神经机器翻译中数据泛化与短语生成方法研究
2018-09-18韩雅倩朱靖波
李 强,韩雅倩,肖 桐,2,朱靖波,2
(1. 东北大学 自然语言处理实验室,辽宁 沈阳 110000; 2. 沈阳雅译网络技术有限公司,辽宁 沈阳 110000)
0 引言
近年来,由于神经机器翻译(neural machine translation, NMT)相关方法取得了极大突破,神经机器翻译在很多语言对间的翻译任务上都取得了极佳的翻译效果[1-4]。给定源语言句子,神经机器翻译可以直接对翻译至目标语言句子的最大条件概率进行端到端建模[5]。目前,最常使用的神经机器翻译模型是基于循环神经网络(recurrent neural network, RNN)的编码器—解码器(encoder-decoder)架构的模型[1]。在这一架构中,通过基于循环神经网络的编码器将源语言句子压缩到一个固定维度的向量中,继而一个基于循环神经网络的解码器将这一固定维度的向量解码至目标语言翻译结果。通过对门阀(gating)[1-2,6]和注意力(attention)[3-4]机制的探索,神经机器翻译模型在多种翻译任务上的翻译性能超过了传统的统计机器翻译(statistical machine translation, SMT)模型[4,7-9]。由于神经机器翻译模型主要以标准的词汇为基础构建翻译模型,对数据的使用没有进行充分的挖掘,因此,在本文中,我们对神经机器翻译中的数据处理方法进行更为深入的研究,包括对数据泛化方法以及短语生成方法的研究。
首先,我们将数据泛化方法引入神经机器翻译中。由于神经机器翻译中解码器端需要在整个目标语言词汇表上进行概率计算,因此当词汇表较大时(>200KB),训练几乎无法正常完成。因此在训练标准的神经机器翻译模型时,需要对词汇表的规模进行限制[1-2]。无法被建模的稀疏词汇被称之为未登录词(out of vocabulary, OOV),在模型训练的过程中,所有的未登录词都被替换为特殊标签UNK。针对未登录词问题,其中一种解决方案是,翻译完成后根据注意力模型中的词对齐为目标语言翻译结果中的UNK找到对应的源语言词汇,最终根据一个词汇翻译表将源语言词汇翻译至目标语词汇并嵌入到翻译结果中[10];另外一种方法是对源语言和目标语言数据中的词汇通过子词压缩的方法,将所有的词汇映射到有限规模的子词上[11]。子词方法目前得到了大范围的推广和应用,基本上所有的在线翻译系统和相关的评测系统中均应用了这一压缩技术。然而,这种子词方法产生的副作用是造成错译问题。为了解决子词方法中出现的这一问题,本文通过对数字、时间、日期、人名、地名、组织机构名等这些稀疏的词语进行识别、泛化以及翻译,有效地提高了子词方法的性能。
继而,我们将短语知识引入端到端的神经机器翻译模型中。在基于统计的机器翻译系统中,基于短语的机器翻译模型[12-16]翻译性能明显优于基于词的翻译模型[17]的翻译性能,这说明短语在翻译建模的过程中起到了非常重要的作用。受到这一方法的启发,本文在子词和数据泛化方法的基础上,同时研究将短语知识融合到神经机器翻译模型中,最终对原始语料进行了更为充分地利用。本文提出的短语生成算法建立在子词算法的基础上,以达到生成可控规模的短语的目的,将生成的短语内嵌到神经机器翻译模型后,进一步提高了神经机器翻译模型的翻译质量。
