式”方法凭借“保留词语间关联性”的优势,很好地克服了以上问题。它可以在从“数据”中高效挖掘“知识”的同时,有效减轻“数据爆炸”问题带给大数据时代的困扰。作为数据挖掘领域的重点与热点,“基于模式”研究已扩展至诸多领域。Gao等提出基于主题最大匹配模式的文档过滤模型MPBTM,依托用户所需信息与模式间的关联度去除不相关文档[6]。Zhao等提出基于未确定数据库的潜在频繁序列模式挖掘方法[7]。Kessl提出基于概率性平衡负载的并行频繁序列模式挖掘方法[8]。Pumjun等提出基于动态数据库调整支持度阈值的多级关联规则挖掘模型MLUPCS[9]。Zhang等提出基于马尔科夫性质的DNA序列模式挖掘模型[10]。Turdi等结合维吾尔文间关联规则进行频繁模式挖掘,进而实现语义串快速抽取[11]。
“通过最优化特征排序标准来进行特征排序与选择”的思想是大多特征选择方法的共同特点,但由此产生的“相关特征排序相近”的特征冗余问题严重影响文本挖掘效率。因此,将冗余特征进行去噪处理将明显提升文本挖掘性能。Ding等提出基于贪心算法的连续特征选择冗余最小化方法mRMR[12]。Wang等提出基于全局冗余最小化的整体局部差异化特征选择方法[13]。
事物间的“差异性”和“不确定性”是普遍存在的,而这种“相似程度”和“不定关系”通常用包含度原理进行描述。Gong等提出基于模糊集包含度的非参数统计模型[14]。Ma等在模糊粗糙集的基础上提出包含度与相似度计算的通用模型[15]。Liu等提出基于最大包含度原理的样本决策表分类方法[16]。李阳等基于知识图谱提出一种通用的实体相似性度量方法[17]。
为扩充基于频繁模式的文本特征选择方法在文本挖掘领域的应用,提出基于包含度和频繁模式的文本特征选择方法TFSIDFP。TFSIDFP方法利用频繁模式词语间的关联,有效避免了“基于词语”方法的噪声问题影响;同时,利用包含度原理可以对文本中的冗余频繁模式进行过滤,有效提高了模式提取效率及特征选择性能。
后续内容为: 第一节介绍基于包含度和频繁模式进行文本特征选择的模型框架;第二节详细介绍基于包含度和频繁模式的文本特征选择方法;第三节为实验;第四节为全文总结。
1 模型框架
基于包含度和频繁模式进行文本特征选择,旨在基于包含度原理过滤掉文本中的冗余频繁模式,并在经过优化处理后的非冗余文本频繁模式基础上进行文本特征选择。该框架主要分为以下几部分:
(1) 文本频繁模式挖掘: 利用FP-Growth算法挖掘文本中所有频繁模式;
(2) 冗余文本频繁模式过滤: 基于包含度原理,度量文本频繁模式间的相似性,将子模式和相似度高于阈值的交叉模式进行去冗余操作;
(3) 非冗余文本频繁模式特征选择: 基于过滤后的非冗余频繁模式,进行文本特征选择,并利用特征与文档的关联度进行词语类别划分及权重分配;
(4) 文本分类: 利用所选择的特征词语进行文本分类。
基于包含度和频繁模式的文本特征选择流程图如图1所示。
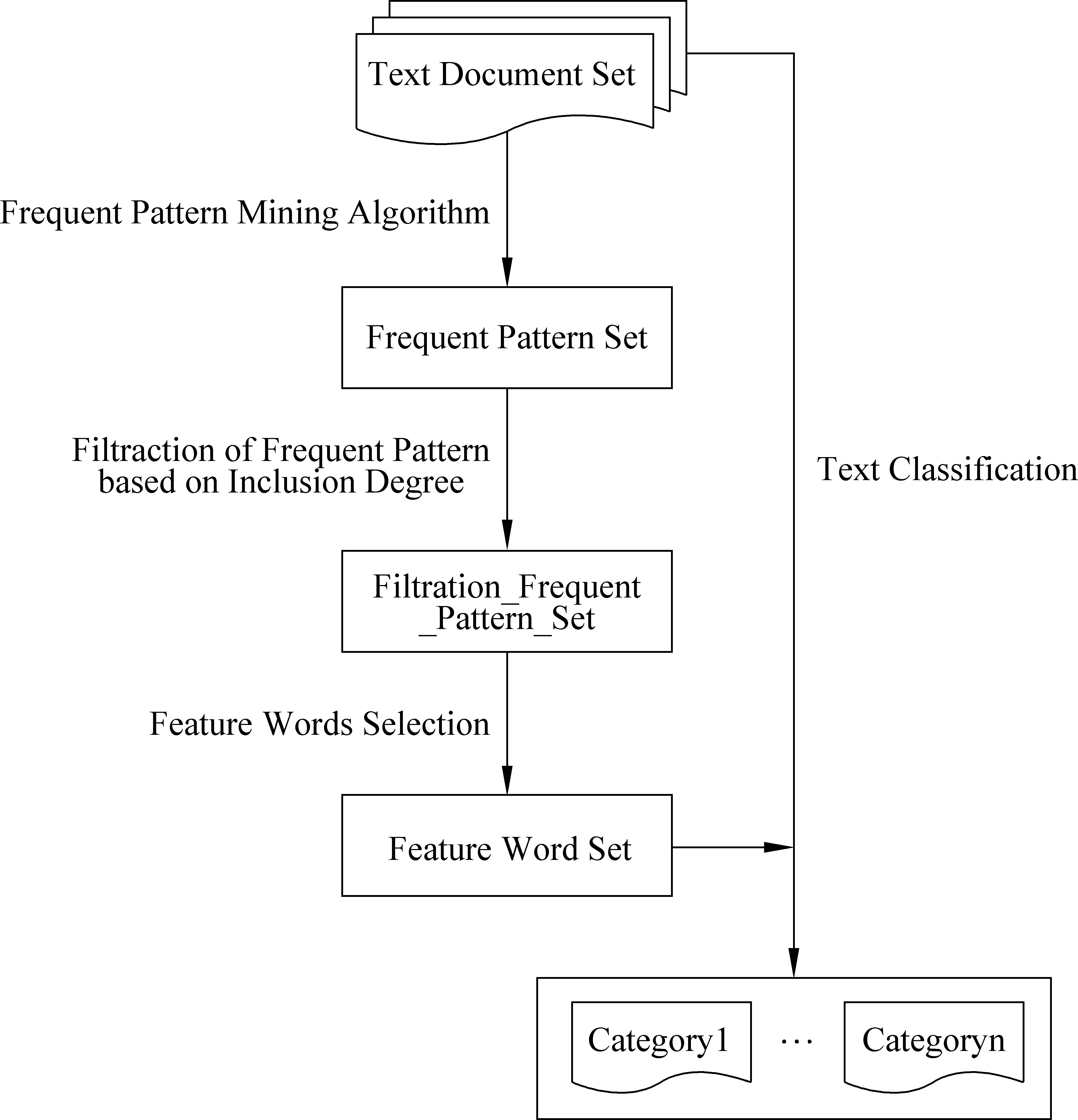
图1 基于包含度和频繁模式的文本特征选择流程图
2 基于包含度和频繁模式的文本特征选择方法
文本频繁模式挖掘过程中会不可避免地产生大量冗余模式。例如,较长文本频繁模式所蕴含的子模式集合以及与该文本频繁模式相似的交叉模式集
