基于社交信任和标签偏好的景点推荐方法①
2018-09-17陈烨天米传民
陈烨天,米传民,肖 琳
(南京航空航天大学 经济与管理学院,南京 211106)
随着国民生活水平的提高和互联网的快速发展,我国在线旅游发展迅猛,2016年中国在线旅游市场交易规模已达6026亿,同比增长34%[1].人们可以在各种在线旅游平台上挑选自己喜欢的旅游产品并制定相应的出行计划.然而严重的信息过载问题,使得用户很难便捷地从海量的检索结果中获取自己真正需要的旅游信息[2].此外,目前国内的在线旅游电商平台提供的服务项目单一,旅游路线、景点介绍几乎都是固定内容,推荐系统的搜索和推荐结果多以产品热度排序,无法满足用户个性化的需求[3].尤其是在旅游景点的推荐上,景点热度和时间因素会对用户造成极大地干扰.用户缺乏旅游经验,面对过于广泛和缺乏人性化的推荐信息,难以获取较高的满意度[4].
为解决上述问题,学者们针对个性化旅游推荐技术做了广泛的研究,主要集中在基于社交媒体的推荐上[5–7].但区别于图书、音乐等物品的推荐[8],由于旅游景点众多,用户购买频次低,导致数据稀疏性极大,传统的推荐方法难以解决冷启动和“新城市”等问题[9].本文通过引入用户信任关系来缓解数据稀疏性和冷启动问题,根据用户社交行为和影响力衡量显性信任,利用上下文信息挖掘隐性信任,并通过信任传递计算用户间接信任,构建完整的信任网络.在信任推荐的基础上,进一步融入用户-标签兴趣信息,提出一种结合社交信任和地理标签的STGT推荐算法(recommended algorithm combined with Social Trust and Geo-Tags ).实验结果表明,本文提出的算法能在一定程度上提高推荐精度,同时缓解新用户和新城市等问题.
1 相关工作
个性化旅游推荐系统通过挖掘用户数据,获得用户的潜在需求和未来喜好,从而主动为用户推荐满足需求或感兴趣的信息,不仅有效解决了信息过载问题,而且满足了用户的个性化需求[10].不同于其他个性化推荐,个性化旅游推荐面临的挑战更大[11]:(1)旅游数据更复杂;(2)用户更难准确表达自己的需求;(3)大多数用户的历史旅游记录和偏好信息都很少;(4)旅游数据更稀疏.传统的推荐方法如协同过滤推荐等效果不佳,数据稀疏性、冷启动问题严峻,还有新城市推荐问题[5].
为解决上述问题,学者们在传统的推荐方法上做了不少改进.从获取用户个性化信息方式角度可分为两类:(1)用户交互方式.如 Ahas 等人[12]通过邀请用户填写问卷的方式获取用户偏好;麻风梅[13]以会话的方式在线获取用户偏好和需求,结合用户浏览行为得到综合兴趣度进行推荐.这类基于知识、会话式的推荐方法不需要用户历史数据,故不存在冷启动问题,对非注册用户也能做出个性化推荐,但数据稀疏性问题依旧无法解决.另一方面,这种方式无法得到大量用户的数据,时间和操作成本高,能使用的用户训练样本小,无法满足日益庞大的数据量处理需求.(2)用户产生的社交媒体数据.这些社交媒体数据包括签到数据(check-in)[14],GPS 轨迹信息[15]、旅游博客[6]等.这类方法能获得大量的用户历史数据和消费行为数据,覆盖面广,得到的结果更具有普适性.近年来,随着互联网技术的不断提高,带有地理信息的图片数据越来越受到研究者的关注[7].以Flickr、Panoramio为代表的图片分享网站的兴起,为研究者提供了海量的用户旅游照片.这些照片附带地理位置、拍摄时间、标签等重要信息,本身就体现了用户的旅游兴趣偏好,为个性化推荐带了极大地便利[16].
