基于Spark的油田应用日志行为分析系统①
2018-09-17陈雷鸣张伟光李翛然李宁宁
陈雷鸣,张伟光,李翛然,李宁宁
(中国石油大学(华东)计算机与通信工程学院,青岛 266580)
随着油田信息化、智能化建设的不断加快,各类IT系统的在企业中广泛应用.某油田现有超过一千套业务系统分别由各级单位独立运维管理.在这些业务系统给企业提供便捷服务的同时,如何对这些业务进行监控分析和安全评估上却面临难题.由于油田现有的应用系统数量庞大、类型繁杂、开发技术多样、部署分散,如何以最小的切入方式完成对这些应用的运行状况和安全状况的评估成为企业关注的重要问题.由于这些应用系统和网站每天都会产生大量的日志数据,这些日志中包括用户的访问信息和应用安全状况等信息.通过分析应用日志数据可以评估应用的使用情况、应用运行的安全状况,进而为各企业信息决策提供重要依据.随着各类应用系统的规模迅速扩大导致应用所产生的日志数据呈爆炸式增长,若继续采用传统的数据储存和处理方式将无法及时评估出各类业务运行情况和安全状况.
针对这一难题,主流的海量日志处理方案是借助于大数据计算框架提供的分布式处理技术.大数据技术的发展大致可分为以下阶段:第一阶段是基于Hadoop提供的MapReduce计算框架做分析.由于MapReduce的编程机制需要严格按照Map和Reduce两个阶段,因此缺少了程序设计的灵活性[1,2].然后是Pig[3]数据分析程序以及Hive[4]数据仓库等工具的出现.这类工具简化了MapReduce的编程过程,然而在任务执行时依然需要先转换为MapReduce作业任务然后再交给Hadoop执行[5].由于Hadoop在处理大批量数据时,需要把中间结果缓存到磁盘上,这一过程受限于磁盘IO速率,因此严重影响分析效率.针对这一问题,基于内存计算的批处理框架Spark应运而生,由于Spark将数据直接保存在内存中进行多次迭代操作[6],从而不再从磁盘中重复的读写数据源,因此具有更快的处理速度.本文基于Spark内存计算框架来代替MapReduce计算框架来提高计算速率,并基于Spark提供的各类功能模块设计数据分析算法来完成应用日志数据的预处理和行为分析.
1 Spark数据分析平台
Apache Spark是由加州大学伯克利分校AMP实验室开发的分布式并行计算框架.Spark支持复杂的机器学习、图计算和实时流处理等功能模块[7].如图1所示为Spark生态圈,从下至上依次为:数据持久层、资源调度层、Spark核心计算层、Spark主要功能组件.其中数据持久层:包括分布式文件系统HDFS和分布式数据库HBase、Cassandra.资源调度层:为Spark提供统一的资源调度和管理,目前主流的资源调度组件为Yarn和Mesos.
Spark 核心层:包含Spark的基本功能,定义了RDD的API和基本操作,Spark其它的功能模块都是构建在RDD和Spark Core之上的.最后一层为Spark主要的功能组件包括:用于对流数据实时处理的Spark Streaming、用于机器学习的算法库MLlib、用于图操作的算法工具集合GraphX和用于在内存数据集上提供查询功能的Spark SQL.本文基于Spark 提供的基本算子函数操先对日志数据进行预处理并利用 Spark SQL模块对预处理后的数据进行指标分析.
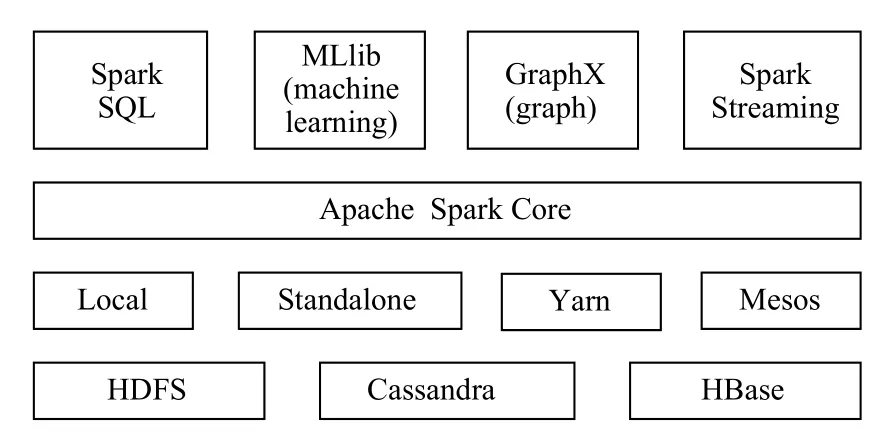
图1 Spark生态圈
2 系统架构设计
根据油田应用系统部署分散的特点,设计应用行为分析平台架构如图2所示.应用行为分析平台主要由数据收集层、数据存储层、数据处理层、数据可视化层、可视化管理调度平台5部分组成.