合,对于同一类别主题而言,往往是冗余的。冗余模式会严重制约文本挖掘性能。因此,为提高文本分类运行效率,本文提出基于包含度和频繁模式的文本特征选择算法TFSIDFP。首先,提出基于包含度的相似性度量原理;然后,提出基于包含度的冗余文本频繁模式过滤方法;最后,提出基于关联度的文本特征选择方法。
2.1 基于包含度的相似性度量原理
“包含度”概念源于真实世界中信息的“不完整性”。这种“不完整性”无法用经典逻辑问题的两个绝对标准(“相等”和“不相等”)度量,由此便衍生出包含度理论。
冗余模式产生问题在挖掘文本频繁模式的过程中无法规避。这不仅影响模式挖掘效率,还会间接制约文本特征选择性能。基于包含度理论对待度量的文本频繁模式进行评估,先过滤掉相似度超过预定阈值的冗余模式,可有效地缩减文本频繁模式集合的规模,进而提高文本频繁模式的挖掘性能。首先,定义“包含度”和“相似度”的概念;然后,提出并证明基于包含度的相似性度量原理的性质。
定义1包含度(InclusionDegree) 设论域Dom_Dis有两个子集Dom_SubA和Dom_SubB,即Dom_SubA,Dom_SubB⊆Dom_Dis。 若存在IDDom_SubB/Dom_SubA满足下述三个性质:
(Ⅰ) 非负性: 0≤ID(Dom_SubB/Dom_SubA)≤1;
(Ⅱ) 规范性: 当Dom_SubA⊆Dom_SubB时,IDDom_SubB/Dom_SubA=1;
(Ⅲ) 传递性: 当Dom_SubA⊆Dom_SubB⊆Dom_SubC时,有IDDom_SubA/Dom_SubC≤IDDom_SubA/Dom_SubB。
则称IDDom_SubB/Dom_SubA为Dom_SubB包含Dom_SubA(或Dom_SubA包含于Dom_SubB)的包含度。
定义2相似度(SimilarityDegree) 设论域Dom_Dis有两个子集Dom_SubA和Dom_SubB,即Dom_SubA,Dom_SubB⊆Dom_Dis。 若存在SD(Dom_SubA,Dom_SubB)满足下述四个性质:
(Ⅰ) 非负性: 0≤SD(Dom_SubA,Dom_SubB)≤1;
(Ⅱ) 自反性:SDDom_SubA,Dom_SubA=1;
(Ⅲ) 对称性:SDDom_SubA,Dom_SubB=SDDom_SubB,Dom_SubA;
(Ⅳ) 传递性: 当Dom_SubA⊆Dom_SubB⊆Dom_SubC时,有SDDom_SubA,Dom_SubB≥SDDom_SubA,Dom_SubC。
则称SDDom_SubA,Dom_SubB为Dom_SubA和Dom_SubB之间的相似度。
性质1设论域Dom_Dis有两个子集Dom_SubA和Dom_SubB,即Dom_SubA,Dom_SubB⊆Dom_Dis。 那么,Dom_SubA和Dom_SubB之间基于包含度的相似性度量公式如式(1)所示。
其中,NumDom_SubA∩Dom_SubB为集合Dom_SubA和Dom_SubB公共元素数目,NumDom_SubA∪Dom_SubB为集合Dom_SubA和Dom_SubB中互异元素总数。
证明:
(一)相似性证明:
(Ⅰ) 非负性:
(Ⅱ) 自反性:
SDDom_SubA,Dom_SubA
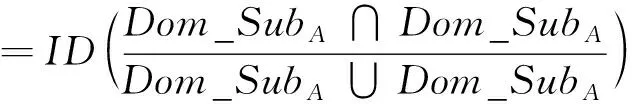
=IDDom_SubA/Dom_SubA=1;
(Ⅲ) 对称性:
SDDom_SubA,Dom_SubB

=SDDom_SubB,Dom_SubA;
