基于Filebeat自动收集Kubernetes日志的分析系统①
2018-09-17翟雅荣于金刚
翟雅荣,于金刚
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
日志是记录系统行为的一种方式,具有非常重要的作用.日志信息可作为系统排错和性能优化的依据;通过日志,可以有效的监控系统的运行状况,如性能信息、故障检测、入侵检测等;日志可以用于用户的行为信息分析,发现潜在商机;日志可以帮助开发人员找到bug的来源,修复漏洞.并且随着数据挖掘、大数据等技术的不断发展,数据也愈发凸显重要,日志作为数据分析的一大来源,日志收集分析系统也愈发凸显重要.但随着互联网、大数据等快速发展,系统应用越来越复杂,规模越来越大,系统产生的日志急剧增加[1],给日志的收集、存储和分析带来很多挑战.
传统的日志存储在本机磁盘上,查看日志时需要登陆到宿主机上,用grep等工具进行查看分析,这种方式的效率极低,并且随着机器数量的增多,排查问题所花费的时间随之增加,并且这种方式很难进行比较复杂的分析,不能充分利用起日志的价值.随着Docker容器技术的不断发展,Docker容器技术的应用范围也越来越广.与传统的主机、虚拟机技术相比,Docker容器产生的日志分散在不同相互隔离的容器中,并且事先并不知道容器应用部署在哪一台机器上,给日志的收集带来一定的挑战,这也迫切需要一种方式来收集存储日志.容器具有即用即销的特点,容器中的存储会随着容器的关闭而被删除,虽然可以将日志文件挂载到宿主机上,但是容器会经常漂移,给日志的统一查看带来挑战.本文采用Kubernetes实现容器管理、服务发现及调度,使用主流的开源日志收集系统ELK实现日志的存储、查看,并通过缓存技术Redis消息队列提供可靠的数据传输,将分散在不同容器中的日志统一收集存储,提高运维人员的工作效率.
1 相关技术
1.1 Docker技术
Docker[2]是一个开源基于Linux操作系统虚拟化技术的高级容器引擎,可以将应用及开发环境打包到一个可移植的容器中.为了避免启动和维护虚拟机的开销,Docker使用Linux内核资源隔离技术(如cgroups、namespace)、联合文件系统(如aufs)等技术实现多个容器在一个Linux内核中相互独立[3].与传统的虚拟机需要虚拟出一个完整的操作系统相比,Docker是一种细粒度、轻量级的虚拟化技术,属于操作系统级虚拟化.图1显示Docker容器技术与虚拟机的原理对比.
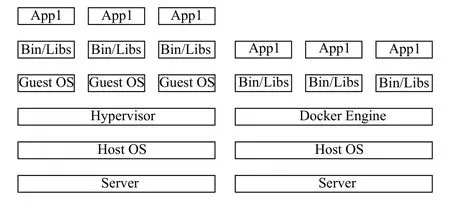
图1 Docker容器与虚拟机的原理对比
Docker是秒级启动,而虚拟机的启动速度是分钟级;Docker容器作为一种轻量级的虚拟技术,其单机支持上千容器,而虚拟机由于需要虚拟出完整的操作系统,单机一般只支持几十个;Docker资源利用率比虚拟机高,资源占用少[4].
1.2 Kubernetes技术
Kubernetes(K8s)[5]是Goolge开源的软件,提供了一个完备的分布式系统支撑平台,是Docker生态圈中的重要一员.它提供了强大的故障发现、负载均衡、自我修复、滚动升级、资源调度管理、自动扩缩容等多个功能,具备的完善的集群管理的能力.并且其对现有的平台侵入性较小,现有平台容易升级改造迁移到Kubernetes上.
Kubernetes集群由 Master节点和Node节点组成,其中Master节点运行集群管理方面的进程(kubeapiserver、kuber-controller-manager和 kube-scheduler),负责实现整个集群的Pod调度、弹性伸缩、安全控制、资源管理等.Node节点是集群的工作节点,主要负责运行真正的应用程序,通过运行kublete、kubeproxy服务进程,来负责Pod的创建、启动、监控等,kube-proxy还提供了负载均衡.与传统的容器相比,Pod是管理的最小运行单元,而并非容器.图2显示Kubernetes的系统架构图.
