相似矩阵和聚类一致性的协同显著检测*
2018-09-12郑海军吴建国刘政怡
郑海军,吴建国,刘政怡+
1.安徽大学 计算智能与信号处理教育部重点实验室,合肥 230601
2.安徽大学 计算机科学与技术学院,合肥 230601
3.安徽大学 信息保障技术协同创新中心,合肥 230601
1 引言
众多学者已经提出了许多可以定位图像中可见的物体或区域的显著检测方法[1-3]。近年来,协同显著检测越来越吸引人们的注意。协同显著检测将图像分为协同显著区域、非协同区域和背景。协同显著区域具有两种性质:(1)每张图片的协同显著区域与其周围相比应该具有较强的局部显著性;(2)所有的协同显著区域应该是相似的。非协同区域指单张图像是显著的,但在一组图像中与其他显著区域相比差异较大,需要被抑制为背景的区域。因此,协同显著检测是在图像集中找到共同的显著目标同时将个别的显著目标抑制为背景[4-7]的方法。协同显著检测广泛地应用于许多计算机视觉方面,如协同分割[8]、协同识别[9]、匹配[10]等。
多张图像的协同显著检测方法已经在多个方面得到发展。Liu等在文献[5]中从分层分割的图像,在精细尺度的分割下定义区域对比线索和相似度线索,在粗糙尺度下计算目标先验,整合这些线索得到协同显著图。李等在文献[6]中提出了一种由查询引导的两级显著检测,通过流形排序获得图像集的引导性显著图。
低秩矩阵分解策略被广泛应用于协同显著目标检测,低秩矩阵分解是将一个矩阵分解成代表背景的低秩矩阵和代表目标的稀疏矩阵。Ye等在文献[7]中提出了一个有效协同显著目标恢复策略。黄睿等在文献[11]提出了高斯混合模型生成协同先验,使用融合策略得到协同显著检测结果。Cao等在文献[12]中计算自适应加权值来融合单张显著图,使用秩约束获得协同显著图。但是,当低秩矩阵和稀疏矩阵相对一致,显著目标和背景相似或具有复杂的背景时,低秩矩阵恢复策略很难解决这些问题。
基于颜色特征聚类的方法在协同显著检测领域被深度应用。付等在文献[4]中提出了基于颜色特征聚类的方法,在类的层次上整合对比、空间和一致性线索,融合单张检测结果和协同检测结果得到最终显著图。Hwang等在文献[13]提出基于聚类和传播的协同显著检测方法,通过类的一致性和前景概率计算类的协同显著值,再通过两个阶段的传播得到最终的显著值。但是,类的一致性会将分布较广的背景误识为显著目标。