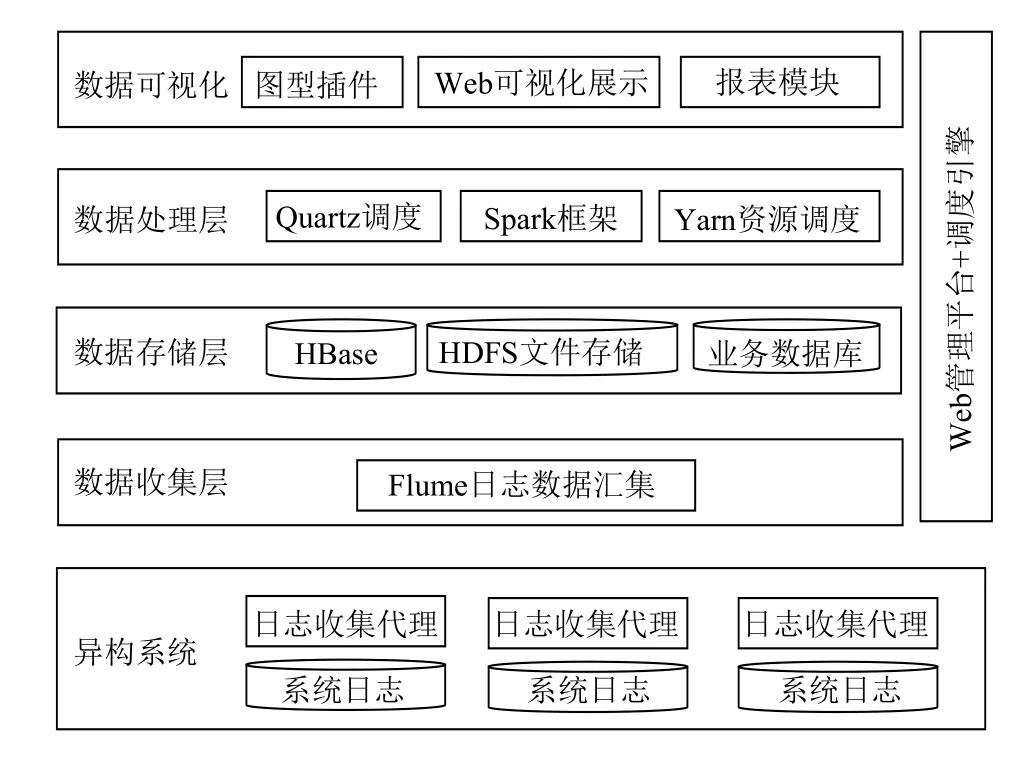
图2 应用日志行为分析平台架构图
数据收集层:用于将分散在各主机应用日志数据集中收集,该模块基于Flume日志收集框架设计完成.
数据储存层:日志文件储存在基于HDFS的文件储存系统上,基于HBase储存经预处理分析后的结构化数据,使用MariaDB作为业务数据库,用于储存分析的最终结果和系统业务数据.
数据处理层:基于Quartz任务调度框架[8]来完成各类任务的定时执行;基于Yarn来完成集群环境下计算资源的分配和Spark任务调度.基于Spark计算框架设计数据的预处理和数据分析算法.
数据可视化层:用于分析结果的图表的可视化展示.其中数据的图形化展示基于Echarts可视化插件来完成,图表的数据通过报表程序模块来完成.
3 系统设计与实现
应用日志行为分析平台需要完成以下功能:系统的可视化管理、各类计算框架的集成管理、分析算法的调度管理,因此需要设计以下三个主要的模块:基于Web管理平台、调度引擎和算法数据库.