1.3 相关研究
目前,针对Kubernetes的日志收集提出了多种方案.Kubernetes官方推荐采用的方案是Flunetd +Elasticsearch + Kibana,通过使用DaemonSet的方式在每一个Node节点上启动一个Flunetd来收集日志文件(包括/var/log、/var/lib/docker/containers),常见的收集器还有Filebeat、Logstash;陈坚娟等人[6]提出Logstash agent + Kafka + Logstash + Elasticsearch +Kibana结构,并将容器产生的日志挂载到宿主机的指定目录上,通过Node上启动的Logstash agent 来收集指定目录及/var/lib/docker目录下的日志;罗东锋等人[7]提出了基于Docker的大规模日志采集与分析系统,主要使用Flunetd + Kafka + Flunetd + Elasticsearch +Kibana实现大规模日志采集;周德永等人[8]提出了在Node节点上部署Logspout收集日志,并Logstash Shipper转发送容器日志,后转发给Redis做缓冲,再有Logstash转发至Elasticsearch进行存储,Kibana进行可视化.
Filebeat具有占用内存较低,性价比较高的特点,本文采用Filebeat作为日志文件的采集器,并针对两种输出方式的日志文件采用不同的收集方式,输出到控制台的日志文件,这类文件主要保存在/var/lib/docker/containers/目录下,/var/log/container软链接到该目录下,该日志文件主要通过在Node节点上部署Filebeat进行收集;未输出到控制台的日志文件,这类文件主要根据业务需求保存在不同的目录下,并且日志文件的格式也不尽相同,此类日志文件通过在每一个Pod节点部署Filebeat来进行日志收集,此方法可解决传统日志文件通过挂载到宿主机上进行收集时需要统一日志文件收集的规则、目录和输出方式的缺点.
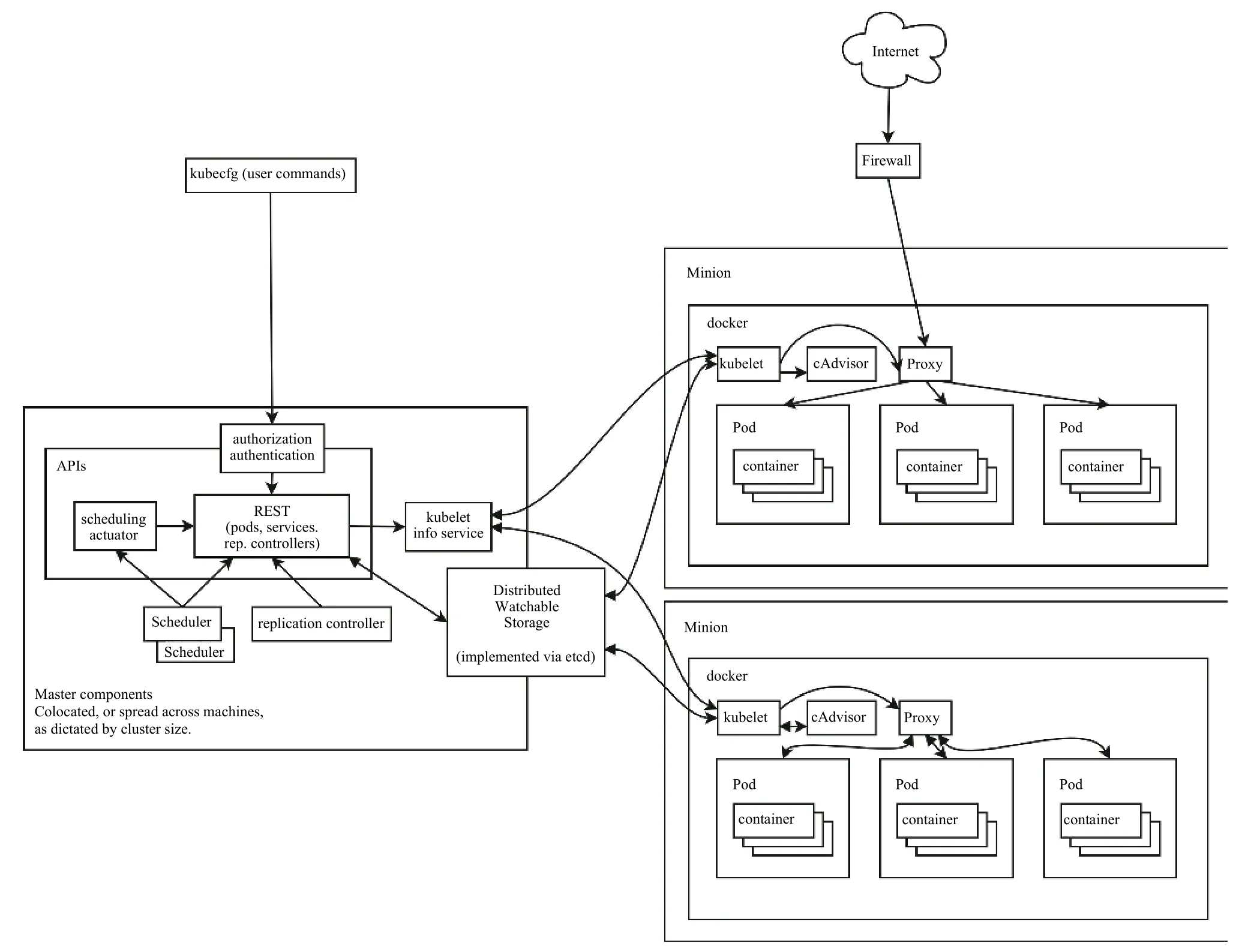
图2 Kubernetes系统架构
2 系统架构
该系统的整个架构(如图3)从左到右共分为5层,第1层数据采集层,主要负责采集业务集群中的日志,并将日志发送给Redis服务中,采用的日志收集器为Filebeat;第2层为数据缓存层,该层使用Redis作为缓存;第3层为数据转发层,该层主要负责去Redis集群拉数据,转发到Elasticsearch;第4层为数据存储层,该层使用Elasticsearch把收到的数据进行存储,写入磁盘;第5层主要使用Kibana处理数据检索请求,并进行数据展示[7].