随着用户个性化需求的不断提高,学者们利用地理图片社交媒体这一数据时,分析用户偏好的方法主要分成两类:(1)利用上下文信息分析用户偏好,包括用户年龄等个人信息、消费成本、天气、时间和季节等时空信息[17].如Memon等人[18]综合考虑用户偏好和时间因素,根据用户过去时间内在旧城市的旅游偏好推荐新城市的旅游产品.Yin等人[15]进一步区分了游客偏好和当地居民偏好,利用当地居民偏好缓解数据稀疏性和新城市问题.这些研究在传统用户相似性度量假设用户未评分项为0的基础上,通过添加附加约束条件缓解数据稀疏性问题,但没有从根本上解决这个问题.因此有研究者提出在计算用户相似性时,先用相似性度量方法计算未评分稀疏项和其他项目的直接相似性,增加共同评分项来缓解稀疏性.但这类研究集中在电影、音乐数据,在旅游景点推荐方面的效果有待检验.(2)利用标签信息.之前的研究大多使用用户评分数据,但相同的评分不能代表兴趣真正相同.标签信息可以进一步直观地揭示用户对景点本身的兴趣点.如Lu等人[7]结合地理手册从地理信息图片中得到目的地后,引入目的地风格标签,结果比只用流行游览时间等上下文信息更精确.虽然这些研究通过标签细化了用户兴趣偏好,但大多简单地考虑了标签-景点关系,进行景点预过滤筛选处理,忽视了标签-标签关系、用户-标签关系.
此外,部分学者还引入了社交信任关系来缓解传统协同过滤算法的弊端,通过综合信任度和相似度,提高推荐精度[19].如史一帆[20]提出的基于用户社交关系和物品标签的协同过滤推荐,把与目标用户相似度大于0或信任度大于0的用户当做相邻用户.但这些研究大多聚焦在图书、音乐、电影等推荐领域,涉及旅游照片、游记等类型数据的旅游推荐研究极少.刘艳等人[3]通过用户景点照片矩阵计算用户偏好,结合好友亲密信任关系计算相似度,但只是简单判断了好友间是否有关注关系,忽视了用户交互行为和信任的传递问题.在现实推荐中,社交用户间的直接信用值获取也是一个难题.
因此,本文基于图片数据,根据用户社交行为、社交影响力和上下文信息获取用户直接信任和隐性信任关系,在考虑信任传递的基础上挖掘用户间接信任,最后综合相似度和信任度得到推荐结果.为缓解用户信任好友稀缺时推荐效果不佳的问题,引入用户标签偏好,提出一个混合社交信任和标签兴趣的STGT景点推荐算法.实验结果表明,该算法能够有效利用多维信息,提高推荐精度.
2 基于社交信任的景点推荐模型
2.1 构建信任网络
利用图片媒体数据挖掘用户信任关系的关键是构建信任网络:给定一个用户-景点评分模型,如何表示用户集合中用户间的直接信任关系.直接信任指直接相连的用户间的信任关系,可进一步分为显性信任和隐性信任.
(1)显性信任
显性信任可通过用户社交互动行为和社交影响力获取.在本文中,当用户i和用户j存在好友关系,且用户i对用户j有点赞等互动行为,则认为两个用户间存在显性信任关系,用trustie,xj表示,计算公式为:
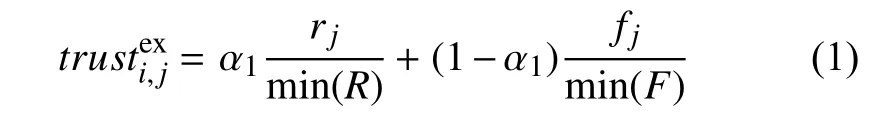
其中,R=(r1,r2,···,rn),rj表示用户i对用户j发布的照片等状态的点赞数;F=(f1,f2,···,fn),fj表示用户j在社交网络中的被关注数.α1取0.75,将较大权重分配给用户社交互动行为.