(Ⅳ) 传递性: 当Dom_SubA⊆Dom_SubB⊆Dom_SubC时,
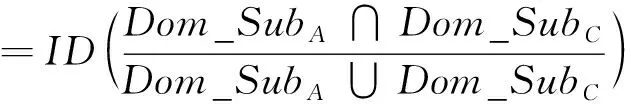
=IDDom_SubA/Dom_SubC。

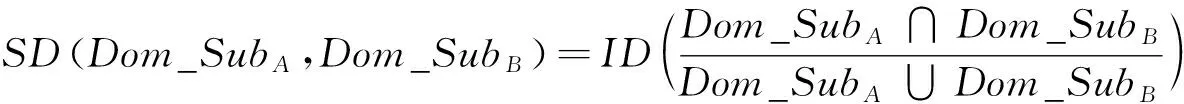
(二)包含度证明:
(Ⅱ) 规范性: 由于Dom_SubA∩Dom_SubB⊆Dom_SubA∪Dom_SubB,则
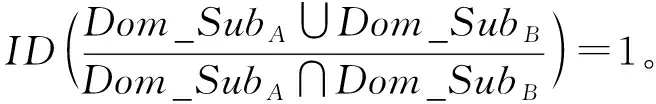
(Ⅲ) 传递性:
当Dom_SubA∩Dom_SubB⊆(Dom_SubA∪Dom_SubB)⊆Dom_SubC,
那么,Num((Dom_SubA∩Dom_SubB)∩(Dom_SubA∪Dom_SubB))=Num(Dom_SubA∩Dom_SubB),
NumDom_SubA∩Dom_SubB∩Dom_SubC=NumDom_SubA∩Dom_SubB。
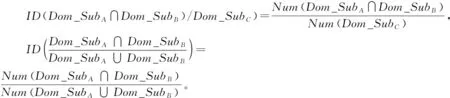
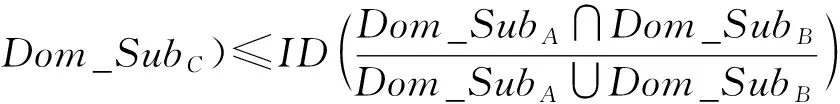
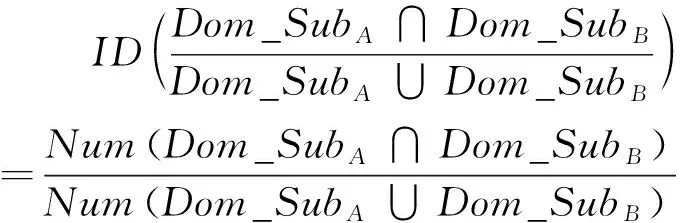
综上所述,基于包含度的相似性度量公式为
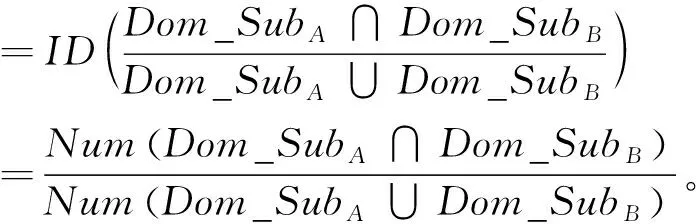
证毕。
例如,基于FP-Growth算法挖掘三个频繁模式X:
若相似度阈值预先设定为SD≥0.7,则将X和Y视为相似模式,X和Z视为非相似模式。根据2.2节保留较长模式的原则,在进行冗余频繁模式过滤操作时,会将Y从模式集合中去除。
2.2 基于包含度的冗余文本频繁模式过滤方法
定义3频繁模式(FrequentPattern)指频繁出现在数据集中的模式,含频繁项集、子序列或子结构。
定义4文本频繁模式(TextFrequentPattern) 若文档Td中某一词集WSeti_Td={w1,w2,…,wq}⊆W的支持度满足SupportWSeti_Td≥MinSupport,则称WSeti_Td构成的模式为文本频繁模式,记作TFP。其中MinSupport为预定的最小支持度。
定义5文本频繁子模式(TextFrequentSubpattern)若两个文本频繁模式TFPi和TFPj对应词集WSet_TFPi和WSet_TFPj满足关系WSet_TFPi⊆WSet_TFPj,则称TFPi为TFPj的文本频繁子模式,记为TFPi⊆TFPj。
定义6文本频繁交叉模式(TextFrequentCrossPattern)若两个文本频繁模式TFPi和TFPj对应词集WSet_TFPi和WSet_TFPj满足关系WSet_TFPi⊄WSet_TFPj&WSet_TFPj⊄WSet_TFPi&WSet_TFPi∩WSet_TFPj≠Φ,那么TFPi与TFPj为文本频繁交叉模式,记为TFPi⊄TFPj&TFPj⊄TFPi&TFPi∩TFPj≠Φ。
频繁模式挖掘过程中不可避免地会受到噪声问题的影响。较长的频繁模式往往包含比较短模式更多的有用信息,有时甚至可以完全覆盖某些子模式,因此在模式过滤中留下较长的频繁模式可保留更多与类别相关的信息,对于类别划分更加有利。
