基于用户兴趣模型的推荐算法①
2018-09-17杨红立
于 波,杨红立,冷 淼
(中国科学院大学,北京 100049)
(中国科学院 沈阳计算技术研究所,沈阳 110168)
随着互联网特别是移动互联网的飞速发展,网络上的资源呈指数级增长,网上资源严重过载[1,2].传统的搜索引擎技术已经不能满足人们的实际需要,而推荐系统可以利用用户行为信息和物品内容信息挖掘人们可能感兴趣的物品,从而进行个性化的信息推荐[1,3].因此推荐系统利用本身独特的优势开始逐步融入到日常生活中,减短人们获取信息的时间,它被大量地应用在网络商城、信息检索和互联网广告等领域[1,2].好的推荐系统不仅仅可以给用户推荐个性化信息,而且可以增加用户对网站的依赖性.推荐系统同时也面临着众多的问题:数据稀疏性问题[4]、冷启动问题[5]、计算量大[6]、扩展性问题[7]等.目前国内外的众多学者已经针对这些问题进行了一系列的研究.文献[8]首先介绍了协同过滤推荐技术所面临的问题,接着介绍了解决这些问题的方案,最后指明了协同过滤推荐技术未来的研究重点.文献[9]提出了一种基于共同评分和相似性权重的协同过滤推荐算法.文献[10]提出将时间因素融入用户项目评分矩阵中,以解决兴趣衰减的问题.文献[11]提出利用基于用户协同过滤算法计算出邻居集,再结合加权 Slope One 算法,预测项目评分,实现对用户个性化信息推荐.文献[12]提出了为了降低用户推荐的计算时间,提出了一种改进的层次聚类协同过滤用户推荐算法.对用户聚类,按照分类计算出每个用户的推荐列表.上述这些研究着重于利用某种机制改进用户相似度的计算或者加速用户相似度的计算,忽略了物品内容信息对用户偏好的影响.在传统协同过滤机制中直接利用评分矩阵来挖掘出目标用户的偏好,但并不能反映出目标用户真实的兴趣爱好.例如电影《泰坦尼克号》的属性为爱情、灾难、莱昂纳多、卡梅隆等,用户选择该电影是因为他是主角莱昂纳多的影迷,但通过评分矩阵无法体现该用户的兴趣所在[13].因此本文提出通过结合物品内容信息和用户行为信息来构建用户兴趣模型,利用用户兴趣模型进行推荐,这充分发挥了物品内容对用户兴趣爱好的影响.推荐结果在准确率和召回率等方面相比传统的基于用户的协同过滤有着明显的提高.
1 相关技术
1.1 LDA主题模型
主题模型[14–17]是对文字隐含主题的一种建模方式,它可以挖掘文本中潜在的主题.LDA[18]是主题模型中最经典的一种算法.它也是一种生成模型[14],认为一篇文档中每个单词都是经过“以一定概率选择某个主题,并在这个主题中以一定概率选择某个单词”这一过程得到的.根据LDA主题模型的生成过程[16,17]的定义,那么每篇文档中词语出现的概率如式(1)所示.

LDA的概率图模型如图1所示.其中,M是文档数量;K是主题个数;V是词袋长度;Nm是第m篇文档中单词的总数;α和β是先验参数;θ是一个M×K的矩阵,θm表示第m篇文档的主题分布.α到θ到Z的过程表示在生成第m篇文档时,先确定第m篇文档的主题分布,然后确定第m篇文档中的第n个词语的主题.φ是一个K×V的矩阵,φk表示第k个主题的词分布;β到φ到W的过程表示在K个主题中,选出编号为Zm,n的主题,然后生成第m篇文档中的第n个词语Wm,n.LDA算法的输入是大规模的文档集合、两个超参数和主题个数,经过LDA主题模型的训练之后得到两个分布,分别为文档-主题概率分布和主题-单词概率分布.
