青海湖区域水体识别系统设计①
2018-09-17薛祥祥
薛祥祥,罗 泽
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院大学,北京 100049)
青海湖区域是我国重要的生态保护基地,青海湖国家级自然保护区是以野生水鸟及其栖息地保护为主要任务的保护区[1].近年来,伴随着人类的生产活动,以及气候的变化,青海湖湖泊会在一定程度上发生变化.为了能够更好的进行青海湖生态保护,及时了解青海湖水体变化,如何能够自动快速的进行青海湖水体识别成为研究的关键.
遥感图像水体识别是指通过一定的方法对遥感图像数据进行处理分析,以期能够识别出遥感图像中的水体.近年来,针对水体识别问题,相关研究人员和学者提出了很多理论和方法.目前主要分为两类,第一类方法主要通过发现单个波段或多个波段之间的关系,通过设定阈值来实现[2–5];第二类方法是指通过机器学习算法,进行训练模型来实现[6–8].上述方法目前均在单机环境下进行水体的提取,同时又存在耗时,普适性不强,自动化程度较低等不足[9,10].
2013年2月,Landsat8卫星在美国加州发射,经过100天测试运行成功之后,开始向地面提供遥感影像,是目前唯一一颗在轨运行的Landsat系列卫星[11].随着Landsat8陆地资源卫星的发射,我们可以更方便的获取更高精度的青海湖区域遥感影像数据.但随着时间的推移,数据量将日益增多,在大数据量的情况下,耗时,自动化程度低等问题将更加突出.
针对目前面临的上述问题,本文采用分布式处理框架进行解决,搭建水体识别系统,实现水体识别自动化执行.其主要包括基于Hadoop平台实现遥感数据的存储和处理,基于Spark平台实现青海湖区域水体的识别.最后通过实验,验证系统的有效性.
1 系统概述
本文通过Hadoop平台和Spark平台实现青海湖水体识别系统,其整体架构图如图1所示.
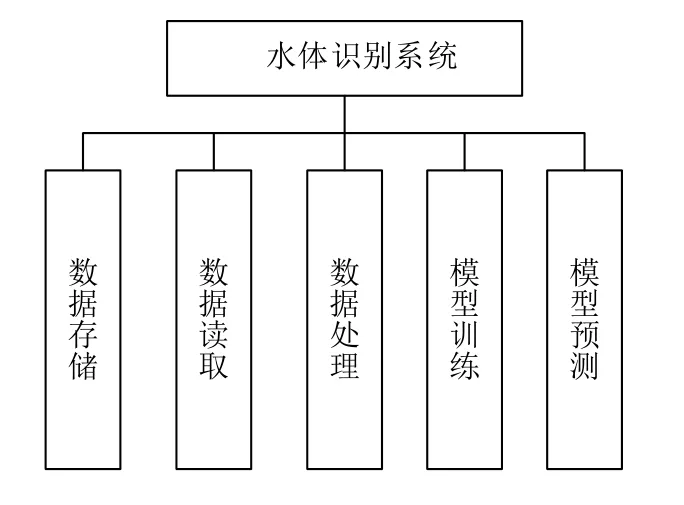
图1 系统架构图
本系统的主要模块功能为:(1)数据存储.系统使用HDFS进行数据存储,用户首先将本地遥感图像数据上传至HDFS,并存储到相应的文件夹下.(2)数据读取.本系统利用GDAL来实现Hadoop平台对遥感影像的数据读取,通过重写Hadoop的输入输出格式进行实现.(3)数据处理.通过第二步的读取,可以获得遥感影像数据,之后自定义MapReduce程序,将原始数据转换为libSVM格式数据,并输出到HDFS相应的文件夹下,提供给Spark程序使用.(4)模型训练.本实验的算法模型采用逻辑斯谛回归算法.针对遥感影像上青海湖区域,人工选取水体和非水体样本,作为训练样本,并利用Spark MLlib进行训练,最后将模型进行持久化.(5)模型预测.第三步的输出结果为用户的待预测数据,通过读取该数据,并调用第四步的模型进行预预测,最终预测结果输出到HDFS上.
2 系统设计
2.1 遥感图像存储策略
Landsat8遥感图像较之前的Landsat系列影像,具有更高的精度,能够更好的对地物进行区分,并且对外开放,可以从官方网站下载获取,故本论文采用Landsat8遥感卫星图像作为实验数据.Landsat8遥感影像属于多光谱遥感图像,共包含11个波段,每个波段对应一幅遥感图像.亦即,对于同一个区域,遥感数据为11幅单波段遥感图像.根据遥感图像数据的特点,本文采用如下的方式来进行数据存储.