本文对神经机器翻译中的数据泛化和短语生成方法进行研究。之所以同时对这两种方法进行研究,主要原因为以下四点:
(1) 本文提出的两种优化方法均是在神经机器翻译模型的数据层面进行处理,即可以归纳为数据预处理中的一些方法研究。
(2) 这两种方法在统计机器翻译中得到广泛应用,如何将这些方法引入到神经机器翻译中还鲜有讨论。
(3) 本文的两种方法均针对子词方法进行讨论,数据泛化方法主要是为了缓解子词方法中出现的错译问题,短语生成则是以子词算法为基础进行的。
(4) 这两种方法同时对数据进行处理,在分别取得不错效果的同时,同时使用这两种方法可以进一步提高翻译模型的翻译质量。
本文提出的两种数据处理方法以子词方法为基础,主要的贡献点如下:
(1) 通过使用数据泛化方法,在解决子词方法中出现的错译问题的基础上进一步缓解了数据稀疏问题。
(2) 在子词和泛化方法的基础上,本文将短语引入到标准的神经机器翻译模型中,进一步获得了翻译效果的提升。
(3) 在汉英和英汉翻译任务上,本文提出方法的翻译质量与基线翻译系统相比分别提高了1.3至1.2个BLEU值。
1 相关工作
首先,在神经机器翻译模型中缓解未登录词问题,已经有了较多的相关工作。Luong等人[10]提出了一种简单的根据注意力模型生成词对齐进行未登录词替换的方法,该方法有效缓解了神经机器翻译模型中出现未登录词问题。Jean等人[18]提出了一种基于重要性采样的方法来解决目标语词表受限的问题。其方法在训练的过程中,在不明显降低训练速度的基础上,可以使用非常大的目标语言词表进行训练。在解码的过程中,为了加速解码,其通过选取整个目标语词表上的一个子集进行解码。Arthur等人[19]通过在神经机器翻译模型中引入外部词汇来解决翻译过程中的数据稀疏问题。Sennrich等人[11]通过使用子词的方法,将非常大的目标语言词表压缩在一个有限的词汇表上,取得了不错的效果,该方法是目前神经机器翻译中最常用的方法之一。
继而,在将短语加入神经机器翻译模型中进行建模的工作中,Stahlberg等人[20]提出了句法结构指导的神经机器翻译,该方法通过简单地对神经机器翻译模型中定向搜索解码算法进行修改,将层次短语规则引入神经机器翻译模型中,取得了不错的翻译效果。Tang等人[21]通过在神经机器翻译中引入短语记忆模块(phrase memory)将外部的短语存储到神经机器翻译模型中,在翻译过程中对候选的翻译片段使用短语记忆模块进行检测,提高了翻译模型的翻译质量。Huang等人[8]通过使用Sleep-Wake(SWAN)网络在神经机器翻译模型的输出序列中对短语进行建模并取得了不错的效果。
与这些工作不同的是,本文提出的方法建立在原始的双语平行数据的基础上,在数据中进行泛化处理和短语生成,因此本文提出的方法是语料驱动的方法。此外,本文方法可以直接应用到任意的神经机器翻译架构中。
2 神经机器翻译
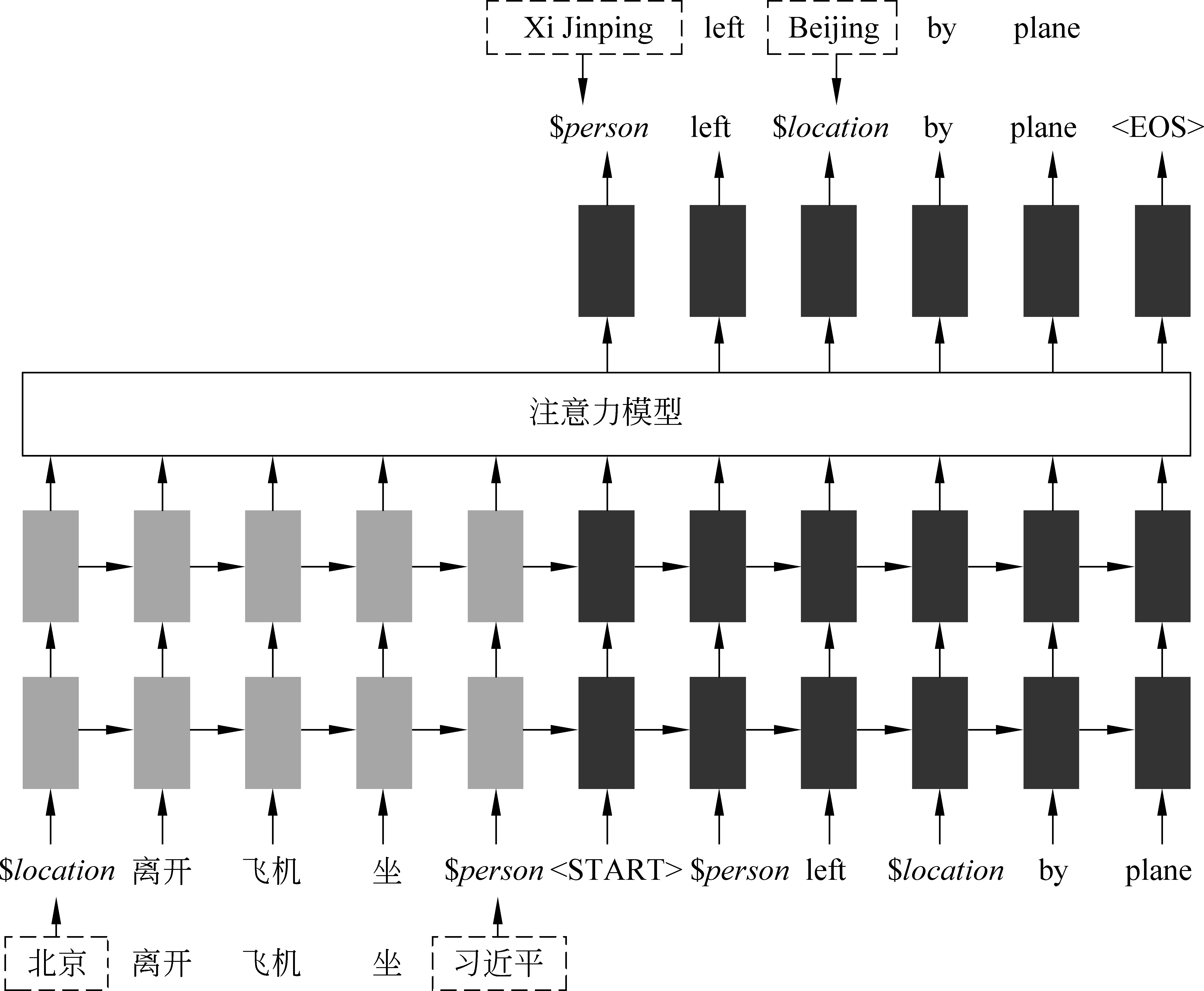
本文的工作中,我们使用基于注意力机制的编码器—解码器结构的神经机器翻译模型[1,4]。基于注意力机制的神经机器翻译模型在翻译推导的过程中,动态地生成词对齐和目标语言的翻译结果。图1 是一个标准的基于注意力模型的神经机器翻译框架。

