基于数据挖掘的仓库智能存储策略研究
2018-09-18文康龙孔凡超
文康龙,孔凡超
(1.成都赛普瑞兴科技有限公司,四川成都,610091;2.中石油西南油气田分公司川中油气矿龙岗采油气作业区,四川南充,637676)
引言
高效的仓储管理对于企业的供应链来说至关重要,仓储可以看做是将上游供应商和下游客户连接在一起的中介。为了提高公司的竞争力,大部分的注意力都放在了生产和销售上,而仓储管理也同样重要,有效的仓储操作大大减少了订单运行中距离的选择,在最短时间内将产品交付给顾客,也大幅度的降低了成本。
在仓储管理中,根据订单进行产品挑选时自动化最密集的操作,一些研究表明,订单的取货成本可以占到总仓储运营成本的 55%以上。因此订单的挑选过程可以优化,同时分配产品到正确的存储位置也对订单挑选时间有很大的影响。在有关仓库存储策略的文献中,最常用的位置分配策略是:最近空位法和固定分类法。最近空位即将产品放置在里输入/输出口最近的空位上,这种策略在大多数的情况下减少了放置时的运行距离。在固定分类中,每一个产品都被放置在预先分配好的固定位置,就算产品缺货位置依然会被保留,这种方法的优势在于,订单采购者熟悉每一个产品的位置,他们可以用更少的时间来定位产品。
最近空位法和固定分类法是仓库存储策略的两个极端,现有的的研究表明,在仓库使用率较低时,最近空位法效率更高,而在仓库利用率高的时候,固定分类法的表现更加好。
1 仓储模型建立
模型是一个零部件的仓库,仓库的布局如图1所示,仓库有M个垂直的储物架,每个架子都有M个位置,在架子的两边有相同的间隔,架子上每个选择位置只能存放一种产品,在仓库最左边的角落是产品的进出口,在货架的两端都有通道,进货和出货的操作都是通过操作运货卡车完成的。
为了最大限度的减少对产品放置和订购时的总运行距离,提出针对存储位置的分配算法,来确定存储产品的位置,以便将相关的产品放在相近的位置,一个完整的仓储过程如下:当一个客户的订单发送到仓库,上面所需求的产品和数量会被列在一个订单列表中,订单挑选系统会根据系统生成的选择路径从货架上收集商品,然后挑选用的卡车返回产品输送口,当产品的库存数量不足以满足订单的要求,或者少于预定的标准时,就需要重新制定订单来补充货物,一旦接受到订单,产品会根据仓储策略系统将产品放置到制定的位置。
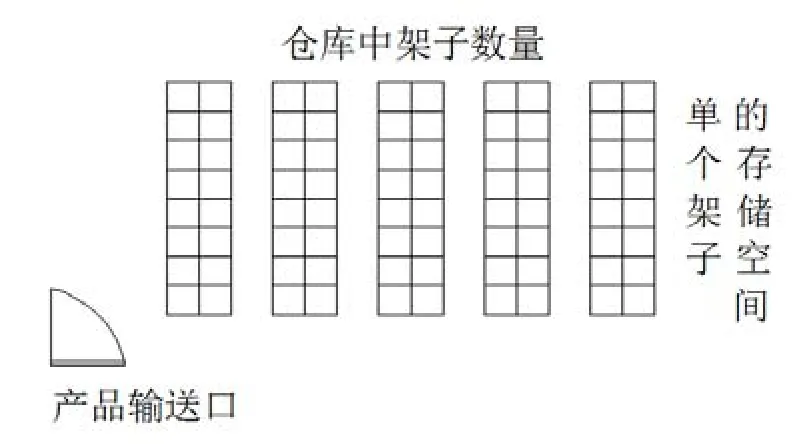
图1 仓库模型图
将仓库存储位置分配问题转变成程序化语言,定义有P件产品即将放置在仓库中,还定义仓库中空余的位置为L,假设L≥P,即有充足的容量来存储即将到来的货物,产品输送口的位置定义为0,对于相邻的产品i和k,定义关联强度:Aik,由数据挖掘算法得出,表示产品之间的相关强度,用来衡量产品i和k之间的关系。为了定义产品在某一位置的适合度,定义Fij为产品i在位置j的适合度,Fij基于两个因素,第一个位置j距离产品输送口的距离,定义为dj,第二个它和周围产品的关联强度,即是否和周围的产品有很强的关联性,发现在位置j直线距离内才属于其周围的产品,定义这些相关联的位置为nj,可以得到当产品k的位置在nj内,则所有在nj内的产品与产品i的关联强度Aik的总和(注意Aik≠Aki意味着订单中有产品i就有产品k并不等于订单中有产品k就有产品i)。最后基于过去的订单记录和帕雷托法则将产品的重要程度按照ABC等级划分将其定义为Wi。
2 公式和算法
对于在位置j放置的产品i,为描述其适合度,定义α和β分别作为关联强度和运行距离的权重,适合度定义为下面的公式:
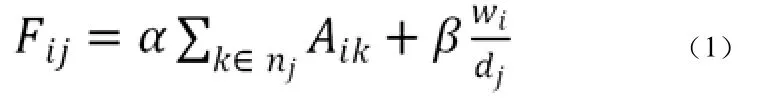
K:位置J相邻的产品;α和β分别作为关联强度和运行距离的权重