为解决上述问题,本文提出一种基于特征权重的低秩矩阵分解模型和聚类一致性的协同显著检测算法。为了更好区分低秩背景和稀疏目标,在低秩矩阵分解模型中加入一个拉普拉斯正则项。使用直方图表示显著区域,计算相似矩阵表示直方图之间的差异性信息,将特征权重融入拉普拉斯正则项,并以此得到加权显著图。此外,简单的类的分布不能很好地体现协同一致性,相同类的显著值应具有相似性,用聚类一致性得到协同显著图,并融合加权显著图,得到最终结果。
2 方法
本文主要包括显著区域提取、构造直方图和计算相似矩阵、低秩矩阵分解和聚类一致性4个主要部分。图1为算法的流程图。首先,图1(b)、图1(c)是对一组图像分别生成基本显著图和超像素。本文引用多种显著检测方法如图1(b),得出的显著图作为基本显著图。其次,在一组图中,通过设置显著阈值提取每个算法的显著区域如图1(e),将每个显著区域的RGB颜色特征转换成直方图,所有的直方图组合成一个特征矩阵H如图1(f),并计算相似矩阵,通过低秩矩阵分解模型分解特征矩阵H得到噪音矩阵E如图1(f)。结合加权值和相应的基本显著图得到加权显著图如图1(g)。对输入图进行聚类如图1(d),采用聚类一致性得到协同显著图,并融合加权显著图生成最终显著图如图1(h)。
2.1 显著区域的提取
选取M种显著检测方法分别对N张图像进行处理得到N×M张显著图,1≤i≤N,1≤j≤M,i表示第i张图像,j表示第j种方法,N表示输入的图像的数量。同时使用SLIC(simple linear iterative clustering)[14]分别对图像进行超像素分割得到超像素,代表的超像素数量。设置阈值分别对显著图处理得到二值化图:

其中,x∈Xi;mean(·)表示在超像素x中所有像素点在显著图的显著值的平均值;表示中所有超像素的平均显著值中最大的显著值;α控制阈值,设置为0.3。

Fig.1 Algorithm flow chart图1 算法流程图
图像Ii的显著区域由第j种方法中的一组显著的超像素构成如图1(e),如图2所示,显著区域定义如下:

选择的M种显著检测方法本身具有误差,因此提取的显著区域包含协同区域、非协同区域和背景。
2.2 构造直方图和计算相似矩阵