图3 日志分析系统架构图
2.1 数据采集层
数据采集层主要负责采集各个服务器上不同的文件,进行预处理后将数据传送到数据缓存层.目前主流的采集器主要有Logstash、Fluentd、Filebeat,本文采用Filebeat作为主要的采集器,Filebeat相比与Logstash、Fluentd的内存使用较低,性价比较高.

表1 Logstash、Fluentd、Filebeat对比
本文采用Kubernetes来实现容器管理、服务发现及调度,使用Filebeat作为采集器来采集日志文件.日志文件按照输出的不同可以分为两种:1)输出到控制台的日志文件.这类文件主要保存在/var/log/containers/目录下;2)应用日志(未输出到控制台的日志)输出到指定文件下的文件.本文针对两种不同的日志文件,使用不同的方式.如图4为日志采集层.
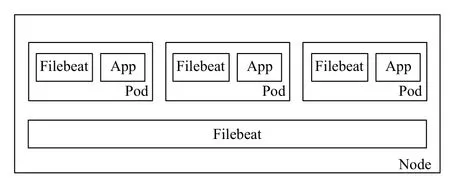
图4 日志采集层
输出到控制台的日志文件,这类文件都会保存在/var/lib/docker/containers/目录下,以*-json.log的命名,/var/log/containers软链接到该目录下.该类日志文件主要使用每个Node节点上个运行的一个Filebeat容器进行日志采集,然后汇总到Redis缓存中.本文采用以DaemonSet的方式将Filebeat作为Kubernetes的一种资源对象运行在Node节点上.
针对未输出到控制台的日志文件,这些文件主要存储在容器中的指定目录下,由于不同应用产生的日志文件格式不同,位置不同,如果采用将Pod的日志挂载到宿主机上,进行日志收集,需要统一日志收集规则、目录和输出方式,而各个文件各有不同,同时为了高扩展性、方便维护和升级,本文针对这类文件采用以每个Pod为单位进行日志收集.用户也可根据实际需求,来决定是否需要在Pod中使用Filebeat.
2.2 数据缓存层
为了防止发送和接收速率不同而造成数据丢失问题,在数据采集层和数据转发层之间搭建了消息队列,起到缓存作用.Redis[9]是一个开源、高性能、基于内存的键值对数据库,支持数据持久化和订阅发布机制等高级特性,能够满足本系统的要求.为提高系统的性能和可靠性,该层使用Redis消息队列作为缓存.
2.3 数据转发层
数据转发层作为Redis队列的消费者,从Redis队列中拉取消息并转发到Elasticsearch数据存储层进行处理.本文采用Logstash实现日志的拉取、处理、转发.由于日志中存在字段不完整、格式不一致或者噪声数据,为了降低这些对数据存储带来的冲击,同时提高数据的质量,在数据转发层需要对数据进行预处理,使数据统一格式,过滤掉噪声数据等.
输出到控制台的的日志文件,/var/log/containers/*-*-*_*_*.log代表的命名规则为:podName_namespace_deploymentName-containerID.log,针对日志文件名称解析出deploymentName、podName、containerID、namespace字段,以下是Logstash部分配置信息:


2.4 数据存储层
数据存储层使用Elasticsearch集群,数据转发层将日志逐条插入到数据存储层的Elasticsearch集群中.Elasticsearch[10]是一个实时分布式搜索和分析引擎,基于Apache Lucene(TM)的开源搜索引擎,使用Lucene作为实现所有索引和搜索的功能,它通过简单的RESTful API来隐藏Lucene的复杂性,使全文搜索变得简单.
