基于深度学习分位数回归模型的风电功率概率密度预测
2018-09-13彭曙蓉彭君哲黄士峻郑国栋
李 彬,彭曙蓉,彭君哲,黄士峻,郑国栋
长沙理工大学 电气与信息工程学院,湖南 长沙 410114)
0 引言
截至2016年年底,中国风电并网容量已达到148.6 GW[1],然而随着风电在电网中比例的提高,风电的随机性、波动性等缺点也被逐步放大,大规模发展风电给电网带来了巨大挑战。提前精确预测风电功率,可以更好地指导电网发电、调度等工作,以及针对风电爬坡和其他对电网具有较大威胁的风电事件做好预防和消除工作[2]。
统计学习方法和物理方法是目前风电功率预测的2种主要方法。其中物理方法主要是利用数值天气预报NWP(Numerical Weather Prediction),目前基于该方法的预测精度均有限。相较于物理方法,统计学习方法在短期风电功率预测上预测精度较高。统计学习方法又分为点预测(确定性预测)和区间预测(不确定性预测),点预测的预测方法有IAFSA-BPNN(Improvement Artificial Fish Swarm Algorithm-BP Neural Network)[3]等。文献[4]提出了一种在3种不同优化准则下多预测组合模型的权重确定方法,并利用风电场实际数据验证了预测精度得到了有效提高。文献[5]提出了一种在改进局域Volterra自适应滤波器基础上的混沌时间序列预测模型。
然而确定性预测不能对风电功率不确定性进行定量描述的缺陷很难克服。在含风电的电网规划、运行和安全稳定分析领域中需要对风电的波动区间进行较精确的估计,仅仅得到单个点的预测值是不够的[6]。而且对风电的概率分布以及置信区间的预测可用于优化风电场的出力可靠性[7]、指导配电网无功规划[8]、进行实时市场调度[9],进一步给电网的发展规划带来更多的信息。如文献[10]采用极限学习机ELM(Extreme Learning Machine)模型对风电功率进行概率区间预测。