图1 基于注意力机制的神经机器翻译架构
给定源语言句子x=x1,...,xn和目标语言句子y=y1,...,ym,基于注意力模型的神经机器翻译系统通过使用循环神经网络直接对条件概率py|x进行建模,具体如式(1)所示。
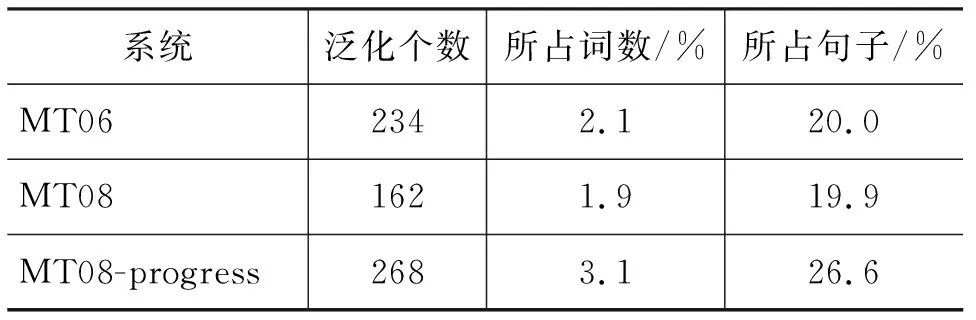
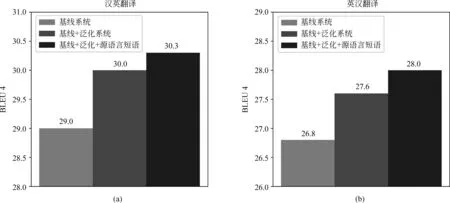
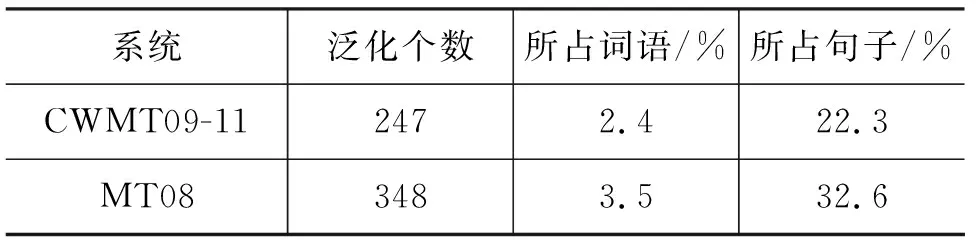
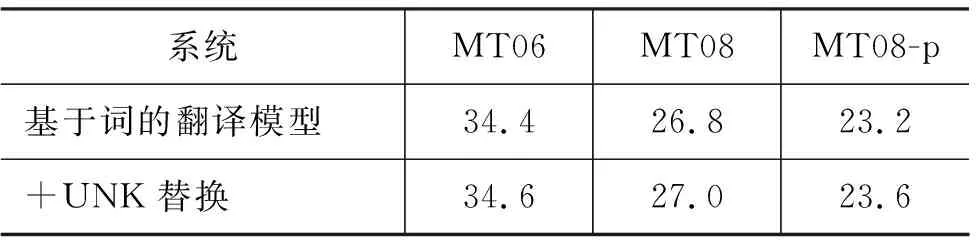
在这里,sx为源语言句子x的固定维度的向量表示。n和m分别是源语言句子和目标语言句子的长度,t是时间戳。为了计算pyt|y 最终,训练目标如式(4)所示。 在这里,D是平行训练数据,最终的学习的目的是找到最优的参数空间θ*。 子词生成算法[11]是神经机器翻译中解决稀疏词汇和未登录词汇的一种常用的方法,该方法将整个词汇表压缩在有限规模子词之中。关于子词方法的训练和使用算法,请参考文献[11]。在神经机器翻译模型训练之前,先对平行训练数据进行子词切分操作,一般源语言和目标语言的词表大小压缩至3~5万词左右。基于子词的数据处理方法有效地将大规模词表压缩在有限规模的子词词表上,可以使神经机器翻译模型对所有词汇进行建模,因此表现出不错的翻译效果。在汉语中使用基于子词的方法,是将汉语中的字的概念与英文中的字母等同对体。然而,由于子词方法将整个词汇切分成片段,因此不可避免地发生错译问题。针对子词方法中出现的错译现象,本文提出了在子词方法基础上使用数据泛化方法来修复子词方法中出现的错误。 不可枚举的、不是封闭集合的词汇都是机器翻译中常见的稀疏词汇,比如数字、时间、日期、人名、地名、组织机构名等。这些稀疏词汇可以分为两类,具体如下: (1) 数字、时间、日期: 可以通过正则表达式进行双语的词汇识别,可以通过书写翻译规则自动生成对应的目标语言翻译结果。 (2) 人名、地名、组织机构名: 书写没有任何规则,识别主要依赖词典或者命名实体识别[23]的相关方法,提供翻译需要依赖词典。 在对含有这两种类型词汇的语料进行预处理后,可以将其按照表1中的规则进行替换。即在语料中源语言端和目标语言端识别出相应的词汇后,直接替换为其对应的泛化类型,具体如图2所示,“北京”和“Beijing”被替换为“$location”,“习近平”和“Xi Jinping”被替换为“$person”,神经机器翻译直接使用泛化数据进行模型训练。 表1 每种泛化类型对应的泛化标签 对于这些稀疏词汇的识别,由于无法做到源语言和目标语言中所有识别的结果都一致。为了在神经机器翻译中使用这些泛化标签,同时希望系统能够自动学习出来源语言和目标语言这种标签的对应翻译关系,则需要进行一致性检测。一致性检测的定义如下。 一致性检测: 在一个句对x,y中,源语言x中如果含有n个标签$type,那么目标语言y中必须有n个标签$type,如果不满足该条件,则不一致,需要将不一致的标签还原至原始词汇,x,y中所有标签都必须满足这一条件。 