通过纵向观察图2,基于协同显著的定义,N个显著区域具有相似性和一致性,如图2(b)所示。同理,通过横向观察M个显著区域同样具有相似性和一致性。为了衡量这种性质,引入三通道颜色直方图表示每个显著区域。颜色直方图是基于RGB颜色分类的思想,每个颜色通道统一量化为10 bin,共有K=103bin,即将显著区域上的像素点量化为1 bin到1 000 bin(即分成1 000类),再统计每个bin上的像素点数量并以此构造一个颜色直方图。将显著区域产生的N×M个直方图重新组合成一个特征矩阵H。
特征矩阵H代表的是显著区域的颜色特征,显著区域是相似的,因此在特征矩阵中属于相同bin的数值也是相似的,但因为显著检测方法并不是十分精准,所以即使相同bin也有差异性。本文引入相似矩阵W表示这种性质,类似于RGB三通道,将特征矩阵H的K-bins视作K个通道,通过欧式距离计算每个通道任意两个bin的相似性,即相同bin情况下不同直方图之间的差异,为突出不同直方图之间的差异,对欧式距离进行指数处理。
欧式距离的优点是简单高效,缺点是样本的多个属性对欧氏距离的贡献是相同的。本文直方图是将显著区域每个像素点的RGB颜色特征统一量化,统计属于相同bin的像素点数量,相似或相同的像素点属于相同bin。每个通道任意两个bin相似或相同,欧式距离越小表示相应的两个直方图差异越小,越可能是协同显著区域,反之亦然;采用指数函数对K个通道的欧式距离进行加权优化处理,凸显相似或相同bin的欧式距离权重,减弱差异较大的欧式距离权重,权重wab定义为:

其中,ha代表H的第a行;||·||表示计算不同bin的欧氏距离;指数函数exp(·)加权处理欧氏距离;σ2=0.01。
2.3 低秩矩阵分解模型
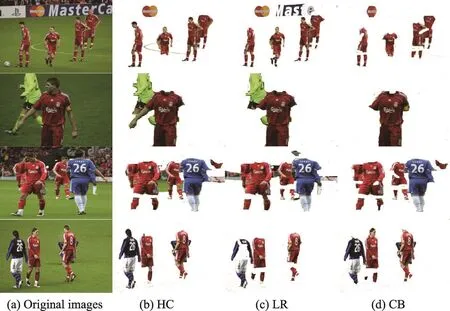
Fig.2 Saliency regions extraction图2 显著区域提取
如图2所示,从不同图中提取的雕像具有相似的颜色特征和噪音背景天空,因此是处于低维空间的显著区域和稀疏噪音的背景的结合。本文使用特征矩阵H描述特征。因此,对于提取的显著区域,重新定义分布较广的雕像为背景,定义稀疏的背景天空为目标,将特征矩阵H分解成两个部分H=L+E,L代表分布较广泛的背景部分,E代表稀疏目标。中的一致性越高,H的秩越接近于1,E越稀疏。因此,将求矩阵的秩转换成求噪音矩阵E的矩阵分解问题,低秩矩阵分解模型可以描述为:
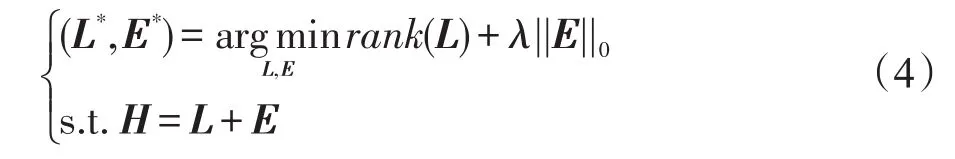