2.5 数据检索和展示层
Kibana是开源的数据分析和图像化展示的平台.Kibana基于Apache License2.0 开源协议,可以对Elasticsearch索引中存储的数据进行搜索、分析、查看,可以进行数据分析和统计,并且可以绘制各种图表展示结果.Kibana支持布尔运算符、通配符和字段筛选进行模糊匹配,并且其提供了Web界面,方便用户查看结果.
3 实验测试
本文重点验证系统整体的有效性.通过部署在同一局域网的5台PC机搭建集群进行测试.每台PC机的硬件换件为主频3.1 GHz的四核CPU、内存4 GB、磁盘200 GB,软件环境为CentOS 7.2(64 bit)、Elasticsearch 6.0.0、Kibana 6.0.0、Filebeat 6.0.0、Redis、Kubernetes 1.6.其中1台作为Kubernetes的Master节点,3台作为Kubernetes的Node节点,Kubernetes的集群部署信息如表2.图5、图6为实验结果.

表2 Kubernetes集群部署信息
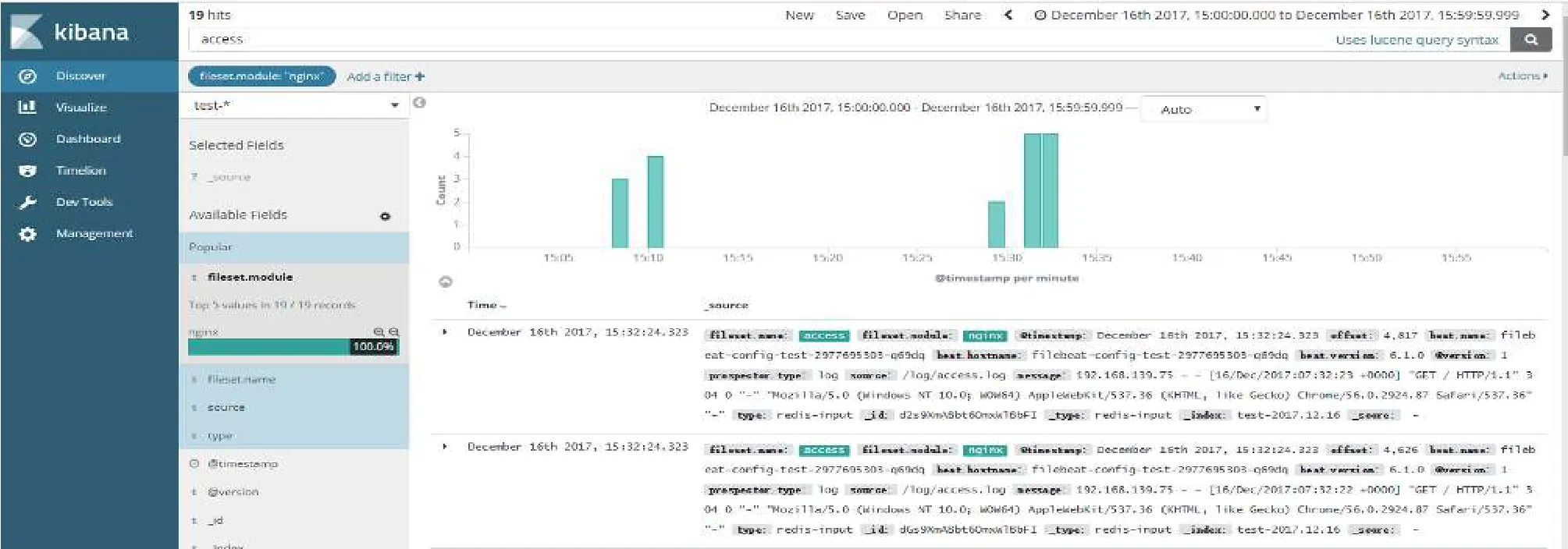
图5 未输出到控制台日志
4 结论
本文将零散的日志统一收集存储,并采用Kubernetes实现容器管理、服务发现及调度,使用主流的开源日志收集系统ELK实现日志的存储、查看,并通过缓存技术Redis消息队列提供可靠的数据传输,提高运维人员的工作效率.本系统可实现实时高效收集日志、处理分析,并进行可视化展示.由于使用Kubernetes作为容器的管理工具,可实现快速部署、自动扩缩容、资源管理等.本系统不仅解决了日志的统一收集,针对不同的日志文件采用不同的收集策略,用户灵活配置,同时也解决了容器的即用即销造成的漂移问题.下一步 工作将对采集到的日志进行挖掘,发现有价值的信息.

图6 输出到控制台日志