(2)隐性信任
当两个用户为非好友时,即trustie,xj=0,但不代表他们是非信任关系,因此需要判断计算他们之间是否有隐性信任关系.本文通过计算用户共同游玩景点的上下文情景信息相似度,来推导用户隐性信任,计算如下:
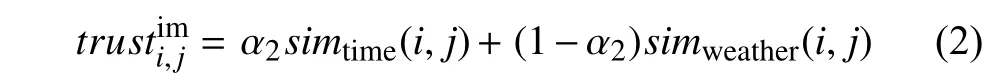
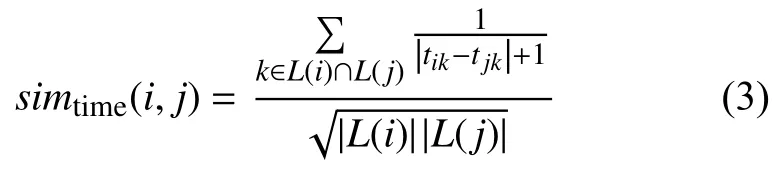
其中,simtime(i,j)表示用户i和j的游玩时间相似度,L(i)表示用户i游玩过的景点集合,L(j)表示用户j游玩过的景点集合,k∈L(i)∩L(j)表示用户i和j共同游玩过的景点,tik表示用户i游玩景点k的时间,tjk表示用户j游玩景点k的时间.

其中,simweather(i,j)表示用户i和j的游玩天气相似度,上下文天气信息用CI=(Temperature,Condition)表示,包含气温Temperature={hot,warm,cold},天气状况Condition={rainy,sunny,cloudy}.
综合前面的显性信任和隐性信任关系,得到用户直接信任值trustdi,ijr计算方式如下:

得到trustid,ijr就能构建信任网络,过程如下:遍历每个用户和其他用户间的直接信任值,与全局信任阈值tthreldall比较,若trustid,ijr大于tthreldall,说明用户间直接相连,反之则说明没有直接相连,由此检查每个用户的连接情况.网络中的每个节点分别代表一个用户,连接节点每条边代表用户间相互连接,边上的权值代表直接信任度,边的方向代表信任方向.
2.2 计算间接信任
信任具有传递性,即当用户a信任b,用户b信任c时,认为用户a对c也存在着信任关系[21].因此仅仅考虑用户直接信任值构建的信任网络并不能完全反应用户的信任关系,还需要考虑信任在网络中传播时的间接信任值.关于信任传播比较经典的算法是TidalTrust[22]和 MoleTrust[23]算法.本研究借鉴TidalTrust算法思想,做出了改进.通过考虑隐性信任解决了用户显性信任难以获取时无法进行信任度计算的问题,并引入信任最长传播距离解决了TidalTrust算法中舍弃高信任值的长距离路径问题.
首先需要为每个节点用户设置一个路径信任阈值,将目标用户对所有邻居用户的信任值的平均值作为路径信任阈值pthrelds:
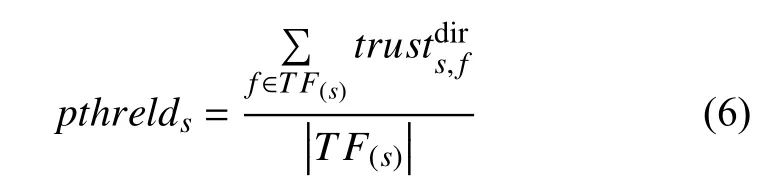
其中,TF(s)表示用户s的所有直接信任好友,trustds,irf表示用户s对直接信任好友f的直接信任值.在信任传递过程中,这个路径信任阈值将过滤所有信任值低于此阈值的路径.
TidalTrust算法中取目标节点到源节点的最短路径d作为信任最长传播距离,这有可能舍弃路径长但信任度高的路径.因此,文献[24]中信任传播距离的研究:

其中,n表示信任网络中的用户总数,m表示网络中用户的邻居用户的平均数,即平均度数.本文在信任最长传递距离的选择上取MD=max(L,d).如果用户A不能到达用户B,则B对A就没有信任价值.但如果A能在最大传递距离内达到B,则意味着B对A来说具有一定的信任价值[25].