首先在HDFS根目录下创建image目录,并且之后上传的图像均在/image目录下.下载得到的青海湖区域某一天的遥感图像为一个文件夹,该文件夹中包含各个波段的遥感图像.本文在将本地文件夹数据上传至HDFS时,会首先获取该文件夹名称,并在HDFS上/image目录下创建与此文件夹名称相同的文件目录.然后依次将本地文件夹中的波段数据上传到HDFS对应的目录下.
2.2 Hadoop平台输入输出设计
Hadoop平台支持文本文件,SequenceFile等多种文件作为输入,同时也允许用户自定义输入输出格式[12,13].Hadoop平台默认的输入格式为textInputFormat,当进行数据读取时,会首先计算SplitSize大小,然后根据此数值对输入文件进行Split操作,最后每一个Split对应一个Map任务.按照Hadoop的默认输入格式,其Split的过程是按照文件大小来进行分片的,不会考虑数据之间的关系.而遥感影像数据属于栅格数据,如果按照默认方式进行切分,则会丢失数据之间的关系,无法读取到正确结果.所以,如何实现正确读取遥感数据,是问题解决的关键.
为了保证数据的完整性,本文对于输入的遥感图像不进行切片操作,一幅遥感影像作为一个Map任务进行数据读取.本文通过自定义MyInputFormat类和MyRecordReader类来实现该功能.MyInputFormat类重写isSplitable()方法,使其返回值为false,表明对输入数据不进行切片.MyRecordReader类的功能为获取Split数据,并将其转换为MapReduce的输入,该类重写initialize()nextKeyValue(),getCurrentKey(),getCurrentValue()四个方法来进行实现.
根据2.1中的存储策略,本文会将青海湖区域同一时刻的遥感数据存储到HDFS上同一文件夹下.在执行Hadoop程序时,程序的输入路径为该文件夹的路径.Hadoop程序会依次遍历该路径下的每一个文件,按照上述不分片处理的设计,则该文件夹下每个波段文件会分别对应一个Map任务进行处理.
Hadoop程序通过自定义输入格式来读取数据,之后通过MapReduce程序对数据进行处理,然后输出libSVM格式数据,以提供给Spark程序进行调用.根据系统需求,本文Hadoop程序输出格式采用默认输出格式,即 TextOutputFormat.
2.3 MapReduce程序设计
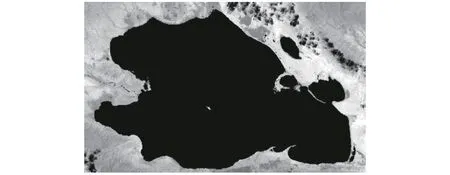
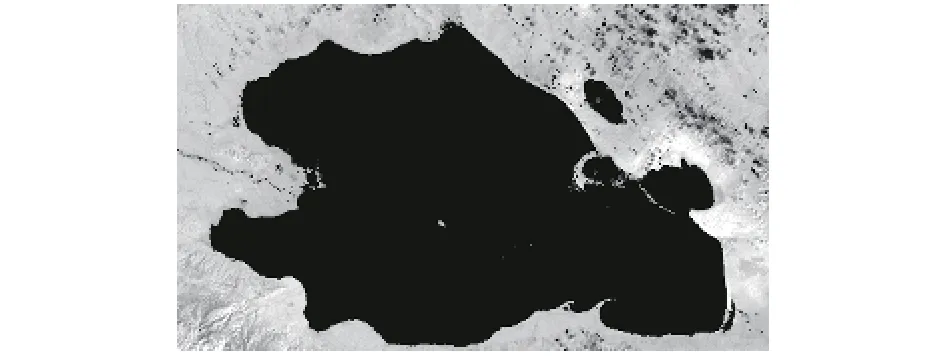
MapReduce是Hadoop框架的计算模型,可以完成海量数据的处理任务.其主要包含三个阶段,分别是Map阶段,Shuffle阶段和Reduce阶段.Map函数的输入为一个 图2 MapReduce执行原理图 本文MapReduce中,Map函数的输入key值为当前处理的文件名称,value为当前处理文件的二进制数据流.经过MapReduce处理,本文最终要得到由多个波段数据组成的libSVM格式数据.因此,本文采用如下MapReduce设计. Map函数输入的key值为当前处理文件的文件名称,value值为当前处理文件的二进制数据流.Map函数首先获取当前处理文件的波段号,然后通过GDAL进行数值读取,对每一个像素点进行输出.Map函数的输出key值为当前像素点的坐标,格式为:XSize.YSize,输出的value为当前波段号和该像素点的值,格式为“波段号:像素值”.具体转换过程如图3所示. 图3 Map函数转换图 Reduce函数输入的key值与map函数输出的key值相同,为当前像素点的坐标.输入的value值为该坐标下,各个波段的像素值组成的集合.Reduce函数会对集合中的数据进行排序,使其按照波段的大小顺序有序.Reduce函数输出的key值为像素点的坐标,输出的value为各个波段值的有序集合.