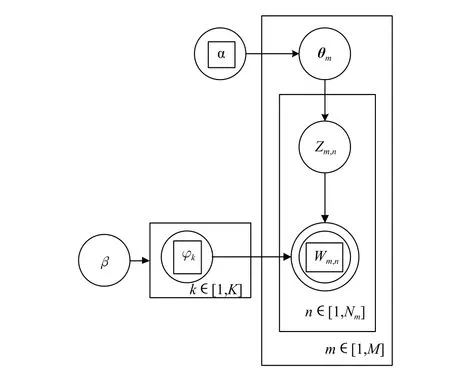
图1 LDA 的概率图模型
1.2 基于用户的协同过滤
基于用户的协同过滤算法[3,8]认为,一个用户会喜欢和他有相似兴趣爱好的最近邻所喜欢的东西[14],其主要利用行为的相似度计算兴趣的相似度.
用户相似度的计算是基于共同评分的项目集进行的,通常利用余弦相似度[19,20]进行计算,如式(2)所示:
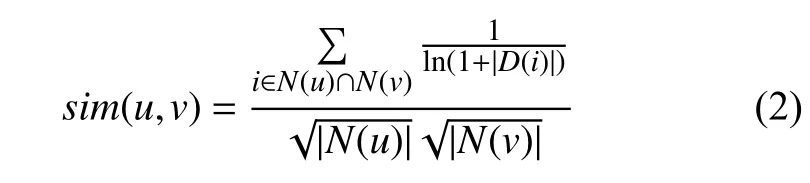
其中,D(i)表示对物品i有过行为的用户集,N(u)表示用户u有过行为的物品集合.
基于用户的协同过滤算法如算法1.

算法1.基于用户的协同过滤算法输入:评分矩阵R,物品集D,用户集N,目标用户u输出:目标用户u的推荐列表Begin:Usim={},sim={},rank={}forvinN:fordinN(u)anddinN(v):sim(u,v)+= 1/(ln(1 +len(D(d))));

end for sim(u,v)/=(len(N(u))* len(N(v)));end for Usim= sorted(sim(u,v))[0:N];forvinUsim:foriinN(v)andinot inN(u):rank(i)+=sim(u,v)end for end for return sorted(rank)[0:N]
2 用户兴趣模型的建立
虽然基于用户的协同过滤对物品冷启动问题不敏感,但需要解决第一推动力问题,即第一个用户如何发现新物品.如果将物品随机展示给用户,显然不太个性化,因此可以考虑利用物品的内容信息,将新物品投放给曾经喜欢过和它内容相似的物品的用户[20].
通过分析用户的历史评分记录来创建用户历史兴趣模型,进而为用户推荐一组物品.用户的历史记录是有限的,因此存在数据稀疏性问题.针对此问题,提出了以用户行为和物品内容为基础来构建用户兴趣模型,从而为用户进行推荐.
2.1 LDA主题模型建模
首先通过标题、导演、编剧、主演、类型和简介等等来给电影划分属性,生成电影-属性分布文件.然后在电影-属性分布上利用LDA主题模型进行建模,得到电影-主题概率分布,利用这个分布计算相似性.
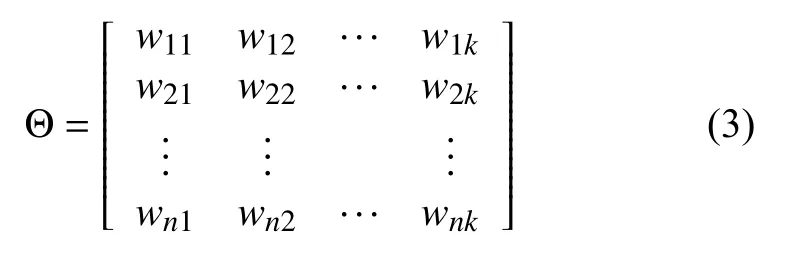
给定电影集M={m1,m2,…,mn},将每个电影看成一个单独的文档,对于文档中内容信息诸如像导演、主演等实体的话可以直接将这些实体作为电影属性,但诸如像简介等需要对文本内容进行分词,从字流变为词流,从词流中提取出命名实体,将这些命名实体也作为电影属性,形成电影-属性分布.在电影-属性分布上利用LDA算法进行建模,设置主题个数为K,从而得到主题特征序列[21]F=(f1,f2,…,fk)和电影-主题概率分布矩阵Θ,如式(3)所示:
2.2 构建用户历史兴趣模型UHIM
对于任意用户,利用评论过的电影和电影-主题概率分布矩阵Θ进行数学运算,得到与F对应的权值向量称为用户历史兴趣模型(User History Interest Model,UHIM),其数学式为UHIM=(w11,w12,…,w1i,…,w1k),其中,w1i表示主题词fi在UHIM中的权值.用户u的UHIM中主题词fi的权值计算如式(4)所示,该值代表了用户现有情况下的兴趣分布情况,较好了反映了用户历史的兴趣爱好.