设TFPSet=TFP1,TFP2,…,TFPn为文本频繁模式全集,集合中的频繁模式按照模式长度进行降序排序。文本频繁模式过滤集合初始化为Filter_TFPSet=Φ。 从集合TFPSet中依次选取频繁模式与Filter_TFPSet中的模式做比较。对于∀TFPi∈TFPSet,TFSIDFP算法进行冗余文本频繁模式过滤的过程如下:
(1) 对于∀TFPj∈Filter_TFPSet:
① 若TFPi为TFPj的文本频繁子模式,即TFPi⊆TFPj,则执行冗余模式过滤操作TFPSet-TFPi;
② 若TFPi和TFPj为文本频繁交叉模式,即TFPi⊄TFPj&TFPj⊄TFPi&TFPi∩TFPj≠Φ,则计算其相似度SDTFPi,TFPj,若SD(TFPi,TFPj)≥θ(θ为预定相似度阈值),则执行冗余模式过滤操作TFPSet-TFPi,同时归并支持度SupportTFPj=SupportTFPj+SupportTFPi;
③ 否则,执行文本频繁模式计数器增值操作TFP_counti++。
(2) 若TFP_counti=Filter_TFPSet,表示TFPi与Filter_TFPSet中任意文本频繁模式TFPj均不存在子模式或高相似度交叉模式关系,则将TFPi归入Filter_TFPSet,并从TFPSet中去除。
(3) 重复执行过程(1)(2),直至TFPSet=Φ。
经过冗余文本频繁模式过滤,可明显缩减文本频繁模式集合容量,提高文本频繁模式挖掘效率,进而提升文本特征选择的性能。
2.3 基于关联度的文本特征选择方法
本节在经过过滤优化处理后的非冗余文本频繁模式基础上,基于特征与文档的不同关联度对特征进行类别划分及权重分配,以此实现文本特征选择。
定义7关联文档和非关联文档(CorrelatedDocumentandUncorrelatedDocument) 指定类别C,若文本文档Td满足Td∈C,则称Td为关联文档。所有关联文档集合表示为TDcor={Td|Td∈C}。 若文档Td满足Td∉C,则称Td为非关联文档,所有非关联文档集合表示为TDuncor={Td|Td∉C}。Td的训练集合为TD=TDcor∪TDuncor。
定义8嵌入式文档(EmbeddedDocument)WSet_TDcor表示关联文档集合TDcor的词集。对于任意词语w∈WSet_TDcor,有
称为词语w的嵌入式关联文档集。
称为w的嵌入式非关联文档集。
定义9关联度函数(CorrelativeDegreeFunction) 在训练集TD=TDcor∪TDuncor中,词语w与文档间的关联度函数为:
其中,n=TDcor为关联文档数目。CorDeg(w)值越大,代表w与预定类别关联度越大。CorDeg(w)>0表示w较常描述关联文档;反之,则说明w描述非关联文档较多。
定义10关联特征词语和普通特征词语(CorrelatedFeatureWordandGeneralFeatureWord) 频繁出现在关联文档中且较少出现在非关联文档中的词语称为关联特征词语,如式(5)所示。
频繁出现在关联和非关联文档中的词语称为普通特征词语,如式(6)所示。
其中,δ表示CorFW和GenFW的关联度界限。
定义11特征选择支持度(FeatureSelectionSupport) 词语wj的特征选择支持度定义,如式(7)所示。

定义12特征权重分配函数(FeatureWeightDistributionFunction) 词语w在关联文档集合TDcor中的特征选择支持度为FS_Support(w,TDcor),与预定类别的关联度为CorDegw,则w的特征权重分配函数定义,如式(8)所示。