回归分析RA(Regression Analysis)是确定2种及以上变数间相互依赖的定量关系的一种统计分析方法。通常的回归分析方法又称为均值回归分析,均值回归很难代表响应变量服从非对称分布或者散布较大时的情况。Koenker等提出的分位数回归QR(Quantile Regression)可以较好地克服均值回归的不足。Taylor研究了一种神经网络非线性分位数回归模型[11],文献[12-13]将径向基函数(RBF)神经网络分位数回归模型应用于电力负荷概率密度预测,并在考虑实时电价的因素下采用支持向量机(SVM)分位数回归模型对电力负荷进行了概率密度预测。文献[14]提出一种采用因子分子法对24 h内小时级的风电功率序列进行降维处理后,再输入神经网络分位数回归预测模型进行风电曲线概率预测的方法。
基于以上分析,为了能得到更加准确的风电功率预测结果,给出更加准确、范围更小的预测区间和更符合风电功率的概率密度分布,提出一种长短期记忆神经网络LSTM(Long Short Term Memory neural networks)分位数回归概率密度预测方法。该方法可以预测未来风电功率区间以及概率分布,给电网运行带来指导作用。以美国PJM网(http:∥www.pjm.com/markets-and-operations/ops-analysis.aspx)上MIDATL地区的风电功率数据作为研究数据,能够得到一定置信度下的未来风电功率预测区间。
1 LSTM回归
深度学习在机器学习中的应用非常广泛,1997年Hochreiter和Schmidhuber提出了一种LSTM,能够很好地解决序列的长期依赖问题[15],其主要结构如图1所示,LSTM可以由时间展开表示成这种链状结构,LSTM的重复模块中有4个神经网络层。
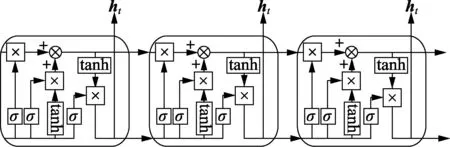
图1 LSTM结构Fig.1 LSTM structure
图1中一个矩形框称作一个元胞(cell),LSTM有4个门,第一层神经元为遗忘门(forget gate)的Sigmoid控制层,如式(1)所示。
ft=σ(Wf[ht-1,xt]+bf)
(1)
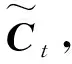
it=σ(Wi[ht-1,xt]+bi)
(2)
(3)
再将元胞的旧状态Ct-1更新为Ct,见式(4)。
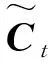
(4)
最后,通过一个如式(5)所示包含Sigmoid层的输出门(output gate)将式(4)通过一个tanh层之后(使得输出值在-1~1之间),再与输出门相乘,这样就将遗忘和记忆参数带至最后的输出。