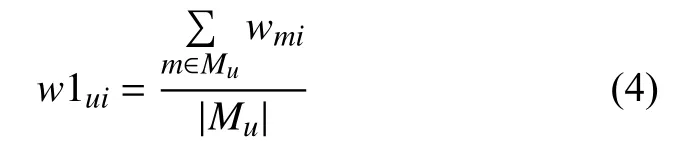
其中,Mu是用户u评论的电影集合.
2.3 构建用户行为兴趣模型UAIM
对于任意用户,利用评论过的电影计算用户行为之间的相似度,通过协同过滤将相似用户群的历史模型推荐给该用户,得到与F对应的权值向量称为用户行为兴趣模型(User Actor Interest Model,UAIM),其数学式为UAIM=(w21,w22,…,w2i,…,w2k),其中,w2i表示主题词fi在UAIM中的权值.在选择相似用户群时选择相似度最大的前h个用户.
用户u和用户v的行为相似度计算如式(2)所示.
用户u的UAIM中主题词fi权值计算如式(5)所示:
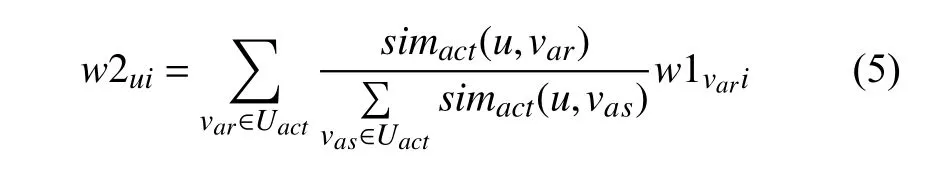
其中,Uact为用户u的行为相似用户群.
2.4 构建用户内容兴趣模型UCIM
对于任意用户,结合电影的内容信息计算用户内容之间的相似度,通过协同过滤将相似用户群的历史兴趣模型推荐给该用户,得到与F对应的权值向量称为用户内容兴趣模型(User Content Interest Model,UCIM),其数学式为UCIM=(w31,w32,…,w3i,…,w3k),其中,w3i表示主题词fi在UCIM中的权值.在选择相似用户群时选择相似度最大的前h个用户.
设用户u评论的电影集Mu={mu1,mu2,…,mus},历史模型UHIMu=(w1u1,w1u2,…,w1uk),用户v评论的电影集Mv={mv1,mv2,…,mvt},UHIMv=(w1v1,w1v2,…,w1vk).
用户u和用户v的内容相似度计算如式(6)所示.

用户u的UCIM中主题词fi权值计算如式(7)所示:
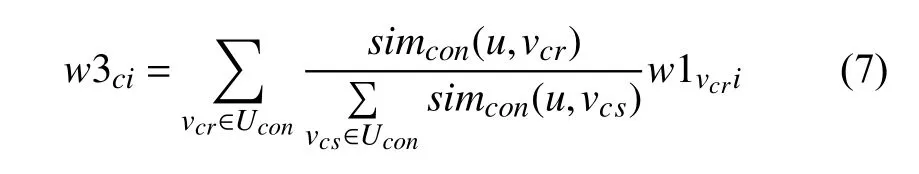
其中,Ucon为用户u的内容相似用户群.
2.5 构建用户兴趣模型UIM
得到目标用户的UHIM、UAIM和UCIM后,将三个兴趣模型的主题词权值进行合并,可得到用户兴趣模型(User Interest Model,UIM),其数学表达形式为UIM=(w41,w42,…,w4i,…,w4k),其中,w4i表示主题词fi在UIM中的权值.