例如,假设训练集中包含的文档总数为5,其中,3个关联文档Td1,Td2,Td3中包含特征词w2,且有1个非关联文档Td4也包含w2。 从Td1,Td2,Td3中提取的频繁模式如表1所示(符号< >脚标为频繁模式对应支持度):
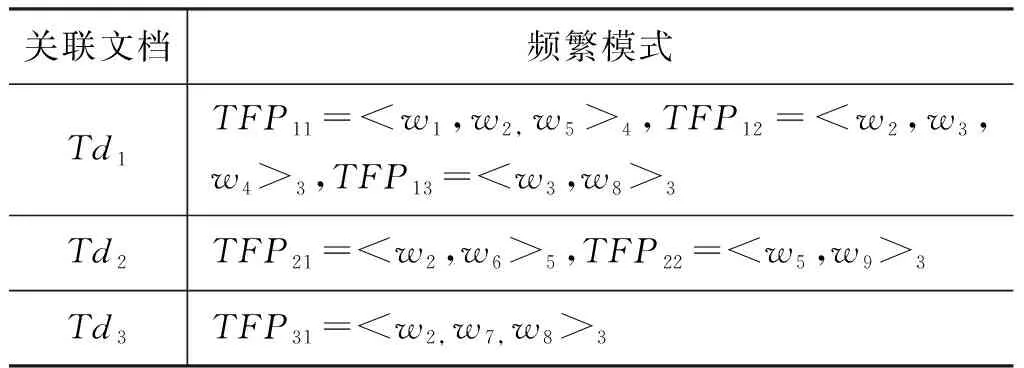
表1 文档与对应的频繁模式
那么,特征词语w2的权重计算如下:
其中,ωw12=
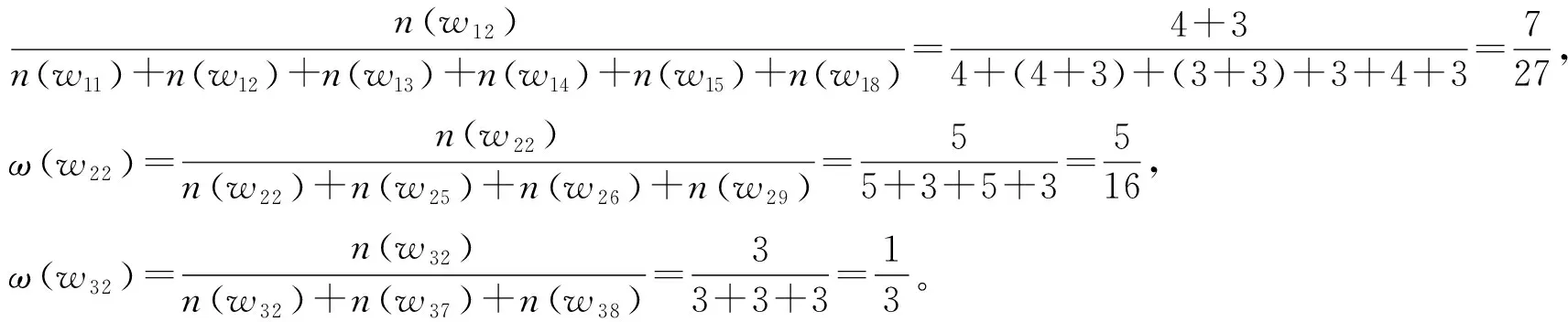
(3) 特征权重:Weightw2=FS_Support(w2,TDcor)1+CorDegw2=0.905×(1+0.4)=1.267。
2.4 算法伪代码
算法1为基于包含度和频繁模式的文本特征选择算法TFSIDFP。步骤1-26为冗余文本频繁模式过滤过程,步骤27-42为文本特征选择过程。其中,步骤1初始化文本频繁模式过滤集合Filter_TFPSet和文本频繁模式计数器TFP_counti;步骤2利用FP-Growth算法挖掘所有文本频繁模式,并按长度进行降序排序;步骤3-6判断集合Filter_TFPSet是否为空,将TFPSet中首个文本频繁模式TFP1从集合中删除,加入Filter_TFPSet中;步骤7-20为冗余模式过滤过程,将TFPSet与Filter_TFPSet中模式逐一比较,若TFPSet中模式为Filter_TFPSet中模式的子模式或二者相似度大于预定阈值,则将其从TFPSet中删除,否则加入Filter_TFPSet中;步骤21-26将非冗余文本频繁模式加入Filter_TFPSet,判定TFPi并非Filter_TFPSet中任意文本频繁模式TFPj的子模式或相似度较高的交差模式,则将TFPi选入集合Filter_TFPSet,并从TFPSet中删除。步骤27-30定义变量及集合的值;步骤31-34计算文本特征词语支持度及关联度;步骤35-36为特征词语类别划分,采用聚类方式确定关联度界限δ;步骤37-42为文本特征词语加权;步骤43返回文本频繁模式过滤集合及特征词语权重。

算法1 基于包含度和频繁模式的文本特征选择算法TFSIDFP
INPUT: 关联文档集合TDcor和非关联文档集合TDuncor,其中Tdi∈TDcor;相似度阈值θ;
OUTPUT: 文本频繁模式过滤集合Filter_TFPSet;文本特征词语权重:Weightw。
METHOD:
/*冗余模式过滤*/
(1)Filter_TFPSet=Φ,TFP_counti=0
(2)TFPSet=procedureFP_Growth(Tdi) /*挖掘频繁模式,并按模式长度降序排序*/
/*判断Filter_TFPSet是否为空,将TFPSet中第一个模式TFP1从集合中删除,并加入Filter_TFPSet*/
(3)IFFilter_TFPSet=ΦTHEN
(4)TFPSet=TFPSet-TFP1
(5)Filter_TFPSet=Filter_TFPSet∪P1
(6)ENDIF
/*冗余模式过滤过程*/
(7)FOREACHTFPiINTFPSetDO
(8)FOREACHTFPjINFilter_TFPSetDO
(9)IFTFPi⊆TFPjTHEN/*子模式*/
(10)TFPSet=TFPSet-TFPi