Web管理平台:向用户提供交互功能和分析结果的可视化展示,该模块基于SSM框架完成,用于分析任务的管理、分析错误告警信息的管理、算法库管理、各类应用信息的管理以及与平台业务相关功能.
调度引擎:该模块基于Apache Felix[9]的OSGI框架开发完成,主要完成不同数据源的数据信息拉取储存、数据处理分析模块的调度、分析任务定时执行,该模块主要利用各类大数据框架提供的API封装成相应的功能模块集成开发完成.
算法信息库:用于储存与日志行为分析的算法,算法主要基于Java编程语言开发,每个算法为单独jar包,由调度引擎选择并提交到Spark集群执行.行为分析系统各类组件的调度流程为:
第一步:通过在应用服务器上安装日志收集代理(Flume Agent),将分散在各应用服务器的日志文件定时汇集到日志储存服务器,然后经Flume框架上传到HDFS文件储存系统中规划的文件夹.
第二步:由调度引擎执行定时任务、调度各类框架.并由调度引擎选取各类算法提交给Spark集群.
第三步:Spark集群从HDFS拉取数据,首先对日志数据预处理,并将结果反馈给调度引擎.若处理过程无异常,则将分析结果储存到HBase数据库.
第四步:由调度引擎依次进行各类行为分析算法的调度,并将分析结果储存到相关数据库中.
3.1 日志数据的预处理
油田应用日志的特点为:业务量较小的应用每天生成一个日志文件,大业务量的应用日志可能会被切分成多个日志文件(在分析处理时若应用每天产生多个日志文件则逻辑上当作一个文件处理).分析系统需要处理前一天所有应用产生的日志文件.因此调度引擎模块会在每天0点开始执行总的分析任务.每分析一个日志文件就执行一次预处理算法任务.在日志的预处理分析顺序上,调度引擎会根据传输到HDFS的日志文件顺序,按照先来先服务的原则生成任务执行列表,然后依次对各日志进行预处理分析.
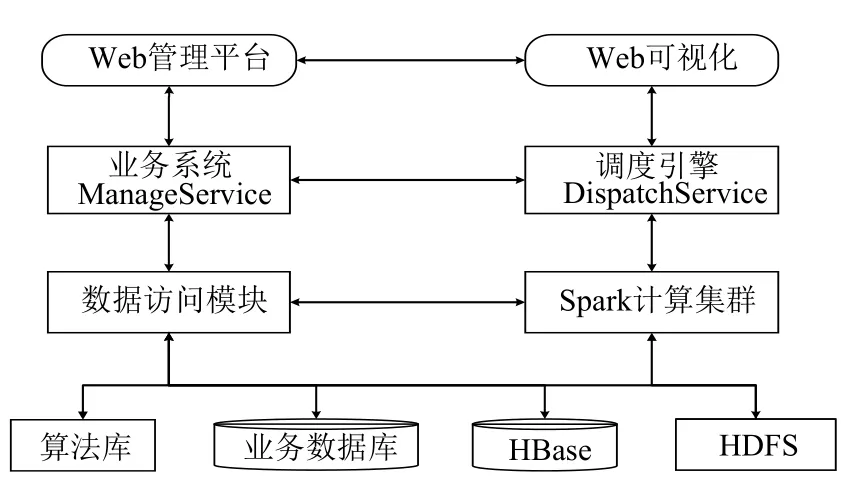
图3 系统模块调度流程图
由于油田在部署各类应用系统时使用的服务软件种类繁多,主流的服务软件包括:iis、tomcat、apache、nginx等.不同类型的服务软件产生的日志类型不一样;同类型的服务软件可能有多个版本.因此需要设计多种分析规则来处理不同类型的日志.设计的原则为:面向同类型日志分别设计相应的处理规则.其中应用日志预处理分析流程如图4所示.