简单来说,进行一致性检测的主要目的如下: 模型训练后进行翻译的过程中,源语言x中存在n个标签$type,必须翻译至y中的n个标签$type。一致性检测仅仅应用到训练数据和校验集中,在模型训练好后,进行翻译的过程中,则不受此限制。不一致的情况在训练数据中非常常见,这是因为一般的规则无法枚举所有出现的语言现象,因此存在识别错误。如果不进行一致性检测,由于双语训练数据中可能存在大量的不对称的类型标签,因此训练好的翻译模型并不能保证译文中的类型个数与输入的类型个数相同,就会造成明显的翻译错误。本文方法在进行类型的识别和替换时,无论多长的词汇,均会被替换成一个对应的标签$type,如果双语端均对类型进行了正确的识别,则不会被一致性检测过滤掉。 在翻译推导时,输入的源语言端句子存在泛化标签,与此同时,在翻译结果中同样存在相应的泛化标签,具体如图2所示。 在图2中,正常的源语言句子为“习近平 坐 飞机 离开 北京”,在使用泛化规则后,实际输入到神经机器翻译系统中的句子为“$person坐 飞机 离开 $location”,翻译结果为“$personleft $locationby plane”。为了得到最终的翻译结果,需要经过如下两步: (1) 源语言的句子中被识别的词汇,如果是数字、时间、日期,需要通过规则自动生成对应的目标语言的翻译结果;如果是人名、地名、组织结构名,需要查询词典,找到对应的翻译结果。 (2) 在翻译结果中的泛化类型,需要根据注意力模型找到源语言中对应的泛化标签,进而根据源语言提供的泛化内容的翻译结果生成最终的翻译结果。 图2 类型替换实例 (6) 本节提出的数据泛化的的方法与子词方法相比,有如下的优缺点。 (1)优点: 只要是泛化的词汇,对应的翻译结果中的词汇的翻译是完全正确的,极大缓解了稀疏词汇在子词方法中错误翻译的问题。 (2)缺点: 与子词方法相比,覆盖度不足,像数字、时间、日期这类泛化词汇,识别准确率较高。但是像人名、地名、组织机构名这类词汇,识别内容的多少依赖于词典的精度和大小。 在本文中,我们在子词方法的基础上进行数据泛化,最终取得了不错的翻译效果。Luong等人[10]提出的UNK替换方法本质上是一种类型替换方法,与其工作的主要不同是: 首先,本文提出的方法可以对数字、时间、日期、人名、地名、组织机构名六类词汇进行识别和泛化,与此同时,本文提出的框架对于类型识别的方法不做限制,任何可以进行识别并且提供目标语言译文的方法都可以使用。而Luong等人的工作将所有类型的低频词统一作为UNK进行处理,并没有对不同的类型进行区分,可能存在源语言中的UNK是一个数字,而目标语言中的UNK是一个时间的情况;其次,本文对泛化的类型进行了一致性处理,同时解码器进行了有针对性的修改,保证翻译后译文中的泛化类型个数与输入的源语言个数相同;最后,本文方法的提出是为了解决子词算法出现的错译问题,本文实验中的基线系统使用了子词压缩算法,已经不存在UNK问题。 目前,神经机器翻译模型在本质上都是基于词的,由于词表受限,所以无法在训练的过程中直接引入大规模的短语集。然而,基于短语的统计机器翻译模型[12]的翻译质量与基于词的统计机器翻译模型[17]相比,翻译性能有大幅度提高。