选择完信任路径和传递距离后,通过加权源节点与直接信任节点间的信任值,得到源节点对目标节点的间接信任值,公式如下:
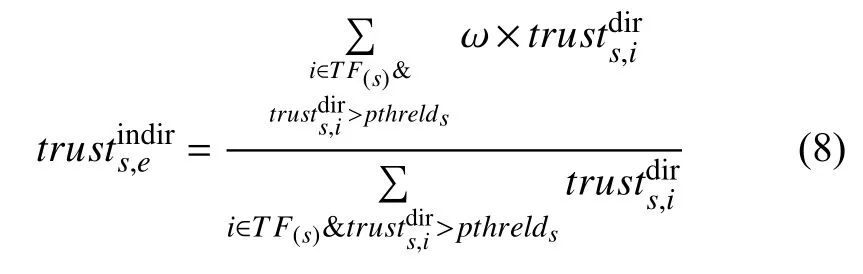
其中,加权因子是通过比较直接信任节点到目标节点的最大路径信任值确定的,如公式(9)所示.route(i,e)表示用户i到用户e的所有路径集合,(x,y)∈r指路径r上的任意两个用户x和y,表示单条路径r上的两个用户间信任值的最小值.
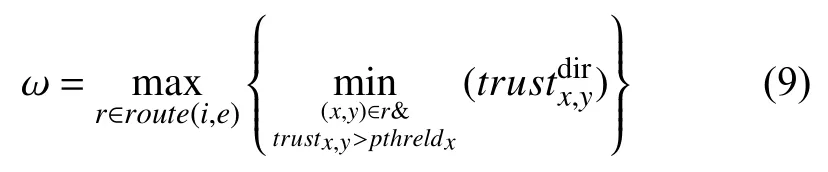
综合上述计算,信任网络中任意两个用户间的传递距离在信任最长传播距离内时,他们之间存在信任关系:当距离为 1 时,两用户直接相连,取直接信任值作为信任度;当距离大于1且不超过最长传播距离时,取间接信任值作为用户间信任度.当用户间距离大于最长传播距离时,信任度为0.
2.3 结合相似度和信任度的推荐策略
在传统的协同过滤推荐算法中,目标用户对目标项目的评分可以通过加权计算目标用户的相邻用户打出的评分来进行预测.但随着系统中用户和项目数量的增加,数据稀疏性越来越高,以及新用户和新项目带来的冷启动问题大大降低了传统协同过滤算法的推荐精度[26].研究证实在推荐过程中引入信任关系能缓解上述协同过滤推荐算法中的主要问题,有效地提高推荐结果的准确度.Massa[23]提出的MoleTrust模型则采取通过信任关系过滤相邻用户,信任度替代用户相似度的策略.经典的TidalTrust算法则利用信任关系过滤相邻用户,再通过信任权重加权评分的方式进行评分预测.
这些基于社交信任关系的推荐算法虽然提高了推荐结果的准确度,但推荐结果的覆盖率却比不上经典的协同过滤推荐计算方式.因此本文采用综合协同过滤推荐和信任推荐的推荐策略:
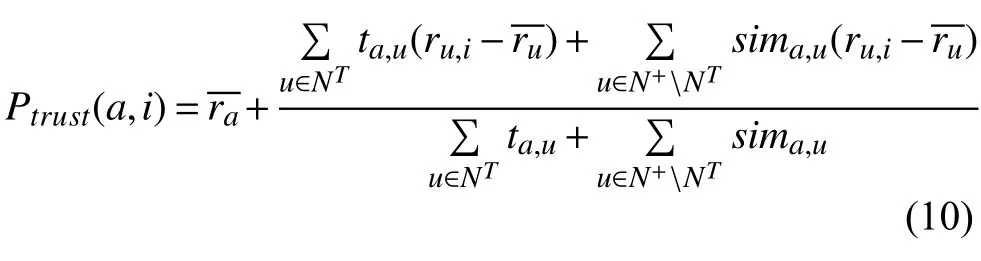
其中,Ptrust(a,i)表示目标用户a对景点i的预测评分,N+表示和目标用户a相似度高的相邻用户集,ta,u表示用户a和用户u间的信任度,NT表示对目标项目i有过评分且信任度ta,u超过阈值的用户集合,NT+=NT∩N+.ru,i表示用户u对项目i的评分,是用户u的项目平均评分,是用户a的项目平均评分.sima,u表示用户a和用户u间的用户相似度,通过Pearson相关系数计算得到.
当目标用户和其他用户之间有直接或间接的信任关系时,则使用信任度代替相似度作为加权计算的权重,通过优先考虑信任用户的方式来保留信任推荐的优势.另一方面,覆盖率可以通过考虑无法获取信任信息的那部分相似用户保证.