(11)ELSEIFTFPi⊄TFPj&TFPj⊄TFPi&TFPi∩TFPj≠ΦTHEN/*交差模式*/

(20)ENDIF
(21)IFTFP_counti=Filter_TFPSetTHEN/*将非冗余模式并入Filter_TFPSet*/
(22)Filter_TFPSet=Filter_TFPSet∪TFPi
(23)TFPSet=TFPSet-TFPi
(24)ENDIF
(25)ENDFOR
(26)ENDFOR
/*文本特征选择*/
(27)n=|TDcor| /*关联文档数目*/
(28)WSet_Filter_TFPSet=w|w∈TFP,TFP∈Filter_TFPSet/*文本频繁模式过滤集合词集*/
(29)Emb_TDcorw=Td|Td∈TDcor,w∈Td/*嵌入式关联文档*/
(30)Emb_TDuncorw=Td|Td∈TDuncor,w∈Td/*嵌入式非关联文档*/
(31)FOREACHwINWSet_Filter_TFPSetDO
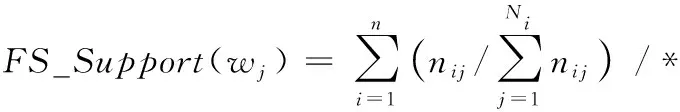
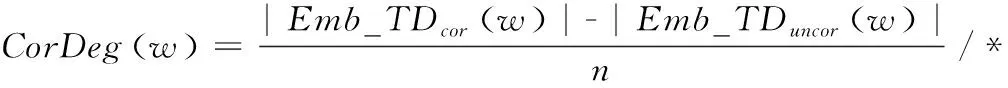
(34)ENDFOR
(35)CorFW+=w∈WSetCorDeg(w)≥δ/*词语类别划分*/
(36)GenFW0=w∈WSetCorDeg(w)<δ/*词语类别划分*/
(37)FOREACHwINw∈CorFW+DO/*关联特征词语加权*/
(38)Weightw=FS_Supportw*1+CorDegw
(39)ENDFOR
(40)FOREACHwINGenFW0DO/*普通特征词语加权*/
(41)Weightw=FS_Supportw
(42)ENDFOR
(43)RETURNFilter_TFPSet,Weightw

分类性能评价指标为准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1-Measure),及各自对应的宏平均值。
硬件环境: CPU 3.40Hz;内存4G。软件环境: 操作系统 Windows7 32位;开发环境 Eclipse JDK 1.6,Pydev 3.9;开发语言 Python 2.7。
3.1 数据集
数据集选取公共语料库Reuters-21578: Acq(2 369篇),Crude(578篇),Earn(3 964篇),Grain(1 102篇),Interest(478篇),Money(717篇),Ship(286篇),Trade(486篇)。其中,训练样本与测试样本比例为7∶3。
3.2 实验结果
3.2.1 参数分析
为验证冗余文本频繁模式过滤方法有效性,令相似度阈值θ在最小支持度min_sup取不同值,得到非冗余频繁模式数量占模式总数的比重,如图2所示。可知θ取值不同,文本频繁模式过滤集合中模式数量在模式总数中占比均有明显下降,证明冗余模式过滤对提升频繁模式挖掘效率具有重要作用。为保证频繁模式尽可能多地保留与文档关联的信息,将min_sup设为较小值。由于FP-Growth算法和TFSIDFP方法复杂度较低,min_sup较小并不会明显提升时间复杂度。随着θ设置增高,文本频繁模式过滤集合中的模式数量逐渐增多。θ设置过高,会保留大量冗余频繁模式;θ设置过低,会过滤掉过多与文档关联的频繁模式。由图2可知,当θ取值为0.7左右,频繁模式数量相对稳定。因此,设定min_sup=0.2,θ=0.7。