受到这一想法的启发,本文提出一种在神经机器翻译中引入源语言短语集的机制,最终表现出了不错的翻译效果。本文通过使用压缩算法生成短语,可以合理控制加入到翻译模型中短语的个数,故不会导致词表爆炸这一问题。与此同时,短语的元数由算法自行控制,不由人工指定,生成短语的形式更为灵活。基于压缩算法生成的短语都是高频短语,不会造成数据稀疏问题,而神经机器翻译中低频词汇会明显造成翻译质量的下降。本文提出了一种新的在神经机器翻译中引入短语知识的方法,即不需要对神经机器翻译模型本身进行修改,而是通过外部生成规模可控的短语集,实现神经机器翻译对短语的建模。 我们使用子词算法[11]进行短语的生成,基于子词算法的短语训练和使用算法如图3和图4所示。图3中短语模型训练过程如下: 图3 短语模型训练算法 (1) 算法第2行: 进行分词操作得到词串x=x1,...,xn,进而在标点的前后分别加上特殊标签“”,即进行训练时,不可以跨越标点,只在子句中完成,生成的短语都是子句的部分内容。如果在泛化数据的基础上进行短语生成,将泛化标签等同于标点处理,即短语不可以跨越泛化标签。 (2) 算法第3行: 参数i清零,模型P清空。 (3) 算法第4~9行: 如果i (4) 算法第10行: 返回短语模型P。 图4 短语模型使用算法 图4中使用短语模型进行短语生成的过程如下: (1) 算法第2行: 进行分词操作得到词串x=x1,...,xn,进而在标点的前后分别加上特殊标签“”,即进行短语生成时,不可以跨越标点,只在子句中完成,生成的短语都是子句的部分内容。如果在泛化数据的基础上进行短语生成,将泛化标签等同于标点处理,即短语不可以跨越泛化标签。 (2) 算法第3~5行: 根据短语模型P中合并操作的优先级将语料C中的xi,xi+1替换为xi_xi+1,即执行合并操作,循环执行所有存在于P中的合并操作。P中合并操作的优先级是在训练过程中输出的顺序,先输出的优先级高。 (3) 算法第6行: 返回处理后的语料C。 在进行短语生成时,首先使用图3中算法在大规模的数据上进行短语模型的训练,继而使用图4中的算法在测试数据和训练数据上进行短语的生成。至此,短语训练和使用算法介绍完毕,该算法的一个优点是: 可以通过参数k控制生成短语的规模,同时,生成的短语是n元的高频短语,不存在数据稀疏问题和词表爆炸问题。短语的元数n是算法自动控制的,不由人工指定,故较为灵活。 图5是本文提出的算法生成的短语实例,在中文中,“综合_报道”“中国_驻”“高度_重视”被识别为短语,因为这三个短语均在本文训练的中文短语模型P中。在英文中,“our_attention”“nuclear_issue”“we_believe”“equal_rights”被识别为短语,这三个短语均在本文训练的英文短语模型P中。 从这些短语可以看出,这些生成的短语基本符合人们对短语的认知。将生成的源语言短语内嵌到神经机器翻译模型中,原始的词到词的神经机器翻译模型转换为短语与词混合到词的翻译模型。由于我们使用“_”将连续的多个词汇拼接为一个短语,而这个语义上的短语在模型中可以看成是一个词汇,因此,我们没有对神经机器翻译框架进行修改,模型的训练方法和解码方法与标准的神经机器翻译模型相同。 