3 考虑信任关系和标签偏好的STGT景点推荐算法
虽然基于信任的推荐往往能获得较高的满意度和覆盖率,但现实中信任关系一般比较稀疏,好友数量不足,导致推荐效果不理想.因此本文在考虑信任关系的基础上,融入用户偏好,通过计算用户对标签的偏好来分析用户兴趣,进一步挖掘了用户的个性化需求.
3.1 基于标签的用户偏好建模
传统的协同过滤通过用户评分来表现用户兴趣偏好,受到数据稀疏性影响推荐结果不佳.标签信息的引入可以很好地细分用户兴趣点,通过计算用户对标签的偏好度能很好地表示用户的兴趣点分布,缓解数据稀疏问题,同时在面对新用户时也能通过获取标签偏好来缓解冷启动问题.
(1)计算景点-标签关联度
首先我们定义用户集合U={u1,u2,···,un},景点集合L={l1,l2,···,lm},标签集合T={t1,t2,···,tk},Lu表示用户u浏览过的景点集合,Tu表示用户u使用过的标签集.一个景点会被很多用户标记标签,在得到用户的标签偏好前需要在景点和标签之间建立联系,评价一个标签在景点资源中的重要性.文献[27]表明,sigmoid函数能最好地表示标签的权重,用W(l,t)表示景点-标签关联度,即:
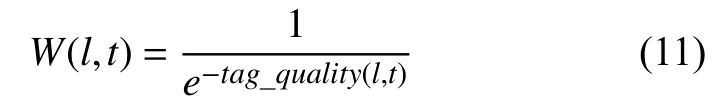
其中,tag_quality(l,t)可用TF算法算得,表示标签t在景点l的标签集中出现的比重.
(2)计算用户-标签关系
本文从用户标签行为和用户评分行为两方面衡量用户标签喜好度:一方面考虑了用户标记标签时间,另一方面当标签在评分越高的景点出现,表示用户对标签的兴趣越高.用tag_prefini表示用户u对标签t喜好度,计算如下:
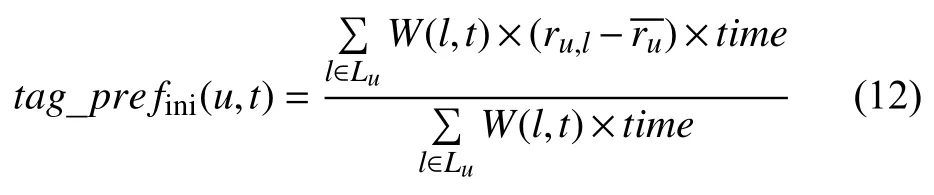
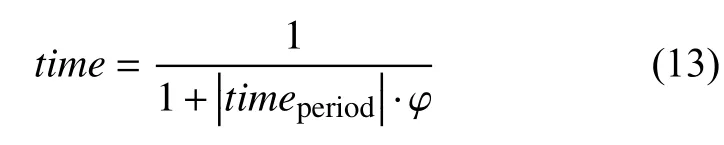
timeperiod表示到用户标记标签的时间到现在的时间间隔,.
(3)计算标签-标签关系
当用户标签行为和评分较少时,标签稀疏性较高,为解决这个问题,本文采取了拓展标签的方法,为每个用户的标签集增加相关度高的相关标签.首先计算标签相关度:
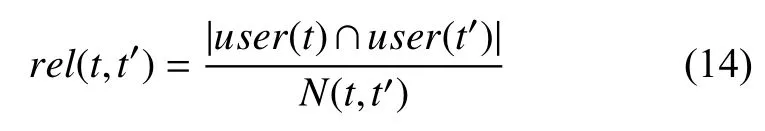
其中,|user(t)∩user(t′)|表示同时使用过标签t和t′的用户数,N(t,t′)表示标签集中同时含有标签t和t′的景点数.按相关度对标签排序,选取TopM个相关标签作为相关标签,得到新的用户标签集Tu′.
用户对相关标签的喜好度可通过加权相关标签喜好度得到:

综合tag_prefini和tag_prefex可得用户的标签喜好度.