Ot=σ(WO[ht-1,xt]+bO)
(5)
ht=Ottanh(Ct)
(6)
其中,Wf、bf分别为遗忘门的权重和偏置;Wi、bi分别为输入门的权重和偏置;WC、bC分别为更新值的权重和偏置;WO、bO分别为输出门的权重和偏置;σ(·)为Sigmoid激活函数;tanh(·)为双曲正切激活函数;[ht-1,xt]表示行数相等的矩阵或向量进行列合并;“*”表示对应元素相乘。
2 条件概率密度预测
2.1 线性分位数回归模型
考虑样本Y=[Y1Y2…YN]和X=[X1X2…XN],其中Y为响应变量,X为相应的解释变量,N为样本量,求线性回归的模型参数可以通过求解式(7)所示的目标函数来得到,其中β为回归系数。
(7)
式(7)中参数向量β的估计可以考虑转化为求解式(8)所示的优化问题。
(8)
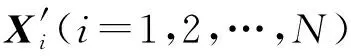
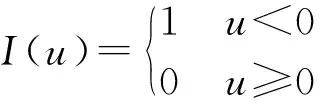
(9)
由式(8)得出,在不同的分位数τ下可以得到不同的参数估计β(τ),就能够测算出在不同分位数τ下解释变量对响应变量的条件分位数的影响。τ在(0,1)内连续取值时,就可以得到响应变量的条件分布,然后得到条件密度,最终得出条件密度预测。
2.2 LSTM分位数回归模型
在式(7)所反映的线性回归模型中,限定了解释变量和响应变量之间只能是线性关系。但是在现实中变量之间更多的是非线性关系。Taylor提出了神经网络分位数QRNN(Quantile Regression Neural Network)回归模型:
QY(τ|X)=f(X,W(τ),V(τ))
(10)
其中,W(τ)=(wij(τ))i=1,2,…,I;j=1,2,…,J为输入层与隐含层之间的连接权重,I为输入层节点数目,J为隐含层节点数目;V(τ)=(vjk(τ))j=1,2,…,J;k=1,2,…,K为隐含层与输出层之间的连接权重,K为输出层节点数目。
(11)
其中,λ1、λ2为惩罚参数。
分位数神经网络回归可以参考式(8),将其对参数W(τ)、V(τ)的估计转化为求解式(11)的优化问题。式(11)中λ1、λ2可以防止模型在训练过程中出现过拟合现象,可以使用Adam随机梯度下降法对式(11)进行求解,估计出参数矩阵W(τ)、V(τ)。