其中,||·||0代表ℓ0-norm(非零元素的个数);λ是控制E的稀疏权重系数。使用拉普拉斯正则来增大矩阵H的差异性,即增大特征空间中的显著目标和背景的差异,因此式(4)转化成:
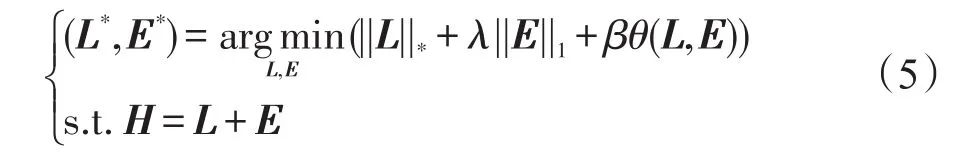
其中,||·||∗表示核范式(奇异值的和);||·||1表示ℓ1-norm(元素绝对值的和);θ(·,·)表示的是增大L和E之间差异的拉普拉斯正则项;β表示平衡参数。
通过使用正则项,显著目标和背景更容易被区分。拉普拉斯正则项被定义为:
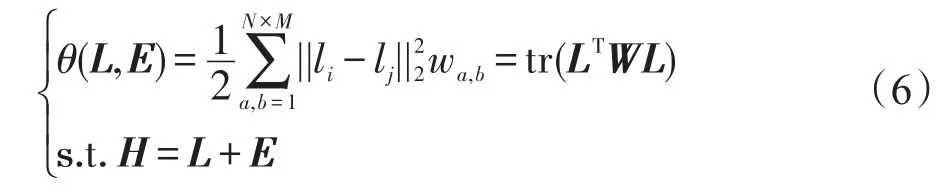
其中,li为L的第i列;tr(·)为矩阵的迹;W为相似矩阵。
2.4 低秩矩阵分解更新
解决凸包问题有多种方法,包括迭代阈值(iterative threshold,IT)方法[15]、加速近端梯度(accelerate proximal gradient,APG)方法[16]、对偶方法(dual method,DUAL)和交替方向方法[17](alternate direction method,ADM)。IT方法迭代形式简单且收敛,但收敛速度较慢;APG方法和IT方法类似,但大大降低了迭代次数;DUAL比APG方法具有更好的可拓展性;ADM比APG方法更快,而且可以达到较高的精度,需要较低的存储空间。因此,本文采用ADM解决凸包问题。结合式(5)、式(6),引入辅助矩阵Z,式(4)可以描述为:
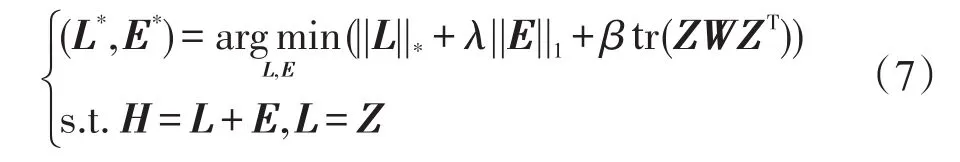
通过使用ADM求解式(7),式(7)相当于最小化下面的增广拉格朗日函数:
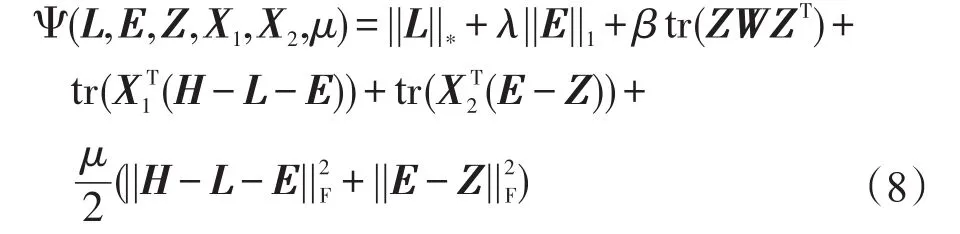
其中,X1和X2是拉格朗日乘子;μ是正数约束;||·||F是Frobenius范式。
通过迭代优化L、E和Z求解式(8),这3部分的最优解并不是同时得到,而是在迭代中通过ADM交替得到。
2.4.1 更新L
固定E和Z,通过解决下面的问题在第(t+1)次迭代得到Lt+1:
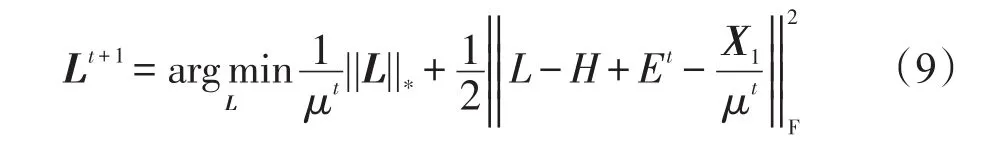
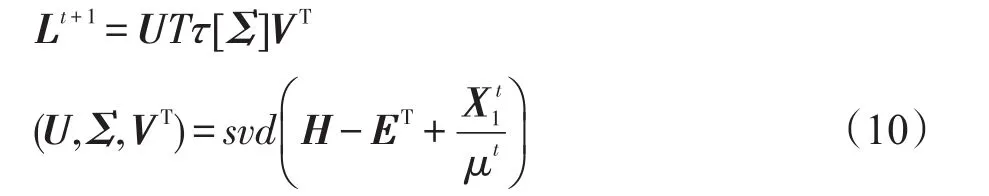
其中,τ=1μt;Σ是奇异值;Tτ[·]是奇异值阈值。
2.4.2 更新Z
固定L和E,Zt+1的更新转换成求解下面的最小问题:
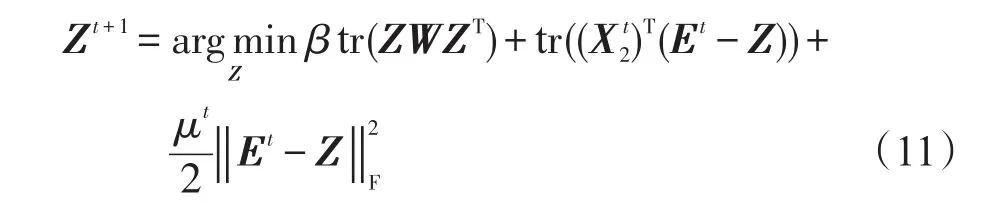
推导式(9),可得:
推导式(11)得到Zt+1,描述为:
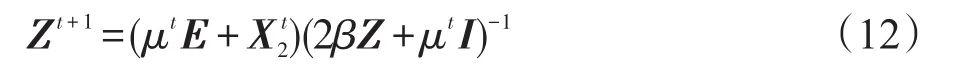
其中,I为单位矩阵。
2.4.3 更新E
固定L和Z,E的更新相当于下面的问题:
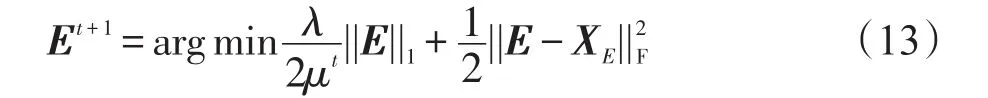
2.5 加权显著图
使用具有相似矩阵的低秩矩阵分解方法,将特征矩阵H分解为更准确的矩阵L和E。矩阵E可以视作特征矩阵H和低秩矩阵L之间的误差,对进行处理得到特征直方图和图像Ii之间的距离



2.6 聚类一致性
通过K-means对图聚类,聚类获得的特征和本文使用K-means所获得的特征是一致的,包括聚类中心、类在图的分布和类中图的像素点个数。K-means方法对初值较为敏感,为确保初值质量采用最大距离聚类方法[18],随机产生第一个聚类中心C1,C1是图中一个像素点对象的RGB颜色特征,从所有像素点中选择与C1的RGB颜色特征相同或相近的作为类C1的分布并更新C1;计算所有像素点的颜色特征与类C1的差异,选取最大差异的像素点作为C2,并选取与C2相同或相近的像素点作为C2的分布且更新C2;以此类推,直到选取C个聚类中心。最大距离聚类方法可以避免可能出现的聚类种子过于邻近,但该方法对聚类中心C1敏感,因此采用多次实验随机产生聚类中心C1,选择最优结果作为最终结果。
将Scos显著值映射到相应的像素点上,计算每个类的平均显著值,得到第i张图像中第j个类的平均显著值
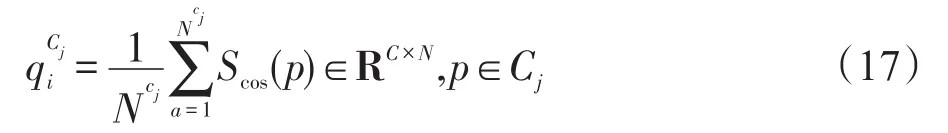
其中,Ci表示类的索引;C表示聚类的数量,设置为20;Ncj表示类Ci中像素点数,1≤i≤N;Scos(p)表示类Ci中像素点p的显著值。将每个相同类的显著值相加除以C可以求得类平均显著值平均显著值越小,类是背景的可能性越大,反之亦然。
协同显著检测的目的是检测多图中协同显著的部分,抑制非显著部分和显著但非协同部分,而且显著非协同部分一定是分布比较少。为进一步区分显著非协同区域和显著协同区域,对进一步方差处理得出显著分布权重w(c):

其中,w(c)∈RC×1;var(·)表示方差分布,即一组图像中相同的类的显著值分布的均匀情况,方差越大表示类的显著值分布不均更可能是显著非协同部分,方差越小表明显著值分布均匀是显著协同或者是非显著部分的可能性更大。