最后设置Reduce函数输出的key值和value值之间用空格进行分隔,这样,通过MapReduce函数,即可得到libSVM格式数据.其具体的输入输出格式如下所示: 本文对遥感图像进行水体识别,其本质上属于二分类问题,要求算法能够准确判别出待预测数据为水体或非水体.本文采用Spark MLlib中逻辑归回算法来进行实现. 逻辑回归算法属于分类算法,广泛应用于二分类问题.该算法首先对数据进行线性拟合,而后通过Sigmoid函数进行映射,将预测结果值限定在0到1区间之内,通过设定阈值,从而实现分类.逻辑回归算法基于Spark平台,实现了并行化处理,并且基于内存计算,大大提高了模型训练和预测的速度. Landsat8卫星遥感影像数据共包含11个波段,根据遥感图像的光谱特征,其中第2波段到第7波段,对于水体的区分具有明显效果.故本文采用第2波段到第7波段这6个波段数据.遥感图像由一个个像元组成,本文在模型训练和模型预测中以像元为基本单位,每一个样本共7个维度,分别对应波段2到波段7像元的数值. 本文系统实现过程中,首先选取样本进行模型训练,并将此模型持久化存储到HDFS相应的目录下.之后,对于待识别的遥感影像数据,经过MapReduce计算转换为待预测数据后,直接调用此模型进行预测,并将预测结果输出到HDFS相应的目录下. 本文根据上述系统设计方法实现了基于大数据平台的水体识别系统.主要系统模块包括数据上传,数据读取,数据转换,模型训练,模型预测.通过系统测试,本文实现的水体识别系统能够自动完成遥感图像水体识别,且具有较高准确率. 本系统在VMware虚拟机下进行实现,采用CDH(Cloudera’s Distribution including apache Hadoop)来搭建大数据平台.软件版本信息为:CDH5.12.0,Hadoop2.6.0,Spark1.6.0,Java1.7.0,Maven3.0.4,GDAL2.2.2. 首先在HDFS根目录下创建image文件夹,此后所有遥感图像数据均保存在此目录下.本文遥感图像数据从Landsant遥感图像官方网站进行下载.这里本文下载2017年10月4日青海湖区域数据,并以此进行说明. 数据下载后,其文件夹名称为:LC08_L1TP_133034_20171004_20171014_01_T1.通过 hadoop fs –put命令将该文件夹及文件夹下数据上传到HDFS image目录下.则执行命令之后,该数据在HDFS上对应的路径为:/image/LC08_L1TP_133034_20171004_20171014_01_T1/*. 从上述3.1中得知,遥感图像数据已经存储到HDFS相应目录之下,本步骤所要实现的功能为通过Hadoop程序,完成HDFS数据的读取以及转换功能,最后生成libSVM格式数据,作为水体识别模型的输入. Hadoop程序采用Maven管理工具来进行构建,通过编写pom文件,实现程序jar包的依赖.本文通过GDAL(Geospatial Data Abstraction Library)来进行读取遥感图像.GDAL是一个用于读取栅格数据的开源库,对外提供了多种语言接口,本文通过Java语言来进行函数调用. 整体的实现过程如下所述:(1)首先从GDAL官方网站下载其源码,然后在linux系统上进行编译,编译完成之后,将得到so文件和jar文件.其中so文件复制到Hadoop安装目录native目录下;jar文件通过maven命令安装到本地maven仓库,而后通过pom.xml文件的设置,添加到Hadoop程序中.(2)按照本文3.2,3.3中的系统设计方案,实现输入输出及MapReduce程序.(3)进入程序的根目录,执行mvn package命令,对程序执行打包操作,得到hadoop.jar文件. 之后,对于遥感图像进行读取转换,只需执行如下命令即可: 程序会处理inputPath下遥感图像数据,并将其转换为libSVM格式数据,结果输出到outputPath路径下. 本文从遥感图像中共选取训练样本18 000个,其中正样本(水体)9000个,负样本(非水体)9000个.