3.2 综合信任关系和用户偏好的推荐策略
由于基于信任的推荐结果未充分考虑用户兴趣,本文通过对用户标签喜好度的分析进一步进行了用户兴趣建模.因此在最终的推荐策略上,本文选择加权混合推荐的方式融合两种推荐方法的优势,通过加权因子λ将两个预测结果线性组合,λ的取值由实验结果确定.预测公式如下:
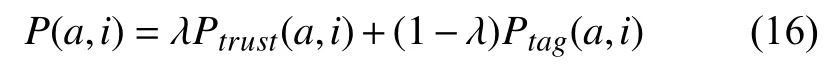
其中,Ptrust(a,i)指基于信任关系的推荐得到的预测评分,计算方法在公式(10)中已给出.Ptag(a,i)指基于标签兴趣的推荐得到的预测评分,计算公式如下:
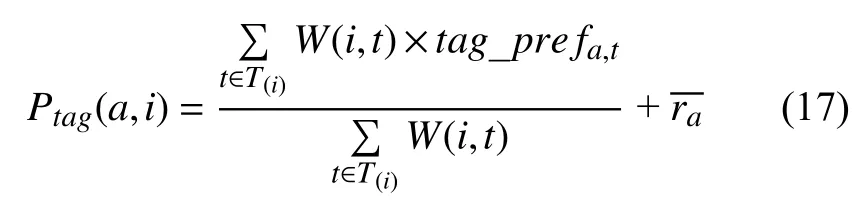
其中,T(i)表示景点i包含的标签集.最后根据P(a,i)对推荐景点列表进行降序排序,选取TopK个结果作为推荐结果.
4 实验验证和分析
4.1 实验数据集
Flickr是一个提供免费及付费数位照片存储、分享服务的图片网站,重要特点就是基于社会网络的人际关系的拓展与内容的组织.在当前的景点推荐领域中,很多推荐方法都会把Flickr数据集作为实验数据集进行研究.本文的数据集就是选用Flickr公开的图像数据集.城市的天气信息通过第三方天气服务网站的API爬取.对得到的数据集进行预处理,删除那些元数据中的地点信息和实际经纬度不符以及带有错误时间的照片.利用文献[28]中的P-DBSCAN方法对照片的经纬度进行聚类得到景点,去除游历景点数少于3个的用户,去除包含图片数少于10张的景点,最后的统计结果如表1所示.为检验算法在解决“新城市”问题上的效果,选择至少去过四个城市中两个城市的用户,且其在训练集中的游历景点数不少于5个.实验时随机将数据集的80%作为训练集,20%作为测试集.
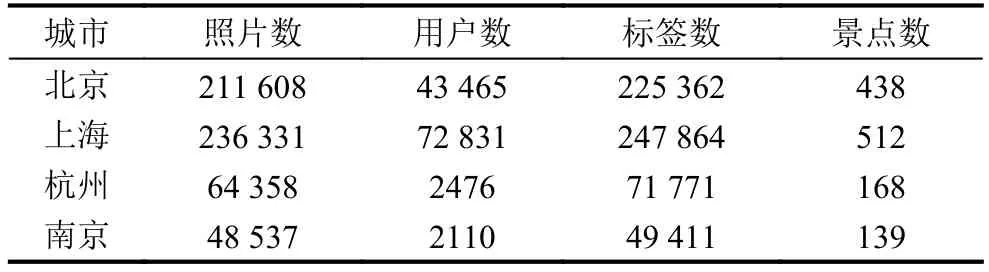
表1 实验数据集统计信息
4.2 评价指标
本研究采用的评价指标是推荐系统中常用的精确度(Precision)和平均绝对偏差(MAE).MAE用来衡量推荐算法的预测评分和实际评分之间的差异程度,用户对景点的评分可通过用户在景点拍摄的照片数量占比表示.MAE的值越小,代表推荐的准确度越高,推荐效果越好,定义如下:
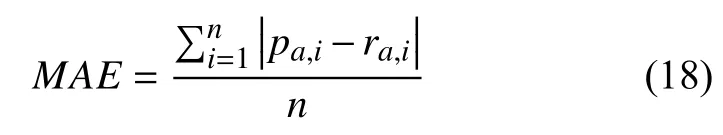
其中预测用户a对景点i的评分为pi,用户对景点的实际评分是ri,n为测试集的景点数量.