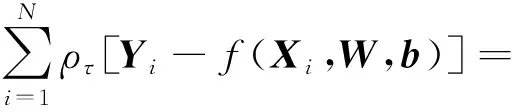
(12)
其中,W={Wf,Wi,WC,WO}为LSTM的权重参数;b={bf,bi,bC,bO} 为网络结构的偏置项权重。
根据LSTM回归模型的结构和式(12)所示的神经网络分位数回归方法,可以建立一种LSTM分位数回归模型,并将其对网络结构参数估计的BPTT(Back Propagation Through Time)算法过程的代价函数转化为如式(13)所示的分位数回归的目标函数。最终可以将参数估计看作式(13)所示的优化问题,并用Adam随机梯度下降法求解该优化问题。
(13)
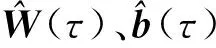
(14)
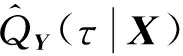
(15)
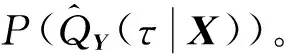
LSTM回归对非线性的时间序列具有很好的拟合能力,在道路运输相关的交通流速预测[17]、医学相关的蛋白质二级结构序列预测[18]等问题上都有较好的预测效果。概率密度估计主要是为了得到概率密度曲线,使得电网工作人员能更好地了解未来风电功率波动范围,获得更多的有用信息。利用分位数回归可以将二者有机结合起来,在不同分位数下进行LSTM回归可以得到多个点预测的结果,进而继续采用高斯核进行概率密度估计,得到概率密度函数,具体程序流程图见图2。
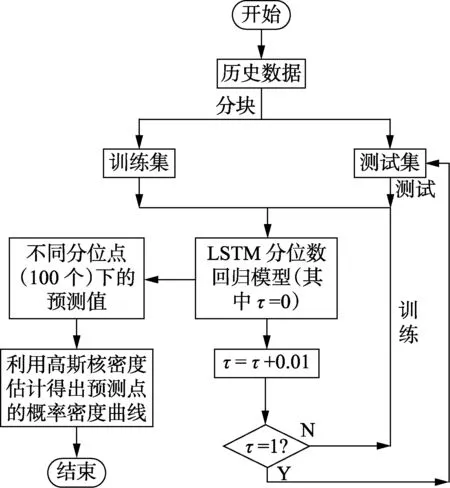
图2 程序流程图Fig.2 Program flowchart
2.3 模型评价
风电功率点预测模型常用的评价指标有平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)。从风电功率特性出发,给出了一种比较2个风电功率点预测模型的检验方法——DM(Diebold-Mariano)检验。该检验方法在假设两模型误差相等并服从正态分布的基础上做假设检验,当DM检验绝对值大于某个阈值时证明2个模型的预测结果有显著差异[19]。