3 实验结果
实验在协同显著研究领域应用广泛的iCoseg和iCosegSub[19]两个公共数据集上评估本文方法。iCoseg数据集包括38组共643张图像,每一组包括5到41张图像。iCosegSub是iCoseg数据集的子集,每组包括5张图像。这2个数据集都有人工标注的真值图像,有利于进行客观的评价。本文M设置为5,选取的算法包括 MR[1]、HS[2]、SM[3]、CB[4]和 LR[20]。实验对比本文算法和其他算法,分别评估Precision、Recall、F-measure以及运行时间这几个指标。本文共选择9种对比方法,其中包括5种协同显著检测方法CB[4]、EM[6]、CF[20]、CO[7]和 SA[12],4 种单张图像的显著检测MR[1]、HS[2]、SM[3]、LR[21]。
实验平台:所有程序都是在Intel Core i7 CPU 2.00 GHz,内存4 GB的PC上实现。本文方法使用Matlab(R2016a),对比算法来自各作者提供的公开代码或显著图。
3.1 评估标准
查准率表示正确检测的显著目标与完全显著目标的百分比。查全率是指正确检测显著目标的完整度与完全显著目标的百分比。当Precision和Recall两者值同时越大,表明算法的效果越好。但两者之间存在制约关系,Precision大时,Recall通常较小,反之亦然。因此,采用F-measure权衡两者之间的关系,其定义如下:

其中,β2=0.3为常数,用来控制查准率和查全率的权值。
3.2 实验结果及分析
3.2.1 性能对比
本文与9种算法在iCoseg和iCosegSub数据集上进行比较,其中,MR将图的4条边界作为种子进行排序并获得背景显著图,二值化背景显著图获得前景种子,进行显著运算获得最终结果;HS将输入分成3层,计算每层的显著线索并将显著线索融入分层模型得到最终结果;CB是基于颜色特征聚类的方法,整合了对比、空间和一致性线索的显著检测方法;LR利用低秩矩阵分解,将图像分解成稀疏的显著区域和低秩的背景;SMD将树结构嵌入低秩矩阵分解模型中;EM是由查询引导的两级显著检测方法,通过流形排序获得图像集的引导性显著图;CF是基于协同区域具有相似的颜色特征,将颜色特征稀疏编码并计算协同引导图,通过融合得到最终结果;SA是基于一致性能量和秩约束得到自适应权重,加强显著图的协同区域的比重;CO有效地利用局部和全局恢复的协同显著区域、边界连通性,从而生成图像集的协同显著图。使用查准率、查全率和F-measure作为评价指标。