在公式(1)中Wi/dj意味着,相比于C类产品,更受欢迎的A类产品将被放在离产品输送口更加近的位置。α和β用来平衡这两个参数的效果。当α设为0时,产品将被放在离产品输送口最近的地方,相反的,当β为0时,只考虑将它放置在使它关联强度最大的位置即将它放在与它最相关的产品附近而不考虑距离。一种初始化定义α和β的方法是,确定一个特定的产品i和其Wi,当把其放在离输送口最近的位置而不考虑关联强度,和将其放在最远位置此时关联强度最大,两者的适合度是相等的。α和β的可以由以下等式计算出:
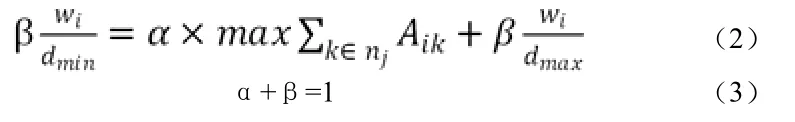
3 实验分析
交易数据和客户订单是由ARtool平台生成的,产品之间的相关性对于位置分配很重要,因为研究的重点是利用相关性的信息得到存储分配策略,而不是提取方法的效率,所以这里采用关联规则算法(The Apriori algorithm)。这种算法更加常见和高效。
3.1 实验模拟
为了模拟操作的不同规格,测试了M分别为30,40,50的仓库,仓储空间分别为1800,3200和5000,使用ARTOOL软件,指仓库大小,定库存量单位(Stock-Keeping Unit),订单数量和产品相关等等,得到了2000个客户的订单,随机抽取1000个订单作为历史记录,来进行关联规则和受欢迎程度的计算。另外1000个订单作为过程的模拟。
除了仓库大小的参数外,还考虑了库存量单位和订单中项目的数量,对于M为30和40 的仓库,考虑每个订单的数量为15。M为50的仓库则考虑到订单数量为20。
3.2 实验结果
测试三种方法:存储位置分配算法(Association Rule Based storage location assignment algorithm (ABP));最近空位(the closest open location(COL));固定分类(purely dedicated (Dedicated))。在表1显示中,在C4总距离方面,提出的ABP算法与最近空位相比,节省了很多距离,从11%到37%不等,与固定分类相比,节省的距离十分显著,从35%到61%不等,如果我们采用ABP算法,将节省很大一笔费用,特别的对于更大的仓库来说,这样的优势更加明显,而结果中SKUS的数量并没有产生很大的影响。
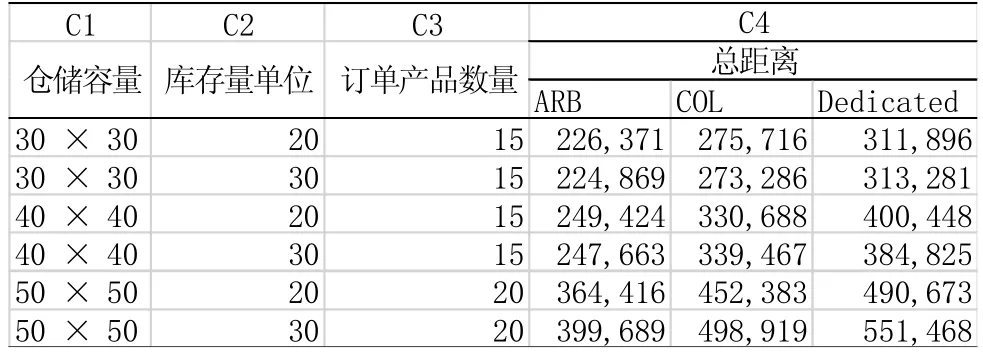
表1 仓储实验结果
4 结论
在本文中提出了一种存储分配算法,利用数据挖掘技术找到客户订单中不同产品之间的关联,从而安排这些产品在仓库中放置的位置,在不牺牲太多进购货物摆放时间的前提下,优化了挑选货物的过程,同时考虑了离输送点远近和产品之间相关联的情况。
这种方法的性能是通过测量总的运输距离来检测的,与最近空位法和固定分类法相比较,提出的方法在改善总体仓库方面效率更高,在大城市中,仓库租金高,空间利用率有限,此方法可以优化空间利用率,节省成本。
总而言之,数据挖掘是一个很有希望的领域,在信息技术变得越来越强大和廉价时,数据更加容易获得,同时,大数据将成为今后的热门话题。
[1]杜宇峰.考虑干扰风险影响下应急物流仓储量最优模型分析[J].物流技术,2014,33(1);203-205
[2]邓莉.云时代的仓储物流与“互联网+”的融合研究[J].改革与战略,2017,33(5):131-133.
[3]罗勇.供应链金融质押物仓储空间分配的鲁棒优化[J].铁道科学与工程学报,2016,13(2);394-400
[4]宋宪明.基于数据挖掘和数据仓库的用户重购行为的研究[D].山东大学, 2016.
[5]林骁尉.基于数据挖掘的货品存储分配策略研究[D].大连海事大学, 2010.