图4 应用日志预处理分析流程
结合各类应用特点和部署环境等因素,数据预处理过程可分为以下阶段:数据清洗、用户识别、会话识别、数据格式化[10].数据清洗阶段主要完成对残缺信息的过滤(字段缺失、信息缺失)、冗余信息的过滤(主要过滤掉与请求无关的静态数据文件如JS文件、CSS文件、图片数据等)、核心字段的提取.然后根据客户端IP地址将访问信息按照时间先后顺序分组排序.在用户识别阶段,采用的是IP和客户端组合方式来识别.分析规则为:不同的IP为不同用户,同一IP、不同客户端为不同用户.在会话识别阶段,采用的是基于固定阀值会话识别算法(固定阈值为 30 min)[11].为了便于下一阶段进行应用行为分析,需要对多种日志类型预处理后的结果各字段进行数据格式统一,最后将处理后的数据储存到HBase数据库中.
预处理算法的设计主要基于Spark Core模块提供的操作RDD的算子实现.RDD是Spark计算框架提供的分布式数据架构及弹性数据集,它会在集群环境中的多个节点进行数据分区,但是在逻辑上可看成一个分布式数组[12].预处理算法的设计原理:主要利用Spark提供的各类算子设计相应函数,从而实现对各类RDD的操作;Spark最终会将者一系列对RDD的操作翻译成有向无环图(DAG)的形式进行调度和分布式任务分发[13];最终整个执行过程会形成预处理分析算法.根据分析流程设计分析预处理算法:首先日志文件数据会由spark读取加载到内存,并将源数据转变成分布式数据集;然后按照各阶段目标,设计并实现相应算法模块或者基于各类算子设计相应的函数实现对已有的RDD进行转变操作.应用日志预处理算法主要的分析步骤如算法1.

算法1.数据预处理算法1)根据日志类型选取处理方法[A|B|C…].2)利用textfile()函数将日志文件加载到内存,并转换为可操作的RDD数据集.3)调用字段检查函数对数据字段完整性检查,对字段完整的数据利用map()算子实现数据类型转换.4)使用filter()算子对url字段数据过滤,去除与访问请求无关的数据以及自动加载的静态资源数据等.5)利用map()算子提取与分析目标相关的核心字段.6)调用设备解析算法模块对agent字段进行解析,解析出客户端的设备、操作系统、浏览类型版本等信息.7)使用sortByKey()算子按照IP、时间将访问记录排序.8)调用用户识别函数对数据处理.9)基于固定时间间隔会话识别算法,划分用户会话{cuserID|(pid,time,url1,url2…)}.11)调用map()算子对数据格式进行归一转换.12)调用数据储存模块将数据储存到HBase数据库.
3.2 应用系统的安全分析与行为分析
油田日志的分析包括应用系统的安全性分析和行为分析.在安全分析方面,由于被攻击的应用日志记录中会包含了两类请求:正常访问请求和恶意攻击请求,本文主要通过匹配记录中的恶意访问信息的特征来判断应用系统是否被攻击.在安全检测方法上采用基于特征方式的检查方法,该方法的实现主要借助于预先设计攻击特征库和基于RDD算子设计的函数模块.其中攻击特征库是依据各类攻击特征设计正则表达式,从而匹配出可能存在的攻击类型[14].基于RDD算子设计的函数模块主要在集群环境下通过Spark并发处理机制来提高日志安全分析检索速率.
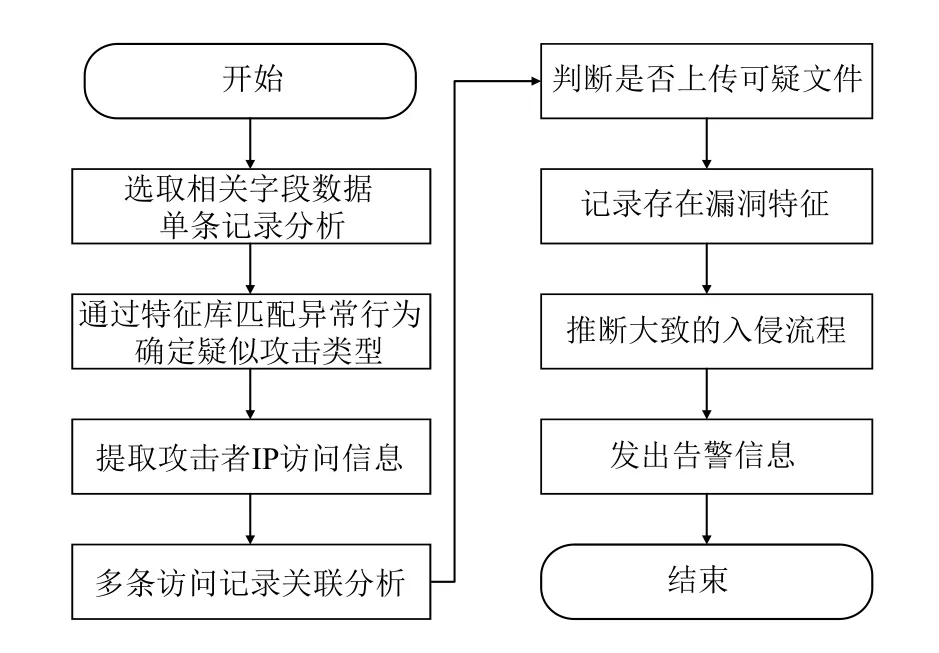
图5 日志安全分析流程
基于RDD算子的安全分析算法主要步骤如算法2.