在汉英和英汉翻译的实验中,我们的训练数据为2.85MB平行句对,该句对从NIST MT 2008评测数据中的NIST部分选取出来。在训练数据中随机选取2 492个平行句对作为校验集,并从训练数据中将这些数据移除。关于数据更为详细的信息如表2所示。在汉英翻译中,我们使用NIST 2006,NIST 2008,NIST 2008 progress作为我们的测试数据。在英汉翻译中,我们将CWMT2009和CWMT2011英汉测试集合并得到CWMT09-11,使用CWMT09-11和NIST 2008作为测试数据。所有测试数据均含有4个参考答案。 表2 汉英和英汉翻译中,训练和校验数据的统计情况 本文的主要对比系统描述如下: 5.2.1 基线系统 本文使用的基线神经机器翻译系统为两层的基于注意力机制的编码器—解码器结构的神经机器翻译系统[1,4],在该系统中,使用局部注意力模型和反馈—输入(feed-input)模型[4]。该基于长短期记忆[22]的神经机器翻译系统通过使用基于时刻的反向传播算法[24]以极大似然估计为目标进行模型的训练。对于编码器和解码器,隐藏状态和节点状态的向量大小均为1 024,同时源语言词汇和目标语言词汇的词向量大小为1 024。使用子词算法对源语言和目标语言词表进行压缩,最终源语言词表和目标语言词表大小为50KB。我们使用批量训练的方法,批量的大小设置为80,句子最大长度设置为20个词汇。我们将梯度裁剪为5.0。所有参数通过使用正态分数初始化在[-0.08,0.08]这个区间中。使用随机梯度下降算法在整个训练数据上训练10轮,初始的学习率为0.7,在5轮后每一轮减小一半。丢弃率设置为0.2[6]。与Sutskever等人的实验设置一样,输入到编码器的源语言句子进行反向处理。 5.2.2 基线+泛化系统 主要设置和基线系统相同。首先对数据进行泛化处理,进而进行子词模型的训练和进行子词切分操作,源语言和目标语言词表的大小设置为50KB。 5.2.3 基线+泛化+源语言短语 主要设置与基线+泛化系统相同。在源语言端使用本文提出的短语生成方法生成短语,短语生成的合并操作k=10K,短语的频次大于200次。汉英和英汉翻译系统中实际加入的高频源语言短语个数分别为2 567个和2 801个。这里我们仅将生成的短语加入到翻译模型的源语言端,源语言词表的增长并不会影响翻译系统的训练速度和解码速度。 表3是汉英翻译任务上,本文方法与基线系统的性能对比。首先,在三个测试数据上,使用泛化的系统的翻译结果与基线系统相比,性能提高的幅度为0.3~2.2个BLEU点。泛化方法和子词方法相比,虽然同是解决了数据稀疏问题,但是侧重点不同,子词方法对所有词汇同时适用,但是不能保证翻译结果的正确性[11];而泛化方法虽然对稀疏词汇的覆盖度有限,但是可以保证翻译结果的正确性。与基线系统相比,泛化方法在MT08 progress获得了2.2个BLEU值的上升,主要是因为在该测试集上,泛化类型的个数更多,因此起到了较为明显的作用。 表3 汉英翻译任务上,本文方法与基线系统的性能对比 *表示在p<0.05情况下,显著好于基线系统的结果 不同测试集上泛化词汇所占的比例统计如表4所示。在MT08 progress测试集中,泛化词汇占整个语料词汇数的3.1%,在26.6%的句子中都出现了可以泛化的数据,使用泛化标签很好地纠正了子词方法中产生的错误,因此获得更好的翻译结果。 