样本具体信息为:青海湖中心水体样本3000个,沿岸水体样本3000个,小岛附近水体样本3000个,耕地样本3000个,山脉样本3000个,荒地样本3000个.以此作为训练数据集,进行模型训练. 本模块基于Spark平台来进行编码实现,Spark工程同样采用Maven管理工具进行构建.在模型训练过程中,对训练数据集进行随机切分,其中70%用于模型训练,30%进行模型测试,不断迭代训练,直至模型收敛. 整体实现过程如下所述:(1)读取遥感图像,得到训练数据集,并保存为train_libsvm.csv文件.(2)将train_libsvm.csv上传到HDFS /MLlib目录下.(3)通过逻辑回归算法进行模型训练,并将得到的模型持久化保存到HDFS /model目录下. 本文模型训练的参数及测试集上准确率,如表1所示. 由上述3.2,可以得到待预测数据集,其格式为libsvm格式.Spark程序通过从HDFS相应目录下读取待预测数据,然后调用训练得到的模型进行预测,最终将预测结果输出到HDFS/spark_output目录下. 表1 模型参数及准确率说明 本文中,数据在HDFS上的存储路径设置如下:遥感图像存储于/image目录下,Hadoop程序运行结果存储于/Hadoop_output目录下,spark程序运行结果存储于/spark_output目录下,训练数据集存储于/mllib目录下,模型存储于/model目录下.根据目录之间的设定关系,本文采用shell脚本来进行程序的自动化执行,用户可以根据不同的需求,执行相应的脚本来完成功能.脚本的具体信息如下所述. 本文定义脚本waterClassification.sh,该脚本完成整个流程的自动化执行.当用户执行该脚本时,只需输入本地遥感图像文件夹路径即可.该脚本将依次完成文件上传,并执行Hadoop计算,而后进行模型预测,最终将结果识别结果输出到HDFS对应文件夹下,完成水体识别的整个流程. 由于本文水体识别过程,由不同的功能模块组成,故针对每一个具体的功能模块,本文定义对应的shell脚本,来实现模块功能的单独执行.实现模块功能的shell脚本有:uploadImage.sh,hadoop.sh,spark.sh.其中uploadImage.sh完成本地遥感图像上传功能;hadoop.sh完成读取数据,并对数据进行运算的功能,该脚本可以指定HDFS上任意遥感图像文件夹.spark.sh完成水体识别功能,该脚本运行时需指定待预测样本文件路径. 在上述系统设计方案的基础上,本文成功实现了基于大数据平台的水体识别系统.为了验证系统的有效性,以及对青海湖区域水体识别的效果,本文选取了不同三天的遥感图像数据,通过该系统进行水体识别.测试遥感图像数据为时间分别为:2017年7月16日,2017年10月4日,2017年11月5日. 通过该系统对遥感图像进行水体识别,得到识别结果后,对于识别出的水体像元,本实验将其对应的像元值设置为0,进行标注,其最终识别效果如图4,图5,图6所示. 图4 2017年7月16日 图5 2017年10月4日 图6 2017年11月5日 针对当前遥感图像水体识别速度慢,自动化程度低等问题,本文基于大数据平台,构建了水体识别系统.将遥感图像存储于HDFS,实现数据的分布式存储;自定义实现Hadoop输入输出格式,完成数据的读取;设计MapReduce,完成对遥感数据的处理;通过训练的模型对遥感图像像元进行预测;最后通过实验,来对该系统进行验证.实验结果表明,该系统可以自动,快速完成青海湖区域遥感图像水体识别,且准确率较高,具有一定的应用性.在本实验中,系统的执行是通过命令行的形式来完成,下一步工作将尝试开发Web界面,以使用户可以更简单方便的进行操作.


2.4 模型训练和模型预测设计
3 系统实现
3.1 遥感图像存储实现
3.2 数据读取及转换实现
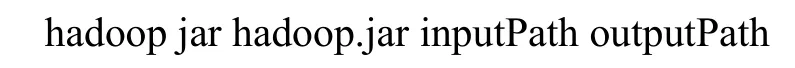
3.3 模型训练及预测实现

3.4 系统执行流程实现
3.5 系统验证

4 结论与展望