算法2.应用日志安全检查算法1)利用map()算子提取相关字段进行单条数据分析.2)调用攻击特征库,通过正则表达式完成攻击行为匹配,并确定疑似攻击类型.3)利用sortByKey()算子重现攻击者访问行为轨迹.4)利用union()算子进行多条记录关联分析.5)提取post字段,利用filter()算子判断可疑文件.6)记录漏洞特征,推断大致入侵流程并发出告警信息.
在油田应用行为分析方面,主要是在基于HBase的键值存储模型上运行各类分析算法.由于油田在规划内部网络时会预留一部分IP地址作为应用服务地址,因此可以根据IP+端口(appID)来作为应用的唯一标识,根据分析指标需求设计HBase表存储结构包括:一个唯一标识的行健(RowKey)和两个信息列簇.其中行健由:应用ID、访问时间、用户IP三者的组合来标识;两个列簇分别为用于描述用户设备信息和请求访问结果信息,其中每个列簇又包括多个列.应用行为分析存储结构详细描述如表1.

表1 HBase键值表结构
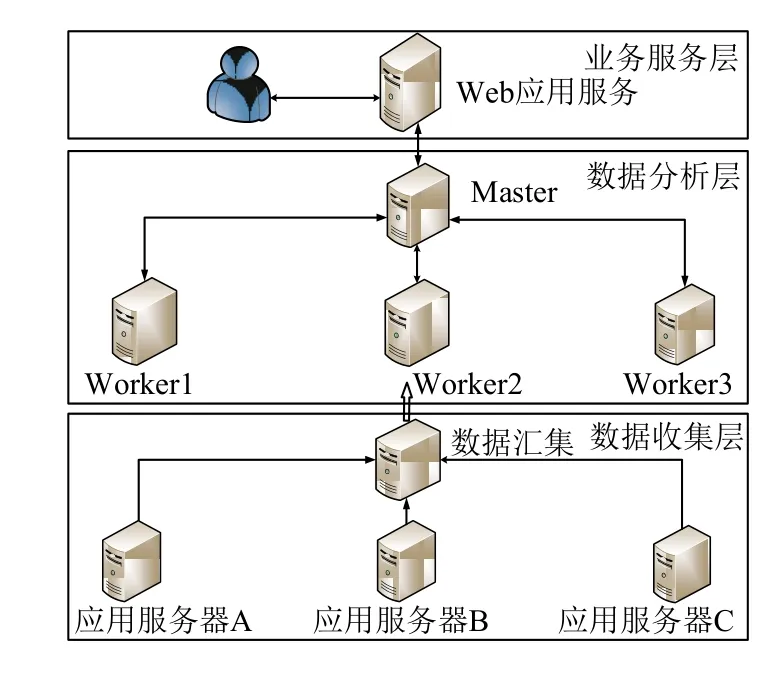
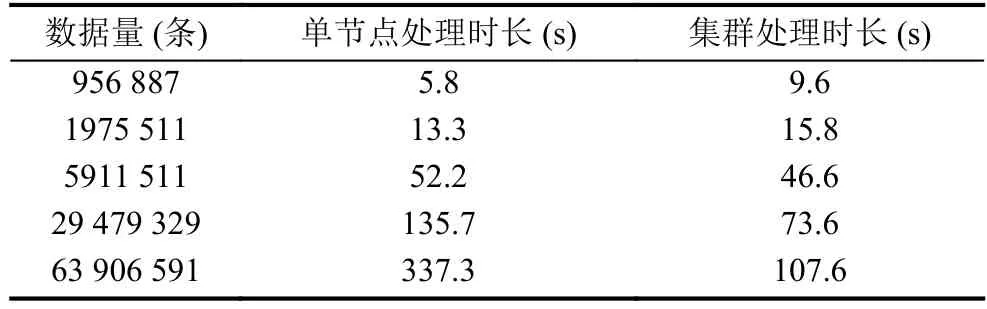
在应用日志的行为分析算法方面,主要基于Spark计算框架中的Spark SQL模块设计完成,Spark SQL向用户提供了在大数据集上的类SQL查询功能,同时还支持将原有持久化储存数据迁移到Spark环境下进行分析[15].Spark SQL的分析的核心模块是DataFrame.DataFrame是一个以命名列方式组织的分布式数据集.它类似于关系型数据库中的一张表.DataFrame可以由结构化数据、现存在的RDD或者从外部的关系数据库导入并转换而来[16].其中DataFrame包括:用于描述列字段的集合Schema和行数据集DataSet 根据油田管理评估要求需要统计的应用行为指标包括:应用每小时的访问量、应用运行安全状况、各模块的使用量、应用模块异常信息、使用次数用户排名等27个行为指标.由于HBase根据rowkey来检索数据并且支持以字符串匹配方式的扫描方法.因此将时间和IP作为查询条件,可以在各类应用间进行用户访问行为的关联分析,进而描绘出用户每天在各类应用的停留时间和访问轨迹并推断出用户访问喜好. 本文在实现应用行为分析算法时,将这些应用统计指标封装在一个算法内,因此执行一次算法就可统计出所有应用指标.