精确度是Top-n推荐问题的重要衡量指标,用表示根据训练集预测的推荐列表,T(u)表示用户在测试集上的实际访问景点列表,计算公式如下:
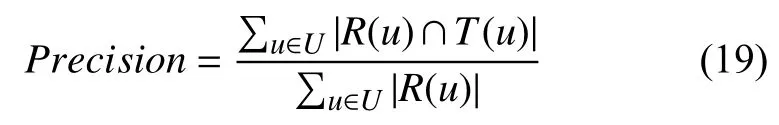
4.3 实验结果分析
实验一.确定加权因子λ
为了选择最佳的加权参数使得混合推荐的效果达到最好,我们先固定推荐数量和用户最近邻数都为25进行实验,通过改变 λ的取值观察MAE指标的变化.λ从0.1取到0.9,依次递增0.1.实验结果如图1所示.
从图1中可看出,随着加权因子 λ 的逐渐增大,MAE的值先逐渐减小再逐渐增大.当 λ 的取值为0.6 时,MAE的值达到最小,推荐质量达到最佳.因此我们在后面的实验中取 λ=0.6,来确定用户最近邻数量和不同算法推荐效果的比较.
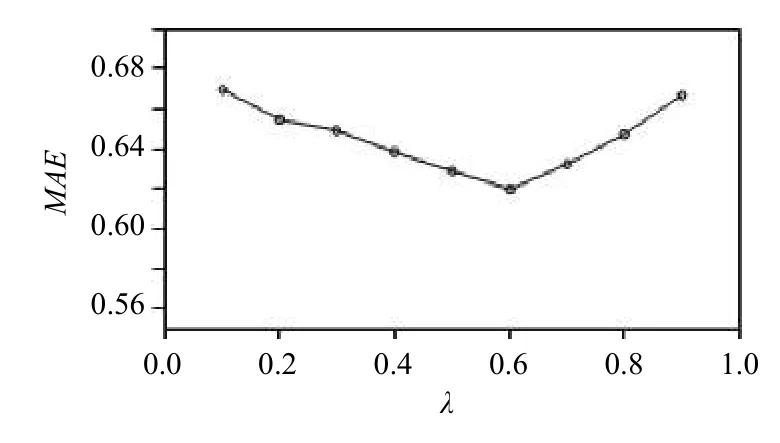
图1 λ取值对实验结果的影响
实验二.和其他推荐算法的比较
为了验证本文提出融合信任关系和用户偏好的STGT推荐算法的准确性和推荐效果,将本文提出的算法和考虑标签信息和社交关系的UKS算法[20]、基于信任和项目偏好的TIPCF算法[26]以及MFT-Co[29]信任推荐算法进行对比.固定推荐列表长度为15,拓展标签的数量取20,通过改变最近邻数量观测MAE和Precision@15值的变化.实验结果如图2、图3所示,横坐标为最近邻数目个数,纵坐标为MAE和Precision@15的值.
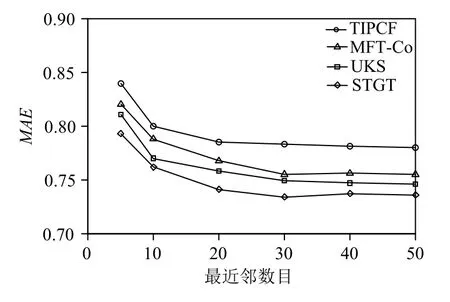
图2 各算法MAE值对比
从图2实验结果中可看出,最近邻数目确实是影响推荐质量的因素,随着最近邻数目的增大,各推荐算法的MAE值下降明显,当数目达到30左右时MAE的值趋于稳定.说明近邻用户与目标用户的相似度和信任度已经接近阈值,此时继续增大最近邻数目,增加的近邻用户已经不具备较好的推荐参考价值(相似度或信任度低于阈值),导致推荐效果趋于平缓.从整体上看,STGT算法的推荐效果明显优于其他三种算法,而UKS的推荐质量比MFT-Co和TIPCF好.