表4 汉英翻译任务上,不同测试集上的泛化类型统计 图6是汉英翻译任务上,基于子词的方法与泛化的方法对比的两个翻译实例。在第一个例子中,源语言输入句子中的词汇“525亿”由于是一个稀疏词汇,因此基于子词的方法将其切分为“5@@ 25亿”,在最终的翻译结果中,没有被准确地翻译出来,而是翻译为“5 billion”,造成了错误。在本文提出的使用泛化的方法中,源语言的“525亿”被识别为“$number”,通过规则可以书写出其对应的翻译结果为“52.5 billion”,最终翻译结果中出现的$number使用“52.5 billion”进行替换,最终获得了正确的翻译结果。在第二个翻译实例中,源语言中的日期“2005-6-23”通过子词的方法被切分为“200@@ 5-@@ 6-@@ 23”,源语言中的时间“19:16”被切分为“19:@@ 16”,最终子词方法错误地将时间和日期翻译为没有意义的结果“300 - 23 - 23 - 23 - 23”。在本文提出的泛化方法中,首先日期“2005-6-23”被识别为“$date”,时间“19:16”被识别为“$time”,通过对其进行判断,发现其自身就是其对应的翻译结果,在翻译结果生成时,直接将翻译结果中的$date使用“2005-6-23”进行替换,“$time”使用“19:16”进行替换即可。通过这两个实例可以看出,子词方法虽然将稀疏的词汇切分成高频的子词,仍有很大可能发生翻译错误。而数据泛化的方法却总能获得准确的翻译结果。 图6 汉英翻译任务上子词方法与泛化方法结果对比 在汉英翻译任务上,在子词和泛化方法的基础上,加入本文提出的短语生成技术,与基线系统相比,最终提高的翻译性能为0.5~2.6个BLEU值。 图7是汉英翻译任务上,使用短语和没有使用短语的翻译结果的对比情况。 图7 短语系统与无短语系统结果对比 从第一个翻译实例可以看出,当没有使用短语时,翻译结果中没有对源语言句子中的“大家”和“机遇”进行正确的翻译。而当使用短语方法时,“这_也_是”和“一_次”都被识别为短语,输入句子的长度从19减小至14,从而间接地影响到整个句子的翻译,翻译模型将“大家”正确地翻译为“members”,将“机遇”正确地翻译为“opportunity”。在第二个翻译实例中,无短语输入的系统将源语言句子中的“不 是”错误地翻译为“can’t”,而在短语系统中识别为“不_是”,作为一个短语,其被正确的翻译为“have to”。从这两个翻译实例中可以看出短语在神经机器翻译模型中起到了正确的导向作用。在基线系统的基础上使用泛化和源语言短语在所有测试数据上的平均BLEU值增长如图8(a)所示。与基线系统相比,加入泛化后BLEU值平均增长1.0个点,加入源语言短语后BLEU值平均增长1.3个点。 图8 汉英和英汉翻译任务上,不同翻译系统的平均BLEU值 表5是英汉翻译任务上,本文方法与基线系统的性能对比,具体的性能表现与汉英翻译任务上类似。在英汉翻译任务上,首先,在两个数据集上,在子词方法的基础上,通过使用数据泛化的方法,与基线系统相比,性能提高的幅度为0.6~0.9个BLEU值。 