在Spark执行行为分析时需要确定数据源和具体的分析算法:其中算法选取由调度引擎来完成并提交给Spark集群来;数据源来自于上一阶段的数据预处理算法处理后储存在HBase中的结构化数据,需要调度引擎将要分析数据的起始行键提交给Spark集群.Spark集群根据HBase起始行键拉取数据并执行指定算法程序,完成处理后返回处理结果.由于每个分析算法需要完成多个分析指标的统计,因此需要根据分析指标制作多个DataFrame数据集.因为在数据量过大时,制作DataFrame数据集非常耗时.因此制作数据集时要尽可能满足多个查询需求,以减少重复制作数据集的处理时耗.算法流程如下图6所示,其中每一个分支流程对应一个分析指标. 每个行为指标具体的分析流程如下:首先选取相应的字段并对字段数据进行格式转换、数据规约,该过程主要借助于Spark提供的算子函数完成;然后将RDD数据集转换成DataSet 图6 分析算法流程图 图7 行为指标分析流程图 系统平台的主要由三个部分组成:数据收集层、数据分析层、Web业务层.依据实际生产场景,系统开发环境部署规划如下,数据收集层由1台日志储存服务器组成,用于部署Flume日志收集框架.数据分析平台是由1台主机点和3台计算节点组成计算集群,各节点分别搭建Hadoop服务集群、Spark服务集群、HBase储存集群,并在主节点搭建调度引擎程序.业务层由一台Web服务器组成,用于部署业务管理平台和业务数据库.系统具体部署规划如图8所示. 实验分析聚焦在数据分析层上,主要统计各类算法的分析耗时,本文的实验环境是由4台节点组成的集群环境,日志文件储存在HDFS上,基于Spark框架设计分析算法完成数据的分析,基于HBase储存分析数据,并将Spark任务直接提交到Yarn上,由Yarn完成资源分配和Spark任务调度.其中各节点的环境信息和部署组件信息如表2所示. 图8 系统部署图 表2 Spark 集群运行环境 实验分别在单节点环境和四节点组成的集群环境下测试了2个典型算法的耗时,测试的算法为:日志文本数据的预处理算法和应用行为指标分析算法A(该算法主要用于统计IIS类型应用日志的行为指标,包括统计每小时IP量、总UV量、每小时PV、总PV量、各模块的访问量、TOPN用户等27个行为指标).