然而上述评价指标并不能用来评价概率预测的结果。考虑风电功率的随机性强、波动范围大的情况,提出一种非参数模型的风电概率区间预测方法,并给出参考风电功率特性的概率区间评估指标[20],采用如下2个评价指标。
a. 可靠性指标。
在置信度1-α下,一共有Ninterval个预测区间,可靠性评价为:
(16)
风电功率实际落在预测区间内的概率应该等于或接近事先给定的置信度,可靠性指标越接近置信区间值则代表该预测模型越可靠。
b. 敏锐性指标。
可靠性指标不能全面体现概率预测结果的好坏,因为区间很大时可靠性通常会更高,相应的区间宽度过大会导致能提供的有用信息较少,所以还需要敏锐性指标来共同判断区间预测结果的好坏(区间平均宽度):
(17)
单一的敏锐性指标和可靠性指标都不能全面反映风电功率概率预测模型的好坏,只有综合敏锐性指标与可靠性指标才可以充分反映概率区间预测结果的优劣。
3 算例仿真
(18)
其中,Xt为t时刻的样本向量;Xmin、Xmax分别为所有样本的最小值和最大值。
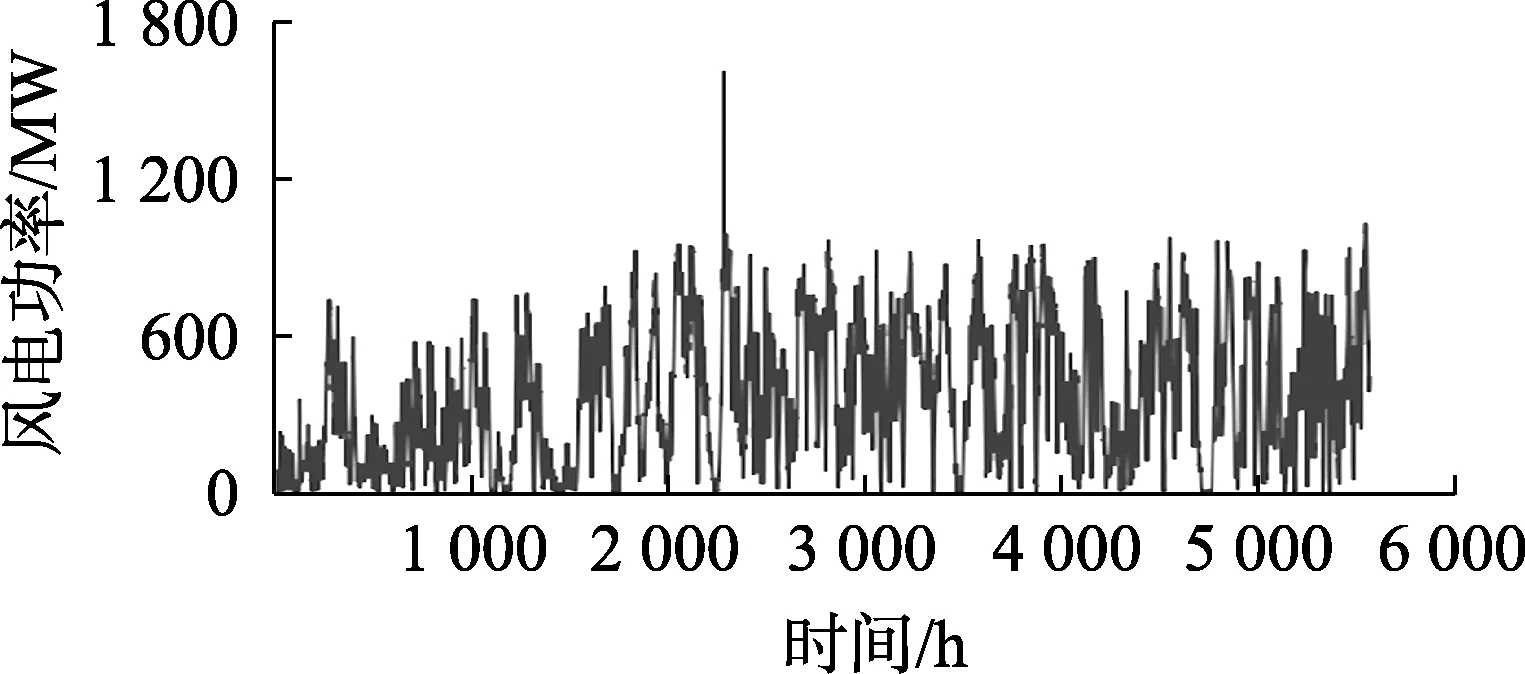
图3 美国风电功率数据Fig.3 American wind power data
QRLSTM的可靠性指标为84.16%,敏锐性指标为124.54,QRNN对应指标分别为79.12%和191.99,指标数据与图4对应的QRLSTM与QRNN预测结果一致。QRLSTM可靠性指标比QRNN高5.04%。虽然理论上可靠性应该与置信度相等,且上述2个模型的可靠性都没有达到置信度90%,但是比较接近置信度的结果也是可以接受的预测效果。QRNN比QRLSTM的敏锐度指标高出54.08%,如此大的差距充分体现了QRLSTM的优势,不仅预测的可靠性高于QRNN,且能在预测结果中提供更多的有效信息。
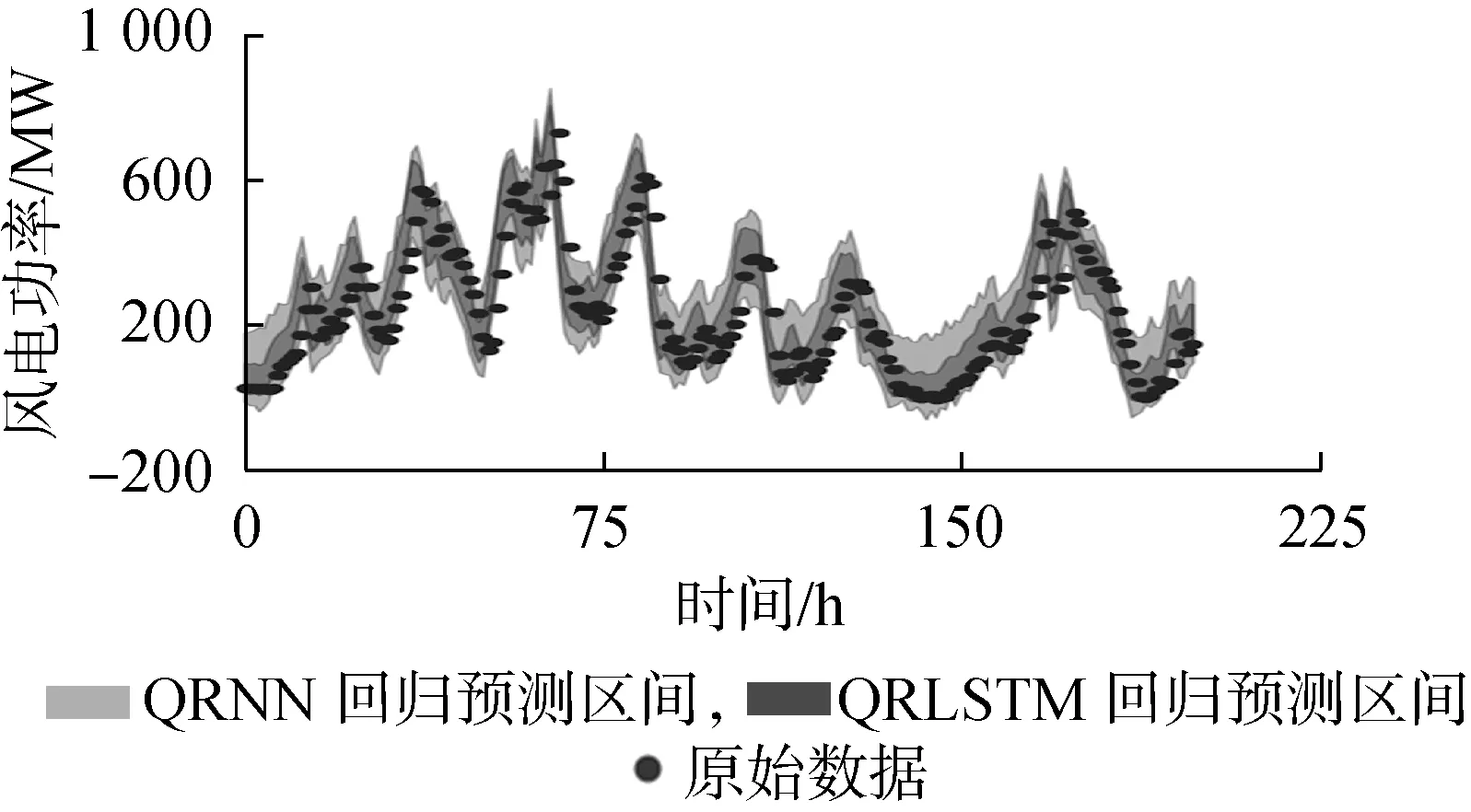
图4 QRLSTM与QRNN风电功率预测结果对比Fig.4 Comparison of wind power forecasting results between QRLSTM and QRNN
通过2个模型指标数据和图4的对比明显看出真实值很大概率落在QRLSTM回归的预测区间内。相比QRNN回归模型,真实值落在QRNN预测区间内的概率明显要小很多,且预测的区间宽度比QRNN的预测区间小很多,这充分说明了本文提出的QRLSTM回归模型可很好地预测风电功率的波动性,且可以预测较长时间的风电功率波动性。