iCosegSub数据集上的比较。图3(a)、图3(b)分别为PR曲线和评估直方图。图3(a)PR曲线显示,本文算法整体优于其他8种算法,图3(b)所示为基于查准率、查全率和F-measure的3个指标的评估结果。评估直方图表明,本文算法的查准率达到0.899 5,高于其他8种算法,F-measure值低于算法EM和CF,但皆高于其他算法。
iCoseg数据集上的比较。图4(a)、图4(b)分别为PR曲线和评估直方图。图4(a)PR曲线显示,本文算法整体优于其他8种算法。图4(b)所示为基于查准率、查全率和F-measure的3个指标的评估结果。评估直方图表明,本文算法的查准率高于第二名的CO近7%,F-measure值低于EM和CO,但皆高于其他算法。
本文算法的查准率比其他算法高,但查全率较低,其原因是选择的5种显著检测方法的检测结果并不是十分准确,加权显著图是对这些检测误差的部分修正,并且加权显著图的误差也影响了聚类一致性的计算。查准率高可以较准确地定位显著目标,查全率较低可能会丢失显著目标的部分区域。
3.2.2 质量对比
图5所示是本文算法与其他算法的质量对比实验。图5(a)来自于iCosegSub数据集,选择1~3列和4~6列两组图像。图5(b)来自于iCoseg数据集,选择一组共31张图像集中的10张图像,其中的协同显著目标为穿红色球衣的球员。相对于其他8种算法,本文算法能够更好抑制较复杂的背景和显著非协同区域,如图5(a)第1和第2列穿红色球衣的球员和复杂背景被抑制,图5(b)中穿红色球衣以外的球员被抑制,第1、2、5和6列的复杂背景被抑制。
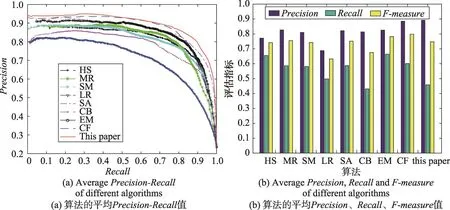
Fig.3 Experimental results of different algorithms on iCosegSub database图3 不同算法在iCosegSub数据集上的对比结果

Fig.4 Experimental results of different algorithms on iCoseg database图4 不同算法在iCoseg数据集上的对比结果
3.2.3 运行时间对比和分析