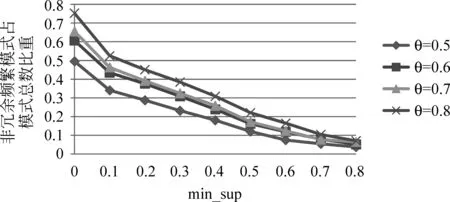
图2 非冗余频繁模式占所挖掘模式总数的比重
3.2.2 特征选择性能评价
(1) 基于信息熵的性能评价
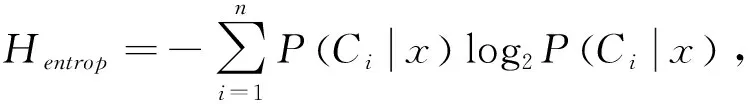
在数据集Reuters-21578中,比较基于关联度进行特征词语类别划分对特征熵值的影响。计算前kk=10,…,2 000个特征的平均熵值。如图3所示, unCor表示仅参照词语支持度进行特征选择,CorDeg表示在支持度基础上利用关联度进行词语类别划分和权重分配后进行特征选择。基于关联度划分特征词语后,关联特征词语CorFW+相对该类的关联度加强,对类别区分力增强,错误率下降,对应熵值降低。由图3可知,前200个特征主要为关联特征,其对应熵值的平均值明显低于未使用关联度函数的特征;随着特征数目增加,普通特征数目增多,其取值差异较小,无法有效区分类别,平均熵值逐渐增大。因此,在所选特征数目有限的条件下,基于关联度进行特征选择,对类别划分更有效。
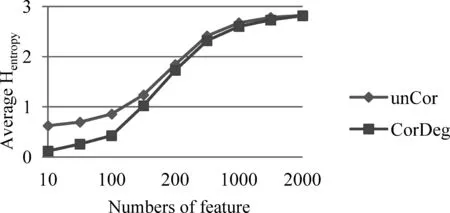
图3 基于信息熵的特征选择方法性能对比
(2) 基于关联度的特征词语分类模型性能评价
在数据集Reuters-21578中,将基于关联度的特征词语分类模型在分类器SVM上进行验证,如图4所示。由图可知,关联特征词语CorFW+和普通特征词语GenFW0同时使用可以明显提升分类精度。相较CorFW+∪GenFW0而言,仅将CorFW+用于分类效果欠佳,原因在于CorFW+对所属类别区分性较好, 却不足以完整描述该文档, 需要
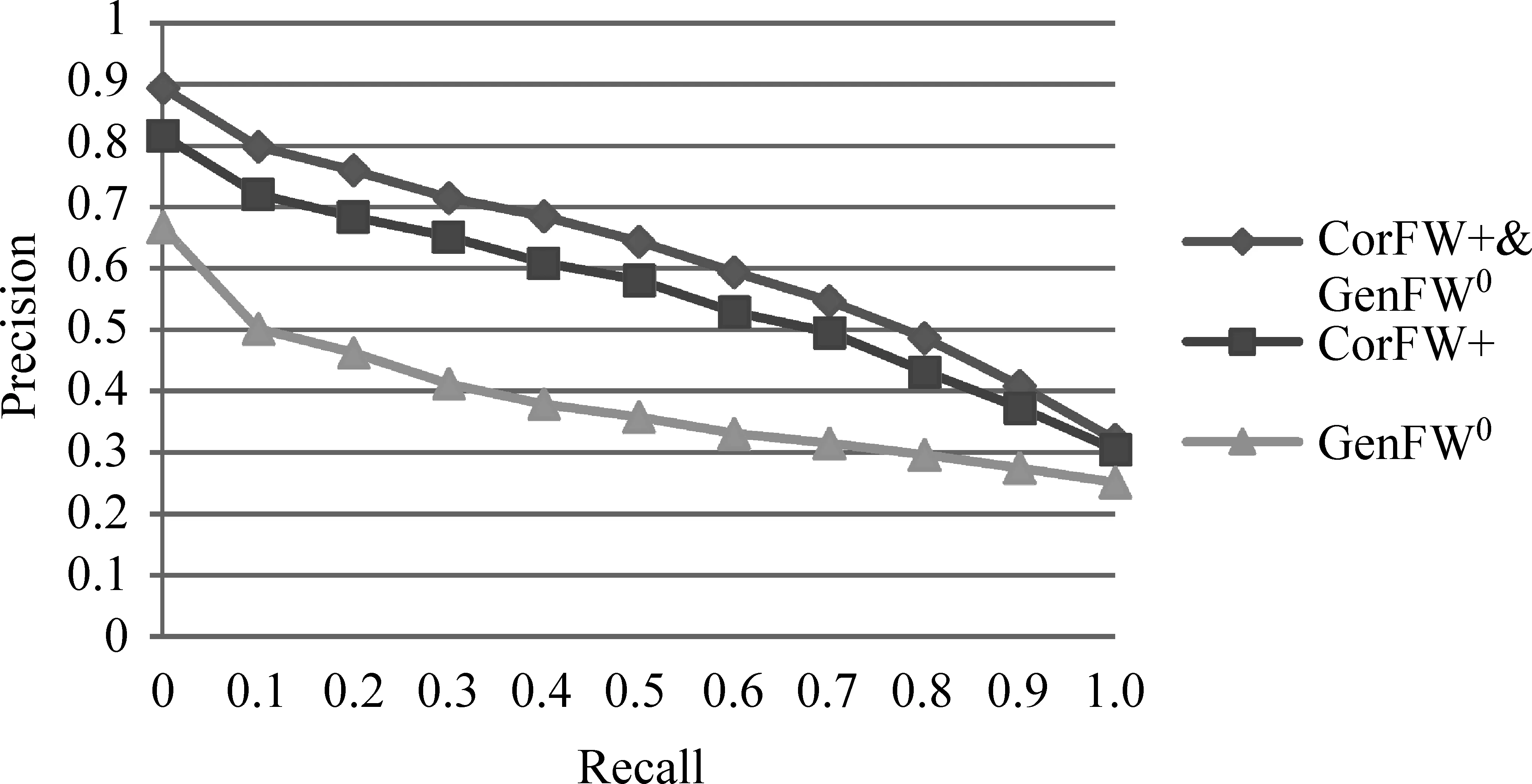
图4 SVM分类器采用不同特征词语的分类PR曲线
加入GenFW0来辅助分类;若仅用GenFW0,分类精度将大幅降低,这是由于GenFW0频繁出现在关联和非关联文档中,无法有效划定文档类别。
3.2.3 与经典特征选择方法的比较

表2 Reuters-21578数据集中精确率、召回率和F1值对比

续表
3.2.4 与新方法的比较
(1) 与新特征选择方法的比较
Filter和Wrapper是两种主流的特征选择模式。基于Filter模式的特征选择方法基于原始数据评价特征性能,无需考虑具体分类器;与之不同,Wrapper模式的特征选择方法依托具体分类器的分类性能对特征进行评价。
① 与Filter类型的特征选择方法的比较
Y Gao等[6]在信息过滤领域提出基于最大匹配模式的主题模型MPBTM,其中使用了Filter类型的特征选择方法。MPBTM模型使用模式表示各主题。这些模式依据统计和分类特性从主题模型中生成并组织,然后再选出最具代表性和区分力的最大匹配特征来判定文档与用户信息间的关联性,以此过滤不相关文档,提高文本分类性能。TFSIDFP方法与MPBTM模型对比如图5(a)所示,可知TFSIDFP性能优于MPBTM。
为进一步验证TFSIDFP方法性能,使用McNemar[18]统计测试对TFSIDFP方法与MPBTM模型做统计显著性检验。分类器选用SVM、KNN(k=1)和NB(Naïve Bayes),显著性水平设定为0.05。为获得稳定结果,每个算法均运行10次,验证结果如表3所示。其中,“Win”表示TFSIDFP性能明显优于MPBTM;“Lose”表示TFSIDFP比MPBTM性能明显较差;“Tie”表示二者性能没有明显差别。由表可知,TFSIDFP性能优于MPBTM。