采用QRLSTM回归方法可以得到预测点的概率密度曲线,从预测点0~200中随机抽取第4、47、90、104、138、168这6个时间点的概率密度函数分布区间见附录中图A1,其中第104个时间点的概率密度函数见图5。从预测出的概率密度函数可以看出,QRLSTM可以预测出风电功率的完整概率密度分布,且真实值都落在该密度函数中间。以上示例说明该方法能够给出未来预测时间点概率密度曲线。
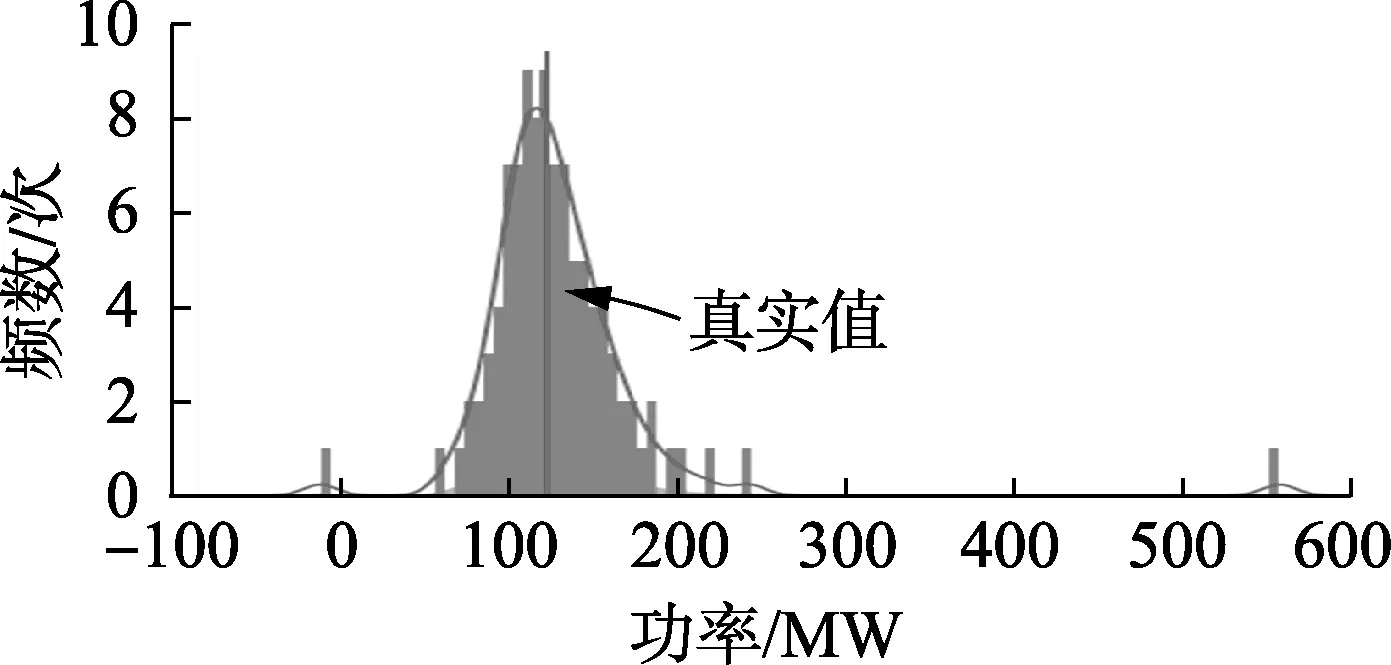
图5 QRLSTM风电功率预测概率密度函数Fig.5 Probability density function of wind power forecasting for QRLSTM
附录中表A1展示了QRLSTM与QRNN预测模型前24个预测点的预测区间和预测区间范围的差值。从数据中也可以看出,QRLSTM预测模型预测出的概率区间比QRNN预测出的概率区间范围小很多。
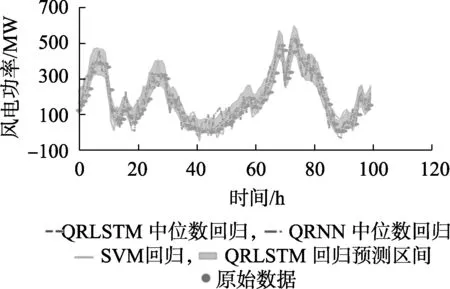
图6 QRLSTM区间预测与点预测结果对比Fig.6 Comparison between QRLSTM interval prediction and point prediction
图6对比了另外2种点预测的结果和LSTM分位数回归的区间预测结果,可看出相比于点预测,区间预测的可信度更高,在实际使用预测结果时可以更好地规避误差带来的风险。QRLSTM、QRNN、SVM这3种点预测模型平均绝对误差分别为34.8、52.8、60.09,可以看出QRLSTM中位数预测的准确率比QRNN和SVM都要高。
4 结论
本文提出一种QRLSTM预测模型,其可靠性指标比QRNN高5.04%,敏锐性指标比QRNN低54.08%,充分体现了QRLSTM的优势,能够提供更多的有效信息给电力行业使用者。
该方法不仅在预测精度上有提高,而且能获得风电功率概率密度函数,可以为电力系统增强风电消纳能力提供更多的有用信息,便于风电的发展,促进环保和解决能源不足问题。
附录见本刊网络版(http:∥www.epae.cn)。