将本文方法分别与HS、MR、SM、LR、CB、CF、SA、CO、EM算法在数据集上进行运行时间的对比,结果如表1所示。本文运行每幅图片的平均时间为3.120 s,运行时间相对于传统方法偏高的原因是低秩矩阵分解模型处理数据较多,比传统方法花费更多的时间。本文方法的运行时间少于同样使用低秩矩阵分解模型的SM、LR、CO的时间。
3.3 矩阵分解模型对比
在不计算聚类一致性的前提下,将引入具有相似矩阵的矩阵分解模型(LRMD-SM)和普通矩阵分解模型(LRMD)进行比较,如图6所示。本文的查准率、查全率和F-measure分别为0.831 0、0.600 9和0.763 5高于未引入拉普拉斯项的矩阵分解模型,其查准率、查全率和F-measure分别为0.821 7、0.588 3和0.752 8。
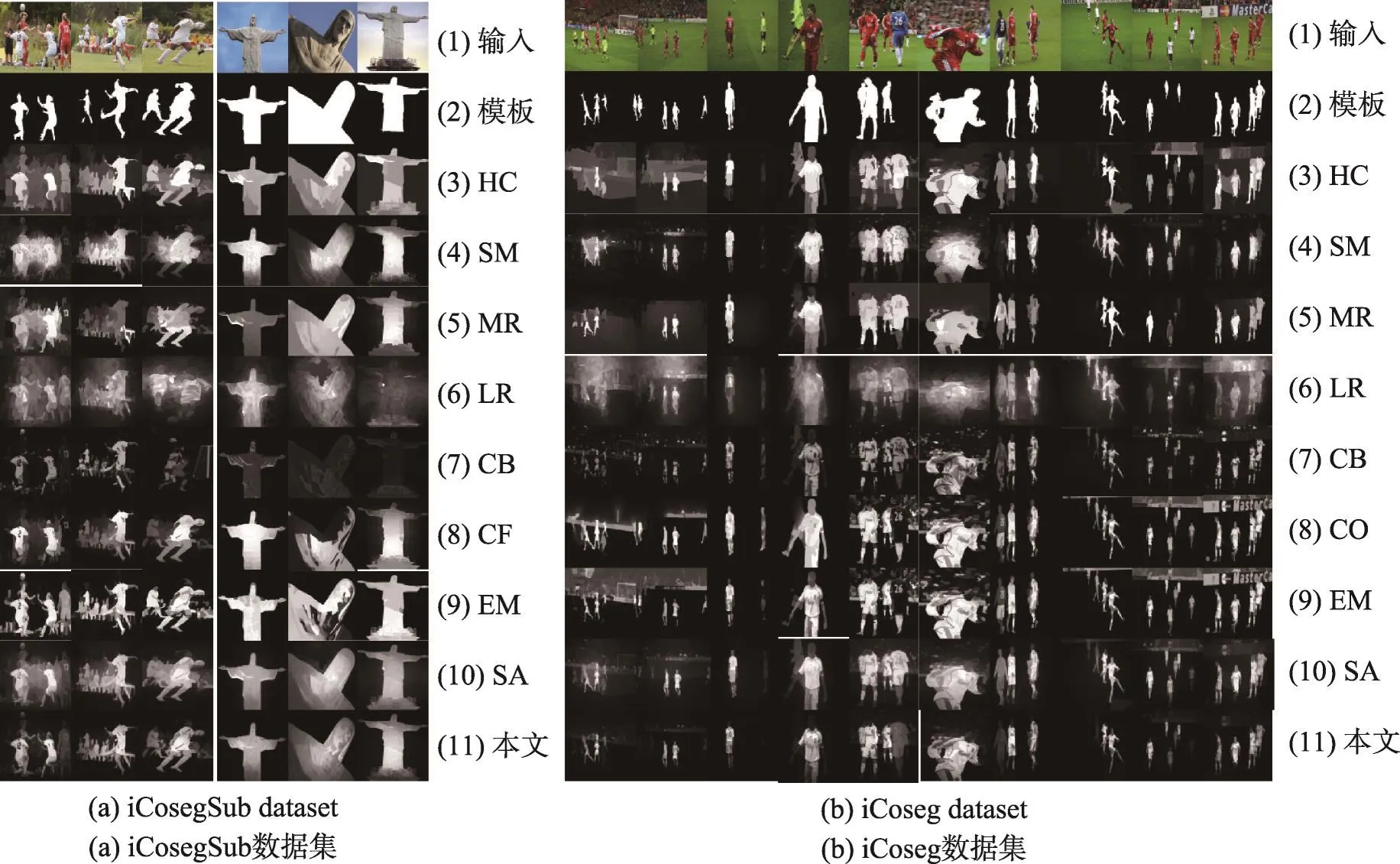
Fig.5 Quality contrast图5 质量对比
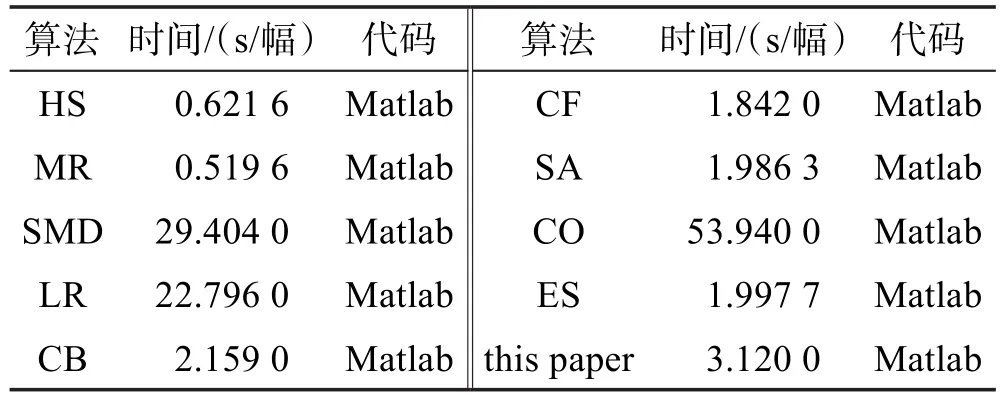
Table 1 Comparison of average run time表1 平均运行时间对比

Fig.6 Low rank matrix decomposition model contrast图6 低秩矩阵分解模型对比
3.4 优化现有算法的结果
本文发现:即使基于某种方式获取的显著图的效果很差,聚类一致性仍然可以提高显著图的查准率和F-measure值。如图7所示是使用本文的聚类一致性方式得到的显著图,对本文4种协同显著算法进行优化的结果。从优化结果上发现聚类一致性对4种算法的PR值有不同幅度的提高。说明聚类一致性方案是可行的,并且也是有效的。
4 结束语
在本文中,相似矩阵和聚类一致性被应用于协同显著检测。提取的显著区域的RBG颜色特征构造了直方图矩阵,由直方图中相同bin的相似性构造的相似矩阵被应用于低秩矩阵分解中,获得更精确的显著目标和背景。聚类一致性一组图像中相同且显著的类应该具有一致性。在iCoseg和iCosegsub数据集上与8种方法进行比较,结果显示了本文算法的有效性和优越性。
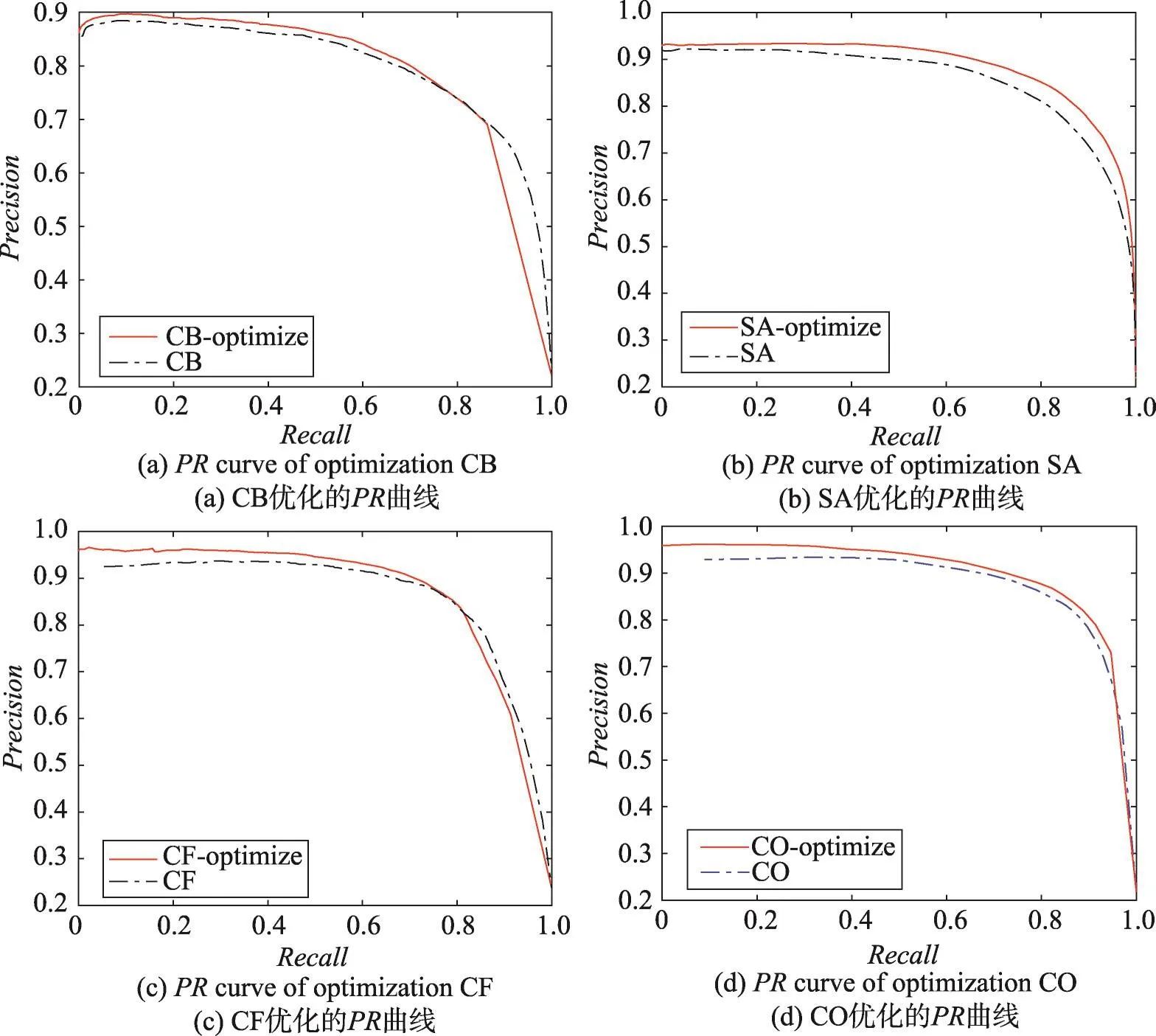
Fig.7 Clustering consistency optimization contrast algorithms图7 聚类一致性优化对比算法