设目标用户u的UHIMu=(w1u1,w1u2,…,w1uk)、UAIMu=(w2u1,w2u2,…,w2uk)、UCIMu=(w3u1,w3u2,…,w3uk),UIMu=(wu1,wu2,…,wuk),则用户u的UIM中主题词fi的权值计算如式(8)所示:
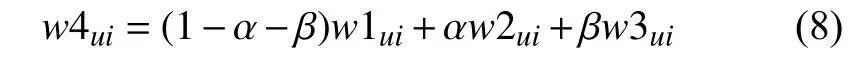
2.6 生成推荐列表
将候选电影集同目标用户UIM进行相似度计算,进行TOP-N推荐.
设候选电影Mcs={m1,m2,…,mh}.目标用户u和候选电影之间的相似度计算如式(9)所示:
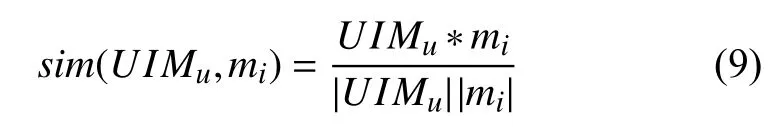
构建用户兴趣模型算法的描述如算法2.
首先将电影内容向量化,利用LDA模型建模,生成电影-主题概率分布矩阵Θ;其次分析用户记录,构建用户历史兴趣模型UHIM;再次利用用户记录计算用户行为相似度,从而构建用户行为兴趣模型UAIM;最后结合物品内容信息计算用户内容相似度,进而构建用户内容兴趣模型UCIM,融合UHIM、UAIM和UCIM生成用户兴趣模型UIM.

算法2.构建用户兴趣模型的算法输入:电影-主题概率分布矩阵Θ,用户集N,目标用户u输出:目标用户u的兴趣模型Begin:UHIMu=(w1u1,…,w1ui,…,w1uk),UAIMu=(w2u1,…,w2ui,…,w2uk),UCIMu=(w3u1,…,w3ui,…,w3uk),UIMu=(w4u1,…,w4ui,…,w4uk),Ucon={},Uact={},simcon={},simact={}// calculateUHIMufordinN(u):w1ui+=wdi;end for w1ui/= len(N(u));
3 实验结果及其分析
3.1 实验数据与实验评价指标
实验数据采用豆瓣电影网的1337部电影,1535个用户,109 398条评分记录作为实验数据集.
本文使用离线实验方法进行评测[20].评价指标选用准确率/召回率和F值来评测推荐算法的精度.召回率[17,20]描述有多少真正产生过行为的物品包含在最终的推荐列表中;准确率[3,20]描述最终的推荐列表中包含多少真正产生过行为的物品;F值[19,21]是准确率和召回率之间的调和平均值.对用户u推荐N个物品,记为R(u);用户u在测试集合上产生过行为的物品记为T(u).召回率计算如式(10)所示.
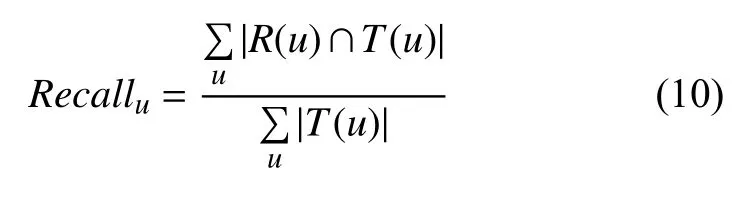
准确率计算如式(11)所示.
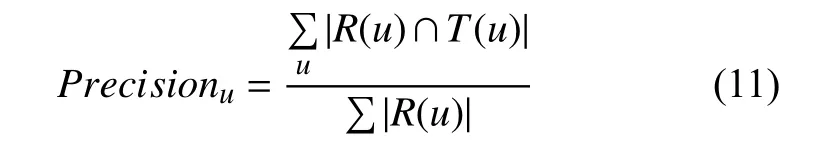
F值计算如式(12)所示.

3.2 实验结果
(1)主题个数K的确定
利用LDA主题模型进行建模时,需要设定主题个数K的大小,表1显示了当给每个用户推荐电影数目为20时,不同的K值对召回率、准确率和F值的影响,可以看出K为20的时候是最佳值.