表3 TFSIDFP方法与MPBTM模型的统计显著性检验结果
② 与Wrapper类型的特征选择方法的比较

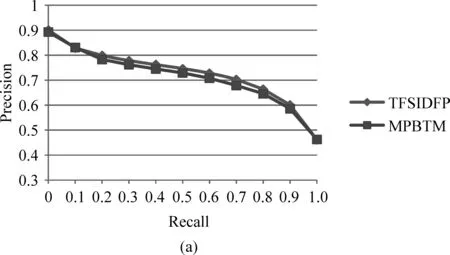
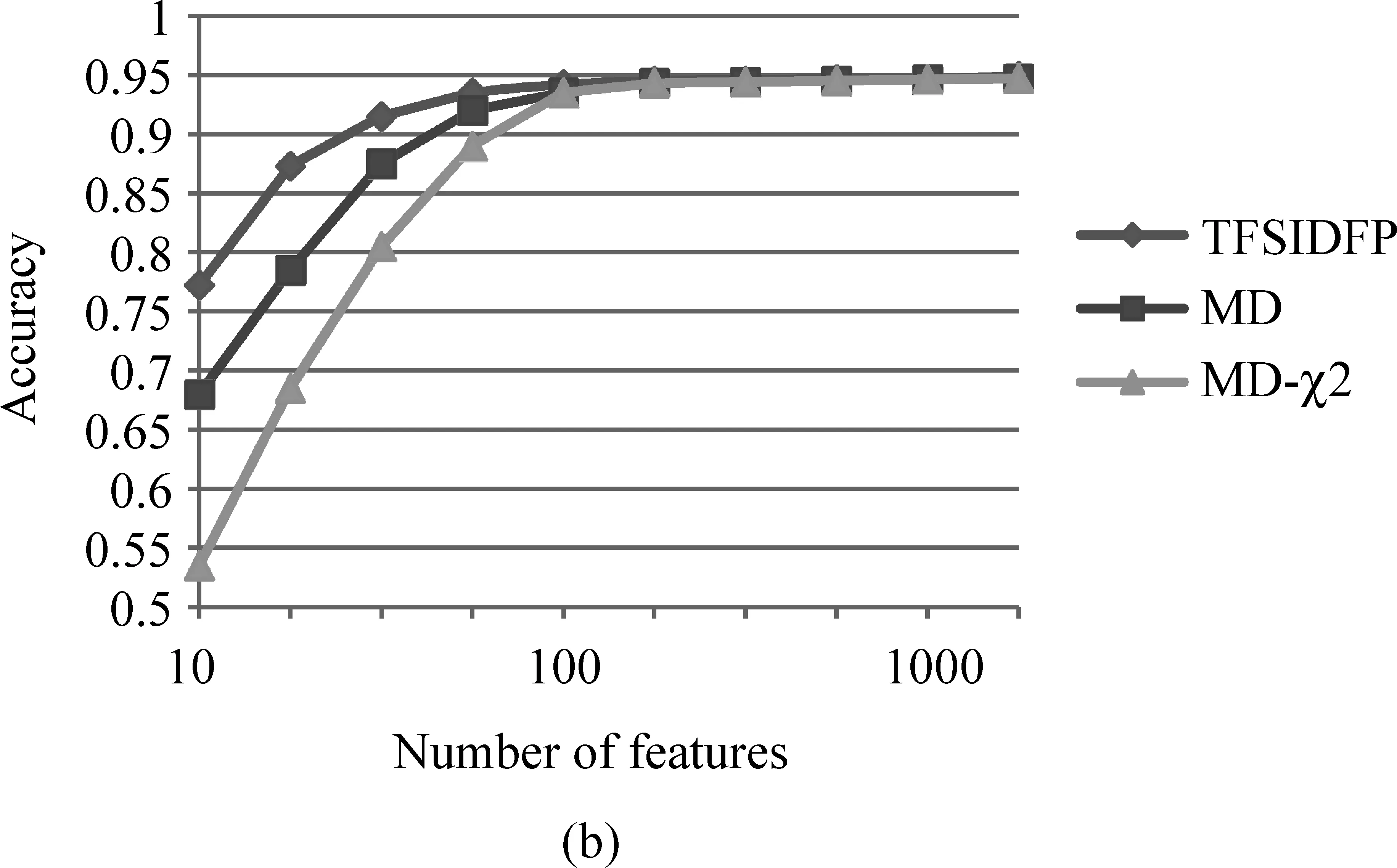
图5 TFSIDFP算法与新特征选择方法的比较((a)与Filter模式的特征选择方法MPBTM的性能比较;(b)与Wrapper模式的特征选择方法MD和MD-的性能比较)
(2) 与新特征抽取方法的比较
作为文本挖掘领域两种典型的特征选取方式,特征选择(Features selection)和特征抽取(Features extraction)均能有效地降低特征空间维数。特征选择是从D个特征中选出使准则函数最优的dd M Khabbaz等[20]提出一种基于软聚类和信息增益特征约简的特征抽取方法Cluster BOW-Inforgain。首先,软聚类方法使用模糊C均值将每一个词语依据不同组内关联度划分至多个聚类中,将每个聚类作为一个特征;然后利用信息增益进行特征约简。这样在传统词袋基础上,每篇文档被表示成一个经过软聚类及信息增益特征约简的特征向量。将TFSIDFP方法用于SVM分类器,与Cluster BOW-Inforgain方法的对比结果如图6所示。由图可知,当所选特征数目有限时,TFSIDFP方法性能优于Cluster BOW-Inforgain。这是由于特征提取是将所有词语进行转换从而降低维度,词语数目并未发生巨大缩减,Cluster BOW-Inforgain方法每个聚类特征中均包含多个词语,因此分类需要的词语数目巨大。同时,由于TFSIDFP方法增大了关联特征词语强度,能有效提升分类精度。数据维度过高会增加系统开销,因此若能利用少量特征得到较高的分类精度,可明显提高分类性能和效率。因此当所选特征数目受限时,TFSIDFP方法性能明显优于Cluster BOW-Inforgain。 图6 TFSIDFP方法与新特征抽取方法Cluster BOW-Inforgain的性能对比 在文本数据量呈爆炸式增长的大数据时代,进行文本特征选择可快速并准确提取文本主题信息,提升文本分类精度。传统基于词语的文本特征选择方法被噪声问题影响,导致分类精度受到制约。提出基于包含度和频繁模式的文本特征选择方法。首先,定义基于包含度的相似性度量原理;然后,提出基于包含度的冗余文本频繁模式过滤方法;最后,提出基于关联度的文本特征选择方法。该方法基于包含度原理度量文本频繁模式间相似性,去除冗余模式,提升文本频繁模式挖掘性能;基于冗余去噪后的非冗余模式选择文本特征,并利用特征与文档的关联度进行特征类别划分与权重分配,所选特征与文档关联度更强,对分类贡献度更大。该方法与传统基于词语文本特征选择方法相比,可以利用文本频繁模式中词语间关联性,很好地解决基于词语方法因无法有效克服噪声问题而导致的分类性能下降问题。对解决大数据时代的“数据爆炸”问题具有重要影响。此外,在进行特征选择时,还未深入考虑冗余特征词语对文本分类性能的影响,以后将深入研究特征词语去冗余方法,进一步提升文本特征选择质量及分类精度。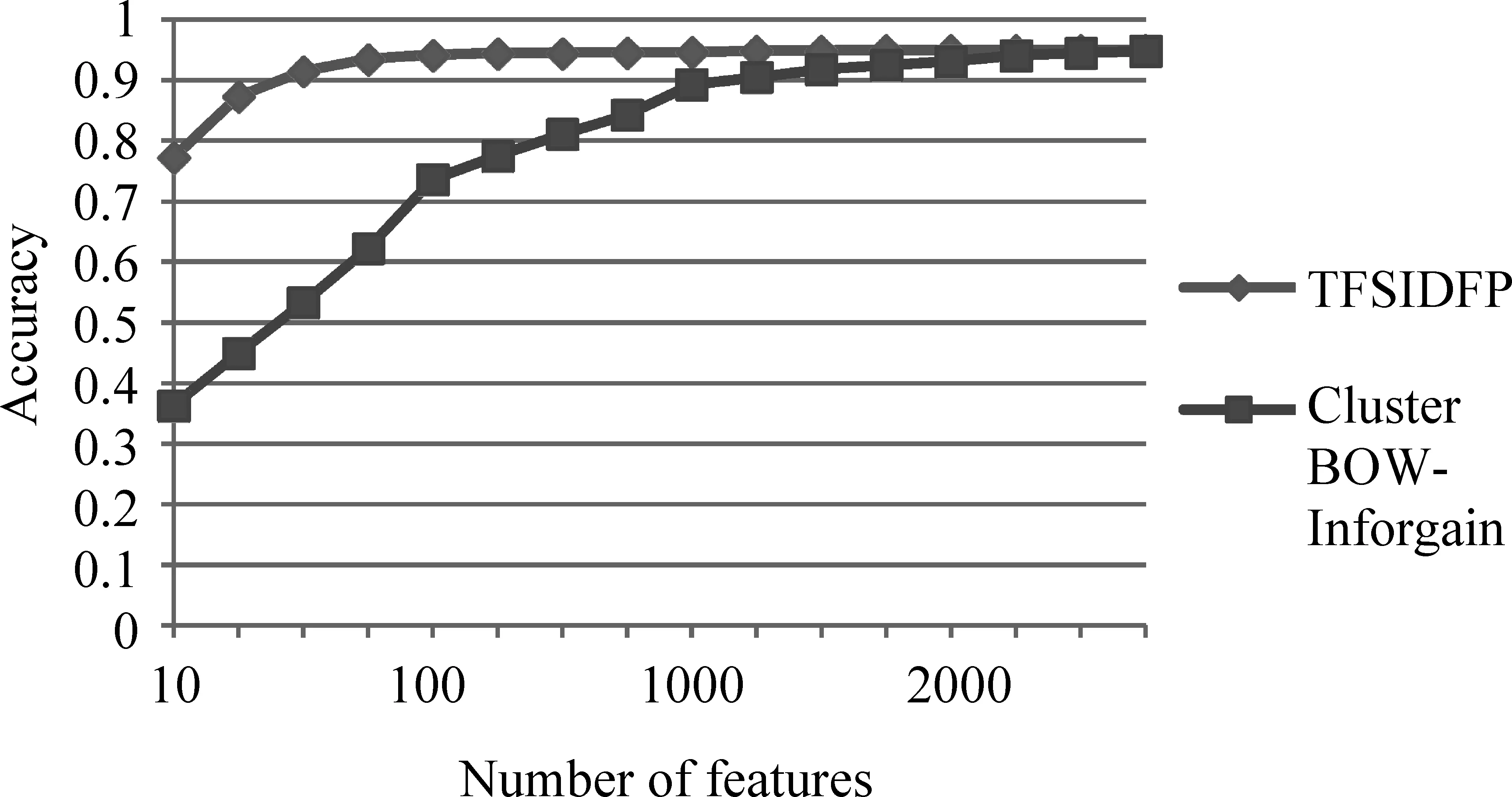
4 总结