表5 英汉翻译任务上,本文方法与基线系统的性能对比。 *表示在p<0.05情况下,显著好于基线系统的结果 表6中,CWMT09-11测试集上22.3%的句子出现了泛化标签,MT08中32.6%的句子出现了泛化标签,因此在这两个数据集上都获得了较为明显的性能提升。 最后在子词和泛化方法的基础上,加入本文提出的短语生成技术,与基线翻译系统相比,在两个数据集上性能的提高幅度均为1.2个BLEU值。最终, 表6 英汉翻译任务上,不同测试集上的泛化类型统计 在基线系统的基础上使用泛化和源语言短语在所有测试数据上的平均BLEU值增长如图8(b)所示。与基线系统相比,加入泛化后BLEU值平均增长0.8个点,加入源语言短语后BLEU值平均增长1.2个点。 在本文的数据集上,完全基于词的神经机器翻译模型的翻译性能如表7所示。 表7汉英翻译任务上,基于词的神经机器翻译模型与进行UNK替换方法的性能对比情况 系统MT06MT08MT08-p基于词的翻译模型34.426.823.2 +UNK替换 34.627.023.6 与基于子词切分的基线系统相比,BLEU值在三个测试集上分别低1.4、0.9和0.4个点。通过使用Luong等人[10]提出的UNK替换方法,在三个测试集上可以平均提高0.3个BLEU值左右。而在图8(a)的汉英翻译任务上,本文提出的泛化方法与基线系统相比平均提高了1.0个BLEU值。因此,Luong等人的方法在性能增长幅度上与本文方法相比有一定差距,进一步证明了本文提出的数据泛化方法的有效性。 表8是本文第三节提出的方法中,不同泛化类型在神经机器翻译中的翻译准确率。在该统计中,针对不同的泛化类型,我们各选取了3 000个含有不同泛化标签的句子进行翻译,继而统计目标语言翻译结果中是否出现相同个数的标签,具体结果如表8所示。从表8中可以看出,本文提出的将泛化类型引入到神经机器翻译模型的方法非常有效,泛化类型翻译准确率非常高,除出现频次最低的$organization类型外,其他结果的翻译正确率均在95%以上。 表8 汉英翻译任务上,不同泛化类型翻译的准确率 在本文中,我们对神经机器翻译中数据处理方法进行了较为详细的研究,主要包括数据泛化方法和短语生成方法。为了缓解子词方法在未登录词和低频词翻译时出现的错译问题,我们提出了泛化数据结合子词方法的技术。在将泛化数据引入神经机器翻译中时,我们提出了一致性检测和解码优化的方法。在将短语引入到神经机器翻译模型中,我们提出了基于数据压缩算法的短语生成方法。最终实验结果证实,通过使用本文提出的方法,在汉英和英汉翻译任务上比基线系统分别提高了1.3和1.2个BLEU值。 未来,我们还将对神经机器翻译中同时引入源语言和目标语言短语进行研究。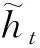

3 数据泛化方法
3.1 数据泛化类型
3.2 一致性检测
3.3 翻译推导
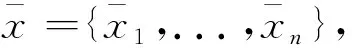

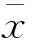


4 短语生成方法


5 实验结果
5.1 数据

5.2 实验设置
5.3 翻译性能




5.4 翻译类型准确率

6 总结与展望