从图3实验结果可知,本文提出的STGT算法在精确度上有明显提高,比TIPCF、MFT-Co和UKS算法分别提高了14.01%、10.07%、6.62%.从增长趋势看,随着最近邻数目的增长,精确度的提升趋势放缓并趋于稳定,继续加入相似度或信任度低的近邻用户无法再提高推荐精确度.
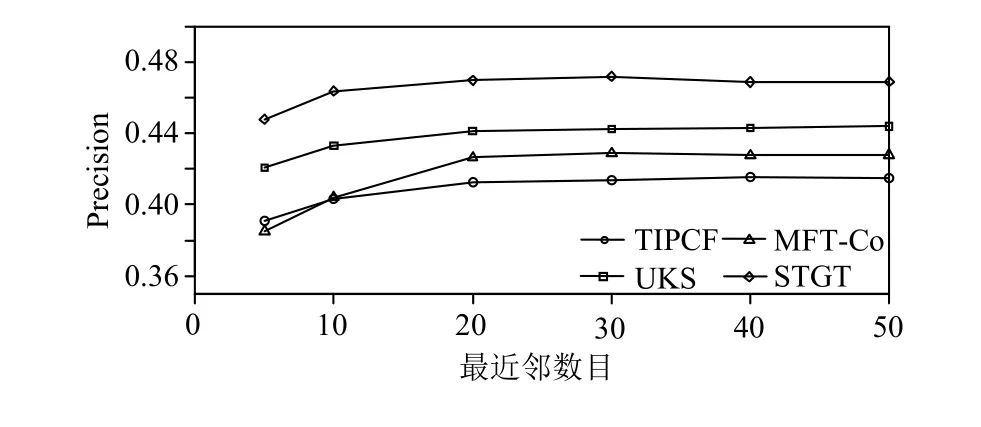
图3 各算法 Precision@15 值对比
为验证本文提出的算法在缓解冷启动问题上的效果,随机抽取 10 000 名用户进行实验,并随机去除150个景点在训练集中的用户访问信息,模仿冷启动环境.从图4的实验结果可知,STGT算法对于系统中新项目的应对能力和推荐效果明显优于其他三种算法,随着最近邻数目的增加,算法性能趋于稳定,有效地缓解了冷启动问题.

图4 冷启动环境下各算法推荐效果对比
从以上分析可得出以下结论:(1)由于本文提出的STGT算法更准确地衡量了用户间的信任关系,通过综合考虑用户评分行为和兴趣品偏好挖掘出用户隐性信任关系,缓解了数据稀疏性的同时获得了更准确的近邻用户.(2)本文不仅考虑了其他算法使用的标签-景点关系,还进一步考虑了标签-标签关系和用户-标签关系,将用户对景点的兴趣偏好分解成用户对标签的偏好,有效地解决了在新城市中无法获取用户兴趣偏好的问题,提高了推荐准确性.(3)当新用户或新项目进入系统时,通过利用用户信任关系和标签偏好,在一定程度上缓解了冷启动问题.
5 结论与展望
现有的景点推荐算法在考虑用户间关系时主要利用了社交网络或好友关系获取用户间直接信任,忽视了用户隐性信任和信任传递问题;而在考虑用户和景点关系时主要从用户评分和天气、时间等上下文信息计算用户相似性进行推荐,当用户处于新城市时由于缺乏用户历史记录无法做出准确推荐.针对这些问题,本文提出一种综合信任关系和标签偏好的景点推荐方法(STGT方法).首先结合用户评分行为和上下文信息挖掘用户隐性信任,构建信任网络,融合相似度和信任度做出推荐.然后通过全面考虑用户、景点和标签之间的关系,把用户的兴趣偏好分解成对不同景点标签的偏好,更准确地获取了这些代表用户长期兴趣的偏好,有效地缓解了数据稀疏性,在新城市问题中能做出更准确的推荐.通过在Flickr网站上收集的数据,设计了对比实验.实验结果表明本文提出的算法有效地提高了推荐准确度,在一定程度上缓解了冷启动和新城市问题.
未来的工作包括考虑用户间信任的动态变化,以及用户标签存在的同义、多义问题,标签本身存在的问题可能会影响推荐质量.此外,可以获取其他类型的旅游信息,如游记等,进一步挖掘用户兴趣,提高用户最近邻搜索精度.