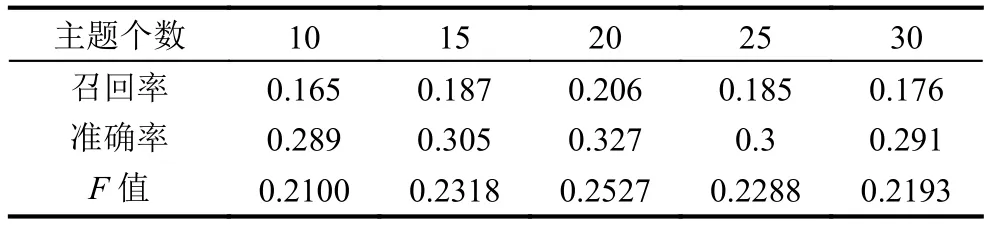
表1 不同的主题个数对应的召回率、准确率和F值
(2)最近邻h的确定
构建UAIM和UCIM时需要设置最近邻的个数,表2显示了当主题个数为20并且给每个用户推荐电影数为20的时候,不同h值对召回率、准确率和F值的影响,可以看出相似用户数为30的时候是最佳值.
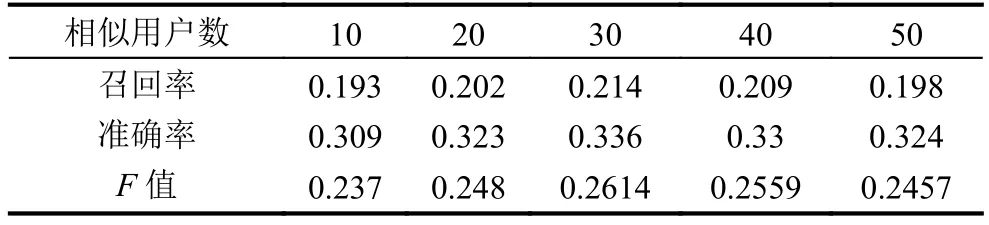
表2 不同的h值对应的召回率、准确率和F值
(3)不同推荐方法下召回率、准确率和F值.
图2显示了主题个数为20,最近邻为30时,不同的推荐电影数目对三种推荐算法在召回率方面的影响.随着推荐电影数量的增加,召回率均随之增加.
图3显示了主题个数为20,最近邻为30时,不同的推荐电影数目对三种推荐算法在F值方面的影响.随着推荐电影数量的增加,准确率随之降低.
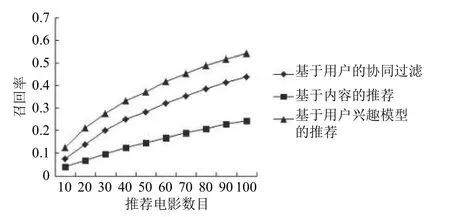
图2 召回率对比
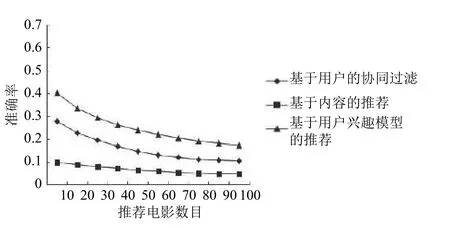
图3 准确率对比
图4显示了主题个数为20,最近邻为30时,不同的推荐电影数目对三种推荐算法在召回率方面的影响.推荐电影数量为40,F值最佳.

图4 F值对比
通过上述的对比可以看出,本文采用的方法在推荐质量上要优于传统的推荐算法,从而证明了该模型的可行性.
4 结语
本文针对传统协同过滤算法中面临的数据冷启动和稀疏性的问题,提出了一种基于用户兴趣模型的电影推荐算法,该算法首先利用用户记录和物品信息构建用户历史兴趣模型,然后使用协同过滤算法挖掘出用户行为兴趣模型和用户内容兴趣模型,最后将三种模型进行融合,再与候选电影集进行相似度计算.最后通过实验验证,表明本文算法在一定程度上改善了数据稀疏性问题,提高了算法的推荐质量.面对日益增多的用户,数据量的急剧增加,算法的扩展性问题成为制约推荐系统实施的重要因素,尤其当用户量达到一定水平时,用户相似度的计算量是巨大的,传统的推荐算法会遇到严重的瓶颈问题,该问题解决不好,将会直接影响推荐系统的质量,那么下一步的重点是解决算法的扩展性问题.