日志预处理算法选取了某油田企业内部具有代表性的应用日志数据,日志数据格式为IIS W3C格式.选取并整理的单个日志数据大小依次为106 MB、511 MB、1.1 GB、5.1 GB、9.8 GB、20 GB.实验对比结果如图9所示. 图9 预处理算法时长对比图 由实验结果可以看出,当数据量较小时,单节点的处理时长较短;当数据容量大于5 GB时,集群环境下的处理时长远小于单节点的处理时长. 算法A的实验数据为储存在HBase中的结构化数据,分别选取的数据集分别为:956 887条、1975 511条、5911 511条、29 479 329条、63 906 591条数据.这里统计数据算法A的耗时为从数据加载到内存到预处理数据分析完成的时间(不包括将数据写回数据库中的时间),结果如表3.该算法的时间消耗主要在于:制作DataFrame数据集的耗时和运行查询SQL的耗时,算法A完成27个指标的统计,需要制作9个DataFrame数据集,运行了35次SQL查询. 表3 算法A处理时长对比 从实验结果可以看出,当数据集增长到一定程度,采用集群环境的处理耗时远低于单机处理耗时. 从两个分析算法的耗时统计可以得出:当数据量大小在单节点处理能力范围内,单节点处理时长要小于集群环境下处理时长;若数据量过大,采用集群环境的处理耗时要小.这是由于集群环境下涉及到数据的分片,任务间的通信,代码序列化分发,如果数据储存不在本地,还会涉及到数据的移动问题,此外处理时长还受主机磁盘IO传输速率、网络带宽的传输速率的影响,这些多方面的因素都会影响处理时长.因此集群环境在处理大批量数据时才会发挥优势. 面对油田应用部署分散、种类繁多、数量庞大的复杂场景.本文借助于各类主流的大数据处理框架实现对海量数据收集和储存;在数据处理分析方面,本文基于Spark计算框架设计了应用日志行为分析系统,并设计了应用的安全状况分析和行为指标分析的算法;此外为了方便运维人员使用该系统,又基于Web设计了可视化的管理平台实现了各类框架的集成与管理.该系统解决了油田进行海量应用数据分析的滞后性难题;为油田迅速评估各类应用系统的运行状况和安全状况提供了决策依据;并为油田快捷高效的管理各类业务系统带来了一系列巨大优势.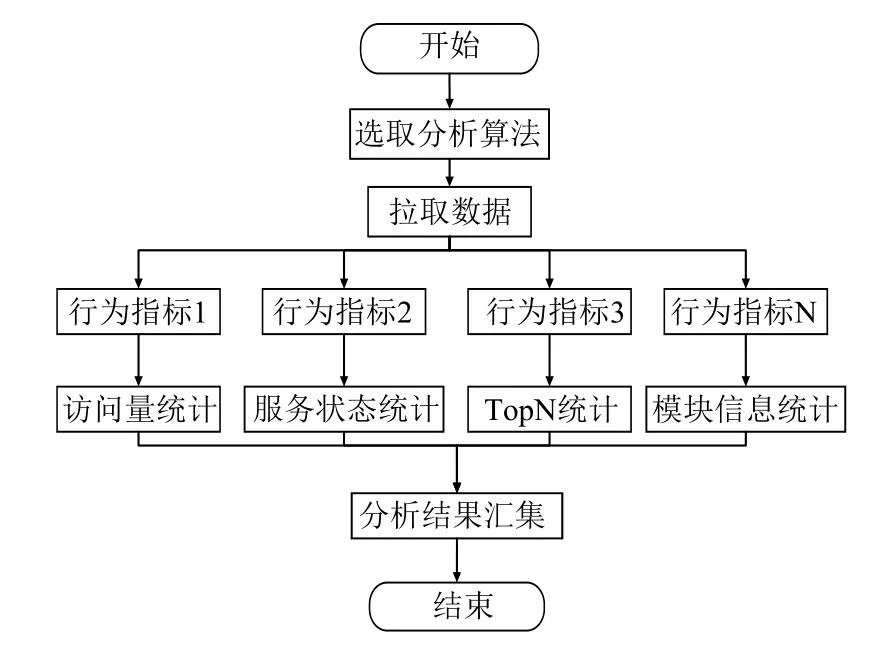

4 系统开发环境及实验分析
4.1 系统平台部署
4.2 实验结果分析


5 结论
